Source-first digest for monthly 2026_05 checked paper rank 2, rank_id p002.
- Routing status:
pandoc_failed - PDF extraction: not used
Motivation / Background
Vision-Language-Action (VLA) models are attractive because they promise one perception, language, and control stack for many robot tasks. The paper argues that current systems miss practical deployment requirements: frontier policies are closed; open alternatives are often tied to costly embodiments; reasoning-augmented policies can be too slow for closed-loop control; and fine-tuned success rates are still brittle on realistic manipulation.
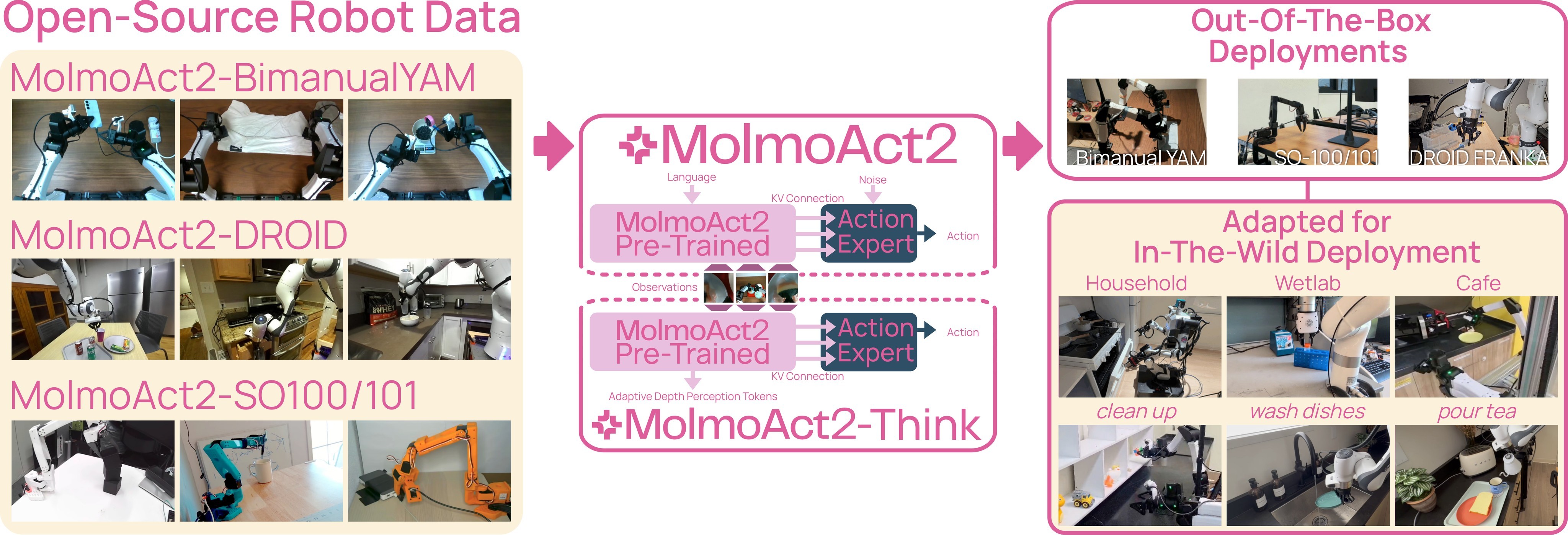
MolmoAct2 is presented as a fully open action reasoning model built around five changes: a stronger embodied-reasoning VLM backbone, new robot datasets for lower-cost platforms, an open multi-embodiment action tokenizer, a continuous action-expert architecture coupled to the VLM, and an adaptive depth-reasoning variant. Figure 1 gives the paper's broad deployment story: collect and curate data on Bimanual YAM, SO-100/101, and DROID Franka; train MolmoAct2 and MolmoThink; then evaluate out-of-the-box and fine-tuned behavior in real robot settings.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | MolmoAct2 is unusually open for a VLA system: the paper says it releases model weights, training code, tokenizer assets, and complete training datasets. | 4 | overview, data, OpenFAST |
| C2 | MolmoER is a stronger embodied-reasoning backbone than the compared open and API VLMs, and this transfers to action-token learning. | 5 | MolmoER, backbone ablation |
| C3 | The deployment data strategy covers useful low-to-medium-cost embodiments better than prior public robot data alone. | 4 | data, YAM setup, deployment limits |
| C4 | A DiT-style flow-matching expert with per-layer KV conditioning is the core architectural bridge from discrete VLM reasoning to continuous robot action. | 5 | architecture, key equations, conditioning ablation |
| C5 | The released embodiment-specific checkpoints work out of the box on the DROID and SO-100/101 settings evaluated in the paper. | 4 | zero-shot results, DROID trajectories, SO-100 trajectories, deployment limits |
| C6 | Fine-tuning MolmoAct2 is competitive or best among strong baselines on LIBERO, RoboEval, and real-world Bimanual YAM tasks. | 4 | fine-tuning results, RoboEval, YAM results |
| C7 | MolmoThink adds useful adaptive depth reasoning, but its benefits are incremental and its speed remains below plain MolmoAct2. | 4 | MolmoThink, depth ablation, speed |
| C8 | The deployment claim is bounded: action chunks are executed open-loop, and zero-shot deployment is tied to the three large-data embodiments. | 5 | limitations |
Support scores are paper-internal support scores, not independent reproduction scores. I score broad deployment claims below 5 when the evidence is strong but limited to the authors' selected embodiments, data, hardware, or evaluation protocols.
