Source-first digest for monthly 2026_05 rank 25, rank_id p005.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
MinT treats post-training as an infrastructure workload rather than as a sequence of isolated checkpoint conversions. The target setting is many trained LLM policies over a small number of expensive resident base-model deployments. Full fine-tuning makes every policy a full checkpoint; merge-based LoRA saves training memory but still tends to materialize a merged full checkpoint for inference. MinT instead makes the LoRA adapter revision the behavior-carrying object that crosses rollout, update, export, evaluation, serving, and rollback. This source claim is the starting point for the managed-policy evidence used in the support table.
The paper's contribution is best read as three separate scale claims. Scale Up keeps the adapter-revision path usable for dense and MoE frontier models, including distributed Megatron training and sparse-route handling. Scale Down removes full-checkpoint materialization from training-serving handoff and reuses idle time across concurrent GRPO policies. Scale Out separates durable policy addressability from CPU-cache, GPU-batch, and cold-load residency. Those distinctions matter because the paper does not claim one engine keeps 1,000,000 adapters active; it claims MinT can build, name, audit, and selectively serve revisions from a million-scale catalog through bounded working sets.
Claims And Evidence
Support scores are support-from-paper scores, not independent reproduction scores.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | MinT's central abstraction is a managed adapter revision plus policy record, not a merged full checkpoint. | 4 | motivation, lifecycle mechanics, key equations and symbols |
| C2 | Adapter-only handoff and concurrent multi-policy training materially reduce systems overhead while keeping the resident base allocation fixed. | 5 | scale-down evidence, handoff figure, utilization figure, scale-down table |
| C3 | The same lifecycle runs across dense SFT/DPO/GRPO, MoE RL, GLM-5.1 Generative UI, and a 1.04T Kimi K2 countdown-task path. | 4 | scale-up evidence, dense curves, MoE curves, GLM curves, AutoResearch trace, scale-up table |
| C4 | The million-scale serving claim is an artifact-backed addressability result with bounded selected-revision execution, not simultaneous residency. | 5 | serving evidence, serving bounds, limitations |
| C5 | The paper identifies two concrete scale-out bottlenecks, cold activation interference and MoE tensor fanout, then gives measured controls for both. | 4 | rollout control, packed loader, serving evidence |
| C6 | The strongest evidence is systems evidence for LoRA policy infrastructure; broad end-task quality claims remain benchmark- and recipe-specific. | 3 | scale-up table, limitations, reference coverage |
Core Technical Idea
MinT separates a policy record from an adapter revision. The adapter revision is a fixed exported LoRA payload in serving layout. The policy record is service-owned state: compatible base version, LoRA rank, target modules, latest training checkpoint, rollout records, optimizer state, exported revisions, and cache/residency state. That distinction lets the system answer four questions independently: which base can run the behavior, which checkpoint resumes training, which revision should be evaluated or served, and where the adapter bytes currently live.
The runtime has four linked mechanisms. First, the service plane creates pollable operation ids and commits outputs only after metadata is written, so retries do not select uncommitted attempt files. Second, training workers keep the base model resident and time-slice policy states. Third, export converts trainer-side LoRA tensors into PEFT/vLLM-compatible serving layout without copying the base checkpoint. Fourth, serving actors map a requested policy revision through GPU-batch, CPU-cache, and cold shared-storage states before generation.
| Source formula or symbol | Digest role | Meaning |
|---|---|---|
| \(W\) and \(L_i\) | Adapter-only handoff | \(W\) is the resident base; \(L_i\) is the trained LoRA adapter that MinT exports and serves instead of moving a full merged \(W'_i\). |
| \(r\) and \(L_r\) | Serving selection | A request resolves to exported revision \(r\); if \(L_r\) is in a GPU slot, vLLM decodes immediately, otherwise MinT promotes or cold-loads it. |
| \(A \rightarrow B\) policy switch | Time-sliced training | The base remains resident while MinT saves policy \(A\)'s adapter, optimizer moments, scheduler position, gradients, and rollout records before restoring policy \(B\)'s state. |
| \(10^6\) catalog | Scale-out addressability | The million count is a durable catalog/audit scale, not the number of adapters resident in one CPU cache or active in one GPU batch. |
| \(\lceil 2300/64 \rceil = 36\) | Fleet-sizing sketch | The appendix uses the 64-adapter same-batch window to size ideal placement for a 2300-distinct-adapter active-wave model. |
The extracted equations.json contains no display equations for this paper, so Table 1 records the key inline symbols and source-side formulas that define the system semantics rather than claiming a formal optimization objective.
