Source-first digest for monthly 2026_05 rank 19, rank_id p009.
- Routing status:
success; routefull_markdown - Source repair: flattened TeX was used only to recover table cells that were dropped by Markdown conversion
- PDF extraction: not used
Motivation / Background
DelTA addresses a granularity mismatch in reinforcement learning from verifiable rewards (RLVR): the reward is a response-level scalar, but the policy update is applied through token-level probability terms. The paper starts from the observation that RLVR can induce sparse token-level distributional shifts even though every token in a response shares the same sequence-level advantage. This raises the central question: which token probabilities are increased or decreased by an RLVR update, and what determines those changes?
The paper's answer is that a sequence-level RLVR update implicitly behaves like a linear discriminator in token-gradient space. Positive-advantage responses and negative-advantage responses each contribute an aggregate token-gradient direction; a candidate token is locally encouraged when its own token-gradient vector aligns more with the positive aggregate than the negative aggregate. The main claims are summarized in Table 1.
The failure mode is subtle. Standard group-relative objectives build each side's aggregate as a centroid over all tokens on that side. But high-reward and low-reward reasoning traces share many high-frequency tokens, such as formatting markers, repeated problem entities, and boilerplate reasoning scaffolds. Those shared directions can pull both centroids toward common background structure, making the induced discriminator less sensitive to sparse directions that actually distinguish good from bad responses.
Claims And Evidence
Support scores in Table 1 are source-support scores, not independent reproduction scores. A score of 5 means the claim is directly backed by source text, equations, tables, or figures. A score of 4 means the source evidence is strong but still depends on assumptions such as benchmark representativeness, proxy validity, or single-paper experimental scope.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Sequence-level RLVR induces a local discriminator over token-gradient vectors, determining which candidate-token probabilities move up or down. | 5 | motivation, local discriminator, key equations |
| C2 | Standard side-wise centroids can be diluted by shared high-frequency token directions, so within-side summarization is not necessarily good between-side discrimination. | 4 | motivation, local discriminator, diagnostics |
| C3 | DelTA estimates discriminative token coefficients and reweights a self-normalized RLVR surrogate to make positive and negative effective centroids more contrastive. | 5 | method, implementation, Figure 1, key equations |
| C4 | On seven math benchmarks, DelTA beats the strongest same-scale baseline by 3.26 average points on Qwen3-8B-Base and 2.62 average points on Qwen3-14B-Base. | 5 | main results, Table 3, Figure 2 |
| C5 | The learned coefficients carry useful token-level signal: top-lambda token selection outperforms full-token DAPO while bottom-lambda token selection collapses. | 4 | diagnostics, Figure 3, Figure 4 |
| C6 | The benefit is not confined to the main Qwen3 math setup: the paper reports gains on Olmo3-7B, code generation, and OOD GPQA-D/MMLU-Pro. | 4 | generalization, Table 5 |
| C7 | The method is lightweight relative to RLVR training but still has caveats: proxy gradients, extra forward passes, mostly math-centered evaluation, and no independent reproduction in this digest. | 4 | implementation, limitations, Table 5 |
Core Technical Idea
The core move is to reinterpret the RLVR update as both a parameter update and a token-gradient classifier. For a candidate token \(x\) under context \(c\), a local first-order step gives:
For a DAPO-style group-relative RLVR objective, the local update direction decomposes into positive- and negative-advantage token-gradient aggregates:
After normalizing each side, the update can be written as a contrast between side-wise centroids:
Substituting this into the log-probability change makes the discriminator view explicit:
The candidate token is encouraged when the positive-side score exceeds the negative-side score. This explains why a response-level reward can still create sparse token-level probability movement: selection is induced by geometry in token-gradient space, not by explicit token rewards.
