Source-first digest for monthly checked paper rank 1, rank_id p001.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
Most interactive video world models still behave as single-agent simulators: they predict future observations from one action stream, one viewpoint, or one user control channel. The paper argues that this is structurally insufficient for shared worlds, because multiplayer games, multi-robot systems, and embodied agents require several independently controlled agents to act in one evolving environment. The model therefore has to preserve time consistency and cross-perspective consistency at the same time.
The paper positions Solaris as the closest prior multiplayer world model, but highlights two bottlenecks: dense all-to-all cross-agent attention grows quadratically with agent count, and learned per-player ID embeddings assign privileged identities to exchangeable players. \(\gamma\)-World is proposed as a multi-agent video world model that keeps each agent independently controllable while making agent identities exchangeable and making cross-agent communication cheaper.

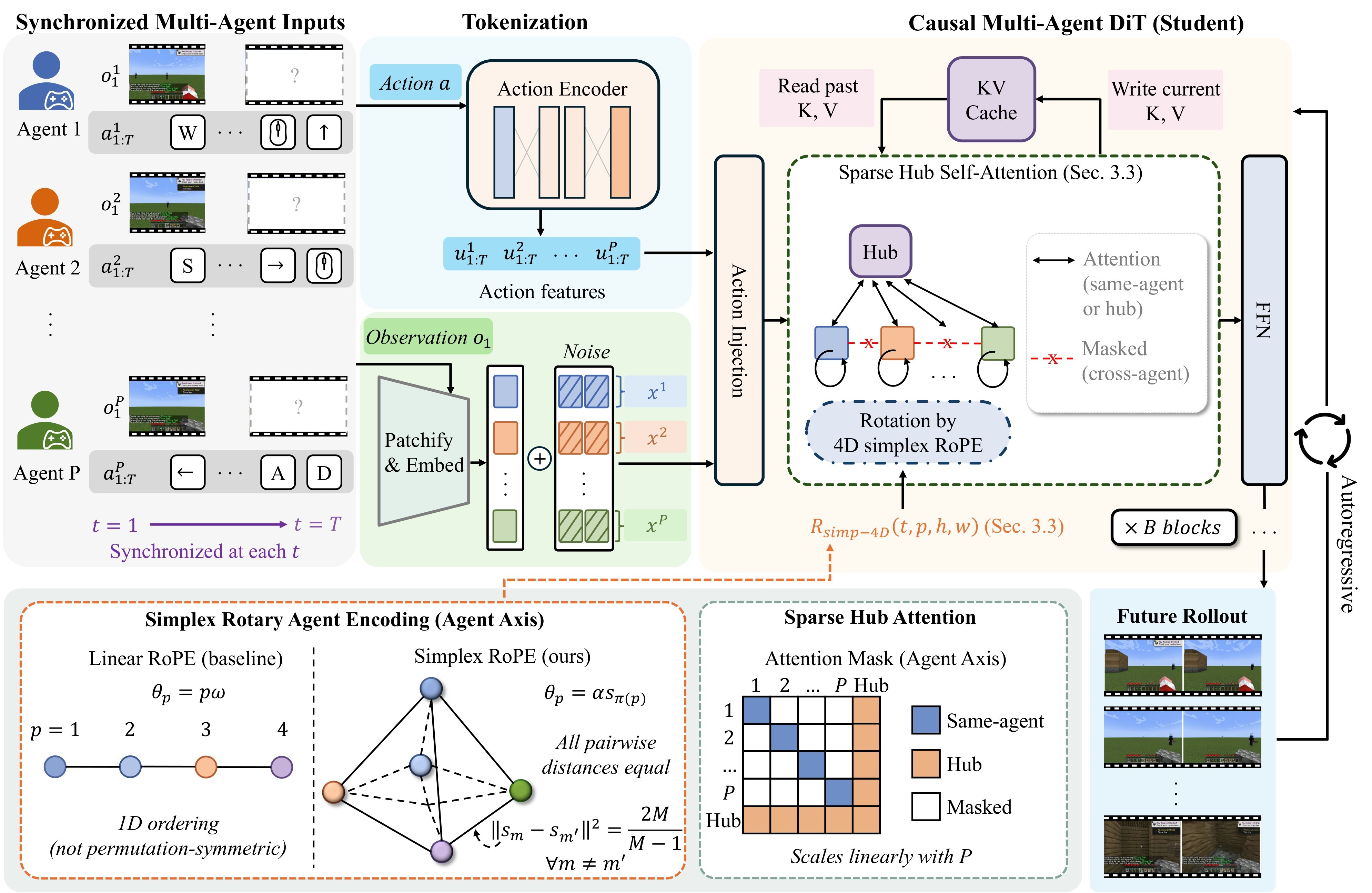
The central claim is not just that a diffusion model can generate more video frames. The paper is about the representation and inference structure needed when the conditioning input is a synchronized set of agent observations and actions. The three main components are Simplex Rotary Agent Encoding, Sparse Hub Attention, and conditional self-forcing distillation into a streaming causal generator.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Treating multi-agent world modeling as a synchronized agent-axis prediction problem is a better fit than merging players into one visual stream. | 4 | problem setup, method overview, baseline table, two-agent examples |
| C2 | Simplex Rotary Agent Encoding gives distinct agent phases while preserving permutation symmetry and avoiding fixed learned player slots. | 5 | simplex equations, simplex proof, architecture ablation, four-agent scaling |
| C3 | Sparse Hub Attention reduces the dominant cross-agent attention cost from quadratic to linear in the number of agents while preserving a shared communication pathway. | 5 | hub mask and cost, efficiency figure, hub-token ablation |
| C4 | The teacher-student recipe makes the model usable for real-time action-responsive rollout with KV-cached streaming. | 3 | training and inference, variant ablation |
| C5 | \(\gamma\)-World outperforms frame concatenation and Solaris on the reported multi-agent Minecraft evaluation protocols. | 5 | baseline table |