Method Details
The training side uses time-sliced multi-LoRA training. A resident trainer restores one policy's LoRA tensors and optimizer state, runs the update, checkpoints the result, then yields to another policy without reloading the base model. Workers advertise supported rank and target-module limits; smaller adapters can be padded/masked inside configured maximum slots. For Megatron MoE runs, dense LoRA tensors follow tensor-parallel shards, expert LoRA tensors are keyed by expert id, and export gathers or deduplicates tensors into the serving layout.
The serving side uses shared-base multi-LoRA sampling. The service maps a user-facing policy name to an exported adapter revision and sends that revision to a vLLM sampler that already holds the base model. If the adapter is active in the GPU batch, the request uses the hot path. If it is CPU-cached, the actor promotes it. If it is absent, MinT schedules a cold load from shared storage before generation. Cold loading is not hidden inside normal decoding latency; it is an explicit service stage with deduplication and backpressure.
MinT also records sparse-model provenance. For Qwen3-style MoE, rollout records can store selected expert ids so training can score tokens along the route that generated them; missing or unmappable routes are masked from the replayed policy-gradient term. For GLM-5-style dynamic sparse attention, the system stores backend/model path and correction policy, then uses IcePop-style rollout correction to zero unsafe importance weights outside a trusted probability-ratio band. This is a mitigation, not full DSA route replay.
Experiments And Results
Scale Down: Adapter Handoff And Utilization
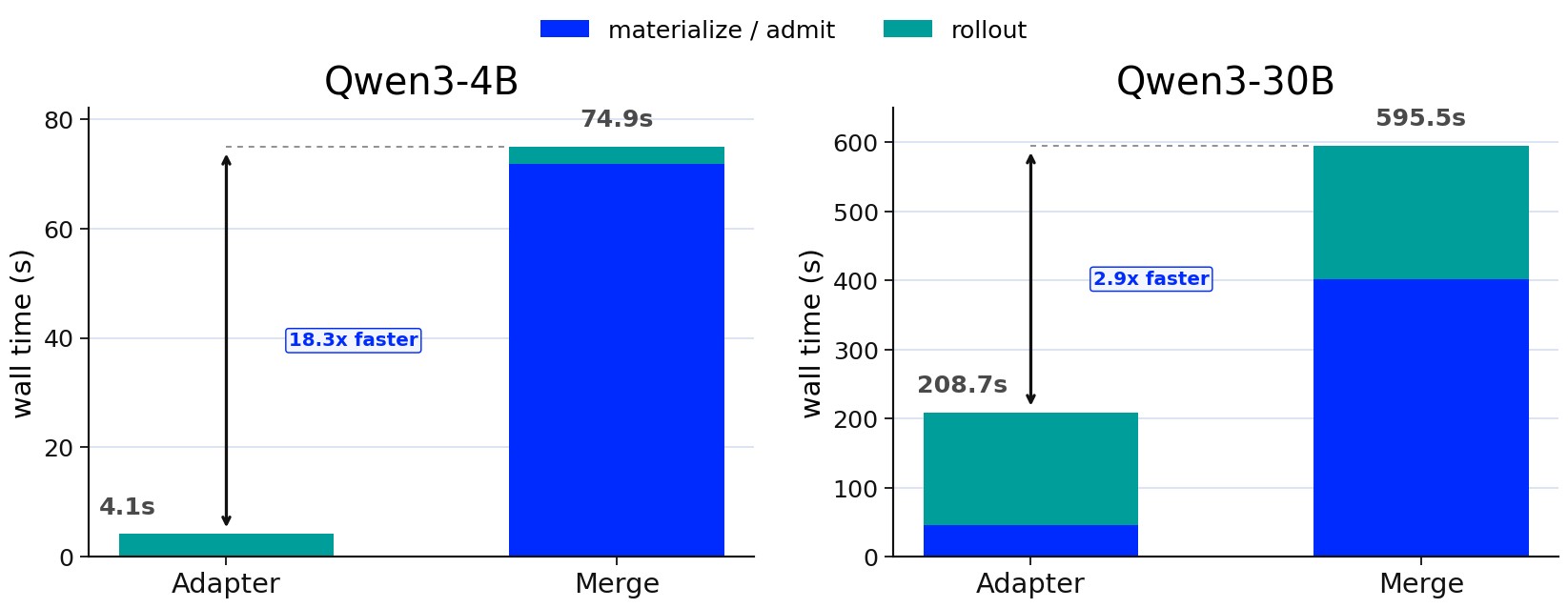
The scale-down experiments isolate systems overhead. Adapter handoff compares a MinT adapter load against merge-and-load paths. Concurrent training compares three GRPO policies run sequentially against the same policies overlapped under one resident base allocation. The paper reports 18.3x and 2.85x handoff-step reductions in the abstract, and the table/figure evidence below shows the underlying file sizes, load/materialization times, cold first-sample times, wall-clock schedule times, and unchanged peak memory.
