Source-first digest for monthly 2026_05 rank 7, rank_id p007.
- Routing status:
success - PDF extraction: not used
Motivation / Background
The paper argues that code should no longer be viewed only as something language models generate. In modern agent systems, code is also the runtime substrate that lets agents reason through execution, act through tools and policies, model environments through inspectable state, and revise behavior through feedback. This reframing matters because long-running agents fail less from one isolated bad completion than from weak surrounding systems: missing state, weak verifiers, unsafe tools, stale context, brittle memory, and poor coordination.
The source introduction separates three parts of an agent system: model-internal capabilities, system-provided harness infrastructure, and agent-initiated code artifacts. The paper focuses on the third part: code artifacts that agents create, execute, observe, revise, persist, and share inside the task loop. Figure 1 is the high-level taxonomy, and Table 2 compresses that taxonomy into the digest's layer map.
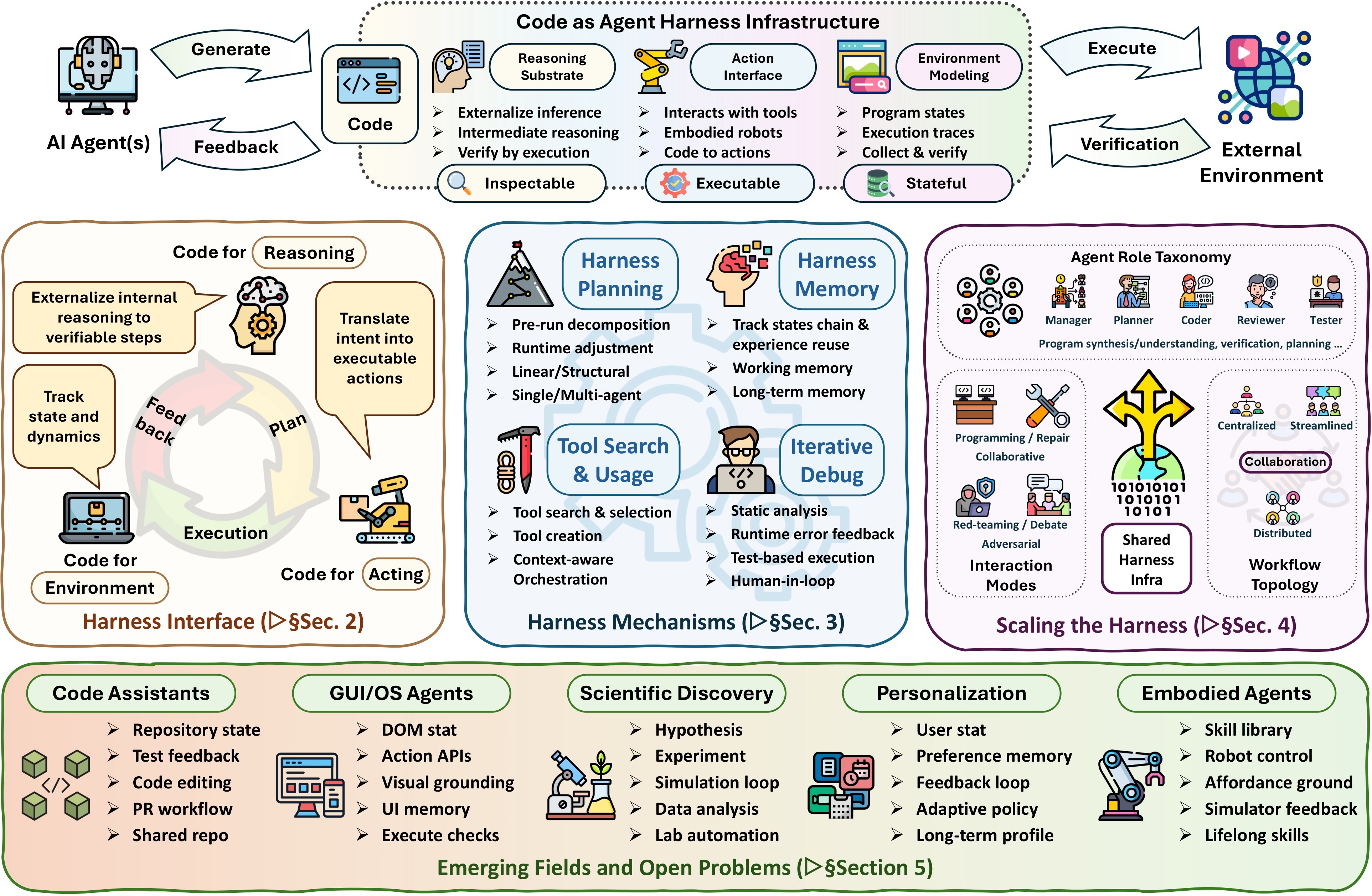
The paper's central contribution is therefore conceptual and synthetic: it gives a vocabulary for code-centered agent systems in which executable artifacts are the medium for reasoning, action, state, feedback, verification, and coordination. This is a useful lens for reading coding agents, GUI agents, embodied agents, scientific agents, personalization agents, DevOps workflows, and enterprise automation as variations of the same code-harness problem.
