Rank: 12 (p006) Venue tag: arXiv2026 Paper: arXiv:2604.27351 HF Daily: huggingface.co/papers/2604.27351
This digest is based on the LaTeX-source extraction route success / full_markdown. I used local source artifact/paper.md as the primary source, with main.flattened.tex, equations.json, and figures.json for equations, tables, and figure provenance. No raw PDF extraction was used.
Motivation / Background
Language-agent systems are good at interpreting instructions, planning, and formatting answers, but the paper argues that they become weak scientific workers when the important input is not naturally linguistic. Scientific tasks often depend on time series, tabular measurements, formulas, or other structured data. Serializing those inputs into text can lose the native inductive bias that specialized scientific foundation models already have. The motivation is captured by the paper's domain-advantage assumption and by the opening contrast between language-only agents and domain-specific foundation models; see Evidence E1.
The proposed answer is Eywa, a framework for connecting LLM agents to non-language scientific foundation models through a bidirectional interface. The high-level system picture is shown in Figure 1: the paper builds from EywaAgent for a single language-model-plus-foundation-model unit, to EywaMAS for plug-and-play multi-agent replacement, to EywaOrchestra for task-adaptive planning over heterogeneous experts.
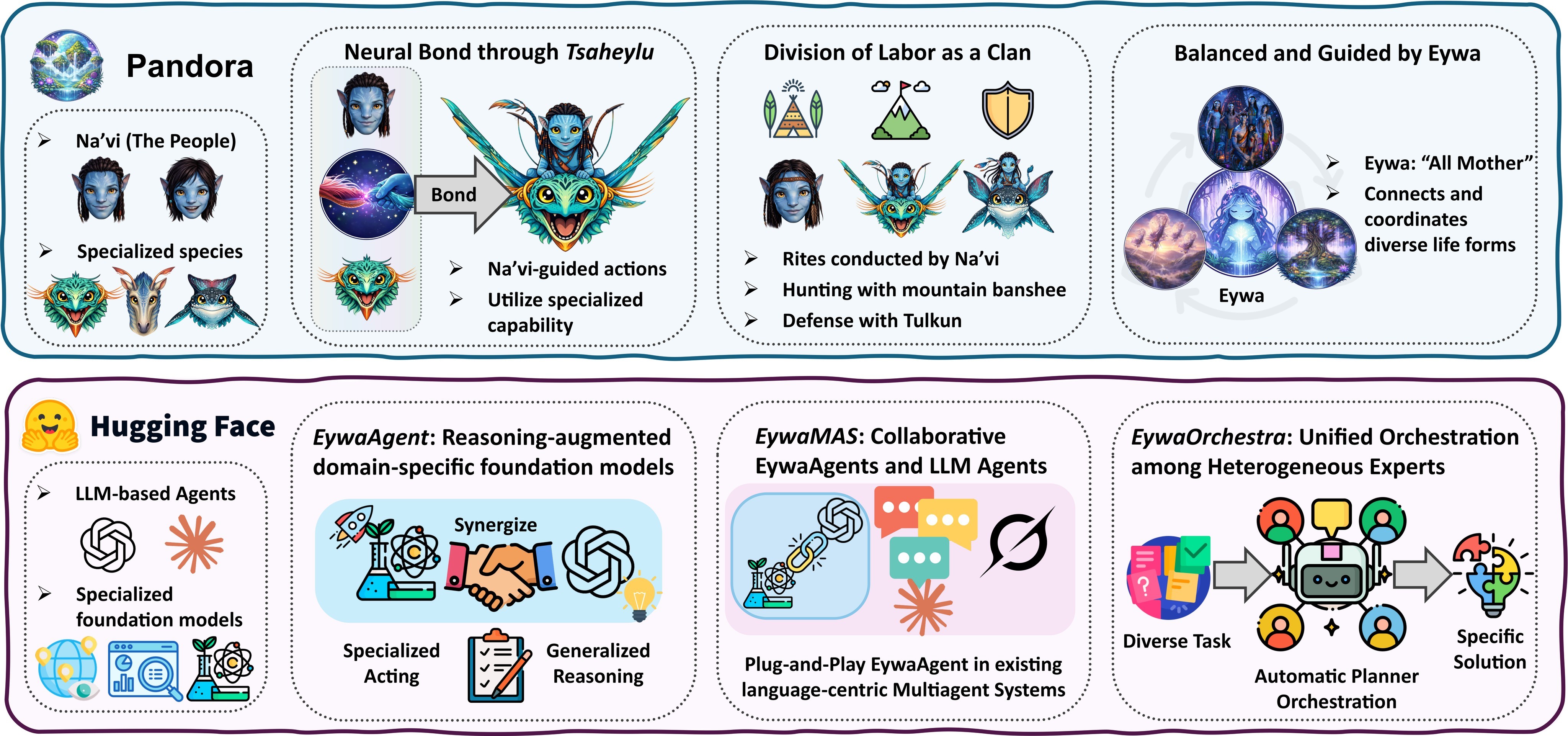
The paper's central practical question is whether a language model can serve as the control and communication layer while the specialized model performs the native scientific computation. That division of labor matters for areas where a language model can parse task text but should not be expected to infer numerical or structured patterns from a tokenized table or time series.