The handoff bars in Figure 1 show why moving adapter revisions is operationally different from moving full checkpoints.
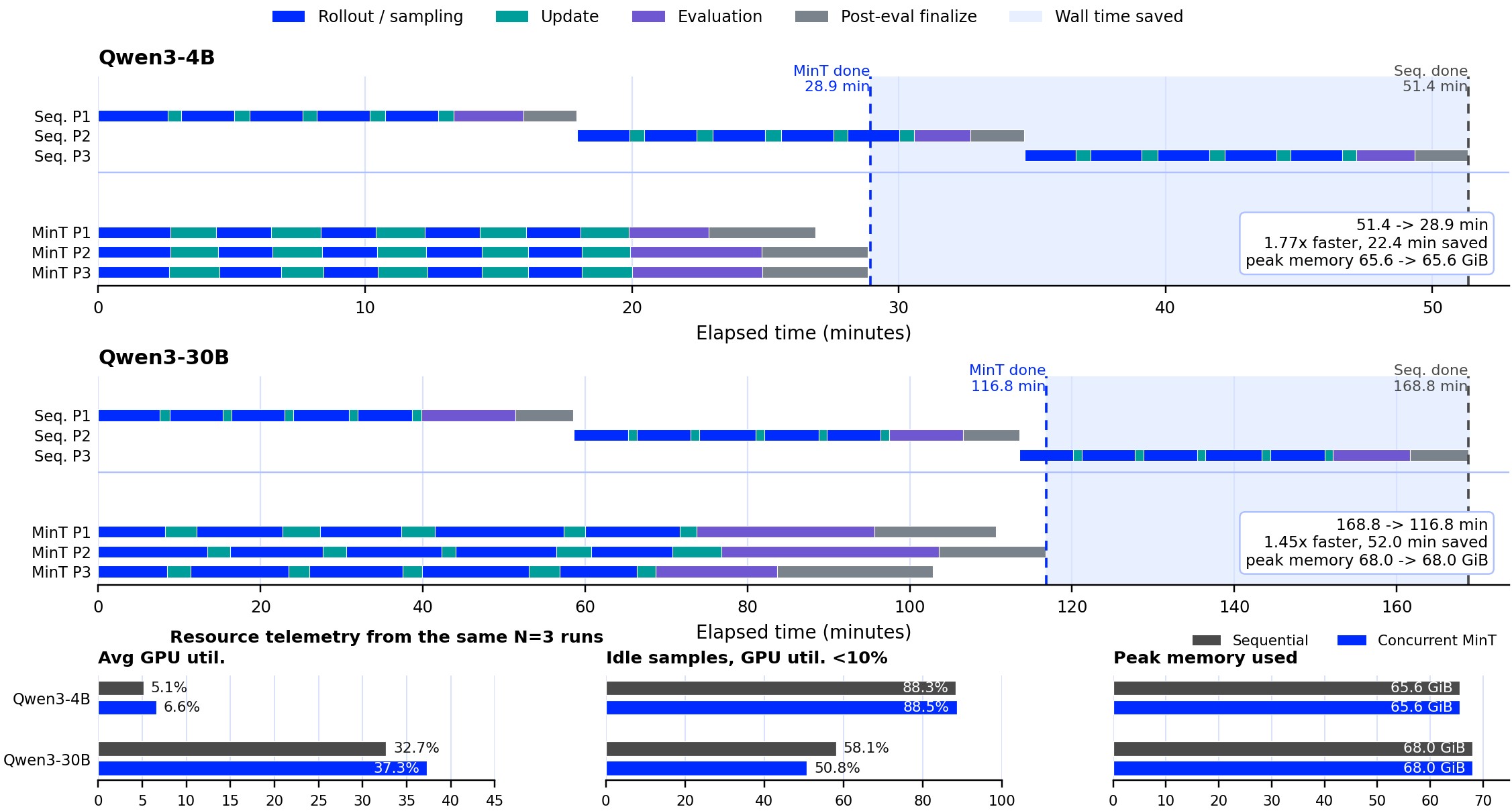
The schedule timeline in Figure 2 shows the second part of the scale-down claim: concurrent GRPO policies fill idle resident-base windows rather than requiring another base copy.
