Source-first digest for monthly checked paper rank 11, rank_id p004.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
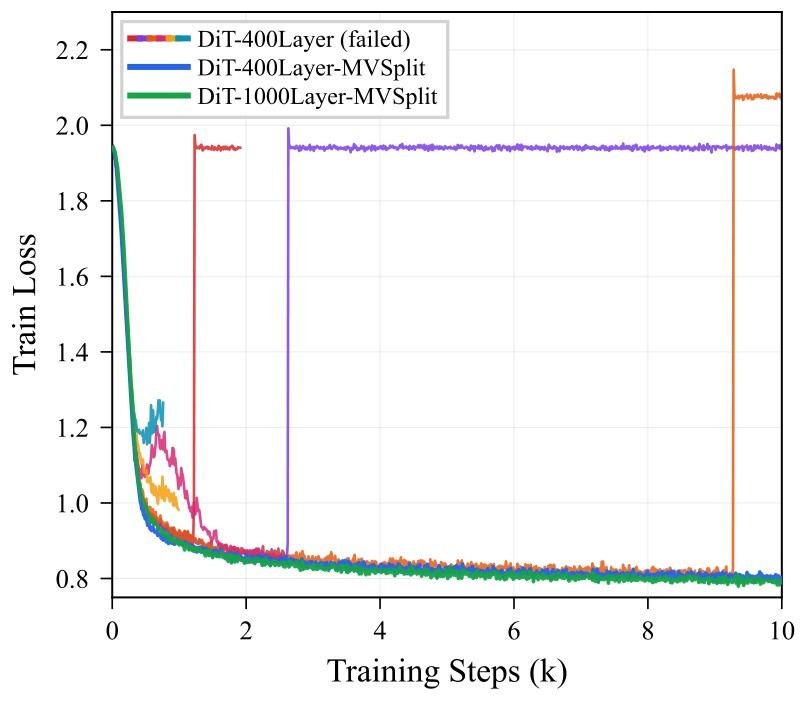
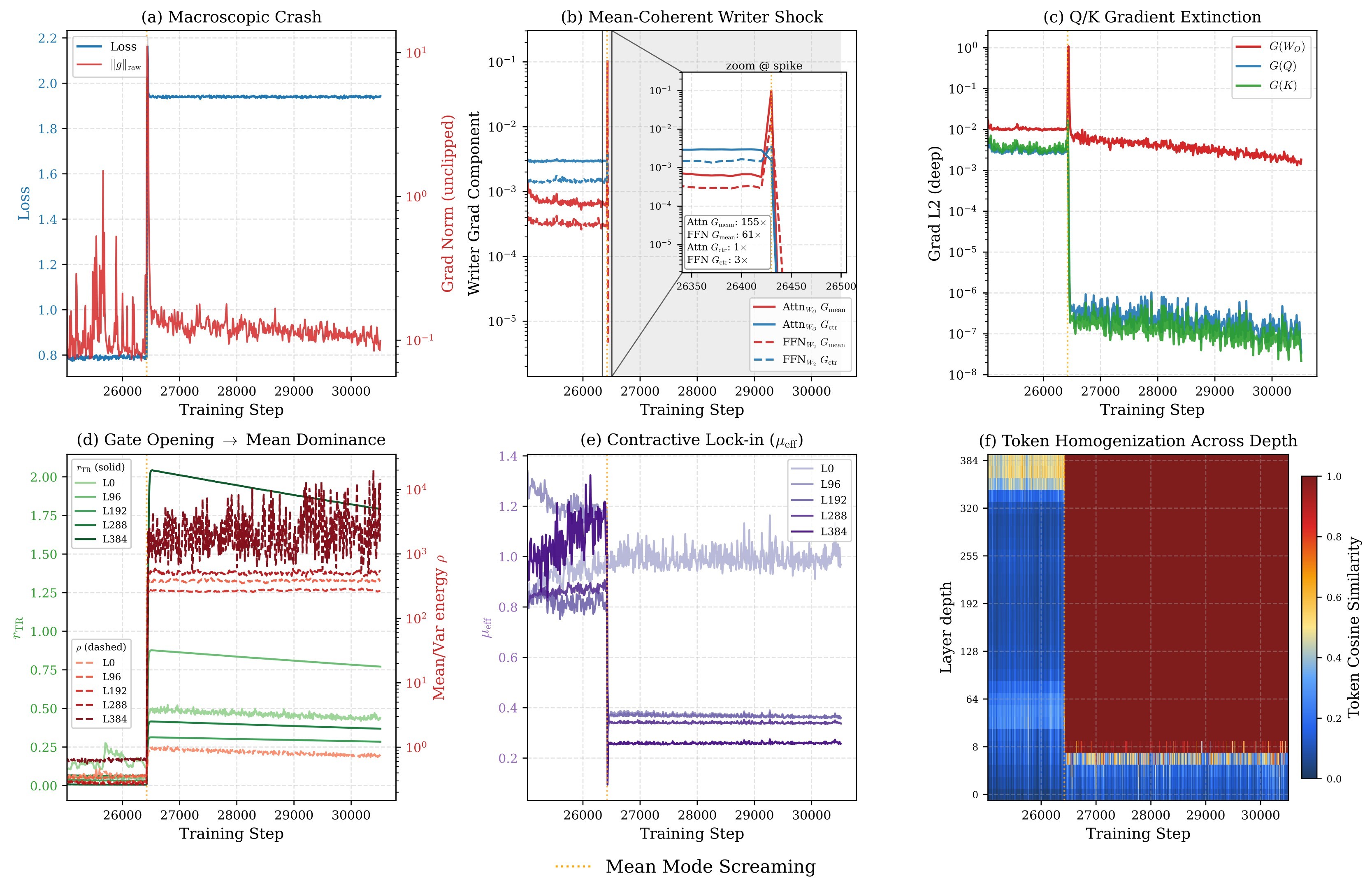
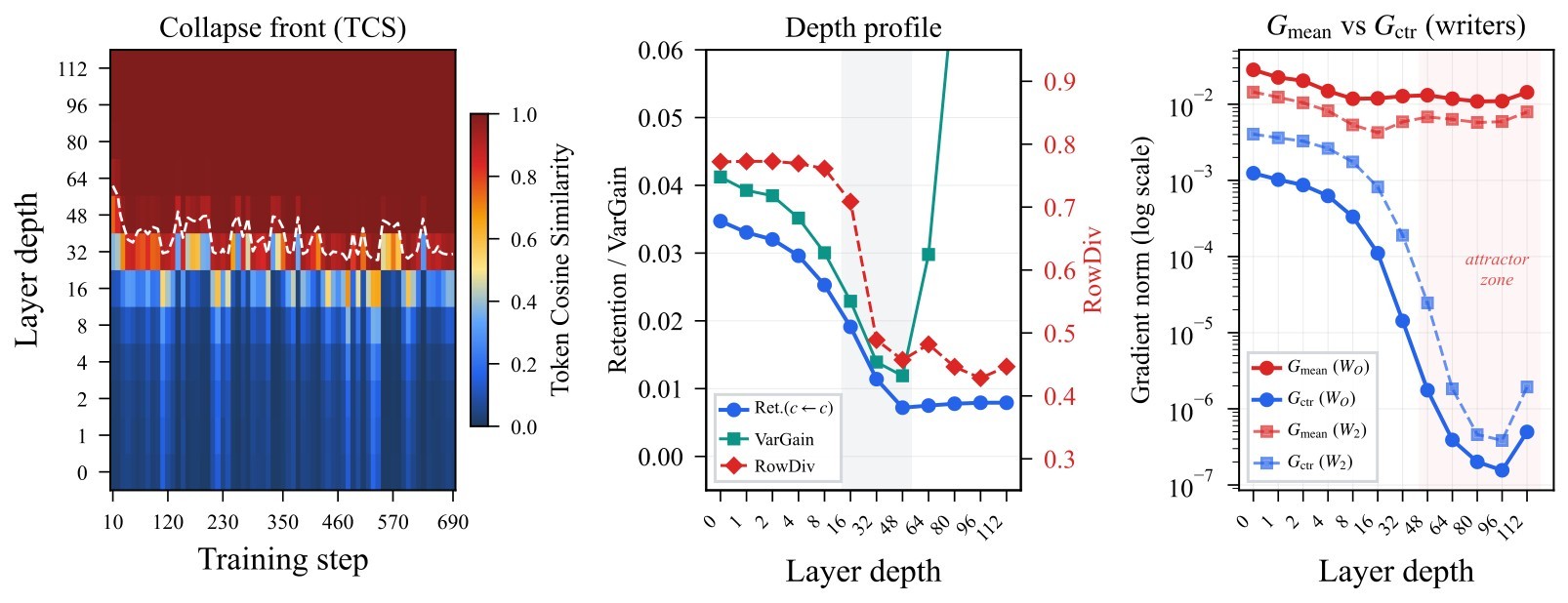
Very deep Diffusion Transformers promise more capacity, but this paper argues that depth also exposes a residual-stream failure mode that ordinary exploding-gradient or vanishing-gradient language does not describe well. The observed runs can look numerically healthy for thousands of steps, then rapidly collapse without NaNs or obvious forward saturation. The collapsed state is mean-dominated: token representations become nearly homogeneous and centered token variation is starved.
The paper names the abrupt entry event Mean Mode Screaming (MMS). MMS is defined by a mean-coherent writer-gradient shock, rapid opening of deep residual branches, and suppression of Q/K learning after values homogenize. That makes the paper less about a new image generator recipe and more about a mechanism for why ultra-deep Post-Norm DiTs can become unstable.