| Digest object | Source label | Role |
|---|---|---|
| Group-normalized advantage and importance ratio | unlabelled prelim equation | Defines the response-level advantage shared by every token in one sampled response. |
| DAPO clipped surrogate | unlabelled prelim equation | Provides the representative critic-free RLVR objective used for the local analysis. |
| Local token log-probability change | eq:local-logprob-change |
Connects a parameter update to candidate-token probability movement. |
| Local RLVR update | eq:local-rlvr-update |
Splits sampled-token gradients into positive and negative advantage sides. |
| Centroid decomposition | eq:centroid-decomposition |
Shows the update as a mass-weighted contrast between side-wise centroids. |
| Local discriminator score | eq:local-discriminator-score |
Makes the positive-vs-negative token-gradient scoring rule explicit. |
| DelTA assignment score | eq:DelTA-alpha |
Computes side-specific soft assignment scores from opposite-side distance margins. |
| DelTA weighted objective | eq:DelTA-weighted-objective |
Replaces uniform token averaging with bounded, self-normalized token coefficients. |
Table 2. Key equations. The source equations come from equations.json and paper.md; Table 2 is the digest's compact map of the mathematical flow.
Method Details
DelTA implements the discriminator view by assigning a coefficient to each rollout token. The method starts from the original positive and negative centroids, estimates how side-specific each token-gradient vector is, refines the centroids with those scores, maps the final scores to bounded coefficients, and uses the coefficients inside the RLVR surrogate. Figure 1 is the paper's overview of this pipeline.
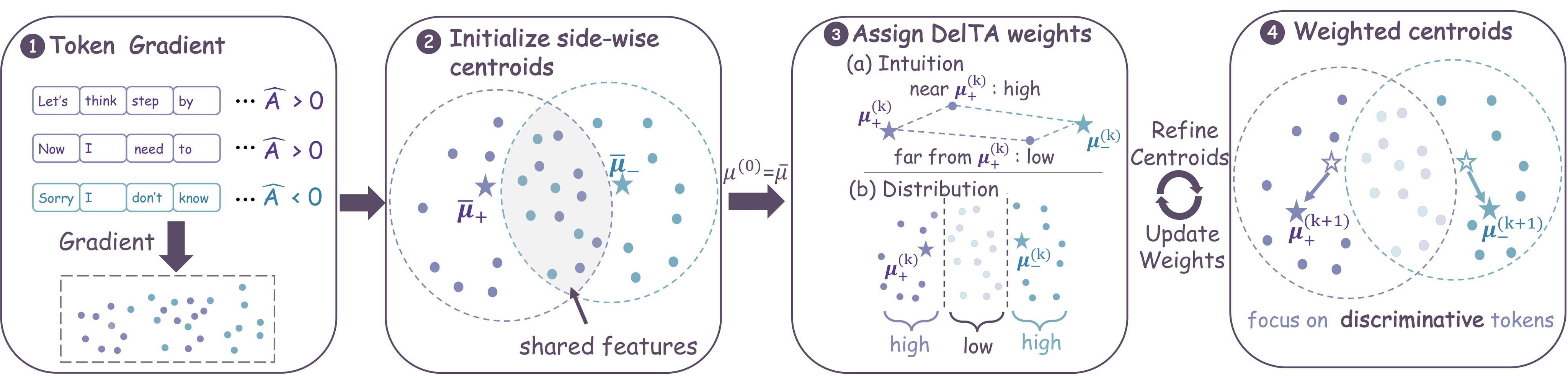
fig_0001, label fig:main, original LaTeX asset figs/main_4fin.pdf, copied from ranking cache local source artifact2026_05/assets/figures/p009/fig001_01_main_4fin.jpg.For a positive-advantage token, DelTA gives a larger raw score when its token-gradient vector is closer to the positive centroid than to the negative centroid. The source writes the entropy-regularized assignment in objective form and gives the closed-form score:
The score is high for token-gradient vectors that are more characteristic of their own side than of the opposite side. DelTA then updates each centroid as a score-weighted within-side average, recomputes final scores \(\alpha_{i,t}^{\star}\), maps them into \(\lambda_{i,t}=\lambda_{\min}+(\lambda_{\max}-\lambda_{\min})\alpha_{i,t}^{\star}\), and optimizes:
Implementation details matter because exact full-parameter token gradients would be too expensive at RLVR scale. DelTA uses a layer-restricted token-gradient proxy based on the LM-head output row:
This proxy is only used to compute stop-gradient coefficients; the weighted RLVR objective still updates the full model. In the main experiments, DelTA sets \([\lambda_{\min},\lambda_{\max}]=[0.8,1.2]\), uses one refinement iteration \(K=1\), computes coefficients once per rollout batch, holds them fixed across optimization epochs, and recomputes them for newly sampled trajectories. The implementation can keep the standard DAPO token-count normalizer by using \(\bar\lambda_{i,t}=\lambda_{i,t}N/Z\), which is equivalent to the self-normalized objective.