| Experiment | Model | MinT / adapter path | Baseline path | Reported effect |
|---|---|---|---|---|
| Handoff file scale | Qwen3-4B | rank-32 adapter, 252 MiB, 0.036 s load/materialization | full model, 8.061 GB, 71.820 s materialization | adapter-only handoff avoids full checkpoint transfer; abstract reports 18.3x measured handoff-step reduction |
| Handoff file scale | Qwen3-30B | rank-16 adapter, 1.692 GB, 46.455 s load/materialization | full model, 61.084 GB, 402.245 s materialization | abstract reports 2.85x measured handoff-step reduction |
| Concurrent GRPO | Qwen3-4B | 3 policies in 1736.1 s, peak 65.6 GiB | sequential 3081.2 s, peak 65.6 GiB | 1345.1 s saved, 1.77x speedup, peak memory unchanged |
| Concurrent GRPO | Qwen3-30B | 3 policies in 7008.4 s, peak 68.0 GiB | sequential 10130.0 s, peak 68.0 GiB | 3121.6 s saved, 1.45x speedup, peak memory unchanged |
Scale Up: Dense, MoE, UI, And AutoResearch Runs
The scale-up evidence is not one benchmark. It is a compatibility argument across training paradigms and model placements. Dense runs cover SFT, DPO, and GRPO under one adapter lifecycle. MoE runs add expert-route replay and distributed placement. GLM-5.1 A2UI adds a product-facing GRPO workload. AutoResearch adds proxy-to-full benchmark promotion logic around maintained adapter recipes.
Figure 3 shows dense-model traces for SFT, DPO, and GRPO, while Table 3 captures the endpoint evidence.
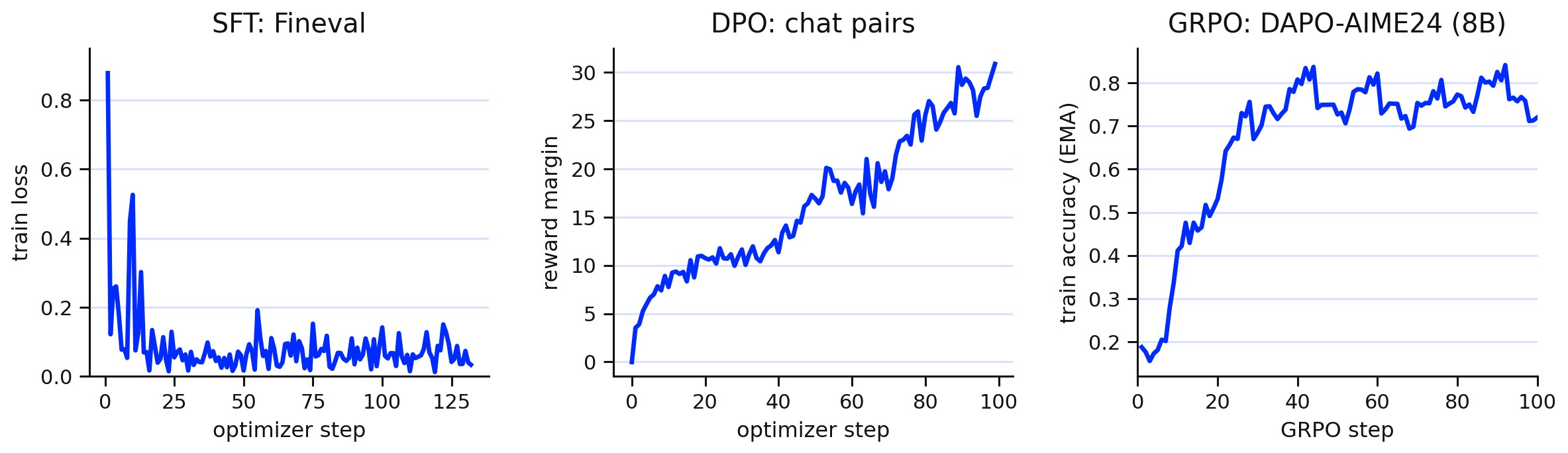
Figure 4 gives the sparse-model scale-up evidence, including Qwen3-30B/235B AIME24 and a Kimi K2 1.04T countdown-task curve.
