Source-first digest for monthly 2026_05 rank 5, rank_id p008.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
Frontier models are now used as agents inside tool loops, file workspaces, and verifier-backed environments. In that setting, adaptation is often procedural rather than factual: the agent needs rules about how to inspect evidence, call tools, preserve file state, format answers, or stop looping. The paper's premise is that a skill document is a portable natural-language state for those procedures, and that this state should be trained rather than hand-written once.
The gap SkillOpt targets is that existing skill or prompt improvement methods are either manual, one-shot, or loosely self-revising. They can collect lessons from trajectories, but they usually lack the controls that make optimization reproducible: train/selection/test separation, bounded steps, rejected-update memory, and held-out acceptance. SkillOpt turns the skill into the only trainable object while the target model, harness, and evaluator stay fixed.
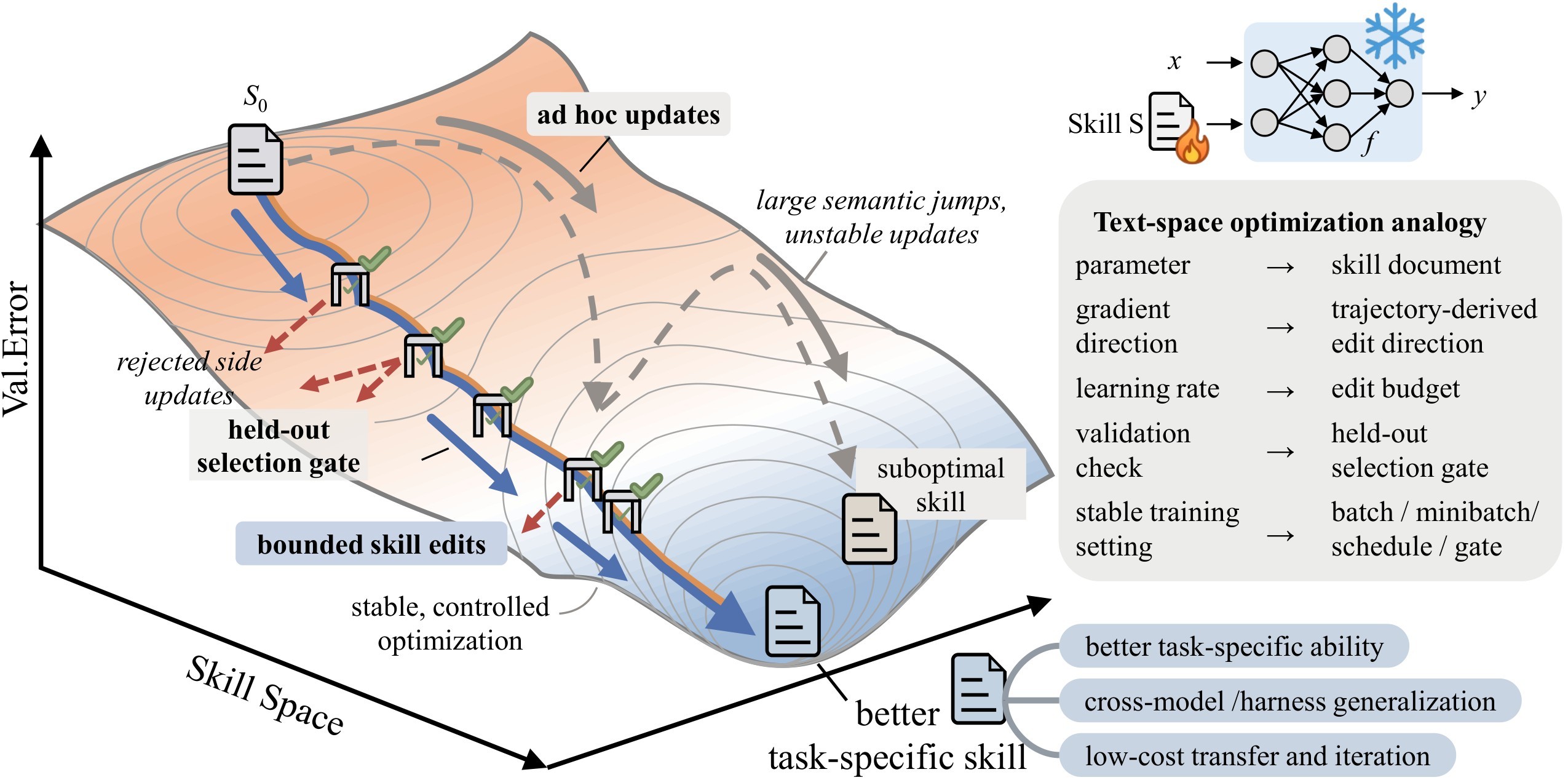
The high-level loop is shown in Figure 1: a frozen target model executes tasks with a current skill, a separate optimizer model proposes bounded edits from scored rollouts, and a held-out gate accepts only improving skill versions.