Claims And Evidence
| Claim | Support score | Evidence |
|---|---|---|
| Scientific agentic systems need a bridge from language reasoning to domain-native foundation models, because language serialization is an information and capability bottleneck for structured inputs. | 4.5/5 | E1, E2 |
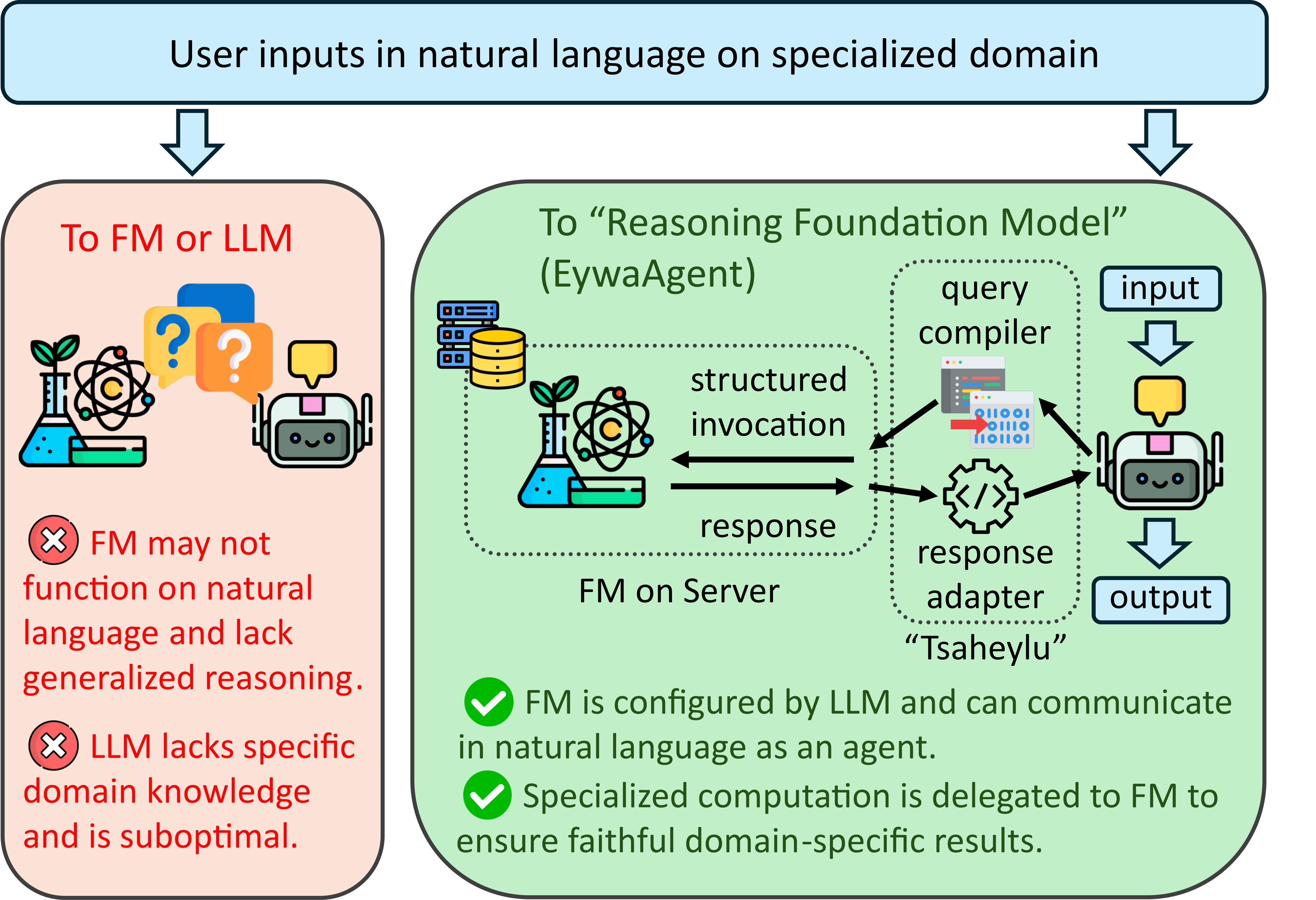
| EywaAgent is a clean abstraction: an LLM can either continue language reasoning or invoke a specialized foundation model through query/compiler and response/adapter maps. | 4/5 | E2, E3, Figure 2 |
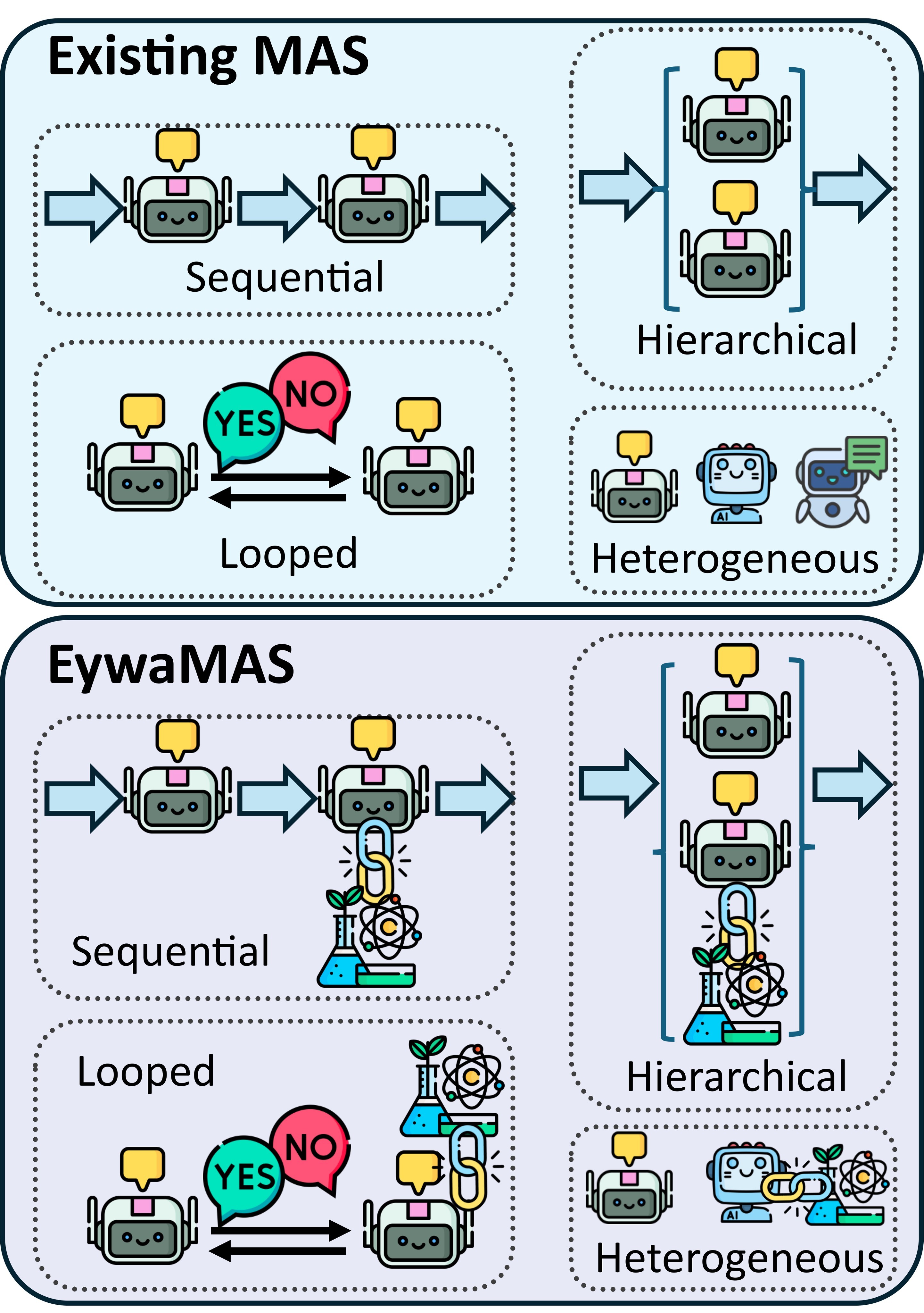
| EywaMAS preserves existing multi-agent topologies while allowing some agents to be specialized EywaAgents. | 4/5 | E3, Figure 3 |
| EywaOrchestra adds useful adaptivity by letting a conductor choose model, agent type, foundation model, and topology per task. | 3.5/5 | E2, E4 |
| On EywaBench, Eywa improves the utility-cost trade-off: EywaAgent raises overall utility from 0.6154 to 0.6558 while cutting average tokens from 4469 to 3137; EywaMAS reaches the highest overall utility, and EywaOrchestra nearly matches it with less cost. | 4/5 | E5, Table 2, Figure 4 |