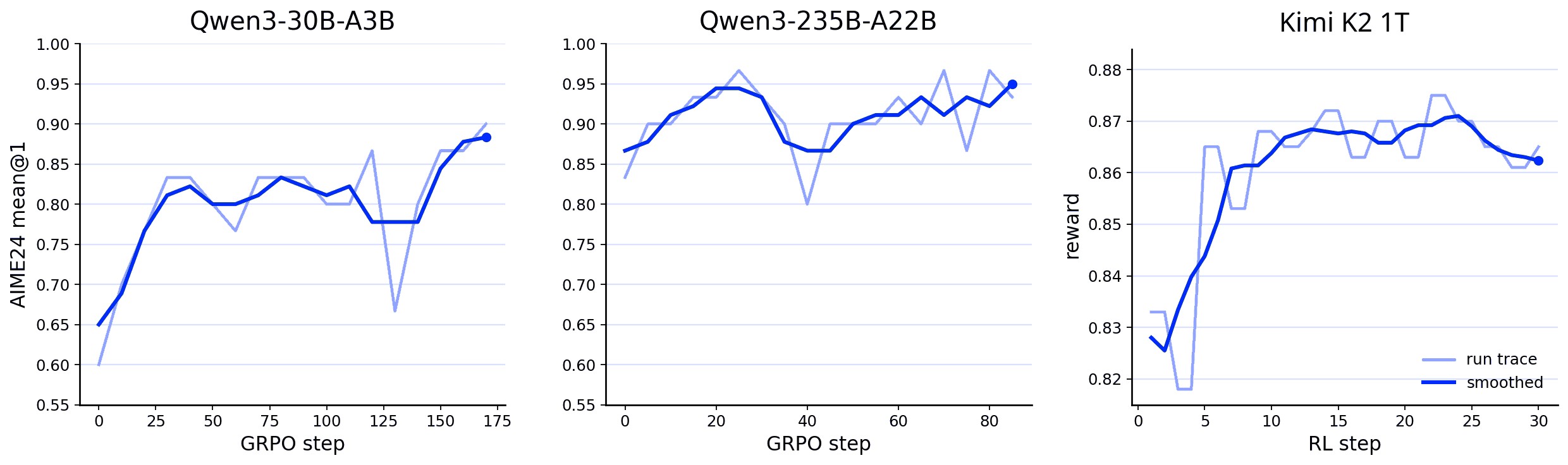
Figure 5 covers the GLM-5.1 Generative UI GRPO case.
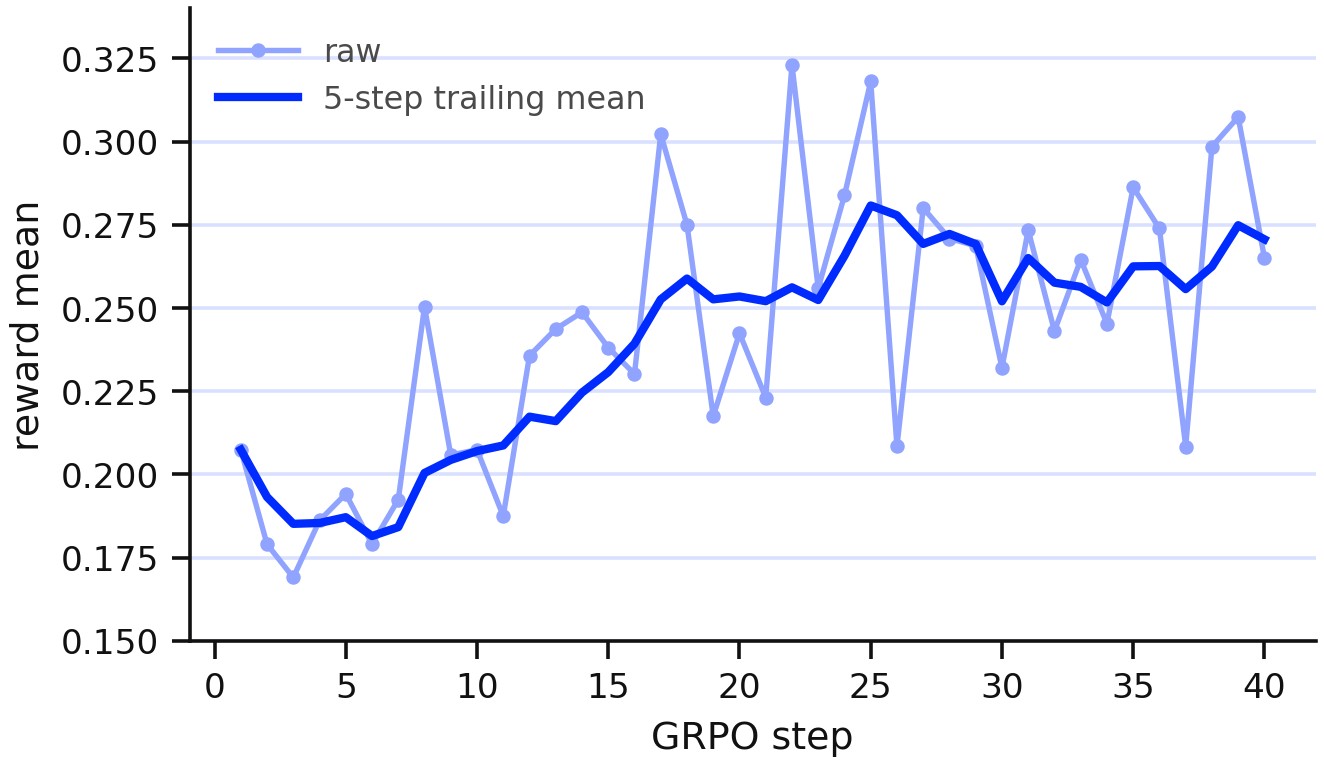
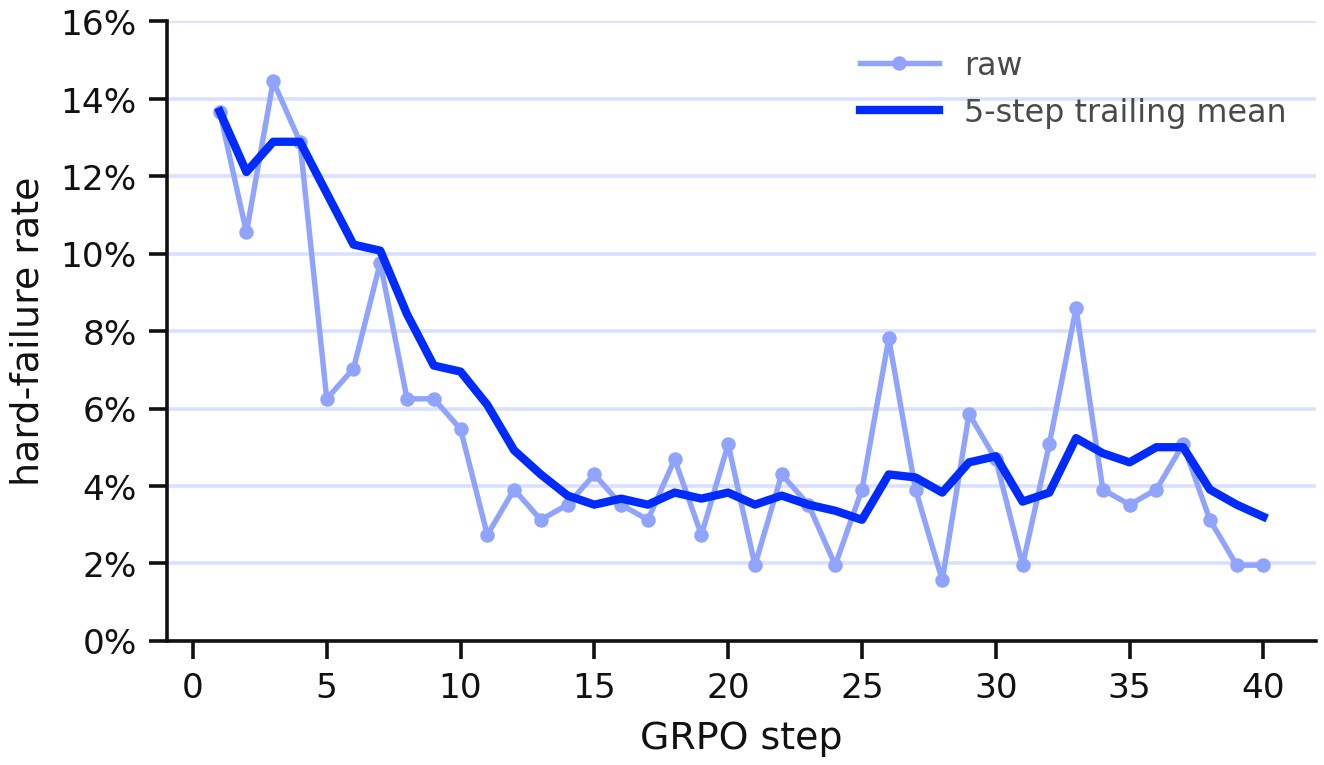
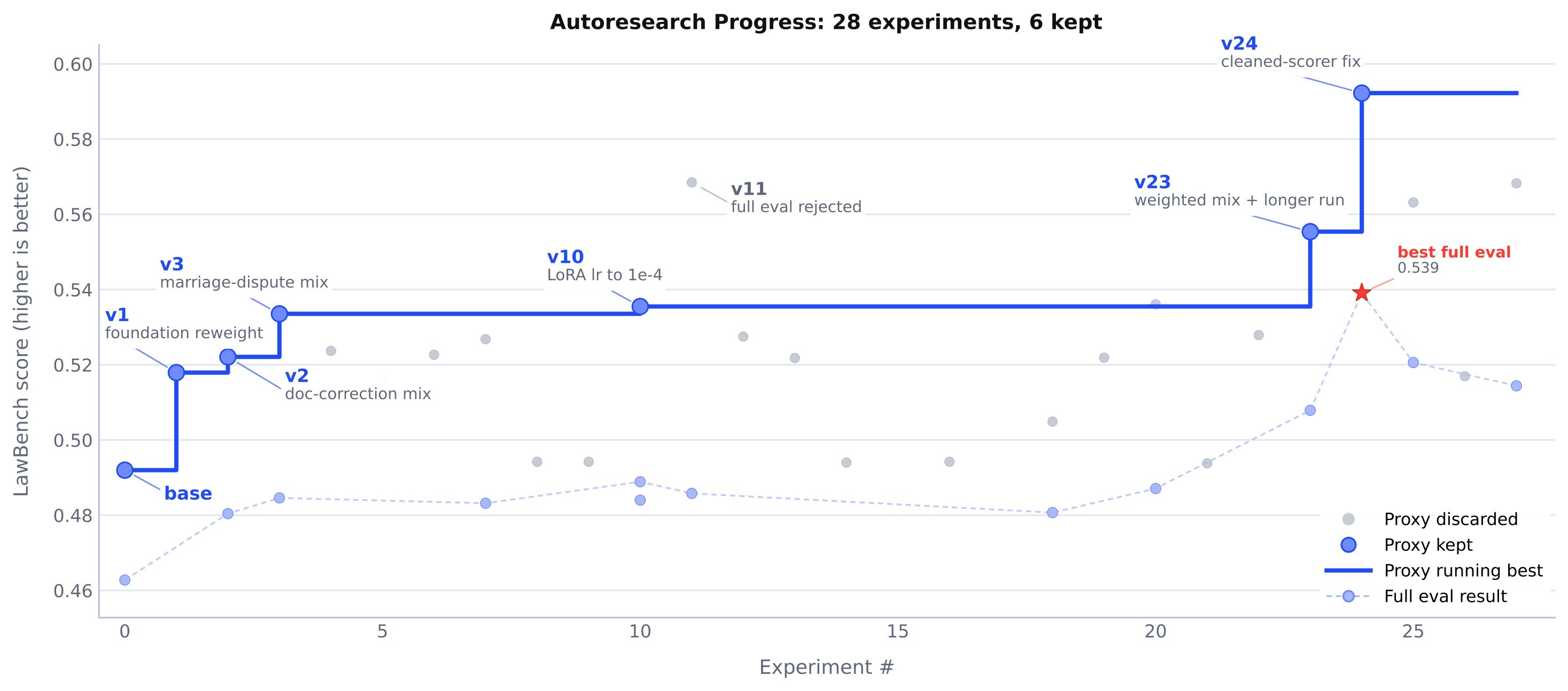
Figure 6 shows the AutoResearch LawBench trace.
| Evidence group | Setup | Main source result | Interpretation |
|---|---|---|---|
| Dense SFT | Qwen3-4B finance suite | Fineval 0.4226 to 0.7811; FPB 0.6906 to 0.8804; TFNS 0.5959 to 0.9095 | SFT updates move through the adapter lifecycle and produce held-out gains. |
| Dense DPO | chat pairs | reward margin -0.03 to 30.88 | Preference optimization uses the same export/serving path. |