| C6 | The full architecture is supported by ablations over composition, identity encoding, and interaction topology. | 4 | architecture ablation, hub-token ablation |
| C7 | The same two-agent-trained checkpoint can be extended to four-player rollouts without architectural changes. | 3 | implementation details, four-agent scaling |
| C8 | The formulation has some transfer beyond games, shown through bimanual robot coordination examples, but the robotics evidence is qualitative. | 2 | robotics examples, limitations |
Support scores are support-from-paper scores, not reproduction scores. Mathematical and table-backed claims receive higher scores; qualitative transfer and real-time deployment claims are capped lower when the paper gives limited quantitative evidence.
Core Technical Idea
The paper takes a latent video diffusion transformer and inserts an explicit agent axis. A clean multi-agent latent is represented as:
where \(P\) is the number of agents. At inference, each agent has an initial observation and its own future action sequence. The model denoises future latent observations jointly, so all agents' generated viewpoints are coupled through the same transformer.
The model still uses a standard flow-matching diffusion objective. For a clean latent \(\mathbf{z}_0\), noise \(\boldsymbol{\epsilon}\), and noise level \(\sigma\), it forms:
then trains a velocity field:
The conditioning package \(\mathcal{C}\) contains initial observations and per-agent actions. The contribution is how those actions and identities are structured so that multiple agents remain separately controllable but jointly consistent.
Method Details
Action Conditioning
Each agent has a synchronized action sequence \(\mathbf{a}_{1:T}^p\). The action encoder is shared across agents, so an action does not mean something different just because it comes from player slot 1 versus slot 2. For layer \(\ell\), the model maps an action to a layer-specific bias:
then adds it to every spatial token for that agent and frame:
This makes action control local to the corresponding agent stream while still letting the transformer coordinate all streams.
| Domain | Per-frame action fields | Details |
|---|---|---|
| Minecraft-style game | 25 | 23 discrete controls for inventory, hotbar, locomotion, movement modifiers, and item interactions, plus 2 continuous camera controls. |
| Robot coordination | 10 | 3D end-effector position, 6D orientation, and gripper opening for each robot arm. |
Table 1. Action formats. This table is included because it shows that the paper's action-conditioning interface is explicit and per-agent, not just a generic text prompt.