Claims And Evidence
The main claims are listed in Table 1. Support scores are support-from-paper scores, not independent reproduction scores. A score of 5 means the claim is directly backed by the source taxonomy, section structure, figures, or tables; a score of 4 means the paper makes a strong literature-synthesis argument but does not independently benchmark it.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Code is becoming an agent harness: an executable, inspectable, stateful medium for reasoning, acting, feedback, and verification, not just a generated artifact. | 5 | problem framing, taxonomy, Figure 1 |
| C2 | The survey's three-layer taxonomy, interface, mechanisms, and scaling, gives a coherent map of code-centered agent systems. | 5 | taxonomy, layer map, interface roadmap, mechanisms roadmap, MAS roadmap |
| C3 | At the interface layer, code plays three recurring roles: executable reasoning substrate, action interface, and environment/world representation. | 5 | interface evidence, Figure 2, Figure 3 |
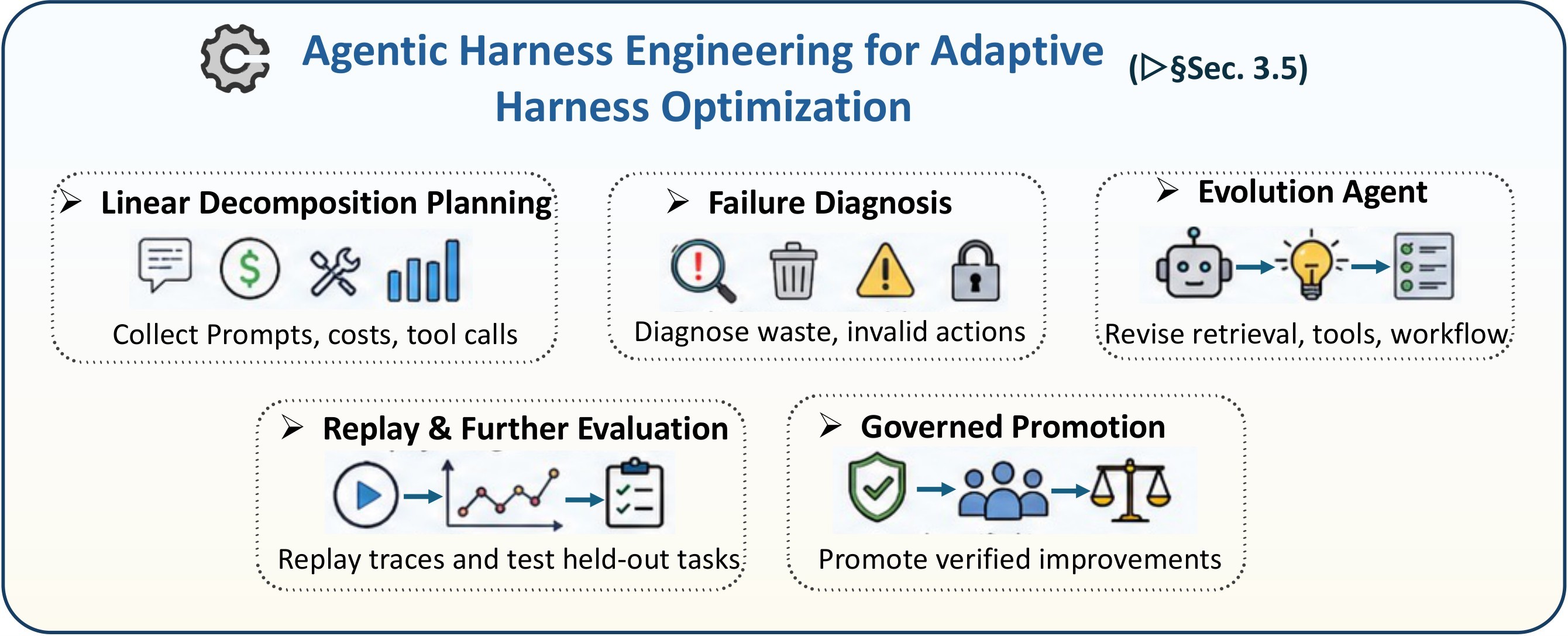
| C4 | Reliability depends on harness mechanisms around the model: planning, memory, tool use, Plan-Execute-Verify control, and adaptive harness optimization. | 5 | mechanisms evidence, mechanism map, PEV evidence, AHE evidence |
| C5 | Multi-agent coding systems need shared code-centric substrates because role specialization increases the cost of stale or inconsistent shared state. | 4 | MAS evidence, shared-state evidence, MAS state table |
| C6 | A major trend is that execution feedback bridges linguistic reasoning and formal verification, but only when the harness has adequate oracles and state representations. | 4 | patterns evidence, PEV evidence, open problem table |
| C7 | The code-as-harness view generalizes beyond coding assistants to GUI/OS agents, embodied agents, scientific discovery agents, and personalization systems. | 4 | applications evidence, Figure 12 |
| C8 | The open agenda is harness engineering: evaluation beyond final success, semantic verification, regression-free self-evolution, transactional shared state, governance, and multimodal grounding. | 5 | open problems, open problem table |
Core Technical Idea
The core idea is to make agent-initiated code artifacts first-class state in the agent loop. A code artifact is not merely an output string; it is something the harness can execute, inspect, store, test, diff, share, and roll back. This makes code a natural interface between model judgment and environment dynamics. Figure 2 shows the interface view, while Figure 3 places representative work into reasoning, acting, and environment-modeling roles.
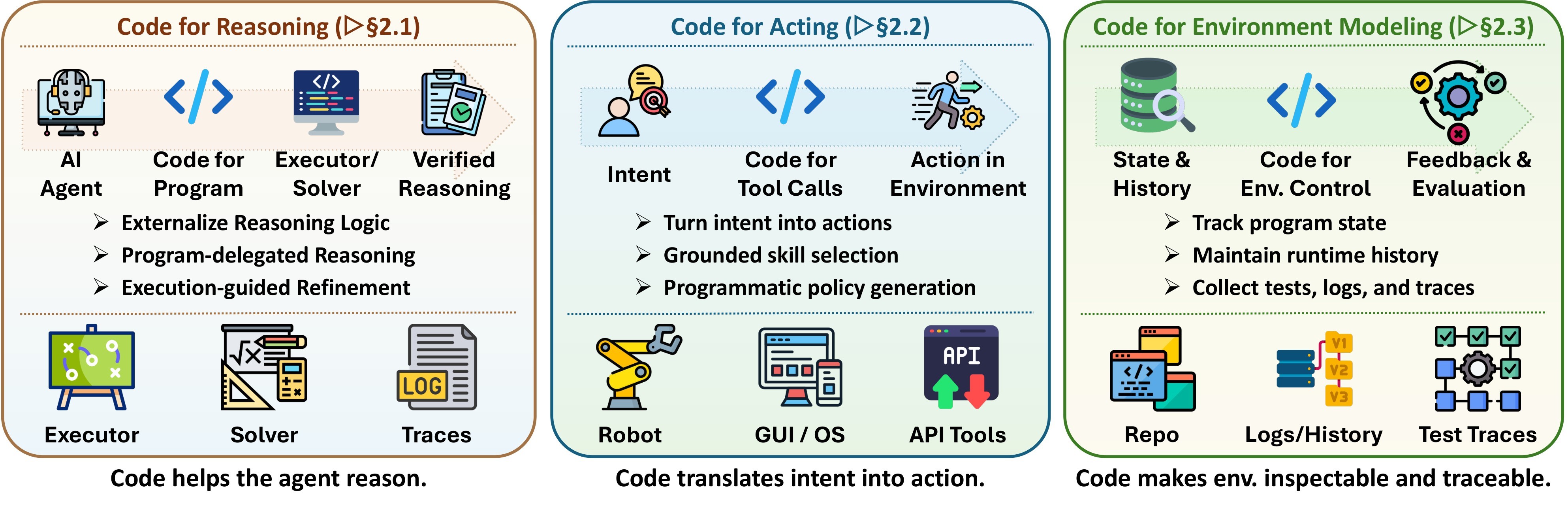
Table 2 is the digest's compact view of the paper's full taxonomy.