Claims And Evidence
Support scores are support-from-paper scores, not independent reproduction scores.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | A compact natural-language skill can be treated as the trainable external state of a frozen agent, with the target model and harness unchanged. | 4 | overview, objective, pipeline, harness adapter |
| C2 | Bounded text edits plus a strict held-out validation gate make skill revision more controlled than unconditional prompt or skill rewriting. | 4 | bounded updates, validation gate, component ablations, epoch curves |
| C3 | Across the reported benchmark matrix, SkillOpt is best or tied-best against no-skill, human, one-shot LLM, Trace2Skill, TextGrad, GEPA, and EvoSkill baselines. | 5 | direct results, harness results, headline aggregate |
| C4 | The exported skill behaves like a reusable artifact: it transfers across model scales, across Codex/Claude Code harnesses, and to a nearby math benchmark. | 4 | transfer summary, skill compactness, learned rules |
| C5 | The gains come from a small number of accepted, inspectable edits rather than from shipping a large optimizer transcript. | 5 | skill cost table, validation gate, learned rules |
| C6 | The method is most suitable when scored trajectories and a reliable held-out selection signal exist; open-ended domains need stronger evaluators. | 4 | limitations, objective, experimental protocol |
Core Technical Idea
SkillOpt defines a skill \(s\) as a natural-language policy inserted into the target agent context. For a frozen target model \(M\), harness \(h\), task \(x\), and skill \(s\), execution returns both a trajectory and a scalar score:
The loop separates training, selection, and test data. Training examples generate candidate skills, the selection split accepts or rejects candidates, and the test split is held out for final reporting:
The important design choice is that the optimizer does not change \(M\). It edits only the skill document, and only a validation-gated best_skill.md is deployed. The optimizer-side state can be richer during training: current skill, best skill, score cache, rejected-step buffer, and optional meta-skill guidance.
Method Details
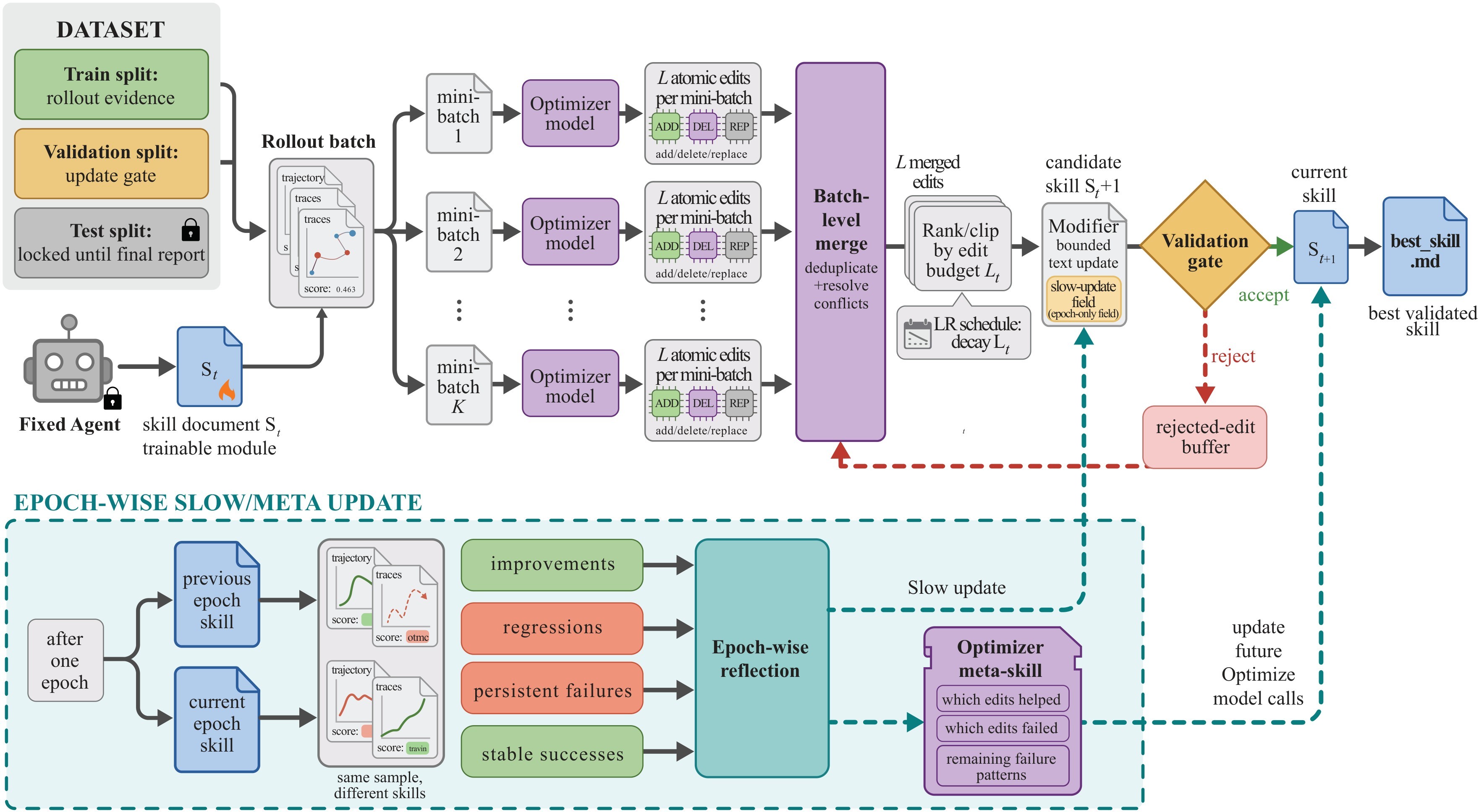
Forward Pass: Rollout Evidence
At each optimization step, the target model runs a batch of training tasks with the current skill. The harness records task metadata, messages, tool calls, observations, command outputs, final answers, verifier feedback, and compact execution traces when the environment has tools. Small batches update quickly but noisily; larger batches expose recurring failures before the skill changes.