Simplex Rotary Agent Encoding
The paper's Simplex Rotary Agent Encoding extends 3D RoPE with an agent band. The rotary dimension is partitioned into time, agent, height, and width:
A naive scalar player index would put agents on a line, so player pairs at distances 1 and 2 would not be equivalent. Learned slot embeddings also bake in a roster. Instead, the paper places agents at vertices of a regular simplex in the agent-angle subspace:
The key property is equal pairwise distance:
For a batch with \(P \leq V\) active agents, the model samples an injective assignment \(\pi\) from active agents to simplex vertices and uses:
The resulting rotary operator is:
The important engineering property is that agent identity is parameter-free. During training, active agents are randomly assigned to different simplex vertices and the slot order is permuted. At inference, additional agents can be activated by selecting unused vertices from the same simplex pool, without adding learned ID embeddings.
The appendix proves the equidistance property directly. After centering one-hot vectors and normalizing,
so:
This is strong mathematical support for the symmetry claim. It does not by itself prove that generated videos are better; that part comes from the ablations and qualitative scaling evidence.
Sparse Hub Attention
Dense cross-agent attention over \(P\) agents, \(n\) frames per block, and \(L=HW\) spatial tokens costs:
The paper replaces direct pairwise agent-to-agent attention with Sparse Hub Attention. Agent tokens attend to their own stream and to hub tokens. Hub tokens attend to all agents and other hub tokens. Direct cross-agent token attention is masked, so information flows as agent \(\rightarrow\) hub \(\rightarrow\) agent.
With identity function \(\rho(i)\in\{1,\ldots,P,\mathrm{hub}\}\), the hub topology is:
For autoregressive generation, it is composed with a block-causal mask:
The resulting per-block attention cost becomes:
which is linear in \(P\) for fixed \(n\), \(L\), and hub-token count \(K\). This is the paper's clearest computational argument for scaling beyond two players.
Training And Streaming Inference
\(\gamma\)-World uses three stages:
1. Train a bidirectional teacher for high-quality conditional denoising with full temporal and cross-agent visibility. 2. Train a block-causal student using Diffusion Forcing and Sparse Hub Attention, so each block attends only to current or past blocks while cross-agent communication goes through hubs. 3. Distill the causal student into a few-step generator using conditional self-rollout and distribution matching distillation.
The paper emphasizes that the distillation is conditional: teacher and student both receive the same first-frame observations and per-agent actions, so the student is trained to stay attached to the specified initial state and control signals rather than merely generate plausible video.
Implementation details matter here. The teacher and causal student are based on Cosmos-Predict2.5-2B with \(D=2048\), 28 transformer blocks, 16 attention heads, and head dimension 128. The RoPE partition is \((64,32,16,16)\) over \((t,p,h,w)\). The reported setup uses a simplex pool of size 4 over 2 active runtime slots during training; at each step it samples 2 of 4 vertices and permutes slot order, which is the mechanism that later allows up to 4 players at inference. Sparse Hub Attention uses \(K=8\) learnable global hub tokens per latent frame and a local window of 24 latent frames per view for bounded KV-cache memory.
At inference, the few-step student generates one latent block at a time with a 4-step denoising schedule and streams at 24 FPS according to the paper. The claim is plausible from the causal/KV-cache design, but the paper gives stronger quantitative support for quality and attention efficiency than for end-to-end FPS measurement.
Experiments And Results
The primary evaluation is on synchronized multi-agent Minecraft trajectories, with two-agent episodes as the main setting and four-agent scenes used to evaluate scaling. The paper reports FVD and FID for generation quality, LPIPS, PSNR, and SSIM for perceptual or pixel-level quality, and latency/FLOPs for attention scaling.