Core Technical Idea
MolmoAct2 keeps a VLM-style autoregressive interface for perception, language, state tokens, setup/control descriptors, and discrete action tokens, but adds a separate continuous controller for deployment. The central design is:
1. Use MolmoER as the embodied/spatial reasoning backbone. 2. Use OpenFAST to make continuous robot trajectories trainable as compact discrete tokens during pre-training. 3. Attach a flow-matching action expert after the backbone has already learned robot-aware action tokens. 4. Feed the action expert the VLM's layerwise key/value attention state rather than only the final hidden state. 5. Optionally add MolmoThink, which predicts depth tokens before action and reuses unchanged depth cells across timesteps.
For a normalized target action chunk \(a\), Gaussian noise \(\epsilon\), and time \(t \in [0,1]\), the action expert trains on the straight-line flow from noise to data:
The expert predicts the velocity field from the noisy action chunk and VLM context \(c\):
where \(m\) masks padded timesteps and padded action dimensions. During post-training, multiple sampled noise levels are evaluated for the same robot action chunk:
The post-training objective keeps the discrete VLM action interface alive while fitting continuous actions:
Method Details
Data And Openness
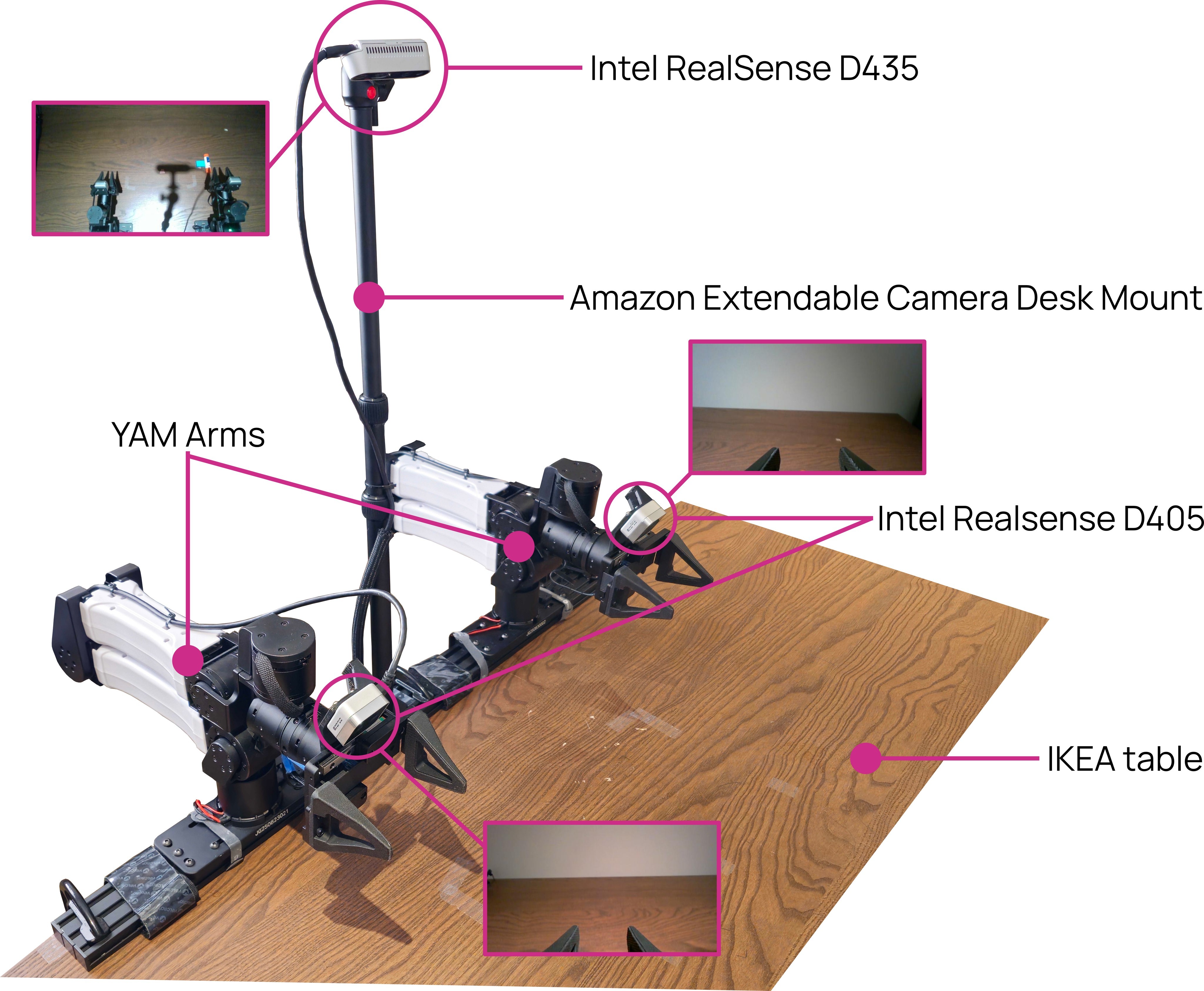
The training data is not just "more robot data"; it is a targeted mixture for practical deployment. Figure 2 summarizes the paper's data sources. The three new or curated deployment-focused corpora are:
- MolmoAct2-BimanualYAM Dataset: 34.5K demonstrations, more than 720 hours, more than 28 real-world bimanual tasks, collected over two months on the authors' YAM setup.