The proposed fix is Mean-Variance Split (MV-Split) Residuals: instead of applying one residual gain to the whole branch, the merge separates the sequence-mean component from centered token variation. The mean path is damped with a leaky replacement, while the centered path keeps an independent gain. This is meant to stabilize the dangerous mean-coherent writer channel without globally shrinking the feature-learning signal.

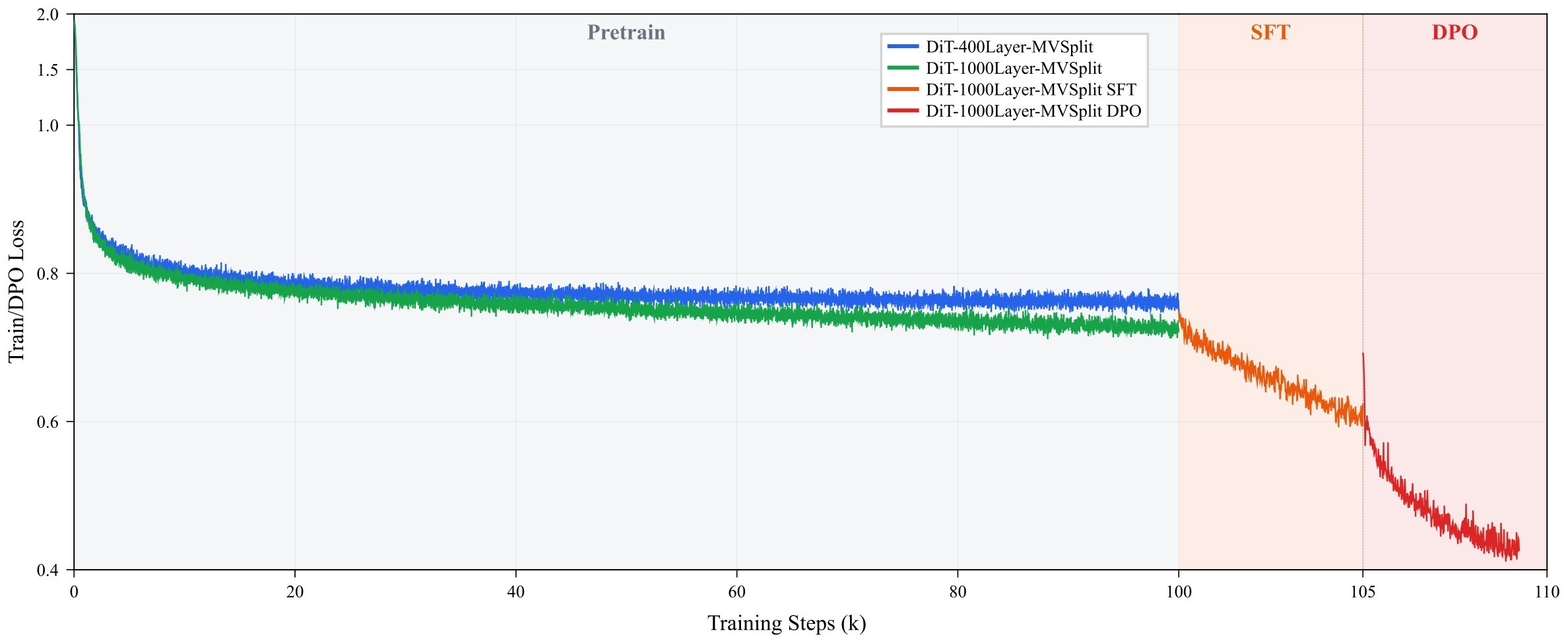
The target use case is still visual generation. The training/evaluation setup is ImageNet-2012 latent diffusion with a frozen FLUX.2 VAE and frozen Qwen3-0.6B text encoder for the matched 400-layer comparison, plus a separate 1000-layer MV-Split run as a boundary-scale validation. See the training setup and frontier results for how much of the evidence is controlled.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Ultra-deep DiTs can enter a mean-dominated collapse state that is distinct from ordinary NaN-style failure. | 5 | problem framing, MMS trace, diagnostic metrics, standard-init control |
| C2 | The mechanism is a residual-writer subspace failure: mean-coherent gradients stop canceling, can scale with token count, and Q/K gradients are then suppressed by the Softmax null space. | 4 | mechanism equations, Softmax null-space lemma, alignment-law audit, MMS trace figure |
| C3 | MV-Split Residuals target the failure channel more directly than LayerScale/ReZero because they give separate gains to centered and mean components. | 5 | MV-Split equations, writer-gradient mode figure, negative controls |
| C4 | In the matched 400-layer comparison, MV-Split is the best stable frontier point among the reported stabilizers. | 5 | frontier table, main result curves, writer-gradient control |
| C5 | The 1000-layer MV-Split run is valid as scale validation, but not as a matched quality comparison against the 400-layer controls. | 4 | teaser samples, training configuration, frontier table, calibration table |
| C6 | The token mean should be gain-limited rather than removed, because it also carries useful global/timestep information. | 4 | timestep probe, MV-Split method, failed hard-centering controls |
| C7 | Attention-only or scalar-norm fixes are insufficient in this setting because they do not implement a local token-subspace split at the residual interface. | 3 | negative controls, attention/FFN relocation note, MV-Split equations |
| C8 | The mechanism may matter more for long spatiotemporal generators, but that extension is a future-work hypothesis rather than demonstrated evidence. | 2 | limitations, writer-gradient decomposition |
Support scores are support-from-paper scores, not reproduction scores. Math/proof-backed and table-backed claims receive higher scores; extension claims and appendix-only negative controls are capped lower.