Comparison With Multi-Agent Baselines
| Method | Memory FVD | Memory FID | Grounding FVD | Grounding FID | Movement FVD | Movement FID | Building FVD | Building FID | Consistency FVD | Consistency FID |
|---|---|---|---|---|---|---|---|---|---|---|
| Frame concat | 450.6 | 69.8 | 528.3 | 63.2 | 556.9 | 65.0 | 551.8 | 87.3 | 576.0 | 123.2 |
| Solaris | 333.8 | 51.7 | 301.9 | 36.1 | 311.1 | 36.3 | 448.6 | 71.0 | 443.1 | 94.8 |
| \(\gamma\)-World | 184.1 | 24.8 | 199.3 | 24.0 | 191.5 | 21.2 | 264.5 | 32.1 | 280.0 | 46.9 |
Table 2. Baseline comparison. This table was recovered from latex_flattened/main.flattened.tex because the converted Markdown kept the table container but omitted the table body. Lower is better for all columns. It is the strongest evidence for C5: \(\gamma\)-World is best on every reported FVD/FID column across memory, grounding, movement, building, and consistency protocols.
The comparison also clarifies why the paper rejects frame concatenation. Concatenating views forces the model to compress multiple agents into one larger visual stream. \(\gamma\)-World instead preserves each agent stream and couples them through attention, which gives substantially lower FVD/FID in the reported test settings.
Architecture Ablation
| Setting | Composition | Agent encoding | Interaction | FVD | FID | LPIPS | PSNR | SSIM |
|---|---|---|---|---|---|---|---|---|
| Spatial Concat | Spatial concat | None | Full | 312.4 | 38.7 | 0.326 | 24.8 | 0.782 |
| Sequence Concat | Sequence concat | None | Full | 285.6 | 35.2 | 0.298 | 25.6 | 0.798 |
| View Embedding | Sequence concat | View emb. | Full | 256.3 | 32.4 | 0.281 | 26.4 | 0.815 |
| Simplex Encoding | Sequence concat | Simplex | Full | 228.5 | 29.6 | 0.265 | 27.5 | 0.830 |
| \(\gamma\)-World (Full) | Sequence concat | Simplex | Sparse Hub | 223.4 | 30.2 | 0.269 | 27.7 | 0.836 |
Table 3. Architecture ablation. The full model is best on FVD, PSNR, and SSIM, while simplex with dense full attention is slightly best on FID and LPIPS. The result supports the design direction but also shows a nuance: Sparse Hub Attention is not a free win on every quality metric relative to dense attention. Its strongest value is quality close to dense attention with much better scaling.
Sparse Hub Efficiency
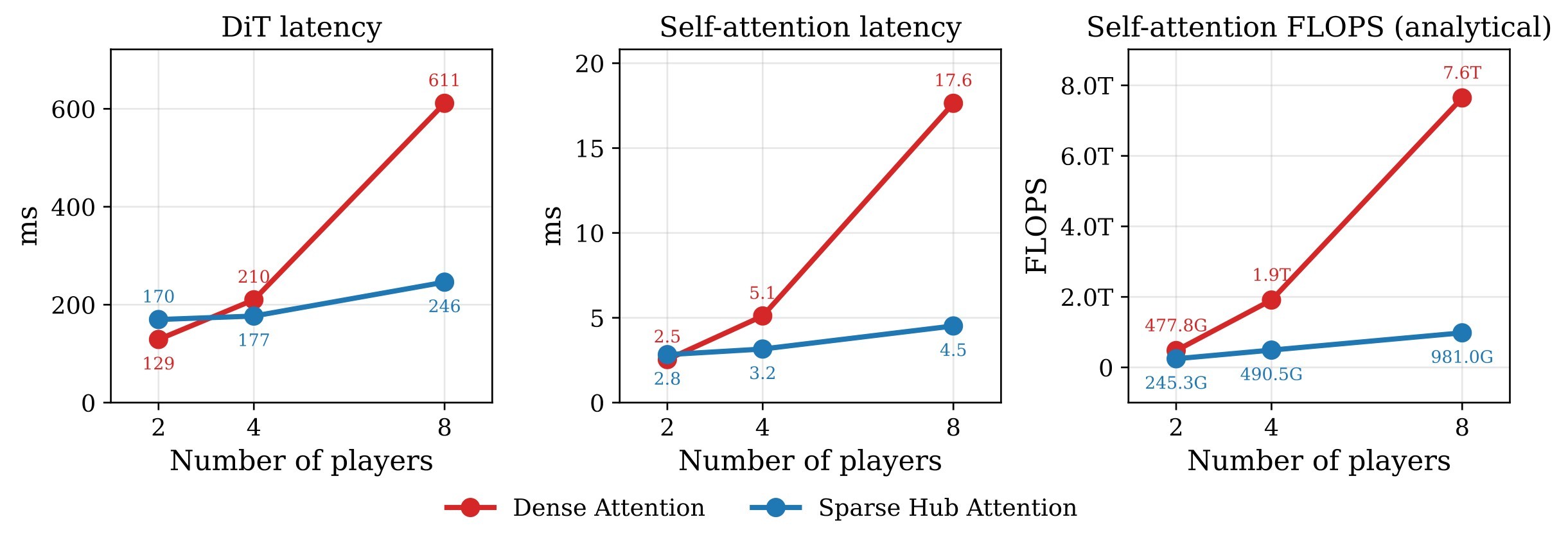
The paper states that latency is averaged over 3 full rollouts to 24 latent frames with full KV cache, while FLOPs are computed analytically from the average token sequence length over the 24-latent rollout. This supports C3 together with the cost equation.