- MolmoAct2-SO100/101 Dataset: curated from 1,222 public LeRobot datasets contributed by 377 users, yielding 38,059 episodes, 19.8M frames, and about 184 hours after structural, license, and quality filtering.
- MolmoAct2-DROID Dataset: a filtered DROID subset with 74,604 valid episodes and 17,758,044 frames, using extended language annotations and an idle-frame filter.
The paper also re-annotates robot language instructions with a VLM pipeline, reporting that unique labels increase from 71,121 to 146,485. This matters because action policies often overfit repeated task names rather than learning robust instruction grounding.

Figure 3 is included because the paper's "deployable" claim depends on concrete lower-cost robot setups rather than only high-end lab robots.
MolmoER Backbone
MolmoER is a Molmo2-based VLM specialized for embodied reasoning. Its added 3.3M-sample corpus spans image embodied QA, image pointing, image detection, video embodied QA, multi-image/ego-exo correspondence, and abstract embodied reasoning. The paper trains it with a specialize-then-rehearse recipe: 20K steps of embodied specialization, then 1.5K refinement steps mixing embodied and general multimodal data.
| Model | Open? | Overall embodied-reasoning average |
|---|---|---|
| Gemini Robotics ER 1.5 Thinking | API only | 61.3 |
| GPT-5 | API only | 57.9 |
| Qwen3-VL-8B | Open weights | 61.0 |
| Molmo2 | Open weights/data/code | 46.8 |
| MolmoER | Open weights/data/code | 63.8 |
Table 1. MolmoER result summary. The source table reports 13 benchmarks. MolmoER has the highest overall average and is reported as best on 9 of 13 benchmarks. The action-learning ablation later shows MolmoER also improves LIBERO Long discrete-action success from 77.6% to 83.6%.
OpenFAST Action Tokenizer
MolmoAct2 uses OpenFAST to turn one second of continuous robot action into a compact discrete sequence. The tokenizer represents actions with a frequency-domain transform, quantizes coefficients, and applies byte-pair encoding over a 2048-token action vocabulary. Before tokenization, actions are padded to 32 dimensions and normalized with 1-99 percentile statistics; gripper commands are handled separately.
| Dataset | Mix | Robot | Action representation |
|---|---|---|---|
| MolmoAct2-BimanualYAM | 30% | YAM | Absolute joint |
| MolmoAct2-SO100/101 | 30% | SO-100/101 | Absolute joint |
| MolmoAct2-DROID | 30% | Franka | Absolute joint |
| Fractal | 3.33% | Google Robot | Delta end-effector |
| BC-Z | 3.33% | Google Robot | Delta end-effector |
| Bridge | 3.33% | WidowX | Delta end-effector |
Table 2. OpenFAST training mixture. This supports the reproducible-tokenizer claim: the tokenizer is open and its action mixture is specified.
VLM Plus Continuous Action Expert
Figure 4 is the most important method figure. MolmoAct2 first adapts MolmoER into an action-aware VLA with discrete action tokens. Post-training then attaches a DiT-style action expert with the same depth as the VLM. The action expert predicts continuous action chunks with flow matching while the VLM still receives next-token supervision over discrete action tokens.