Core Technical Idea
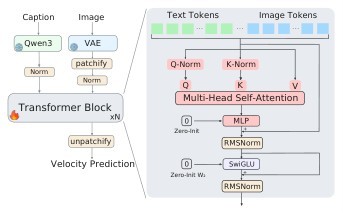
The geometric split starts with projectors over the token axis:
where \(J\) extracts the token mean and \(P=I-J\) extracts centered variation. For a row-stochastic attention matrix \(A\), pure-mean states are preserved while centered states are governed by the restricted operator \(PAP\):
This asymmetry is the core setup. If deep attention becomes contractive on the centered subspace and residual writers stop replenishing centered variation, the model can drift toward a homogeneous token state. The forward state then supports the backward failure: token-aligned residual-writer gradients no longer cancel across sequence positions.
| Diagnostic | Meaning in this digest | Why it matters |
|---|---|---|
| Writer GMD: \(G_{\text{mean}}, G_{\text{ctr}}\) | Frobenius norms of the mean-coherent and centered writer-gradient components. | Separates dangerous mean writes from feature-learning centered writes. |
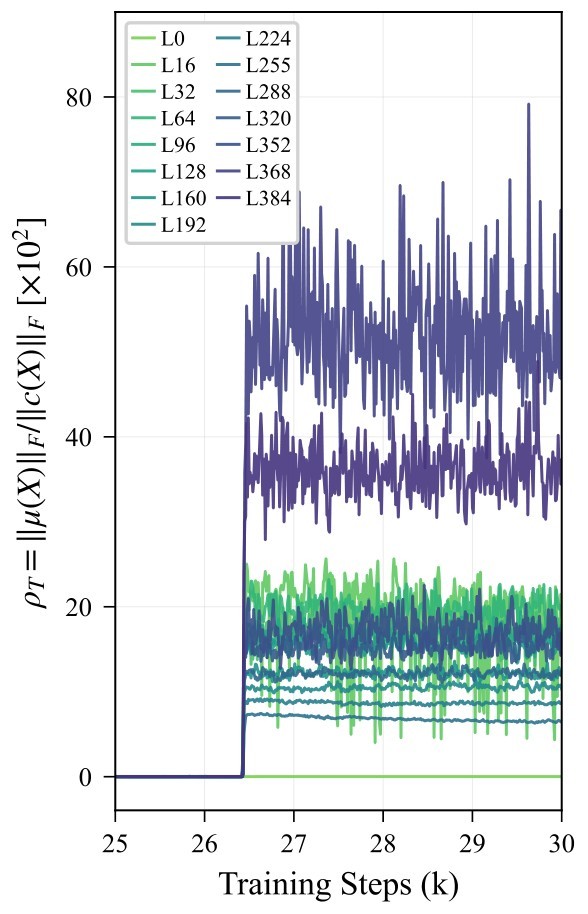
| Energy ratio: \(\rho_T\) | Mean energy divided by centered energy in token representations. | Large values indicate mean-dominated residual streams. |
| Token cosine similarity (TCS) | Average pairwise token cosine similarity. | High values indicate token homogenization. |
| Centered retention | Fraction of centered input energy retained by attention. | Low values show why residual branches must replenish centered variation. |
| Row diversity | Deviation of attention rows from a shared profile. | Helps rule out the simplistic "all rows identical" explanation. |
Table 1. Diagnostic glossary. This condenses the paper's diagnostic table to the quantities used in the digest. The full source table also defines Q/K gradient norm, TR ratio, variance gain, attention contraction, and mean leakage.
Method Details
For a token-wise residual writer \(W\), such as attention output \(W_O\) or FFN output \(W_2\), the gradient can be decomposed exactly:
The mean term is small when sequence means cancel. Once forward states and adjoints align, \(\bar y\) and \(\bar \delta\) become order-one and the rank-1 mean mode can enter a coherent \(O(T)\) regime. The paper calls the sharp transition into this regime Mean Mode Screaming.
The alignment-amplification identity makes this measurable:
The lock-in argument then uses a Softmax null-space fact: if value vectors are homogeneous, \(V_j=\bar v\), then the attention-logit gradient vanishes for one row because the Softmax Jacobian kills the constant direction. Under approximate homogeneity, this removes the constant component and strongly suppresses Q/K learning. Residual-writer gradients are not zeroed in the same way, so the already-dangerous writer path remains active while attention loses a route for restoring token variation.