Backward Pass: Minibatch Reflection
The optimizer model splits rollout evidence into failed and successful trajectories, then partitions each group into reflection minibatches. Failure minibatches propose missing or corrective rules. Success minibatches preserve behaviors that already work. The local proposals are merged hierarchically: failures and successes are consolidated separately, then a failure-prioritized merge removes duplicates, conflicts, and example-specific edits.
Bounded Text Updates
The textual learning rate is the edit budget \(L_t\), the maximum number of skill edits applied at step \(t\). After reflection and merging, the optimizer ranks proposed add/delete/replace edits and clips them to the top \(L_t\). The default schedule uses \(L_t=4\) with cosine decay and a floor of \(L_t=2\). This turns skill improvement into local patching rather than arbitrary rewriting, so a useful rule is less likely to be erased by the next update.
Validation Gate And Rejected-Edit Buffer
Every candidate skill is evaluated on \(D_{\mathrm{sel}}\) with the same frozen model and harness. It is accepted only if its selection score is strictly greater than the current score; ties are rejected. If the candidate also beats the previous best, it becomes best_skill.md.
Rejected edits are not discarded completely. SkillOpt records the failure patterns, attempted edits, and selection-score drop in an epoch-local buffer. Later reflection calls receive this negative feedback so the optimizer can avoid repeating failed edits. The rejected buffer is a training-time mechanism only: it does not add deployment-time calls.
Epoch-Wise Slow/Meta Update
SkillOpt also has a slower update path at epoch boundaries. It samples the same training items under the previous and current epoch-end skills, groups them into improvements, regressions, persistent failures, and stable successes, and asks the optimizer to write a compact longitudinal guidance block into a protected skill region. That candidate is still validation-gated. A separate optimizer-side meta skill summarizes which edit patterns helped or failed, but this meta skill is not shipped to the target model.
Harness-Agnostic Deployment
The adapter interface is simple: construct training/evaluation batches, inject the current skill into the agent context, run the native harness, and return scored trajectories. Direct chat prepends the skill to the system/developer prompt. The Codex and Claude Code harnesses render the current skill into a per-task workspace and return compact execution traces. All modes consume the same final best_skill.md, which is why the paper can test cross-harness transfer.