| The evaluation is broader than a single benchmark slice but still bounded: EywaBench-V1 has 200 tasks from four source families, three modalities, and nine sub-domains. | 3.5/5 | E6, Table 1, Figure 6 |
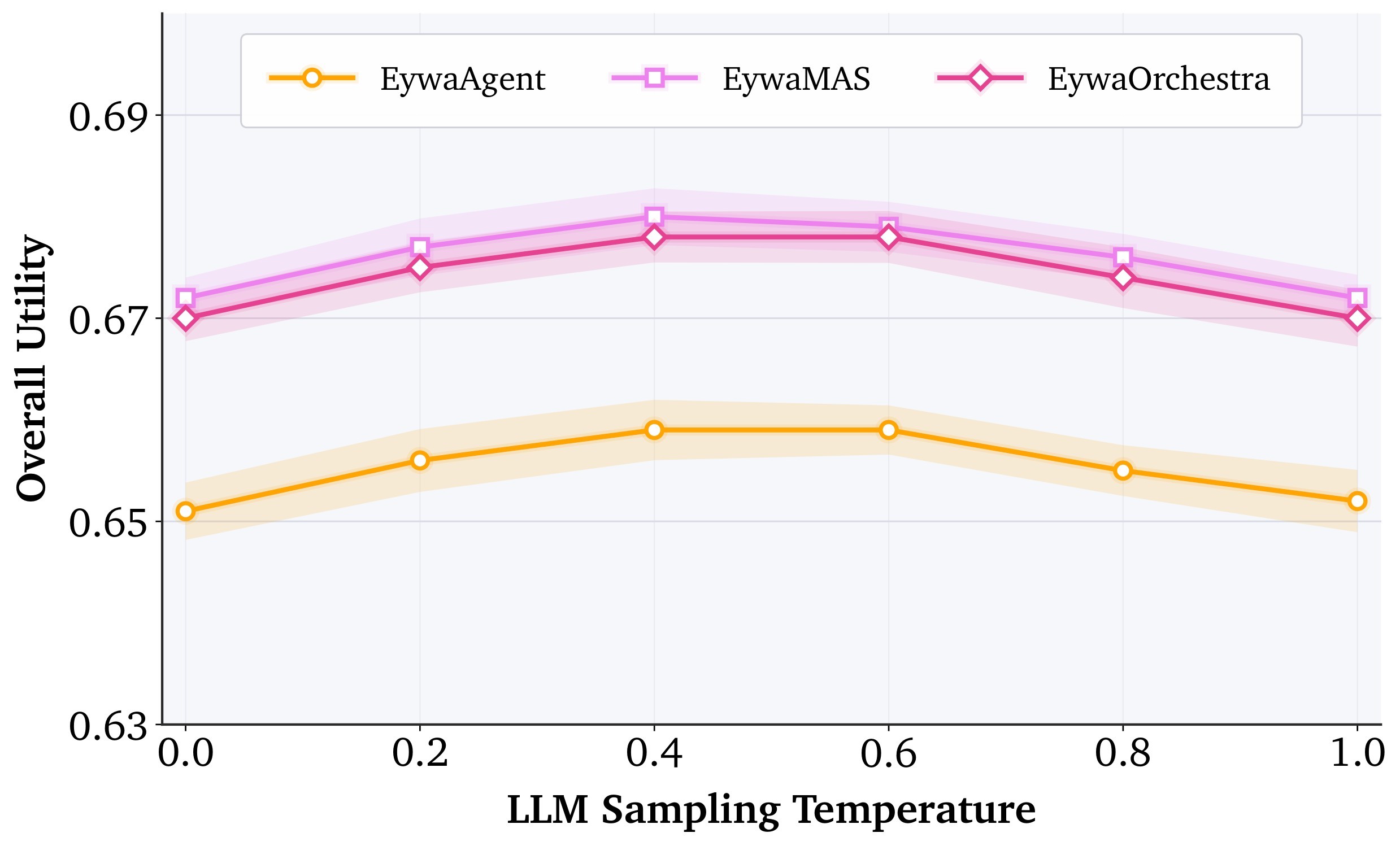
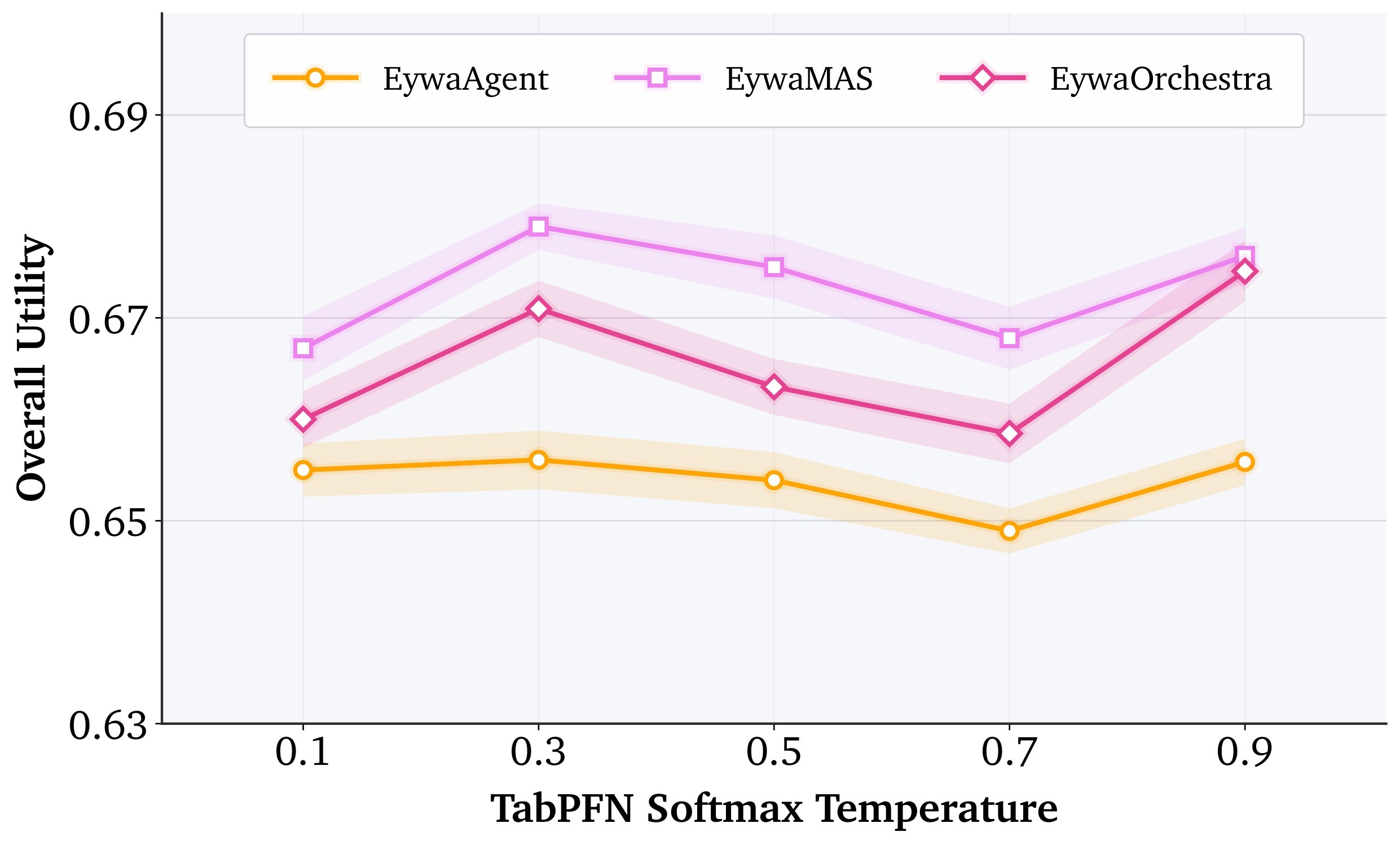
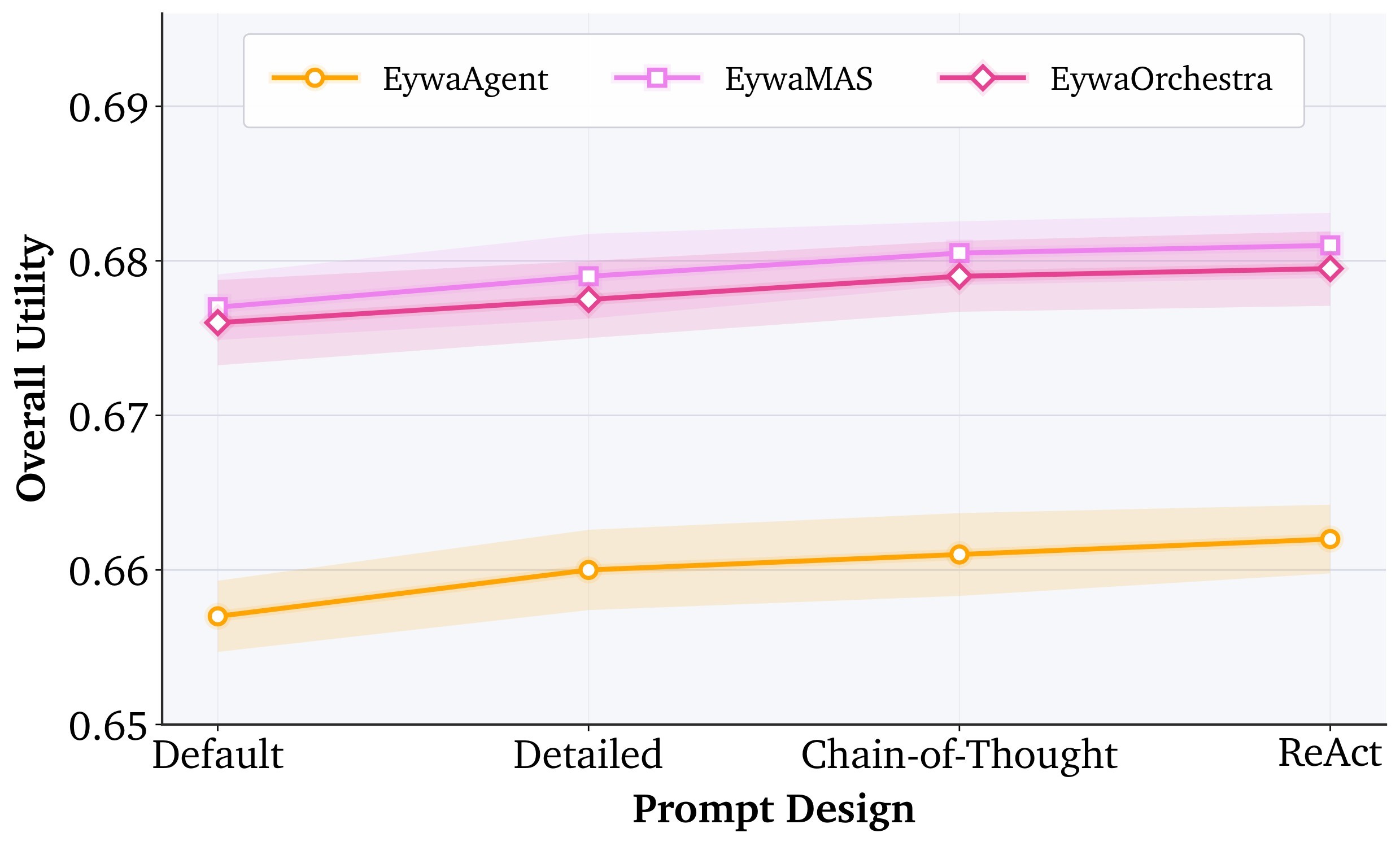
| The robustness evidence is suggestive but incomplete: the paper reports stability under temperature, prompt, and LLM-backbone ablations, but the specialist set is only Chronos plus TabPFN. | 3/5 | E7, Table 3, Figure 7 |
Core Technical Idea
The core idea is to turn a domain-specific foundation model into an agentic component by wrapping it with a language-side control interface. The LLM does not become the scientific model. Instead, it compiles the task state into a structured model invocation, lets the specialist operate on native data, then adapts the output back into language-compatible context.
Evidence E2 - key equations. The paper formulates scientific task input as a product of language-observable context and specialized components:
The task objective is standard expected loss minimization:
The domain-advantage assumption says that, when a domain component is informative, a specialist foundation model can beat a language-only model operating on a serialization of that component:
The FM-LLM bridge is the "Tsaheylu" pipeline:
The EywaAgent tuple is:
where the control policy chooses whether to skip or invoke the foundation model. For an invocation, the main computation is:
The paper also frames dynamic orchestration as choosing among configurations:
Finally, the appendix gives the token-complexity intuition:
These equations are the strongest formal support for the paper's argument that language agents should route native scientific data to domain models instead of reasoning over long serialized inputs.
Method Details
Evidence E1 - interface gap. The paper defines a domain-specific foundation model as a model over specialized input, control, and output spaces:
The important constraint is that the model is not assumed to accept open-ended language. Eywa therefore treats the LLM as the task interpreter and interface manager, not as the native scientific predictor.