| Layer | What code does | Representative artifacts | Main failure pressure |
|---|---|---|---|
| Harness interface | Converts model outputs into executable reasoning, actions, and world-state representations. | Programs, symbolic specs, tool calls, policies, simulators, tests, traces. | Natural-language reasoning is hard to verify and transient. |
| Harness mechanisms | Keeps long-horizon agent loops bounded, observable, and revisable. | Plans, memory stores, tool schemas, sandboxes, validators, telemetry, permission tiers. | Agents need state, feedback, and governance beyond one generation step. |
| Scaling harness | Makes code a shared substrate for multiple specialized agents. | Repositories, blackboards, execution logs, role-specific patches, tests, workflow states. | Agents can diverge in belief, context, assumptions, and accepted state. |
Table 2. Three-layer code-as-harness map. This digest table synthesizes the source taxonomy and section organization.
The extraction equation index contains no substantive technical equation; it only captured a malformed author-affiliation display. The paper is nevertheless formal in several places through compact notations. The most useful notations are conceptual rather than algorithmic:
For GUI and OS agents, the paper models the environment as a partially observable program world:
For multi-agent synchronization, the important formal object is the gap between true shared program state and an agent's belief, summarized in the paper's discussion of belief divergence as \( |B_k - S_k| \). For score-based convergence, the survey cites the form \(s(r) = 1 - m(r) / tc(r)\), where a candidate program's mismatch count is normalized by test count. These notations are not the paper's main contribution; they support the larger claim that code-agent harnesses need explicit state, objective feedback, and convergence criteria.