| Dense GRPO | Qwen3-8B DAPO-AIME24 | train accuracy EMA 0.188 to 0.719; peak 0.841 at step 92; step-240 eval 20/30, 19/30, 18/30 on AIME24/25/26 | Rollout-based RL can update and export the same adapter object. |
| MoE GRPO | Qwen3-30B/235B and Kimi K2 | 235B-A22B reaches 0.967 peak mean@1 on AIME24; Kimi K2 uses 1.04T total parameters with 32.6B active | Adapter/base split survives tensor/expert-parallel placement. |
| Route consistency | Qwen3 MoE | out-of-route scoring ratios: 0.0013% with R3 on 30B, 0.0097% without R3 on 30B, 0.0253% with R3 on 235B | Route metadata controls a specific MoE scoring mismatch channel. |
| GLM-5.1 A2UI | 40 GRPO steps | reward mean about 0.21 to 0.27; hard failures down to 5/256 at step 40 | The lifecycle supports a Generative UI workload, not only math. |
| AutoResearch LawBench | Qwen3-4B recipes | base 0.4628; v10 0.4889; discarded v11 0.4858 full despite high proxy; maintained v23 0.5079 full | Proxy screening is guarded by full confirmation before recipe promotion. |
Scale Out: Policy-Population Serving
The serving experiments split addressability from execution. A durable catalog can contain 1,000,000 adapter revisions, but one serving actor keeps only selected revisions in CPU cache and a smaller set in the GPU batch. The paper's strongest scale-out evidence is therefore a bundle: million-catalog build/audit, cache and same-batch bounds, warm selected-revision SLO, cold-load accounting, packed representation, and readiness control.