Evidence E3 - agent and MAS design. EywaAgent uses a control policy over {invoke, skip}. If it skips, the system behaves like a normal LLM agent; if it invokes, phi converts the current state into a structured call, F performs the domain computation, and psi returns a planner-consumable representation. Figure 2 shows this split.
EywaMAS then upgrades this unit to a multi-agent setting:
where agents in the set can be language-only agents or EywaAgents. The paper emphasizes that an existing multi-agent system can replace some workers with EywaAgents without redesigning the full topology. Figure 3 is the source-side schematic for this plug-and-play composition.
Evidence E4 - orchestration. EywaOrchestra adds a conductor that maps a task to a configuration. The conductor decides the role and type of each agent, the LLM backbone, the attached foundation model, and the topology from a finite topology pool. The algorithm in the paper is short: select configuration c <- P(q,x), instantiate the heterogeneous system specified by c, execute it, and return the final answer.
In implementation, the paper exposes each domain model as an MCP-style service. The query compiler becomes a structured tool call containing the target resource and invocation parameters; the MCP server retrieves the domain data, runs the foundation model, and returns structured output for the adapter.
The source paper's implementation uses Chronos for time-series forecasting and TabPFN for tabular prediction. Neither model is treated as natively conversational; the language model handles task parsing, model-call configuration, output verification, and final response formatting.
Experiments And Results
Evidence E6 - benchmark design. EywaBench is designed to test scientific agentic systems across language, time-series, and tabular workloads rather than only natural-language QA. The source dataset and benchmark structure are summarized in Table 1, with visual coverage in Figure 5, Figure 6, and Figure 8.
| Benchmark aspect | Source evidence |
|---|---|
| Source families | DeepPrinciple, MMLU-Pro, fev-bench, TabArena |