Method Details
The paper's survey method is a taxonomy over code-centered agent systems. It does not introduce a new model or benchmark. Instead, it groups existing systems by the role code plays in the harness and then tracks what reliability problem each role solves.
At the interface layer, code has three jobs. First, code supports reasoning by externalizing intermediate computation into executable programs, symbolic solvers, proof scripts, traces, or process-reward units. Second, code supports acting by compiling high-level intent into robot policies, GUI actions, software commands, behavior trees, or reusable skills. Third, code supports environment modeling by representing state, dynamics, and evaluation through repositories, simulations, tests, logs, and executable world models.
At the mechanisms layer, the paper turns from what code is to how a harness manages code over time. Figure 4 gives the overview, and Table 3 summarizes the five mechanism families.
| Mechanism | Harness role | What the paper emphasizes | Digest reading |
|---|---|---|---|
| Planning | Decides what the agent should do next and when to revise. | Linear decomposition, structure-grounded planning, search-based planning, orchestration-based planning. | Planning is a contract over future state transitions, not just hidden reasoning. |
| Memory/context | Maintains task state across long interactions. | Working, semantic, experiential, long-term, multi-agent memory; compaction and state offloading. | Memory quality depends on provenance, write gates, retrieval keys, and evaluation reliability. |
| Tool use | Expands actions through governed executable interfaces. | Function tools, environment-interaction tools, verification tools, workflow orchestration tools. | Tools need schemas, permissions, lifecycle hooks, result sanitization, and traces. |
| PEV control | Regulates state transitions through plan, execute, verify. | Sandboxes, permission tiers, deterministic sensors, runtime feedback, human-review gates. | Debugging is better read as cybernetic control over executable state. |
| Harness engineering | Optimizes the harness itself using telemetry. | Deep telemetry, Evolution Agents, governed harness mutation. | The wrapper around the model is becoming a measurable, revisable software system. |
Table 3. Harness mechanism map. This digest table condenses the mechanisms section and its roadmap figure.
Figure 5, Figure 6, Figure 7, Figure 8, and Figure 9 are the paper's mechanism-specific roadmaps.
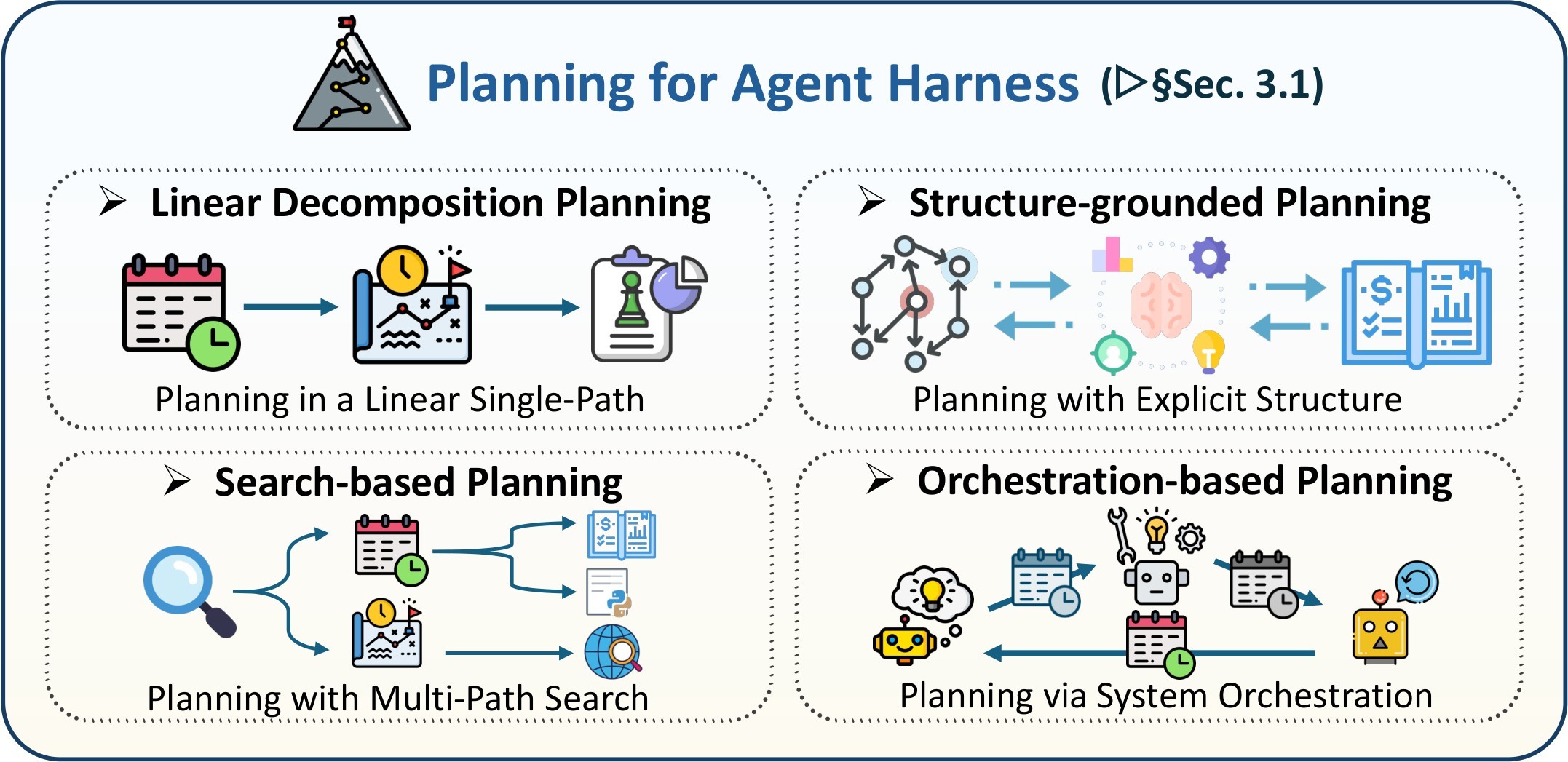
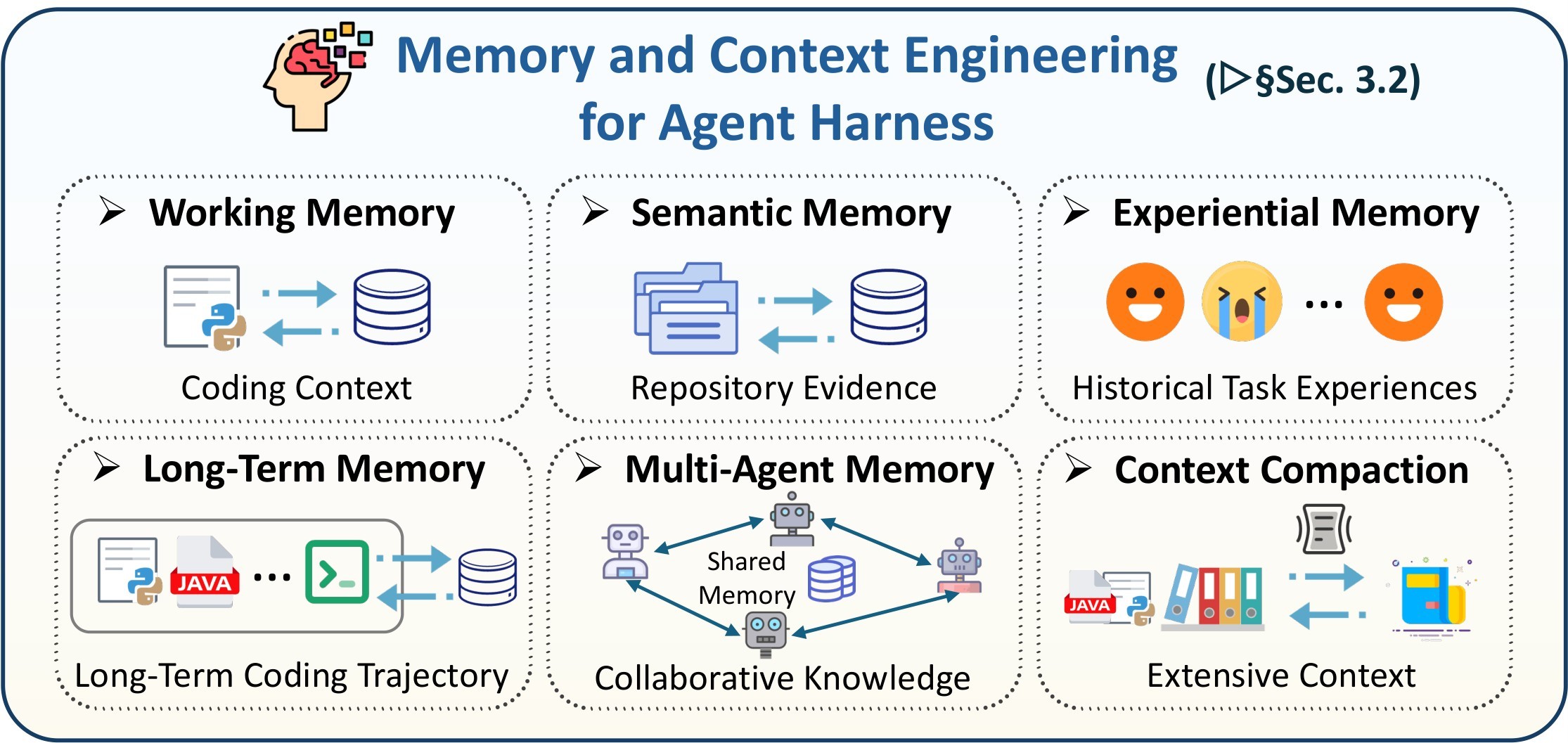
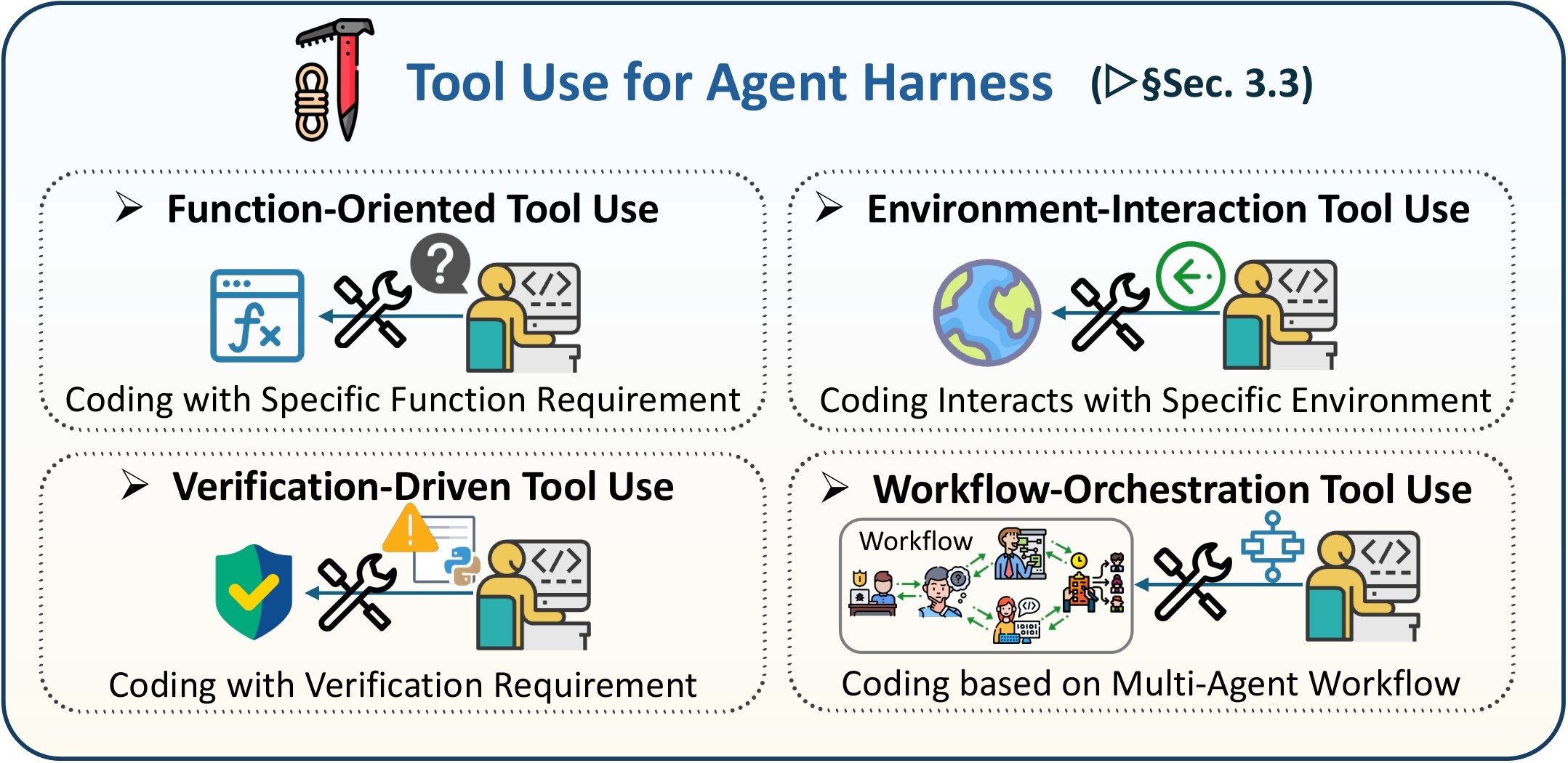
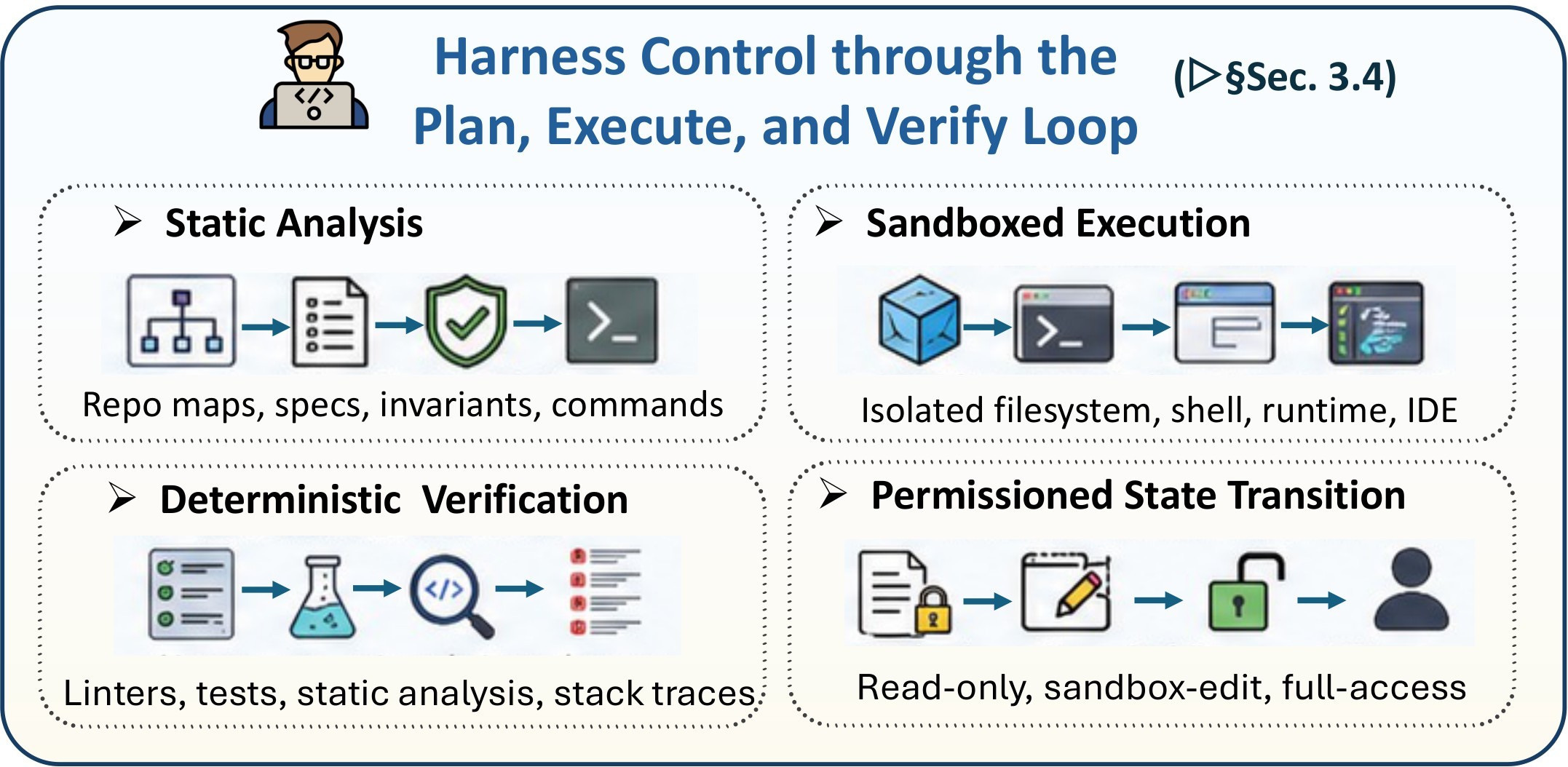
At the scaling layer, the paper argues that multi-agent systems make the shared-code problem unavoidable. A planner, coder, tester, reviewer, executor, and security checker may all be individually useful, but the system can still fail if they read different versions of the repository, optimize against different validators, or carry incompatible assumptions. Figure 10 and Figure 11 summarize this MAS layer.