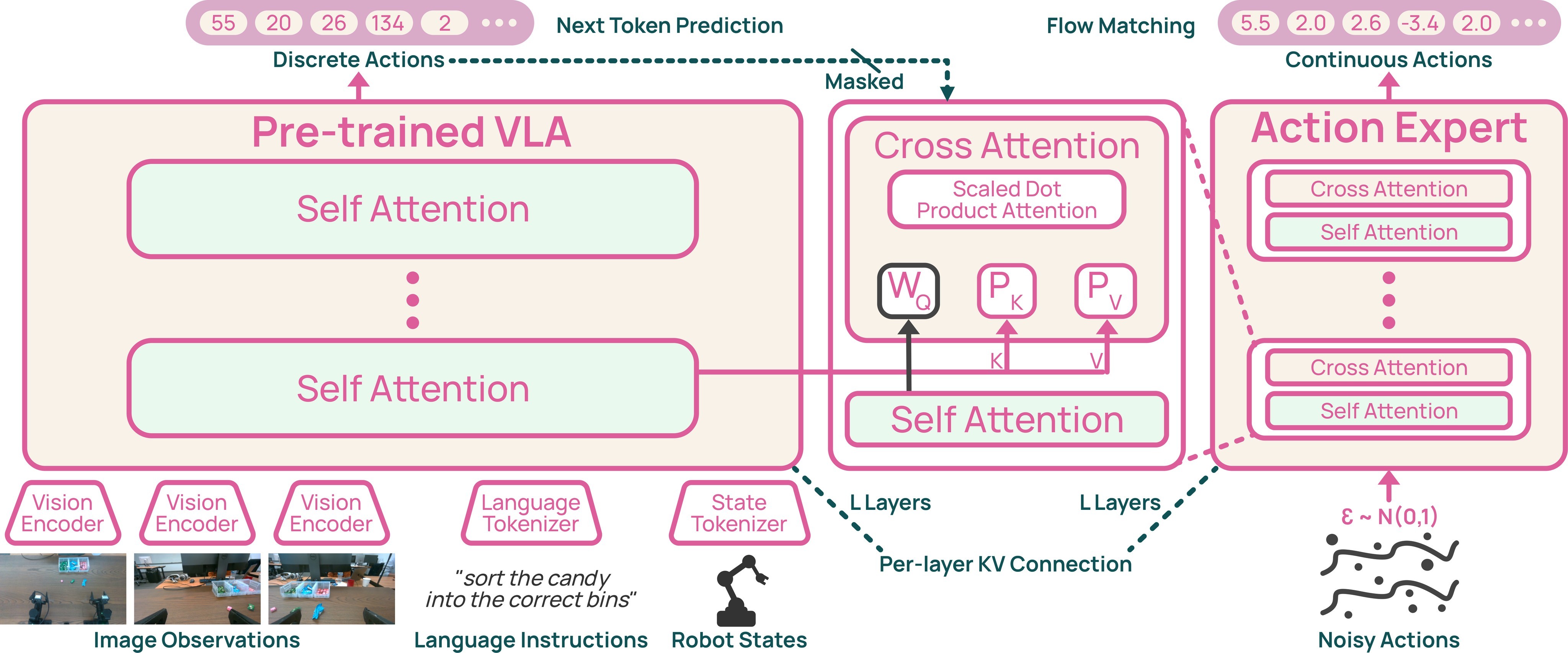
The action expert has 36 transformer blocks, matching the VLM's 36 layers. The model appendix reports a 4.0B LLM, 380M image encoder, 57M vision-language connector, and 621M action expert. The expert predicts up to 30 action steps and up to 32 action dimensions. At inference, the released checkpoints use 10 Euler integration steps:
Per-layer KV conditioning is the distinctive bridge. For VLM layer \(\ell\), the projected keys and values are:
The expert block then cross-attends to the corresponding VLM layer state:
This design is meant to avoid compressing all visual-language grounding into a final hidden state. The flow loss updates the expert and VLM-to-expert adapters; during post-training the conditioning tensors are detached so the continuous-action loss does not back-propagate through the VLM.
MolmoThink: Adaptive Depth Reasoning
MolmoThink adds a depth-token prefix before action generation. Each observation depth map is quantized into a \(10 \times 10\) grid, so the model predicts 100 depth positions, each from 128 learned depth codes. The goal is to keep the interpretability and spatial grounding of depth reasoning without regenerating all 100 depth codes at every control step.
Figure 5 shows the mechanism: unchanged depth cells are replayed from a cache, while only changed regions are regenerated.
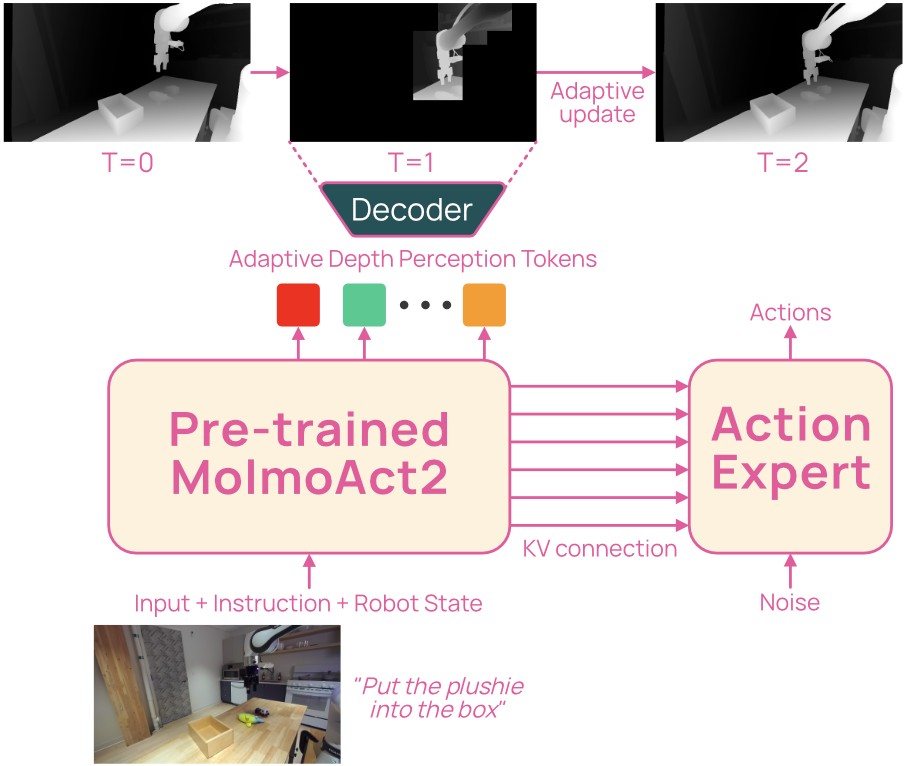
The update rule compares \(32 \times 32\) RGB patches in the same \(10 \times 10\) grid. A cell is updated when cosine similarity falls below 0.996:
The fine-tuned depth model also learns how much each action-expert layer should use depth-token keys and values. The gate is computed from non-depth context:
and then applies only to depth-token keys and values:
Experiments And Results
The experimental section is broad: embodied-reasoning VLM benchmarks, out-of-the-box deployment, fine-tuning on new tasks and embodiments, MolmoThink depth effects, robustness under perturbations, trajectory-quality diagnostics, component ablations, and inference speed.