| EywaBench-V1 size | 200 controlled task instances |
| Modalities | Natural language, time series, tabular |
| Parent domains | Physical science, life science, social science |
| Sub-domains | Material, energy, space, biology, clinic, drug, economy, business, infrastructure |
| Parent-domain balance | 32.0% / 30.0% / 38.0% |
| Modality balance | 41.0% / 39.0% / 20.0% |
| Source diversity | 67 distinct source datasets; largest source is MMLU-Pro with 41 samples, 20.5% |
| Reported entropy | Parent 0.995, sub-domain 0.993, modality 0.960; source distribution 0.846 |
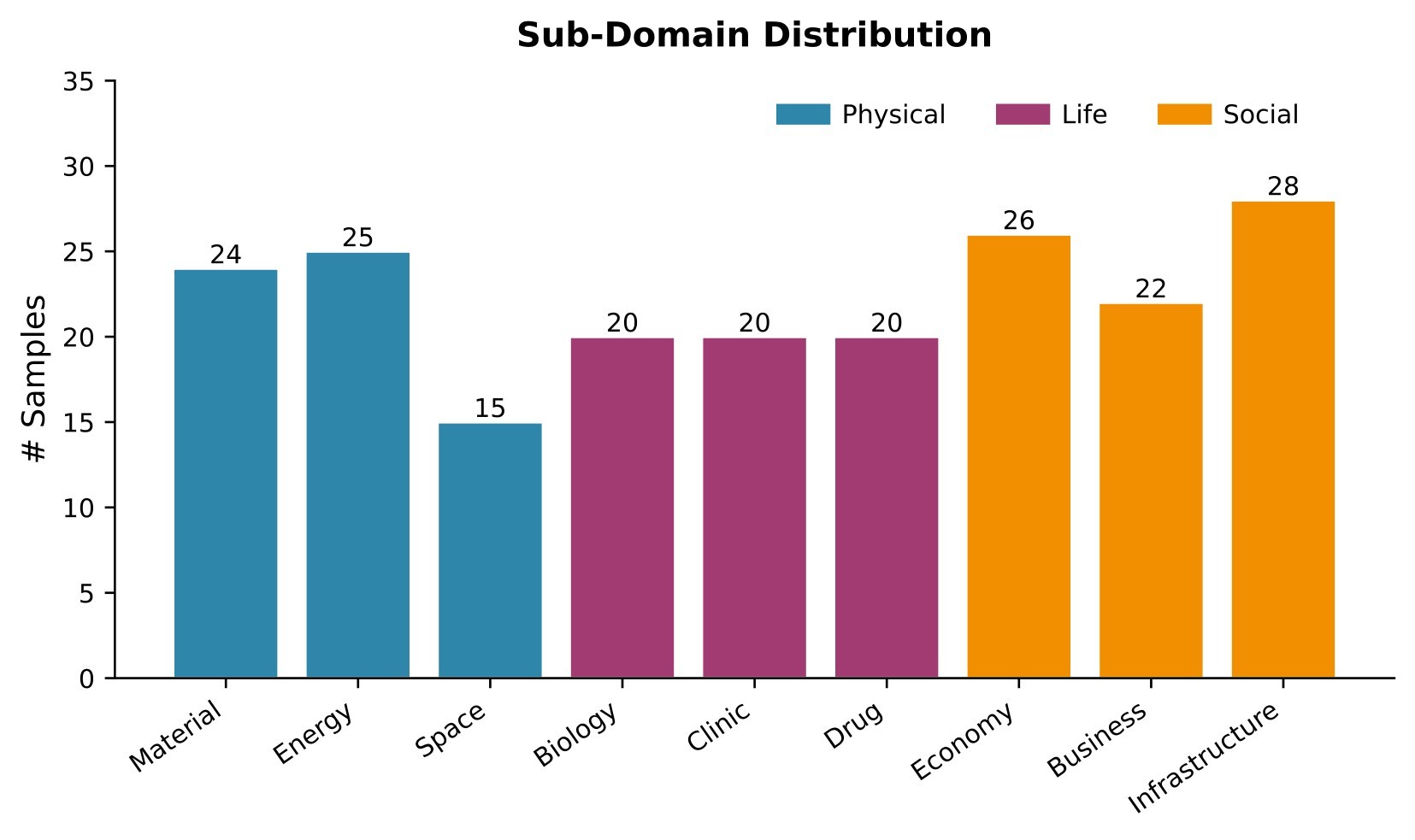
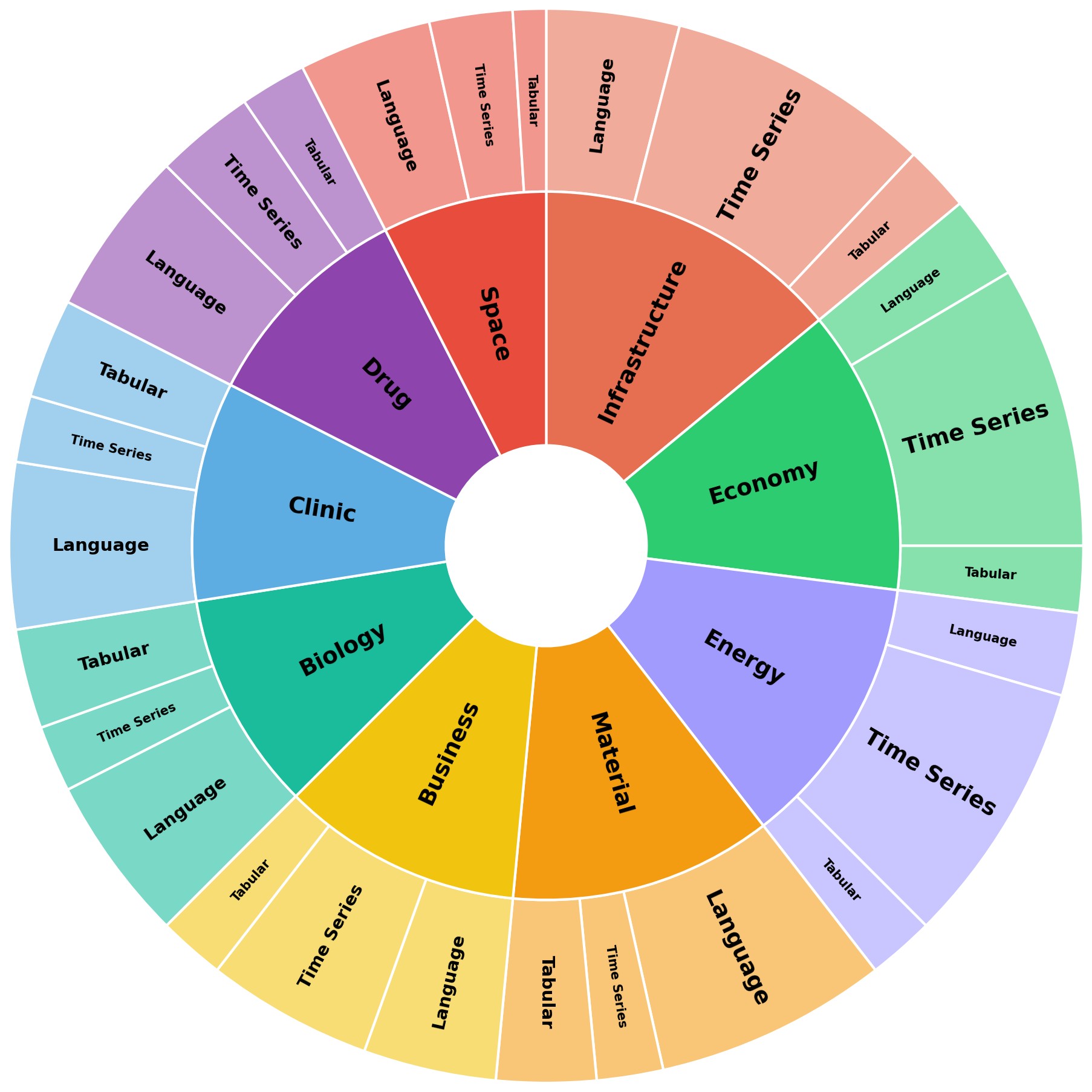
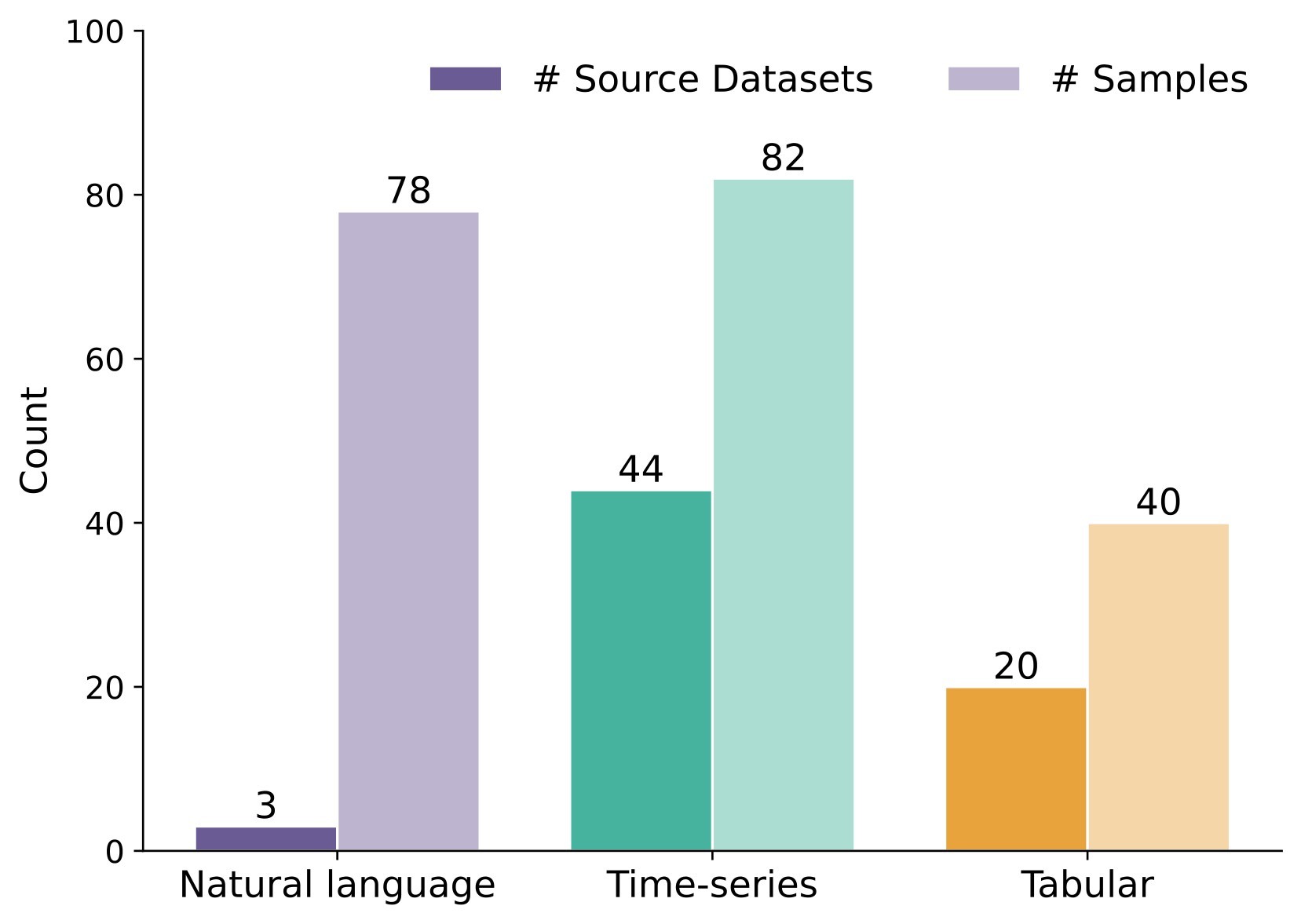
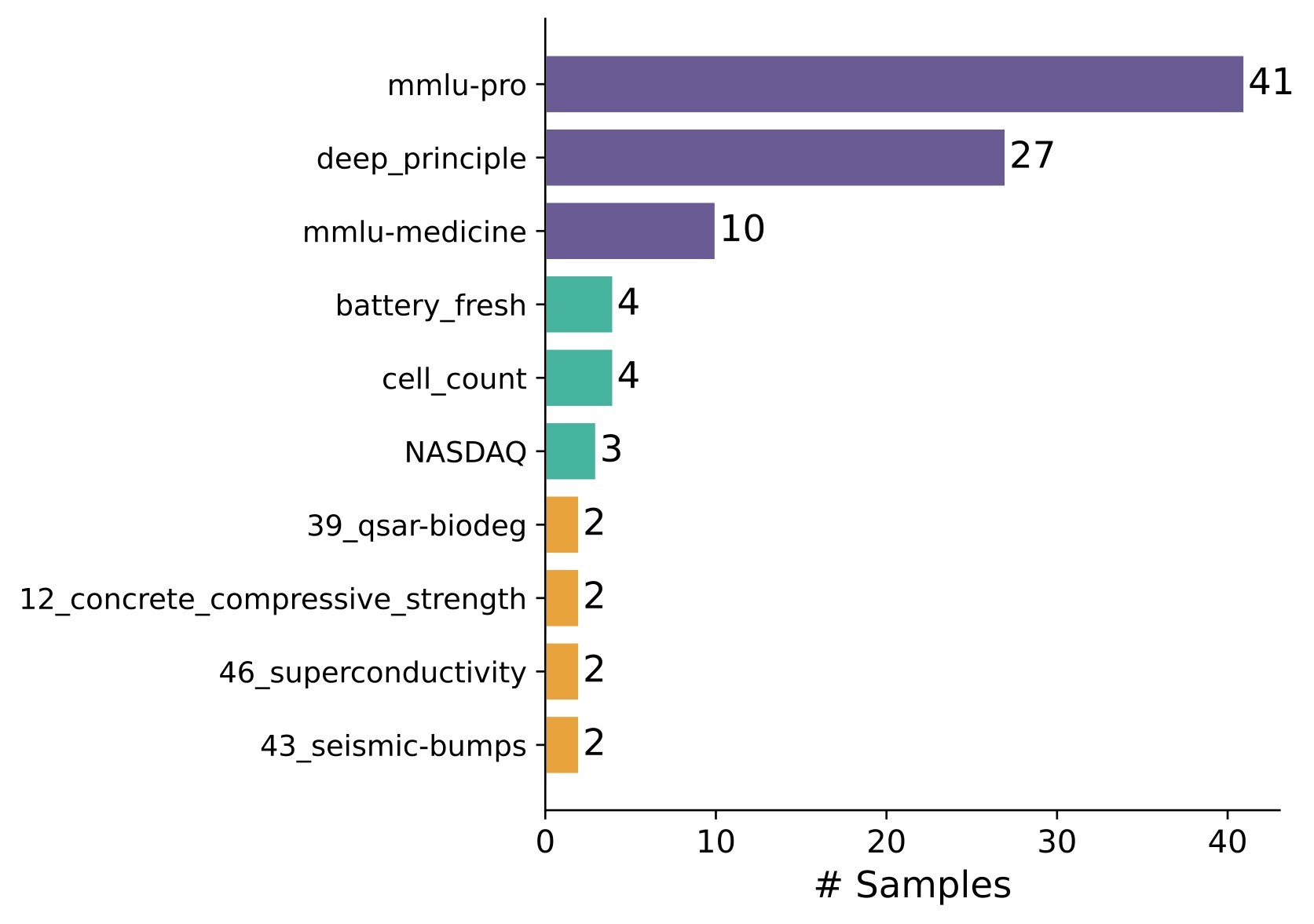
The benchmark uses a per-instance utility score u_i in [0,1] so heterogeneous outputs can be compared. Natural-language answers use exact match, numeric relative error, or lexical fallback. Time-series and tabular tasks use normalized prediction-error or classification/regression utility variants. The paper reports mean utility, runtime, and token consumption.
Evidence E5 - main results. The primary result is that Eywa improves the trade-off between task utility and token cost. Table 2 condenses the main comparison table, and Figure 4 shows the paper's utility-token visualization.
| Method | Setting | Overall utility | Overall time | Overall tokens | Main interpretation |
|---|---|---|---|---|---|
| Single-LLM-Agent | Single agent | 0.6154 | 25.22 | 4469 | Language-only baseline |
| EywaAgent | Single agent | 0.6558 | 22.78 | 3137 | +6.6% relative utility, -29.8% tokens vs Single-LLM-Agent |
| Refine MAS | Multi-agent | 0.6294 | 60.59 | 8673 | LLM-only MAS, higher cost |
| Debate MAS | Multi-agent | 0.6460 | 78.22 | 13216 | Stronger than single LLM, but costly |
| MoA | Multi-agent | 0.6273 | 57.75 | 15317 | Heterogeneous LLM-only ensemble |
| X-MAS | Multi-agent | 0.6188 | 77.42 | 16537 | Heterogeneous LLM-only MAS |
| EywaMAS | Multi-agent | 0.6761 | 72.11 | 11214 | Highest overall utility |