Optimizer Prompt Contracts
The appendix gives concrete JSON contracts for failure analysis, success analysis, failure merge, success merge, final merge, ranking, slow update, and optimizer memory. The patch representation is restricted to append, insert_after, replace, and delete; merge stages carry support_count and source_type; the slow-update region is protected by SLOW_UPDATE_START / SLOW_UPDATE_END; and every candidate goes through the same held-out gate. These safeguards matter because otherwise a strong optimizer could produce plausible but harmful rewrites.
Experiments And Results
The experiments cover six benchmark families: SearchQA, SpreadsheetBench, OfficeQA, DocVQA, LiveMathematicianBench, and ALFWorld. They use native hard-score or exact-match evaluators on held-out test splits. The suite spans single-round QA, spreadsheet code/tool use, local-document and multimodal-document reasoning, math multiple choice, and embodied sequential decision making.
The default optimizer setup is four epochs, rollout batch size 40, reflection minibatch size 8, 16 analyst workers, merge batch size 8, \(L_t=4\) with cosine decay, strict held-out gating, slow update with 20 sampled tasks per epoch, patch edit mode, and an optional rejected-edit buffer. Benchmarks with small training pools adjust batch sizes while keeping the same gate and slow/meta machinery.
Main Results
Table 1. GPT-5.5 direct-chat held-out test scores. This table condenses the main result matrix around the frontier target model. SkillOpt is compared with the no-skill row and the strongest competing baseline in each benchmark cell.
| Benchmark | No skill | Best competing baseline | SkillOpt | Gain over no skill |
|---|---|---|---|---|
| SearchQA | 77.7 | GEPA 84.8 | 87.3 | +9.6 |
| SpreadsheetBench | 41.8 | GEPA 73.6 | 80.7 | +38.9 |
| OfficeQA | 33.1 | Human skill 66.9 | 72.1 | +39.0 |
| DocVQA | 78.8 | Trace2Skill 90.6 | 91.2 | +12.4 |
| LiveMath | 37.6 | Trace2Skill 52.0 | 66.9 | +29.3 |
| ALFWorld | 83.6 | LLM skill 93.3 | 95.5 | +11.9 |
The paper's headline aggregate is that SkillOpt is best or tied-best on 52 of 52 evaluated model/benchmark/harness cells. On GPT-5.5 direct chat, the average rises from 58.8 with no skill to 82.3 with SkillOpt, a +23.5 point gain. The authors also report a +5.4 point gap over an oracle that picks the best competing baseline per cell, whose six-benchmark average is 76.9.
Harness Results
Table 2. GPT-5.5 harness-backed scores. ALFWorld is omitted in these harness rows because it requires persistent embodied-environment interaction outside the standard Codex and Claude Code adapters.
| Benchmark | Codex no skill | Codex EvoSkill | Codex SkillOpt | Claude no skill | Claude EvoSkill | Claude SkillOpt |
|---|---|---|---|---|---|---|
| SearchQA | 81.8 | 61.4 | 87.3 | 81.9 | 84.0 | 85.9 |
| SpreadsheetBench | 27.5 | 67.5 | 85.0 | 22.1 | 75.0 | 80.4 |
| OfficeQA | 38.3 | 42.4 | 51.1 | 57.6 | 70.3 | 71.5 |
| DocVQA | 87.2 | 89.3 | 92.2 | 86.6 | 87.2 | 90.1 |
| LiveMath | 35.2 | 63.2 | 78.4 | 40.8 | 52.0 | 56.5 |
The Codex harness average gain is reported as +24.8 over no skill and +14.0 over EvoSkill. The Claude Code harness gain is +19.1 over no skill and +3.2 over EvoSkill. The largest harness-side effect is SpreadsheetBench, where SkillOpt moves Codex from 27.5 to 85.0 and Claude Code from 22.1 to 80.4.