Out-Of-The-Box Deployment
The out-of-the-box claim is strongest for the embodiments where the paper has large-scale training data: DROID Franka and SO-100/101. The summary in Table 3 combines the main zero-shot tables and text.
| Setting | MolmoAct2 checkpoint | Strongest reported baseline | Main result |
|---|---|---|---|
| MolmoSpaces simulation | MolmoAct2-DROID | \(\pi_{0.5}\)-DROID | 37.7 average vs 34.5 |
| MolmoBot simulation held-out envs | MolmoAct2-DROID | \(\pi_{0.5}\)-DROID | 20.6 average vs 10.0 |
| Real-world DROID kitchen tasks | MolmoAct2-DROID | MolmoBot | 87.1% average vs 48.4% |
| Real-world SO-100 tasks | MolmoAct2-SO100/101 | DePi/\(\pi_0\)-SO100/101 | 56.7% average vs 45.3% |
Table 3. Out-of-the-box deployment summary. The strongest real-world number is the DROID setup: MolmoAct2 is reported at 87.1% average across five tasks with unseen objects and random camera initialization. SO-100 is more mixed: MolmoAct2 leads four of five tasks but loses "Place block in box" to DePi/\(\pi_0\).
Figure 6 and Figure 7 show the real-world trajectory examples attached to those zero-shot evaluations.


Fine-Tuning For New Tasks
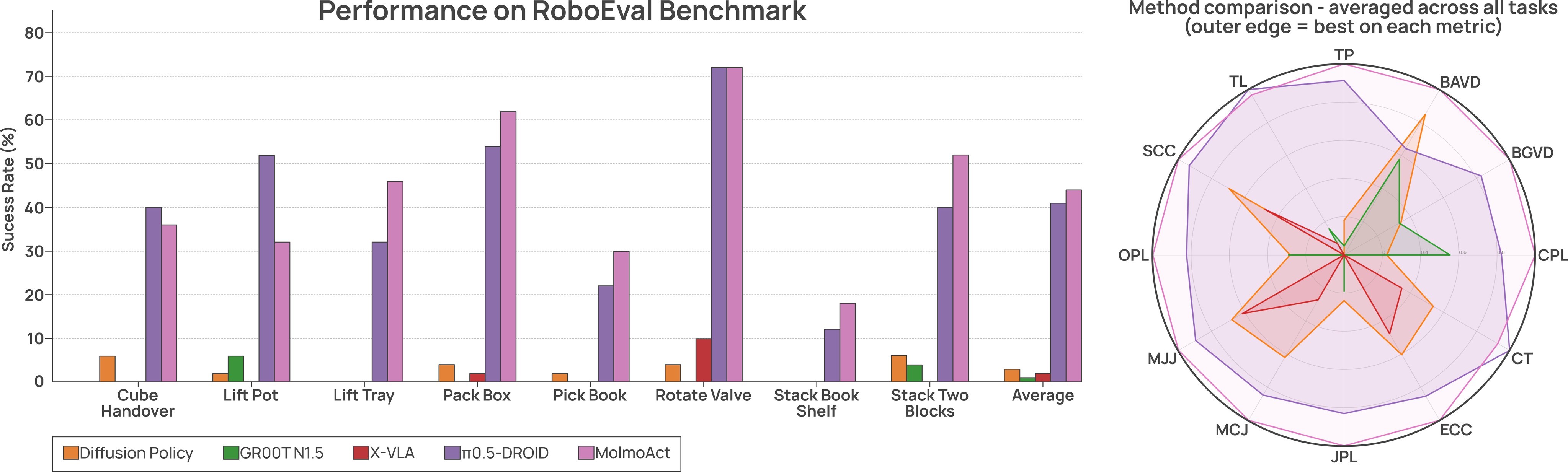
The fine-tuning evidence covers simulation and real robots. On LIBERO, MolmoAct2 reaches 97.2% average and MolmoThink reaches 98.1%. On RoboEval, the main text reports MolmoAct2 at 44.3%, 3.8 points above \(\pi_{0.5}\). On the real-world Bimanual YAM suite, MolmoAct2 averages 50.6% and leads 7 of 8 tasks.