| Tier | Evidence | Measured bound | Interpretation |
|---|---|---|---|
| Catalog artifact | packed Qwen3-30B rank-1 pool | 1,000,000 / 1,000,000 built; 0 errors; 256 / 256 audit OK across 100 shards | Million scale is addressability, not one-engine residency. |
| CPU adapter cache | one 4-GPU serving actor | 369 loaded adapters at a 512-adapter hotset; 550 loaded under 2048-adapter pressure | One actor can keep hundreds of adapters nearby, but weak locality raises p95. |
| GPU batch window | distinct-adapter probe | 64 distinct adapters in the tested decoding batch | Batch execution is the smallest adapter-diversity window. |
| Warm selected-revision serving | 64 warmed revisions, Poisson traffic | 0.5, 1, and 2 rps keep 100% TTFT \(\le 5s\); 4 rps drops to 72.1% SLO | The warm serving knee is between 2 and 4 rps for this workload. |
| Cold-load path | warm/cold N=64 and N=16 probes | warm p95 21.35 s; cold-cache p95 199.81 s; N=16 staircase 1.375 to 23.267 s | Different missing adapters serialize through engine load work before decoding. |
The mixed warm/cold control rows in Table 5 show why MinT distinguishes registered, prewarming, and ready states.
| Policy | Existing warm traffic | New-adapter path | Interpretation |
|---|---|---|---|
| Admission off | post TTFT p95 24.03 s; \(>20s\) stalls: 10 | e2e p95 59.18 s; user TTFT p95 22.19 s; load p95 47.37 s | Fast exposure, but cold first-touch disrupts warm tenants. |
| Admission on | post TTFT p95 9.71 s; \(>20s\) stalls: 0 | e2e p95 314.79 s; user TTFT p95 10.68 s; load p95 294.96 s | Admission protects warm tenants, but new users wait behind activation. |
| Two-phase readiness | post TTFT p95 9.63 s; \(>20s\) stalls: 0 | ready-path TTFT p95 4.60 s; load p95 0.00 s; prewarm span 409.04 s | First user requests arrive after activation, so they do not load adapters. |
The packed-loader rows in Table 6 show that MoE LoRA cold load is object-bound, not only byte-bound.
| Metric | Original | Packed | Effect |
|---|---|---|---|
| File size | 110.75 MB | 105.58 MB | 1.05x smaller |
| Tensor objects | 37,248 | 672 | 55.4x fewer |
| Read tensors | 0.3669 s | 0.0067 s | 54.8x faster |
| Build loader objects | 0.7540 s | 0.0256 s | 29.5x faster |
| N=4 live load | 1.363 s | 0.156 s | 8.7x faster |
| N=8 live load | 1.361 s | 0.159 s | 8.6x faster |
| N=16 live load | 1.388 s | 0.164 s | 8.5x faster |
The evidence boundary is explicit. The 1M result is a built-and-audited catalog plus selected-revision serving measurements. It is not a claim that every revision is resident, active, or warm. Warm selected-revision serving is measured for a particular Qwen3-30B rank-1 LoRA workload with prompt length 1024 and max output length 64. End-task quality evidence comes from named cookbook tasks and benchmarks, while the paper's main novelty is infrastructure: policy records, adapter revisions, export, cache state, cold-load scheduling, and readiness.
Practical Takeaways
MinT is most relevant when an organization expects many LoRA policies over a smaller set of expensive base models. The practical win is not only smaller files; it is making adapter revision the stable service unit that can be resumed, exported, evaluated, rolled back, cached, prewarmed, and served without turning every variant into another full-model deployment.
For training systems, the useful pattern is to keep the base resident and make policy state the object that moves. That requires versioned policy records, committed operation visibility, serving-compatible export, and exact attribution of rollout/evaluation scores to exported revisions. For serving systems, the useful pattern is to treat cold adapter loading as service work. A request-name catalog, CPU cache, GPU batch, and readiness state are different resources with different limits.
The main caution is that scale-out claims need careful wording. MinT's million-scale evidence is durable addressability over a real packed catalog, while runtime capacity depends on selected-revision locality, cold-load rate, batch adapter diversity, CPU cache, and prewarm policy. The paper is valuable because it makes those boundaries visible instead of compressing them into a single "serves millions of adapters" slogan.
Reference Coverage
This digest explicitly links all anchors used above: motivation, lifecycle mechanics, key equations and symbols, scale-down evidence, handoff figure, utilization figure, scale-down table, scale-up evidence, dense curves, MoE curves, GLM curves, AutoResearch trace, scale-up table, serving evidence, serving bounds, rollout control, packed loader, limitations, and reference coverage.