Ablations
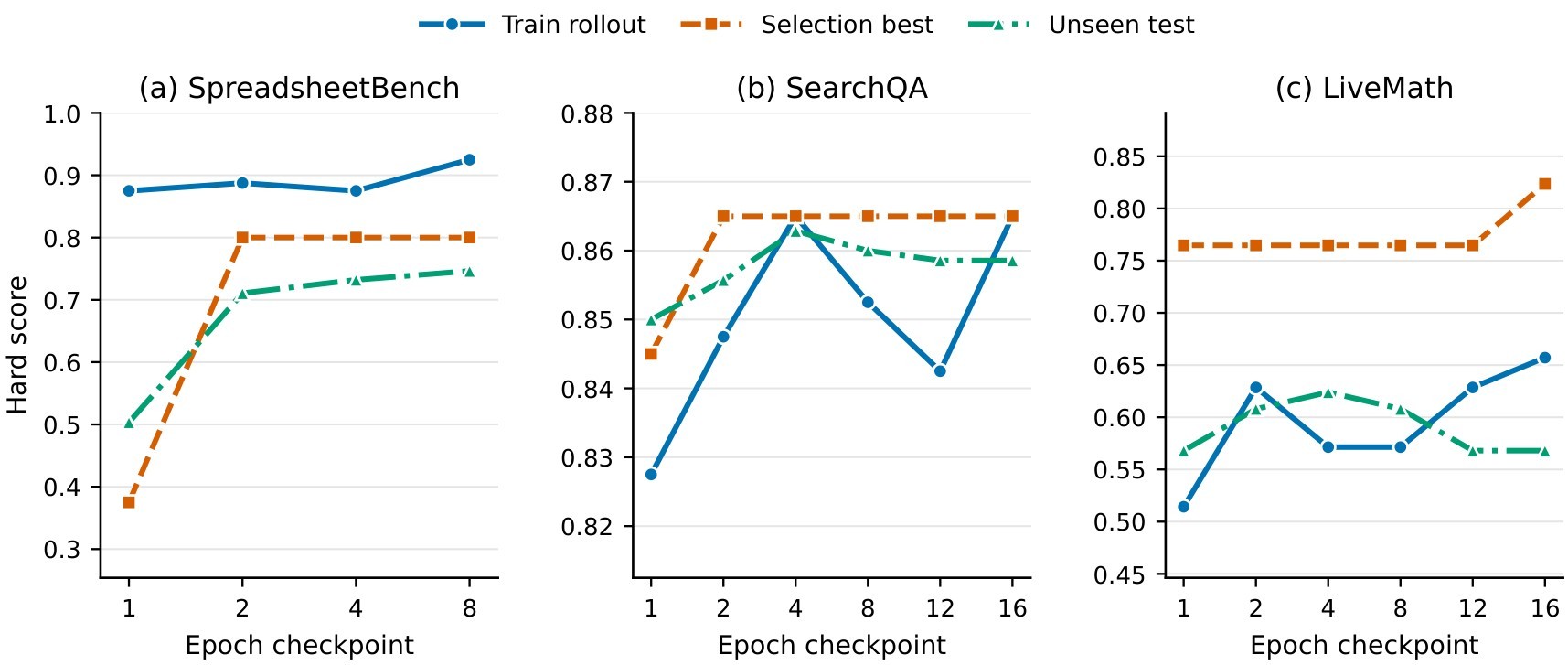
Table 3. Hyperparameter and evidence ablation summary. Scores are reported as SearchQA / SpreadsheetBench / LiveMath when all three appear.
| Factor | Main evidence |
|---|---|
| Training set size | SpreadsheetBench rises 47.5 -> 78.0 and LiveMath rises 59.1 -> 70.5 as training exposure grows from 1 example to 100 percent; SearchQA saturates around 84-86 after 20 percent. |
| Reflection minibatch size | Sweeping \(B_m=1\) to 32 keeps SearchQA in 85.9-87.1 and SpreadsheetBench in 75.4-77.9; default \(B_m=8\) is at or near the top. |
| Rollout batch size | Sweeping \(B=8\) to full epoch keeps SearchQA in 85.1-87.2 and SpreadsheetBench in 75.0-77.5. |
| Textual learning rate | \(L_t=4\) scores 86.5 / 78.2 / 56.5; \(L_t=8\) gives the highest LiveMath score, 66.9. |
| Scheduler | Constant scores 87.3 / 80.7 / 62.1, cosine scores 87.1 / 77.5 / 61.3, and linear scores 87.2 / 72.9 / 62.9. |
| Slow-update samples | The default 20 samples scores 87.1 / 77.5 / 61.3; 5, 10, and 40 samples remain within a few points but do not dominate the default. |
Table 4. Component ablations. The sharpest failure is removing both meta skill and slow update, which drops SpreadsheetBench from 77.5 to 55.0.