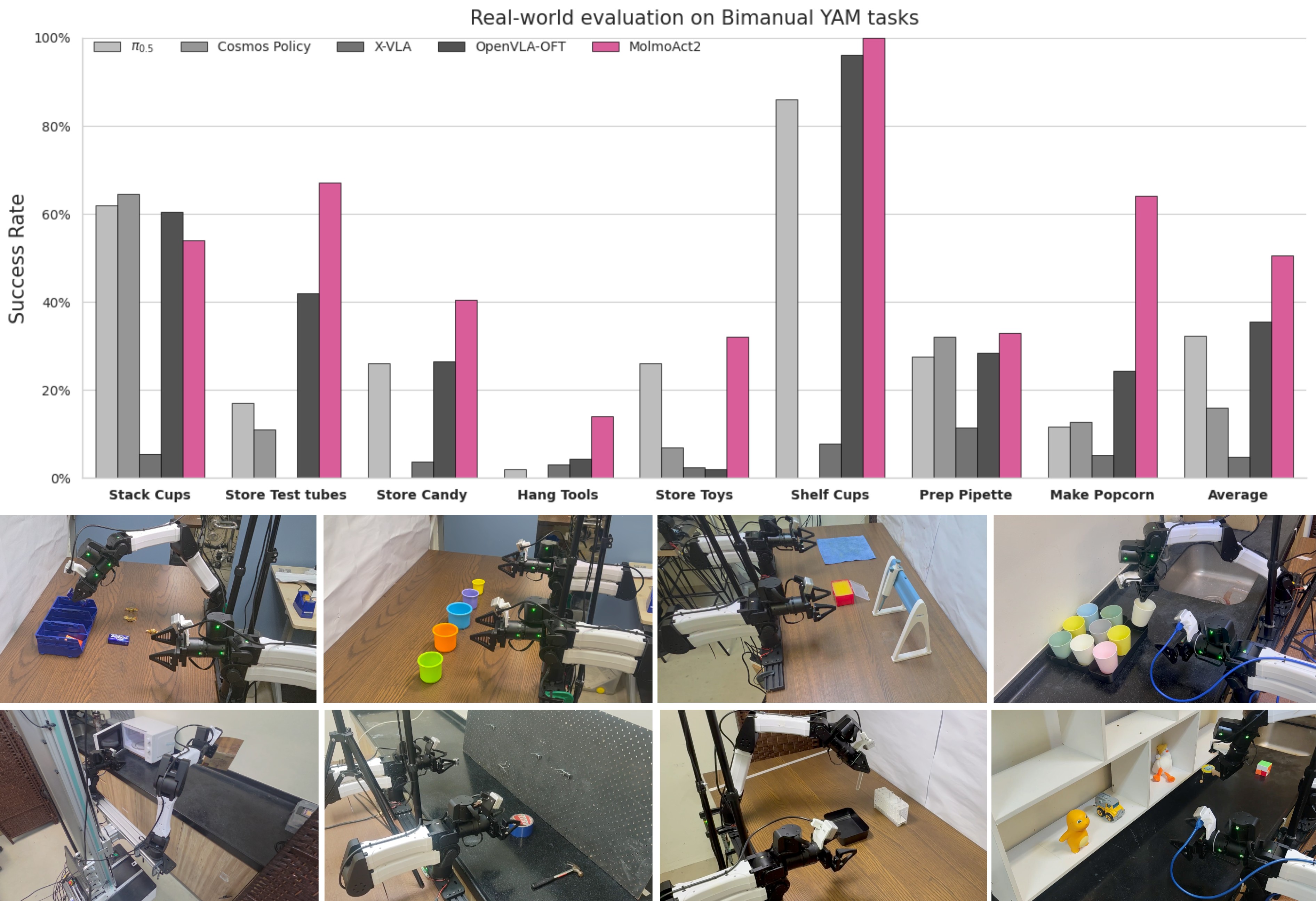
| Task | \(\pi_{0.5}\) | Cosmos | X-VLA | OpenVLA | MolmoAct2 |
|---|---|---|---|---|---|
| Cup Stacking | 62.0 | 64.5 | 5.5 | 60.5 | 54.0 |
| Linearbot | 11.6 | 9.2 | 5.2 | 24.4 | 64.0 |
| Pegboard | 2.0 | 0.0 | 3.0 | 4.5 | 14.0 |
| Cup Storing | 85.9 | 0.0 | 7.9 | 96.0 | 100.0 |
| Candy Storing | 26.0 | 0.0 | 3.8 | 26.5 | 40.5 |
| Store Test Tube | 17.0 | 11.0 | 0.0 | 42.0 | 67.0 |
| Store Toys | 26.0 | 7.0 | 2.5 | 2.0 | 32.0 |
| Prepare Pipette | 27.5 | 32.0 | 11.5 | 28.5 | 33.0 |
| Average | 32.2 | 15.5 | 4.9 | 35.5 | 50.6 |
Table 4. Real-world Bimanual YAM results. Each task uses 50 episodes. MolmoAct2 leads seven tasks; Cosmos leads Cup Stacking. The broad result is strong, but the absolute average is still only about half of trials, so this is evidence of progress rather than solved deployment.