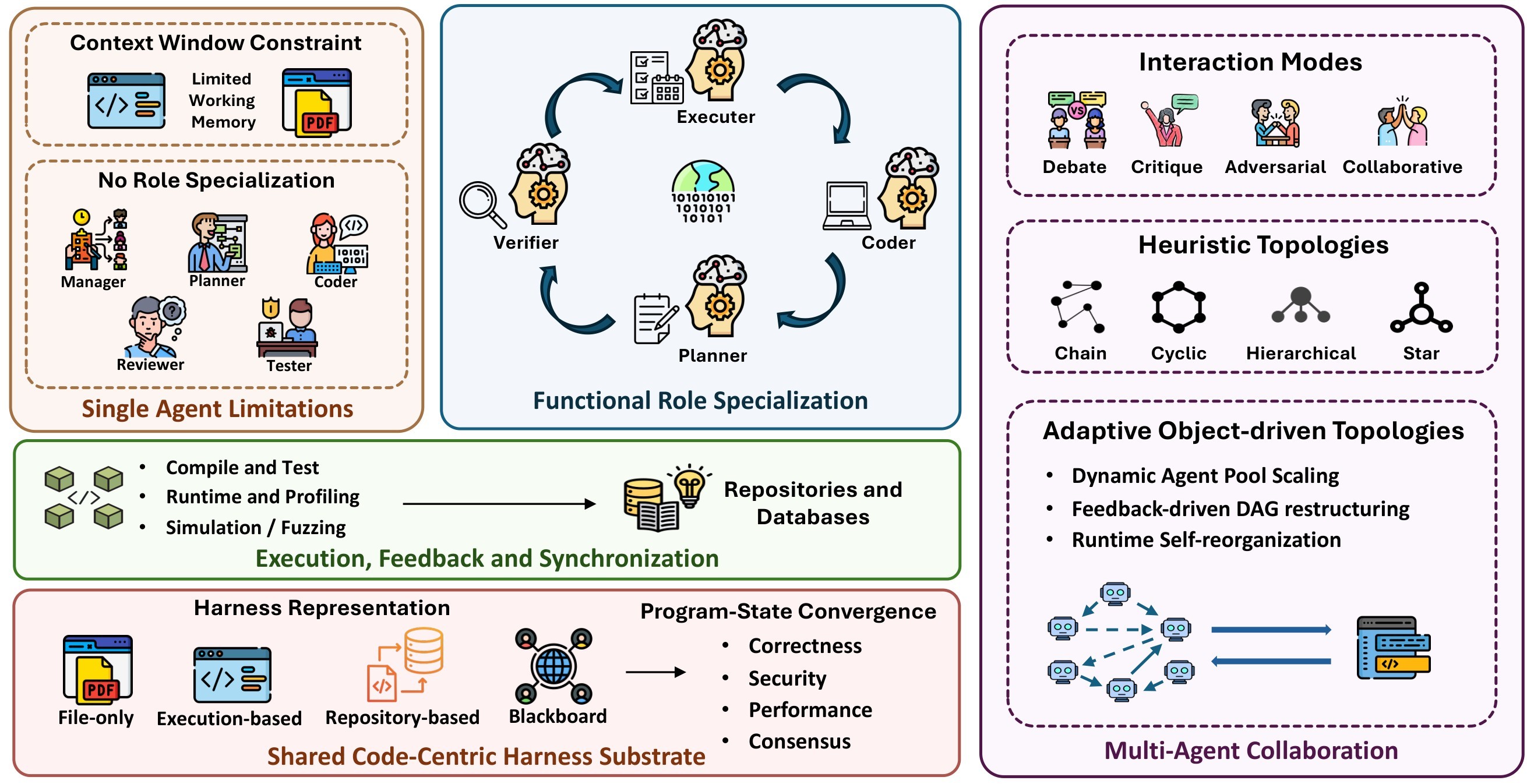
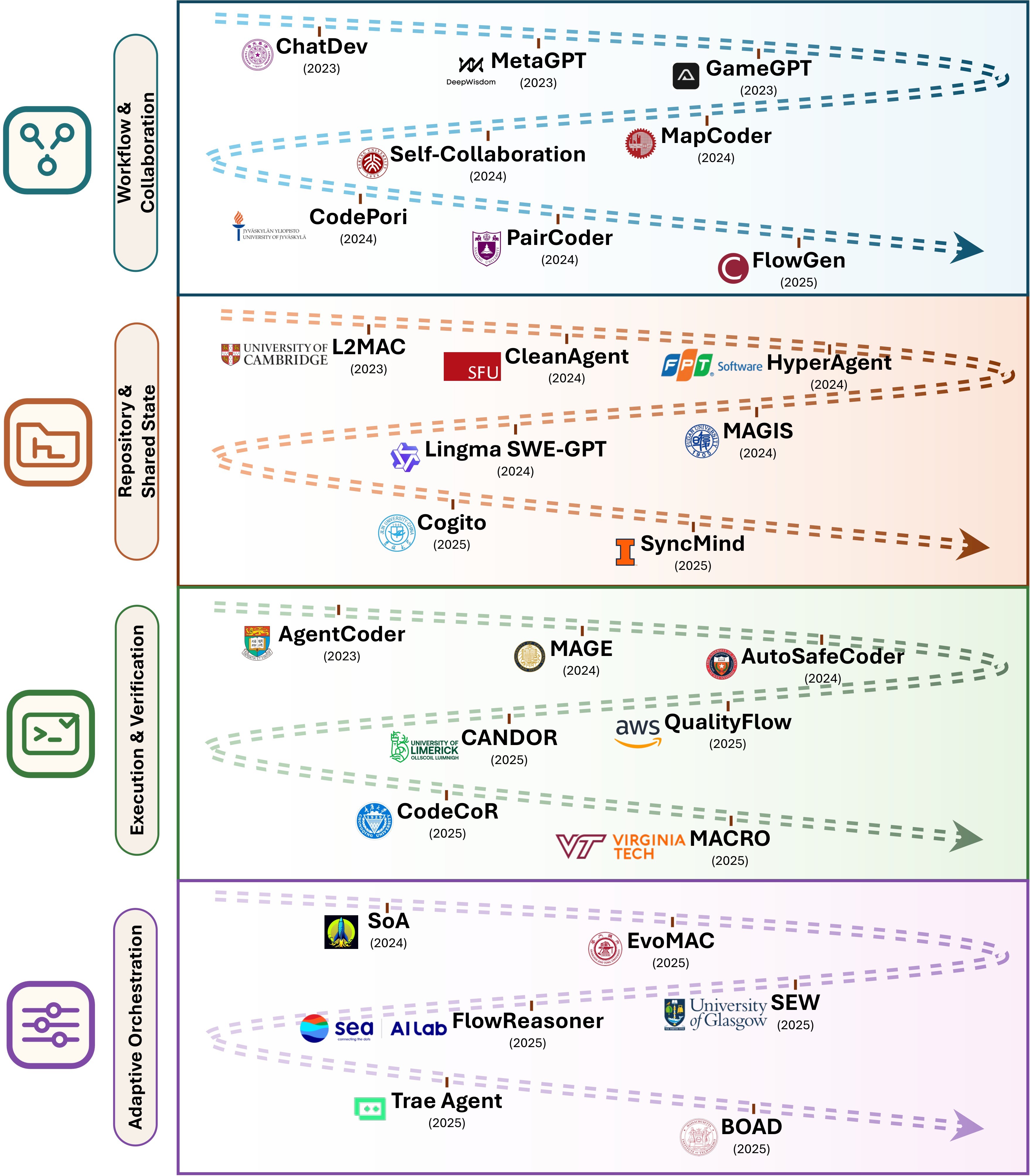
The survey's most actionable MAS distinction is the kind of shared state a system exposes. Table 4 summarizes the four representations discussed in the paper.
| Shared-state representation | What agents share | Strength | Limitation |
|---|---|---|---|
| Implicit / file-only | Latest code files or conversational context. | Simple and cheap. | State divergence is mostly invisible. |
| Repository-based | File tree, dependencies, call graphs, summaries, version history. | Good for localization and structural reasoning. | Can miss runtime behavior. |
| Execution-based | Test results, compiler diagnostics, traces, fuzzing, profiling, simulation snapshots. | Supplies objective oracle signals. | Only as strong as the attached verifier. |
| Blackboard / shared-state | Persistent global store or structured state graph. | Queryable, durable coordination substrate. | Needs authority, consistency, and conflict policies. |
Table 4. Shared code-harness representations. The paper's position is that most systems still lack a formal shared substrate despite code's unique ability to execute and produce objective signals.
Experiments And Results
This paper is a survey, so its "results" are structured synthesis results rather than new experiments. The most important empirical-style output is the pattern analysis in the multi-agent section and the cross-domain agenda in the final section.
The survey identifies seven recurring patterns:
- Implicit shared state is brittle. Systems that rely on conversational history or file-only exchange cannot reliably detect when an agent's belief diverges from the true code state.