| Component group | Setting | SearchQA | SpreadsheetBench | LiveMath |
|---|---|---|---|---|
| Learning-rate form | lr=4 default | 87.1 | 77.5 | 61.3 |
| Learning-rate form | dynamic lr | 85.8 | 71.8 | 54.0 |
| Learning-rate form | without lr | 84.6 | 75.7 | 57.3 |
| Rejected buffer | with rejected buffer | 87.1 | 77.5 | 61.3 |
| Rejected buffer | without rejected buffer | 85.5 | 72.9 | 58.9 |
| Slow/meta update | meta skill and slow update | 87.1 | 77.5 | 61.3 |
| Slow/meta update | without meta skill | 85.1 | 75.7 | 58.1 |
| Slow/meta update | without meta skill and slow update | 86.3 | 55.0 | 59.7 |
The ablations support the method story: exact batch sizes and schedules are not fragile, but bounded text learning, validation gating, rejected-edit feedback, and epoch-level consolidation are the mechanisms that make skill editing behave like a controlled training loop.
Transfer
Table 5. Transfer summary. Direct is in-domain SkillOpt on the target setting; Transferred applies a source skill without further optimization.
| Shift | Source -> target | Benchmark | Baseline | Direct | Transferred |
|---|---|---|---|---|---|
| Cross-model | GPT-5.4 -> GPT-5.4-mini | SpreadsheetBench | 36.1 | 47.5 | 45.5 (+9.4) |
| Cross-model | GPT-5.4 -> GPT-5.4-nano | SpreadsheetBench | 23.5 | 42.5 | 26.5 (+3.0) |
| Cross-model | GPT-5.4 -> GPT-5.4-mini | LiveMath | 14.7 | 32.8 | 19.2 (+4.5) |
| Cross-model | GPT-5.4 -> GPT-5.4-nano | LiveMath | 23.2 | 27.2 | 28.8 (+5.6) |
| Cross-harness | Codex -> Claude Code | SpreadsheetBench | 22.1 | 80.4 | 81.8 (+59.7) |
| Cross-harness | Claude Code -> Codex | SpreadsheetBench | 27.5 | 85.0 | 71.1 (+43.6) |
| Cross-harness | Codex -> Claude Code | LiveMath | 40.8 | 56.5 | 42.4 (+1.6) |
| Cross-harness | Claude Code -> Codex | LiveMath | 35.2 | 78.4 | 48.0 (+12.8) |
| Cross-benchmark | OlympiadBench -> Omni-MATH, GPT-5.4 | Math | 56.6 | n/a | 60.3 (+3.7) |
| Cross-benchmark | OlympiadBench -> Omni-MATH, GPT-5.4-mini | Math | 34.8 | n/a | 36.6 (+1.8) |
| Cross-benchmark | OlympiadBench -> Omni-MATH, GPT-5.4-nano | Math | 38.8 | n/a | 40.1 (+1.3) |
The strongest deployment signal is the SpreadsheetBench cross-harness transfer: a Codex-trained skill transfers to Claude Code with +59.7 over the Claude baseline, and a Claude-trained skill transfers to Codex with +43.6. The paper interprets this as evidence that the skill learns workbook-level procedures rather than only harness-specific commands.
Optimizer Strength
Table 6. Strong versus target-matched optimizer. The optimizer is a training-time choice; the deployed skill still calls only the target model.
| Benchmark | Target | Baseline | Strong optimizer GPT-5.5 | Target-matched optimizer |
|---|---|---|---|---|
| SpreadsheetBench | GPT-5.4-mini | 36.1 | 47.5 (+11.4) | 43.2 (+7.1) |
| SpreadsheetBench | GPT-5.4-nano | 23.5 | 42.5 (+19.0) | 35.4 (+11.9) |
| SearchQA | GPT-5.4-mini | 75.9 | 80.2 (+4.3) | 78.3 (+2.4) |
| SearchQA | GPT-5.4-nano | 55.8 | 74.8 (+19.0) | 69.9 (+14.1) |
The strong optimizer wins on all four cells, but the target-matched optimizer still recovers 56-74 percent of the strong-optimizer gain. This makes the method more than a teacher-student distillation story: the gated optimization loop itself contributes value.