MV-Split changes the residual interface. Let \(F_l=f_l(X_l)\) be the branch output. The standard Post-Norm merge is replaced by:
Projecting the pre-normalized merge gives:
The centered path behaves like a residual update with gain \(\beta\). The mean path is a leaky integrator: each layer contracts the carried trunk mean by \(1-\alpha\) before adding a fresh mean correction. The backward split mirrors the same design:
This is the key distinction from LayerScale/ReZero. A single scalar or feature gain shrinks mean and centered components together. MV-Split can keep centered branch gradients high while damping the mean-coherent writer component.
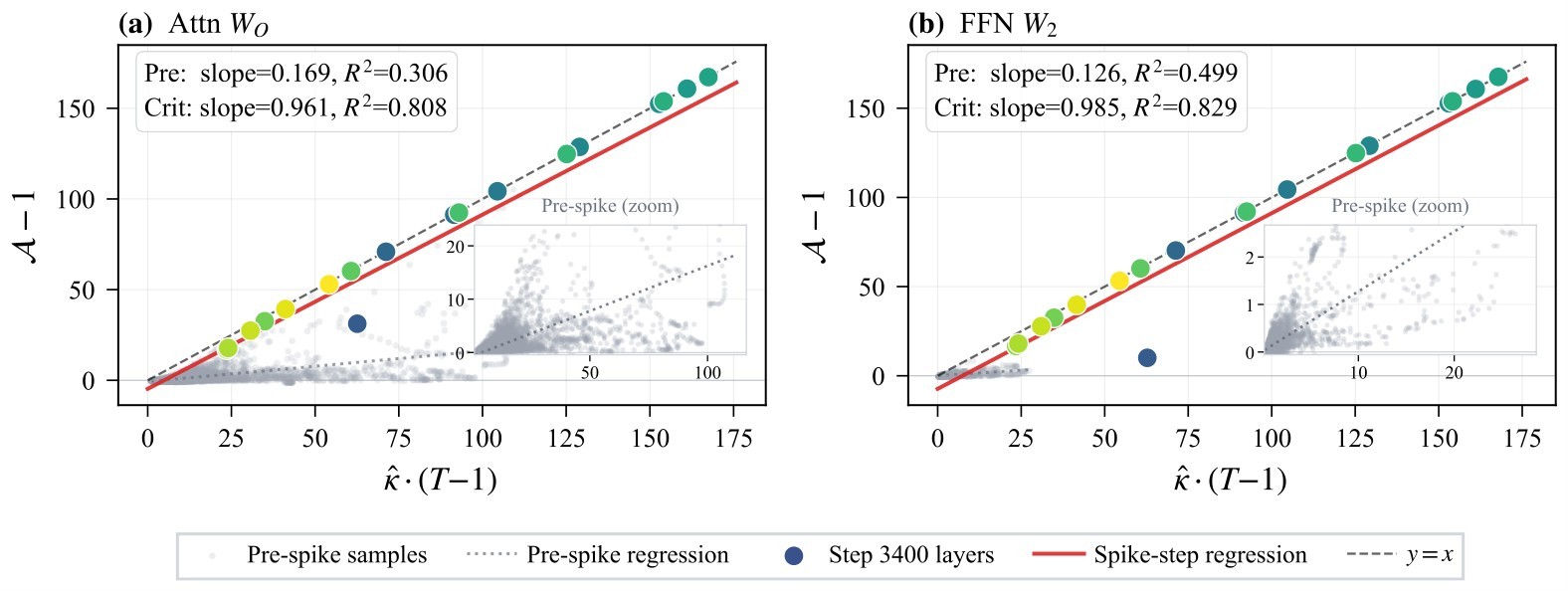
Attn_WO and FFN_W2 layers lie near the absolute-coherence saturation envelope. The paper reports \(\mathcal{A}-1 \approx 167\), about \(13\times\) writer-gradient norm amplification relative to the independent-token baseline.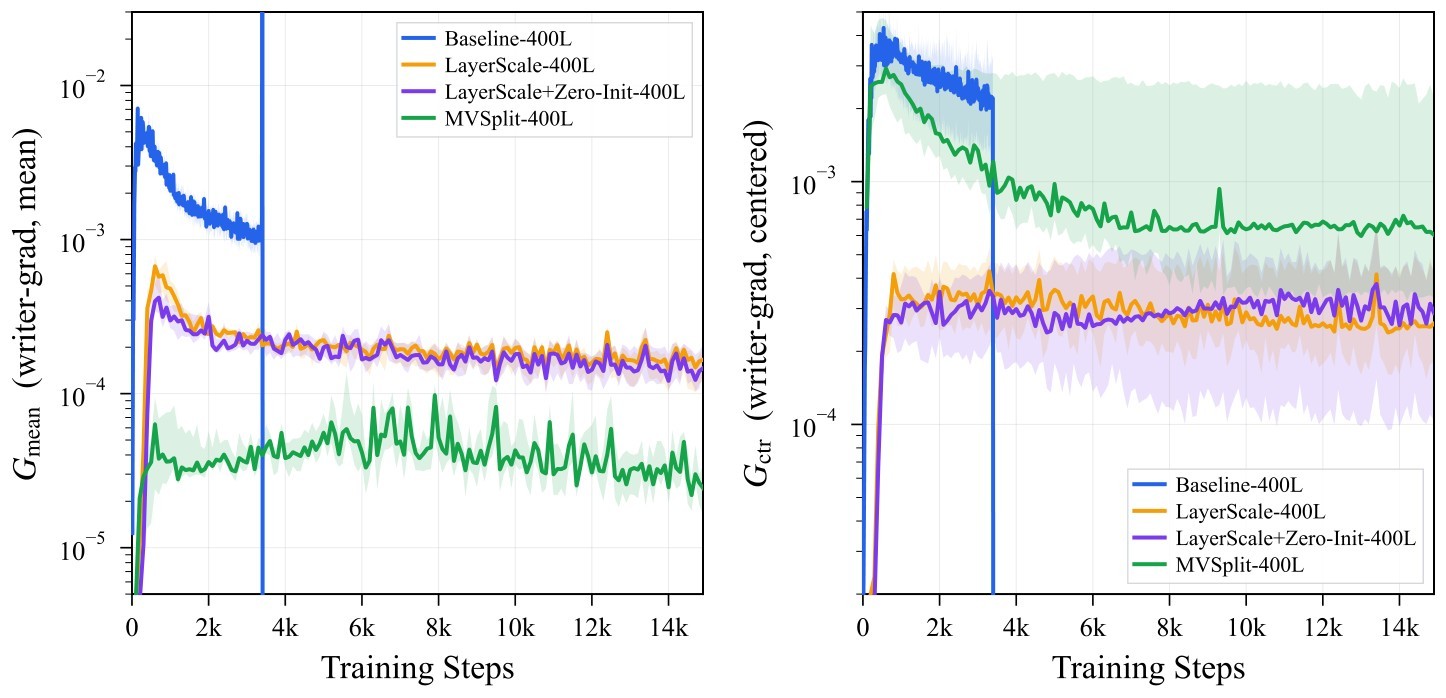
Experiments And Results
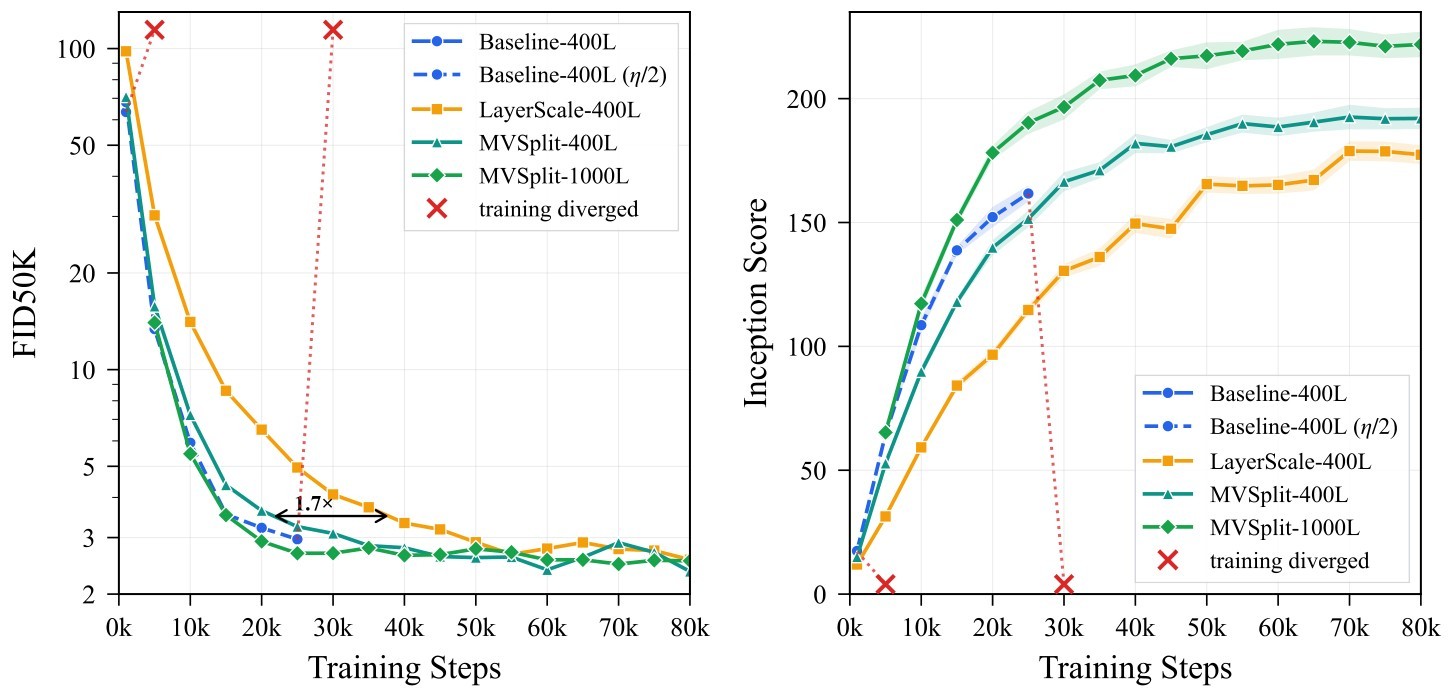
| Method | @10k FID / IS | @20k FID / IS | @30k FID / IS | @40k FID / IS | @50k FID / IS |