- Code-mediated channels still compress information. Files, diffs, tests, logs, summaries, schemas, and blackboards each trade off fidelity, latency, and authority.
- Execution feedback is the bridge from language to formal evidence. Compilers, tests, simulators, fuzzers, profilers, and static analyzers provide signals that model self-critique cannot guarantee.
- Repository and execution views are complementary. Static structure answers "where is the relevant component"; runtime behavior answers "what happens when it runs." The paper argues that the field has not yet unified them into one mature substrate.
- Complex topology can compensate for weak shared state. Systems without formal state often add elaborate agent topologies, while systems with explicit state can use simpler workflows.
- Context management is the tax of implicit state. Long summaries, context scheduling, and agent pool scaling are often workarounds for not having a queryable state representation.
- Specialization increases the need for state metrics. More agent roles mean more opportunities for stale plans, inconsistent memories, and mismatched verification assumptions.
The applications section uses five domains to show that the framework is not limited to software engineering. Figure 12 is the paper's application map. Code assistants operate over repositories and tests; GUI/OS agents act in program worlds built from DOM trees, accessibility APIs, screenshots, and event loops; embodied agents use code as policy and skill memory; scientific agents turn hypotheses, experiments, and analyses into executable pipelines; personalization agents use code to represent preference state, feedback processing, constraints, and policy adaptation.