Qualitative Multi-Agent Consistency


Real-World Robotics Examples

Additional Ablations
| Variant | FVD | FID | LPIPS | PSNR | SSIM |
|---|---|---|---|---|---|
| Bidirectional | 227.3 | 31.0 | 0.272 | 27.7 | 0.828 |
| Causal | 266.4 | 34.4 | 0.277 | 26.2 | 0.805 |
| Distilled | 239.7 | 30.9 | 0.273 | 26.8 | 0.811 |
Table 4. Training-stage comparison. The bidirectional teacher is best overall because it sees full context, but it cannot stream. The distilled model recovers much of the teacher quality while keeping causal generation, which supports the distillation recipe but also shows a quality gap versus the teacher.
| Hub tokens \(K\) | FVD | FID | LPIPS | PSNR | SSIM |
|---|---|---|---|---|---|
| 1 | 250.9 | 31.5 | 0.271 | 27.3 | 0.825 |
| 8 | 223.4 | 30.2 | 0.269 | 27.7 | 0.836 |
| 32 | 221.8 | 29.8 | 0.267 | 27.9 | 0.838 |
| 128 | 220.5 | 29.5 | 0.266 | 28.0 | 0.839 |
Table 5. Hub-token ablation. Larger \(K\) improves all reported quality metrics, but the paper chooses \(K=8\) in the main implementation. That choice appears to be a practical operating point: most of the quality gain over \(K=1\) is captured at \(K=8\), while larger hub counts trade more compute for smaller incremental gains.
Practical Takeaways
\(\gamma\)-World is most useful as a design pattern for interactive multi-agent simulators. The paper's strongest contributions are structural:
- Keep a real agent axis instead of spatially concatenating or flattening agents into one stream.
- Encode agent identity with a parameter-free simplex geometry when agents are exchangeable.
- Use hub-mediated attention when dense all-to-all cross-agent attention is too expensive.
- Distill a high-quality bidirectional generator into a causal student only after the causal model has learned stable multi-step rollout.
The strongest empirical result is the baseline table: the method is clearly better than frame concatenation and Solaris on the reported Minecraft protocols. The strongest theory-backed result is the simplex construction, which really does make pairwise agent distances equal in the rotary angle space. The most pragmatic result is Sparse Hub Attention: even when dense attention is slightly better on some ablation metrics, the hub design is the scalable option.
The main limitations are scope and enforcement. The evaluation is centered on gaming environments, with robotics shown qualitatively. The model does not explicitly enforce 3D geometry or physics, so long rollouts may still drift. The simplex pool can scale only within the allocated agent rotary band; very large populations would likely need larger bands or hierarchical grouping. For downstream use, I would treat \(\gamma\)-World as a strong architecture proposal for controllable multi-agent video simulation, not as proof that arbitrary large-agent physical simulation is solved.
Reference Coverage
- Additional local references for validation and navigation: evidence-action-conditioning, fig-four-agent, fig-method, fig-robotics, fig-sparse-hub-efficiency, fig-teaser.
- Additional local references for validation and navigation: fig-two-agent, table-action-formats, table-architecture-ablation, table-hub-token-ablation, table-method-comparison, table-variant-ablation.