|---|---|---|---|---|---|
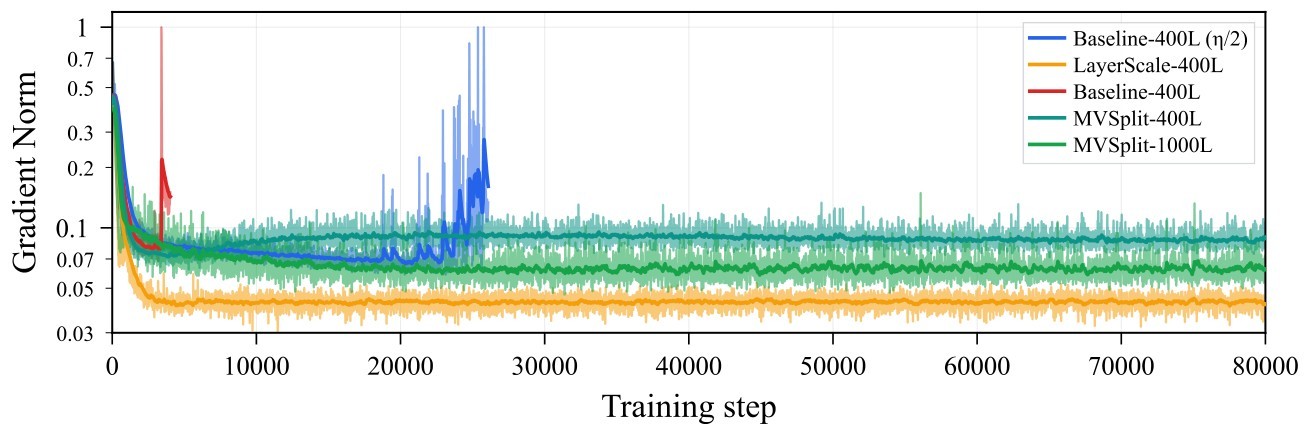
| 400L Base \(\eta\) | -- | -- | -- | -- | -- |
| 400L Base \(\eta/2\) (pre-crash reference) | 5.92 / 108.6 | 3.22 / 152.2 | -- | -- | -- |
| 400L LayerScale | 14.08 / 59.2 | 6.50 / 96.6 | 4.09 / 130.5 | 3.33 / 149.6 | 2.90 / 165.5 |
| 400L MV-Split | 7.23 / 89.8 | 3.64 / 139.9 | 3.09 / 166.5 | 2.79 / 182.0 | 2.60 / 185.5 |
| 1000L MV-Split | 5.47 / 117.3 | 2.92 / 178.2 | 2.68 / 196.6 | 2.64 / 209.4 | 2.77 / 217.3 |
Table 2. Stability-constrained quality frontier. FID-50K and IS use Euler sampling, 25 NFE, and CFG scale \(w=2.0\). The source table marks the default-LR baseline as diverged before the first checkpoint and the lower-LR baseline as a pre-crash reference, not a stable frontier point. The 1000-layer row is a separate scale-validation point, not part of the matched 400-layer frontier comparison.
| Field | 400L baseline | 400L LayerScale | 400L MV-Split | 1000L MV-Split |
|---|---|---|---|---|
| Pretraining data | ImageNet-2012 | ImageNet-2012 | ImageNet-2012 | ImageNet-2012 |