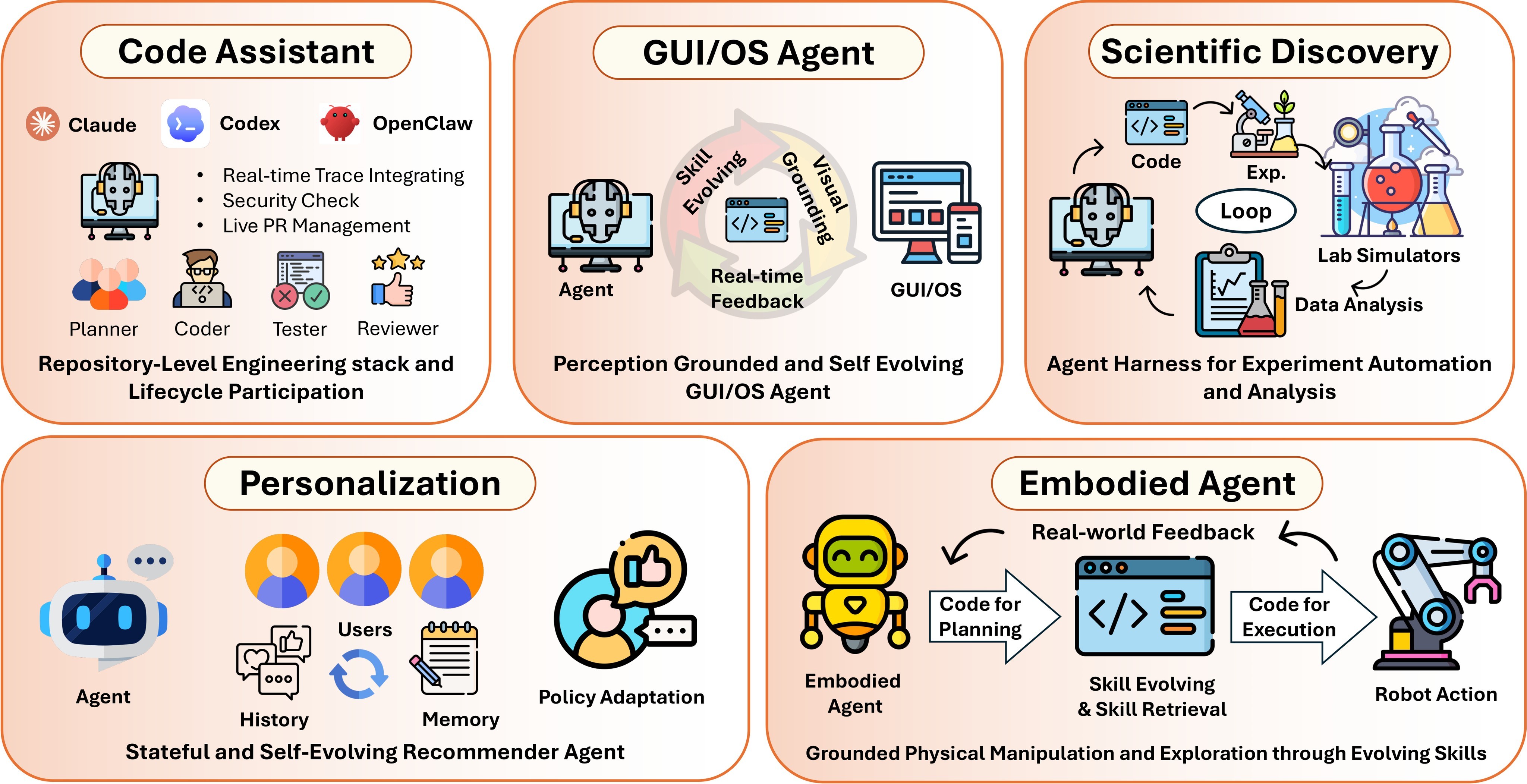
Table 5 summarizes the open agenda. The strongest through-line is that final task success is too weak a metric for agentic systems: a harness can pass a test while hiding weak oracle coverage, unsafe permissions, stale memory, or state conflicts.
| Open problem | Why it matters | Practical version |
|---|---|---|
| Harness-level evaluation and oracle adequacy | Final accuracy mixes model ability, tool quality, environment difficulty, and verifier strength. | Track trajectory cost, recovery, replayability, safety compliance, and verifier coverage. |
| Semantic verification beyond executable feedback | Green tests can be an incomplete proxy for the real specification. | Compose tests, static analysis, fuzzing, formal specs, critiques, coverage, and human review with explicit scope. |
| Self-evolving harnesses without regression | Harness changes affect future agent behavior and can overfit or weaken safety. | Treat harness mutation like safety-critical code: change contracts, regression suites, canaries, rollback. |
| Transactional shared program state | Multi-agent and human-agent workflows can conflict at the level of assumptions, not only file diffs. | Require read sets, write sets, version dependencies, verifier obligations, and conflict policies. |
| HITL safety and accountability as harness state | High-risk actions need enforceable gates, not prompt-only caution. | Store approvals, denials, risk tiers, audit evidence, and policy updates as durable state. |
| Multimodal code-harness systems | GUI, robotics, and scientific settings need visual/physical evidence, not just text logs. | Preserve raw observations, structured annotations, grounding contracts, and calibrated visual feedback. |
| Science of harness engineering | The field needs principles for the whole closed loop, not just better base models. | Build auditable telemetry, component metrics, and benchmarks that expose long-horizon harness failures. |
Table 5. Open harness-engineering agenda. The paper's future work section treats the harness as the main object of measurement, design, and governance.
Practical Takeaways
For builders of agent systems, the practical message is direct: make code artifacts and execution evidence first-class, durable, and auditable. A strong harness should not only call tools; it should record plans, state assumptions, permissions, tool arguments, command outputs, tests, failures, approvals, and rollback points.
The second takeaway is that memory and tool use should be designed together. A memory item is useful only if it preserves enough provenance to be checked against source state, and a tool result is useful only if the harness decides whether it should update memory, trigger verification, or remain transient.
The third takeaway is that multi-agent systems should start with shared-state design, not role taxonomy. Adding a planner, reviewer, or tester is cheap; keeping their beliefs synchronized with repository state, execution traces, and human constraints is the real systems problem.
The fourth takeaway is that self-improving harnesses need stronger governance than ordinary code edits. A new retrieval policy, tool schema, permission rule, or verifier can change future agent behavior. The paper's AHE framing suggests treating those changes as evidence-carrying, replayable, regression-tested software changes.
Limitations are also clear. The paper is a broad survey and position piece, not a controlled experimental comparison. Its support is strongest for taxonomy, synthesis, and design agenda claims; it is weaker for causal claims about which harness design is best under a fixed benchmark. The LaTeX extraction produced all twelve figures and a successful source-first route, but no substantive display-equation index, so this digest reports conceptual and inline formal notations rather than algorithm-specific equations.
Reference Coverage
Anchor coverage links: evidence-problem-framing, fig-taxonomy, evidence-taxonomy, table-claims, evidence-interface, fig-interface-overview, fig-interface-roadmap, table-layer-map, evidence-equation-note, evidence-mechanisms, fig-mechanisms-roadmap, table-mechanism-map, fig-planning, fig-memory, fig-tool, evidence-pev, fig-verification, evidence-ahe, fig-harness-engineering, evidence-mas, fig-mas-overview, fig-mas-roadmap, evidence-shared-state, table-mas-state, evidence-patterns, evidence-applications, fig-applications, evidence-open-problems, and table-open-problems.