Learned Skill Artifacts
Table 7. Cost and edit economy of GPT-5.5 / GPT-5.5 skill runs. These are final best_skill.md token counts and accepted bounded updates.
| Benchmark | Initial tokens | Final tokens | Accepted edits | Train tokens | Cost / point |
|---|---|---|---|---|---|
| SearchQA | 16 | 857 | 4 | 213.8M | 37.9M |
| SpreadsheetBench | 224 | 1,995 | 4 | 21.4M | 0.6M |
| OfficeQA | 145 | 883 | 1 | 20.8M | 1.1M |
| DocVQA | 81 | 959 | 3 | 188.2M | 46.4M |
| LiveMath | 154 | 379 | 1 | 23.2M | 3.6M |
| ALFWorld | 516 | 1,321 | 2 | 59.3M | 15.9M |
Final skills stay between 379 and 1,995 tokens and require only 1-4 accepted edits. The paper emphasizes that the optimizer may propose far more changes, but the validation gate keeps the deployed artifact small rather than turning it into a transcript of every reflection.
Table 8. Text-only learned-rule figure. The source figure has no graphic asset in figures.json; the paper represents it as a boxed text figure. I reproduce the rules as a table rather than copying a nonexistent image.
| Benchmark | Representative learned rule |
|---|---|
| SearchQA | Infer the expected answer type from clue wording, then choose the shortest canonical entity supported by co-occurring distinctive evidence. |
| SpreadsheetBench | Inspect workbook structure and formulas, then write evaluated static values across the full requested target range instead of relying on Excel recalculation. |
| OfficeQA | Treat oracle parsed pages as primary evidence, lock table/date/unit context, and output exactly the requested rounded value without extra labels. |
| DocVQA | For tables, forms, charts, and legends, first bind the question to the exact visual row/header/field, then copy only the aligned answer span. |
| LiveMathematicianBench | In strongest-statement MCQs, rank choices by theorem strength and prefer a justified stronger-result option over true but weaker corollaries. |
| ALFWorld | Keep a horizon-aware visited/frontier ledger, diversify search after repeated same-type failures, and avoid revisiting the destination until holding the target. |
The learned rules are procedural, not instance-specific. They are also auditable: a practitioner can read the final skill, inspect accepted edits, and decide whether the rule is appropriate for deployment.
Qualitative Evolution
The paper closes with two qualitative case studies. In ALFWorld, the skill evolves from a generic search-transform-place plan into a more stateful policy with exact object-name matching, visited-location memory, destination memory, progress locks, and loop breakers. The reported held-out test score for this representative run improves from 49.3 to 74.6.
In SpreadsheetBench, the skill evolves from generic Python spreadsheet automation into workbook forensics: inspect the actual workbook, locate headers and target ranges across sheets, normalize keys and cell types, preserve formatting, write evaluated static values when the grader reads values, fill complete target ranges, keep helper computations in Python, and reopen the saved workbook to check boundary rows and blanks. The representative held-out test score improves from 40.4 to 78.9.
Limitations
SkillOpt needs reliable scored trajectories and a held-out selection split. The method is easiest to apply where exact-match metrics, executable checks, automatic verifiers, or stable task scorers exist. For subjective or multi-dimensional tasks, the validation gate would need stronger human or model-based evaluation. Training also costs extra rollout and optimizer-model calls, so the economics work best when a learned skill can be reused. Finally, a single skill may not cover highly heterogeneous domains, and transferred skills still need held-out evaluation because they can encode training-distribution heuristics.
Practical Takeaways
SkillOpt is most compelling when the domain has repeatable tasks, automatic scoring, and enough reuse to amortize offline optimization. The direct operational recipe is: maintain clean train/selection/test splits, collect trajectory evidence from the real deployment harness, make small patch-style skill edits, accept only strictly improving selection candidates, and keep rejected edits as negative feedback.
For agent engineering, the key idea is not "ask a stronger model to write a better prompt." It is to treat the skill as a versioned artifact with an optimization loop around it. The frozen target model remains fixed, the deployed artifact is just best_skill.md, and a stronger optimizer can be used offline without increasing inference-time cost.
The main caution is evaluation. The paper's strongest claims are backed by verifier-style benchmarks and held-out scores. For open-ended workflows, the validation gate is only as good as the evaluator, so a SkillOpt-style loop should not be trusted without a task-appropriate selection signal and post-transfer testing.
Reference Coverage
- Additional local references for validation and navigation: fig-epoch-curves, fig-skillopt-pipeline, table-component-ablation, table-gpt55-direct-main-results, table-harness-results, table-hyperparam-ablation.
- Additional local references for validation and navigation: table-learned-rules, table-optimizer-strength, table-skill-cost, table-transfer-summary.