| Autoencoder / text encoder | Frozen FLUX.2 VAE / frozen Qwen3-0.6B | Same | Same | Same |
| Trainable components | DiT backbone only | DiT backbone only | DiT backbone only | DiT backbone only |
| Hardware | 8 x H100 | 8 x H100 | 8 x H100 | 16 x H100 |
| Parameters | 5.45B | 5.45B | 5.45B | 13.64B |
| Layers | 400 | 400 | 400 | 1000 |
| Residual mode | None | LayerScale | Mean-Variance Split | Mean-Variance Split |
| Residual gates | none | learnable \(\lambda\), sweep over \(10^{-2}\) to \(10^{-5}\) init | learnable \(\alpha,\beta\), init \(\alpha=0,\beta=1\) | learnable \(\alpha,\beta\), init \(\alpha=0,\beta=0.03\) |
| Learning rate | \(1.5625 \times 10^{-4}\), plus \(\eta/2\) control | \(1.5625 \times 10^{-4}\) | \(1.5625 \times 10^{-4}\) | \(1.5625 \times 10^{-4}\) |
| Post-training | none | none | none | ~50k curated images |
Table 3. Training configuration summary. The 400-layer rows are the matched comparison. The 1000-layer row shares the MV-Split residual design but changes depth, parameter count, hardware scale, and post-training pipeline.