Robustness And Trajectory Quality
The OOD robustness study fine-tunes four Bimanual YAM tasks and evaluates spatial variation, lighting shifts, language rephrasing, and distractors. MolmoThink is reported as best in every perturbation group:
| Model | Spatial var. | Lighting | Language | Distractor | Overall |
|---|---|---|---|---|---|
| \(\pi_{0.5}\) | 15.00 | 33.70 | 26.15 | 33.20 | 27.01 |
| Cosmos Policy | 8.75 | 17.50 | 5.00 | 13.75 | 11.25 |
| X-VLA | 3.75 | 8.30 | 9.95 | 3.75 | 6.44 |
| OpenVLA-OFT | 13.75 | 46.25 | 51.25 | 48.30 | 39.89 |
| MolmoThink | 26.25 | 62.05 | 60.35 | 54.10 | 50.69 |
Table 5. Robustness under perturbations. The largest weakness remains spatial variation: even MolmoThink reaches only 26.25%.
The trajectory-quality analysis goes beyond binary success on RoboEval. The paper reports that, on Stack Two Blocks, MolmoAct2 reduces completion time to 4.70s versus 5.87s for \(\pi_{0.5}\) and 7.27s for Diffusion Policy, while reducing joint path length from 2.16 to 1.04. On Rotate Valve, it reports the lowest completion time, 8.51s versus 9.69s for \(\pi_{0.5}\).
Systematic Ablations
The ablations are useful because they tie the headline performance back to specific design choices.
| Design question | Best reported choice | Evidence |
|---|---|---|
| Does embodied reasoning help action learning? | MolmoER backbone | LIBERO Long discrete-action success: 83.6% vs 77.6% for Molmo2 |
| How should the expert receive VLM context? | Per-layer KV conditioning | LIBERO average: 95.9% vs 94.8% per-head KV and 94.0% hidden-state |
| How many flow samples during fine-tuning? | \(K=8\) | LIBERO average: 95.90% vs 94.15% for \(K=1\) |
| What fine-tuning style works best? | Full fine-tuning with discrete co-training, no knowledge insulation | LIBERO average: 97.20%; action-expert-only drops to 93.05% |
| What helps MolmoThink? | Mixed training plus noise injection plus depth gate | LIBERO average: 98.10% vs 97.50% without all three |
Table 6. Ablation summary. The strongest architectural support is for per-layer KV conditioning. The depth pathway's gain is real but smaller: 98.10% vs 97.50% in the depth-training ablation and 98.1% vs 97.2% in the main LIBERO comparison.
Inference Speed
Figure 10 and Table 7 show why the paper separates continuous action generation from discrete token decoding. MolmoAct2's continuous expert can emit an action chunk much faster than the discrete action path.
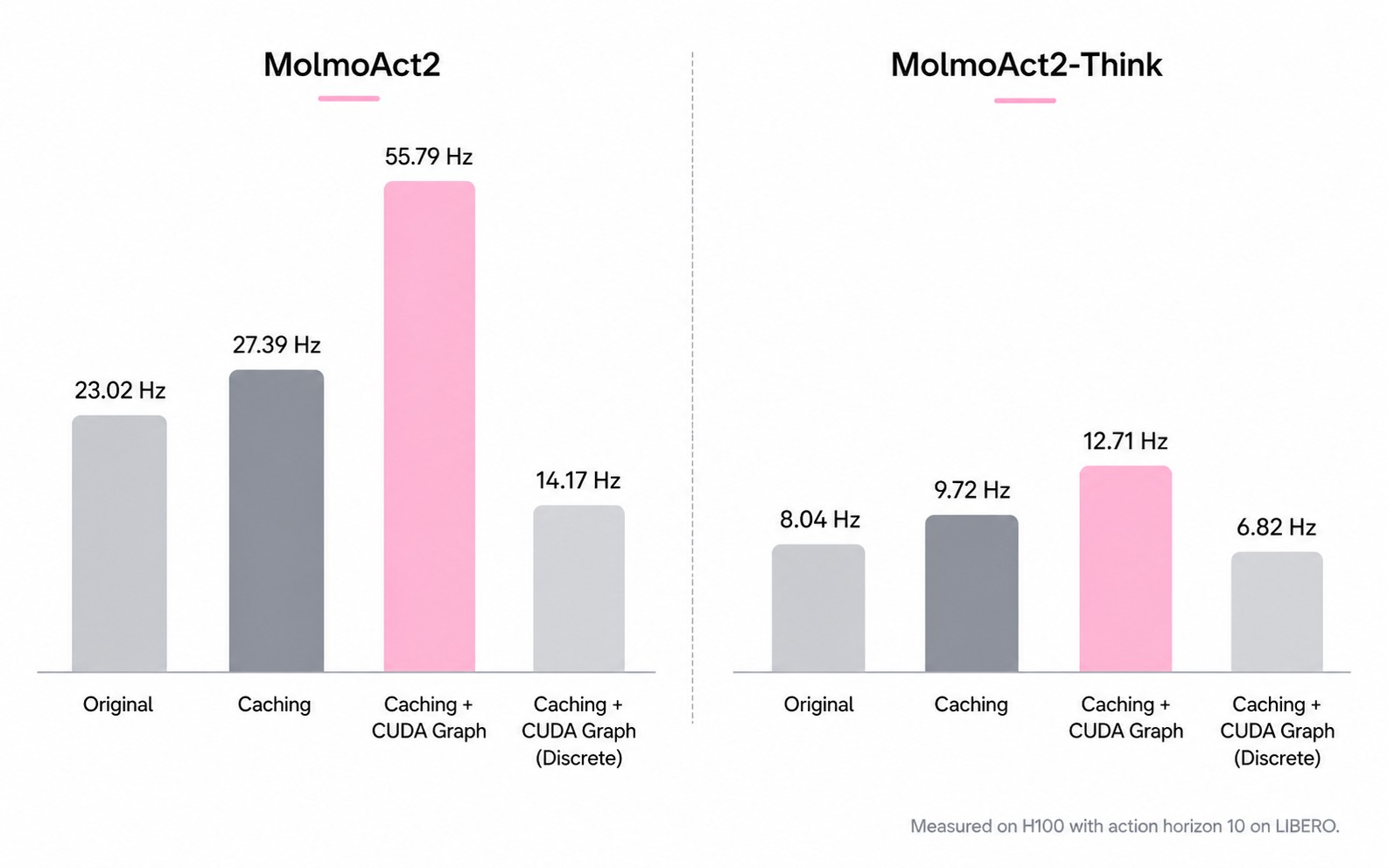
| Model/path | Original | Cache optimized | CUDA Graph optimized | Notes |
|---|---|---|---|---|
| MolmoAct2 continuous | 23.02 Hz | 27.39 Hz | 55.79 Hz | 2.42x over original |
| MolmoThink continuous | 8.04 Hz | 9.72 Hz | 12.71 Hz | 1.58x over original |