| EywaOrchestra | Dynamic orchestration | 0.6746 | 48.16 | 8335 | Near-EywaMAS utility with -25.7% tokens and -33.2% time vs EywaMAS |
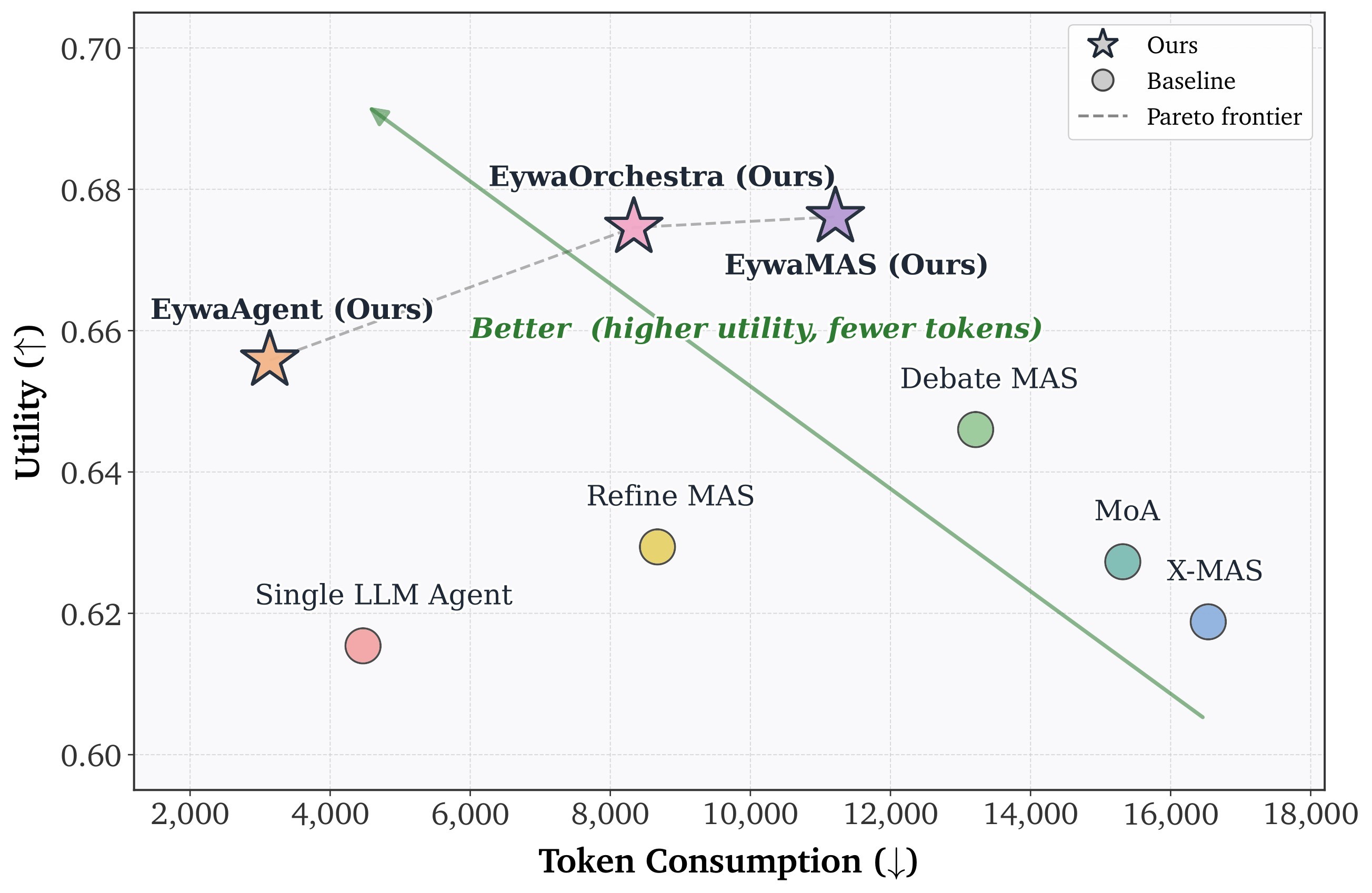
The most important reading of this table is not just that EywaMAS has the highest aggregate utility. It is that the family of Eywa methods changes the cost curve. EywaAgent already beats the single-LLM baseline while spending fewer tokens, and EywaOrchestra is almost tied with EywaMAS on overall utility while avoiding the full cost of a fixed expert-designed multi-agent system.
Evidence E7 - robustness and ablations. The paper reports temperature and prompt ablations, plus an LLM-backbone ablation. Figure 7 shows the three hyperparameter plots copied from the ranking cache, and Table 3 summarizes the compact backbone table.
| EywaAgent backbone | Physical utility | Life utility | Social utility | Overall utility | Overall time | Overall tokens |
|---|---|---|---|---|---|---|
| gpt-4.1-nano | 0.6547 | 0.4010 | 0.6269 | 0.5680 | 19.61 | 1139 |
| gpt-5-nano | 0.6914 | 0.5001 | 0.7488 | 0.6558 | 22.78 | 3137 |
| gpt-5-mini | 0.7191 | 0.5035 | 0.7444 | 0.6640 | 23.63 | 2444 |
The ablation supports two narrower claims. First, Eywa is not tied to exactly one LLM checkpoint: the same framework works with three LLM backbones. Second, the gains from scaling the LLM eventually shrink: the move from gpt-5-nano to gpt-5-mini improves overall utility only from 0.6558 to 0.6640, while several individual domains do not improve. That pattern is consistent with the paper's thesis that domain-native models, not just larger language models, are needed for structured scientific tasks.
The appendix case studies add qualitative support. A language-only agent can parse task format and produce a dataframe-style response while still collapsing to a last-value baseline on financial time-series forecasting. EywaAgent uses Chronos for the actual forecasting and leaves the LLM to parse, configure, verify, and format. EywaOrchestra similarly routes a house-price task to TabPFN when a lightweight tabular predictor is enough.
Practical Takeaways