The implementation appendix matters because a 400- or 1000-layer DiT makes small per-block operations expensive under activation checkpointing. The paper fuses RoPE, QK-Norm, SwiGLU, and MV-Split+RMSNorm in Triton. In an 8-GPU, 400-block profiling setup with three out of four blocks checkpointed, RoPE/QK-Norm/SwiGLU execute 700 times per active optimizer step and MV-Split+RMSNorm executes 1400 times. The fused backend reduces aggregated self-CUDA time for these operators from 1697.4 ms to 614.0 ms per active optimizer step, and reduces in-loop optimizer-step wall-clock from 5.87 s to 4.58 s, excluding dataloader wait.
| Metric | Score |
|---|---|
| GenEval overall, average over tasks | 0.534 |
| GenEval correct images | 52.44% |
| GenEval correct prompts | 67.63% |
| DPG-Bench overall | 74.91 |
Table 4. Text-conditioned calibration. The source explicitly says these values calibrate the post-trained 1000-layer checkpoint and are not meant as a state-of-the-art comparison to large public text-to-image systems.
| GenEval task | Accuracy |
|---|---|
| single_object | 92.81% |
| two_object | 63.64% |
| counting | 33.75% |
| colors | 72.61% |
| position | 25.75% |
| color_attr | 31.75% |
Table 5. GenEval task breakdown. The breakdown is useful because the 1000-layer run is strong enough to be a functioning text-conditioned generator, but still uneven across compositional tasks.
Practical Takeaways
The most reusable idea is the token-subspace view of residual stability. If a model can collapse into a homogeneous token state, scalar gradient norms and scalar residual gates may be too blunt. Separating mean-coherent and centered updates gives a more targeted diagnostic and intervention.
For model builders, MV-Split is especially relevant when depth is large and residual writers are token-wise. The method does not require changing the attention operator itself; it inserts a residual merge that controls how branch outputs enter the mean and centered subspaces. That makes it plausible to test as a localized architectural change.
For evaluators, the paper's strongest evidence is the controlled 400-layer comparison, not the sample grids. The 1000-layer run is important as scale validation, but it changes depth, parameter count, hardware, and post-training, so it should not be read as a direct architecture-vs-architecture leaderboard point.
| Intervention tried | Why it did not solve MMS in the paper's analysis |
|---|---|
| Hard centering \(X \leftarrow PX\) | Removes the mean instead of gain-limiting new mean writes; degraded optimization and removes useful global/timestep information. |
| Attention-matrix reparameterizations | Modify attention but do not protect the FFN writer or residual merge; row-stochastic variants still preserve pure-mean states. |
| Attention-output gates | Token-local head/feature gates do not construct \(JY\) and \(PY\); in a mean-dominated regime they tend to scale mean and centered parts together. |
| Attention-only MV-Split | Protecting only Attn_WO can move the spike to the unprotected FFN branch; the paper reports FFN_W2 taking about 93% of top-K squared-norm mass in the attention-only 1000-layer control. |
| Global gradient clipping | Shrinks \(G_\mu\) and \(G_c\) by the same scalar and cannot rotate a mean-coherent update back into the centered subspace. |
| Muon optimizer | Reshapes singular values in parameter space after token gradients have already summed; it does not implement \(G \mapsto \alpha JG+\beta PG\). |
Table 6. Negative controls and failed fixes. These are mostly appendix-level controls, so they support the design rationale but do not carry the same weight as the main 400-layer table.
The main limitations are clear. First, the alignment-amplification law diagnoses the condition under which token-wise writer gradients stop canceling, but it does not predict the exact onset step \(t^\star\) before the run is observed. Second, parts of the lock-in proof rely on Softmax attention; attention-free sequence mixers may share the residual-writer issue but not the same Q/K null-space argument. Third, the paper's scale validation focuses on image and text-to-image diffusion. Video, 3D, and other spatiotemporal generators have longer token sequences, so they may face even stronger mean-coherent pressure, but that is future work rather than demonstrated here.
Reference Coverage
Evidence anchors referenced for validator coverage: problem, backbone, MMS trace, diagnostics, mechanism equations, Softmax lemma, MV-Split method, alignment law, frontier table evidence, GMD control, standard-init control, training config, timestep probe, implementation, calibration, negative controls, and limitations.
Figure/table anchors referenced for validator coverage: teaser, architecture, loss/rho diagnostics, MMS trace figure, alignment-law figure, GMD figure, main results figure, standard-init figure, timestep figure, full-loss figure, diagnostic table, frontier table, training table, text-to-image calibration, GenEval breakdown, and negative-control table.