| MolmoAct2 discrete action path | - | - | 14.17 Hz | 3.94x slower than continuous MolmoAct2 |
| MolmoThink discrete action path | - | - | 6.82 Hz | 1.86x slower than continuous MolmoThink |
Table 7. Inference speed summary. MolmoThink improves reasoning efficiency relative to dense depth-token regeneration, but it is still slower than plain MolmoAct2 because it must autoregressively produce or replay depth tokens.
Limitations
The limitations section is unusually relevant for deployment:
- MolmoAct2 predicts fixed-horizon action chunks and executes each chunk open-loop before re-querying the policy. The reported 55.79 Hz is amortized chunk throughput, not within-chunk feedback control.
- The flow-matching expert does not enforce smoothness across chunk boundaries, so velocity or acceleration discontinuities can appear when consecutive chunks are generated independently.
- Zero-shot deployment is tied to the three large-data embodiments: Bimanual YAM, SO-100/101, and DROID Franka. New robots still need target-embodiment demonstrations and fine-tuning.
- The strongest real-world results still leave substantial failure rates in difficult settings, especially spatial perturbations and the Bimanual YAM average success rate.
Practical Takeaways
MolmoAct2 is most important as an open, inspectable recipe for VLA deployment rather than as a universal robot controller. The recipe says: specialize the VLM on embodied spatial reasoning, build transparent robot datasets around real deployable platforms, use a discrete action tokenizer for scalable pre-training, and then attach a continuous flow-matching expert for practical control.
The strongest technical idea is per-layer KV conditioning. It gives the continuous controller access to VLM attention state at every depth, and the paper backs this with a direct ablation. If reproducing or extending the work, this is a higher-priority component than cosmetic changes to prompts or output formatting.
MolmoThink is useful when spatial grounding and interpretability matter, especially under perturbations, but it is not free. It improves LIBERO and robustness results, yet its optimized control rate is much lower than plain MolmoAct2. For time-critical control, the continuous MolmoAct2 path is the default; for diagnosis or depth-sensitive tasks, MolmoThink is the more interpretable option.
The deployment boundary is explicit: MolmoAct2 is not a robot-agnostic zero-shot policy. It is a strong open model family for the embodiments where the released data exists, plus a fine-tuning recipe for adapting to new tasks and robots.
Reference Coverage
- Additional local references for validation and navigation: evidence-robustness, fig-yam-real, table-molmoer-results, table-openfast.