1. Treat the LLM as the control plane, not the scientific engine. The strongest design pattern in the paper is to let the LLM parse task text, choose an action, and format the answer while a specialist model handles native time-series or tabular computation.
2. A small interface can unlock a large model family. The phi query compiler and psi response adapter are the key abstractions. Once a domain model is exposed behind a stable schema, it can be used by single-agent, multi-agent, and orchestration systems.
3. Measure utility and cost together. The headline result is not only "higher utility." EywaAgent is more useful than the single-LLM baseline while using fewer tokens, and EywaOrchestra is nearly as useful as EywaMAS with substantially lower token and runtime cost.
4. Dynamic orchestration is useful when task heterogeneity is real. The paper's own examples suggest that heavier multi-agent discussion is not always necessary. A conductor that selects a simple EywaAgent plus TabPFN can be better engineering than always running a fixed multi-agent topology.
5. The evidence is promising but not exhaustive. EywaBench-V1 is balanced and multi-modal, but it is still a 200-task controlled slice. The implementation uses two specialist models, Chronos and TabPFN. Extending the same pattern to vision, geospatial, simulation, molecular, and materials models would be the next real test.
6. For future systems, provenance should be explicit. Because the LLM is only coordinating specialist computation, the final answer should preserve which foundation model was invoked, what data was passed, and how the specialist output was adapted. That is a natural audit trail for scientific agents.
Reference Coverage
Anchor coverage for validation: fig-eywa-system, fig-eywaagent-design, fig-eywamas-design, fig-main-results, fig-benchmark-subdomains, fig-benchmark-hierarchy, fig-source-diversity, fig-hyperparameter-sensitivity, tbl-benchmark-coverage, tbl-main-results, tbl-backbone-ablation, evidence-interface-gap, evidence-key-equations, evidence-agent-design, evidence-orchestration, evidence-benchmark-design, evidence-main-results, evidence-robustness.