The paper reports that with \(K=1\), DelTA needs \(K+2=3\) extra actor forward passes for coefficient estimation when hidden states are not cached. On 8 NVIDIA B200 GPUs, the first DelTA training step takes 37 seconds longer than DAPO, reported as about 10.2 percent of the total first-step time of DelTA. That overhead is nonzero, but the paper argues it is modest relative to long-response RLVR rollout generation.
Experiments And Results
The main setup trains Qwen3-8B-Base and Qwen3-14B-Base on DeepMath-103K with VeRL, disables dynamic sampling for all methods, and compares DelTA against DAPO, DAPO with Forking Tokens, SAPO, and FIPO under the same training hyperparameters. Evaluation covers AIME24, AIME25, AIME26, HMMT25-Feb, HMMT25-Nov, HMMT26-Feb, and Brumo25, with 16 sampled responses per problem and 30,000-token maximum generation length. Table 3 condenses the source main-results table.
| Backbone | Method | AIME24 | AIME25 | AIME26 | HMMT25 Feb | HMMT25 Nov | HMMT26 Feb | Brumo25 | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Qwen3-8B-Base | DAPO | 34.79 | 23.33 | 24.17 | 13.54 | 12.08 | 16.86 | 36.46 | 22.95 |
| Qwen3-8B-Base | DAPO w/ FT | 36.67 | 23.96 | 26.46 | 15.62 | 15.42 | 17.05 | 39.17 | 24.80 |
| Qwen3-8B-Base | SAPO | 38.75 | 24.37 | 26.25 | 14.58 | 16.04 | 17.42 | 39.37 | 25.14 |
| Qwen3-8B-Base | FIPO | 37.50 | 23.13 | 23.96 | 14.58 | 12.92 | 17.99 | 37.71 | 23.89 |
| Qwen3-8B-Base | DelTA | 43.13 | 26.46 | 28.12 | 18.33 | 18.54 | 20.27 | 44.79 | 28.40 |
| Qwen3-14B-Base | DAPO | 51.25 | 32.29 | 39.79 | 19.79 | 30.00 | 25.38 | 48.13 | 35.09 |
| Qwen3-14B-Base | DAPO w/ FT | 54.37 | 33.75 | 41.46 | 20.42 | 31.67 | 24.81 | 52.08 | 36.77 |
| Qwen3-14B-Base | SAPO | 53.96 | 34.17 | 41.46 | 20.62 | 28.33 | 24.05 | 50.21 | 35.94 |
| Qwen3-14B-Base | FIPO | 54.58 | 35.00 | 42.50 | 21.46 | 32.29 | 24.43 | 52.08 | 37.29 |
| Qwen3-14B-Base | DelTA | 56.87 | 37.92 | 45.21 | 26.04 | 32.92 | 26.89 | 54.79 | 39.91 |
Table 3. Main math results. DelTA has the best average at both scales and beats the strongest same-scale baseline average by 3.26 points on Qwen3-8B-Base and 2.62 points on Qwen3-14B-Base.
Figure 2 supports the claim that DelTA's gains are not just a shorter-answer effect: the paper reports that DAPO plateaus and shifts toward shorter responses with rising entropy, while DelTA continues improving reward, maintains longer responses, and has lower entropy.
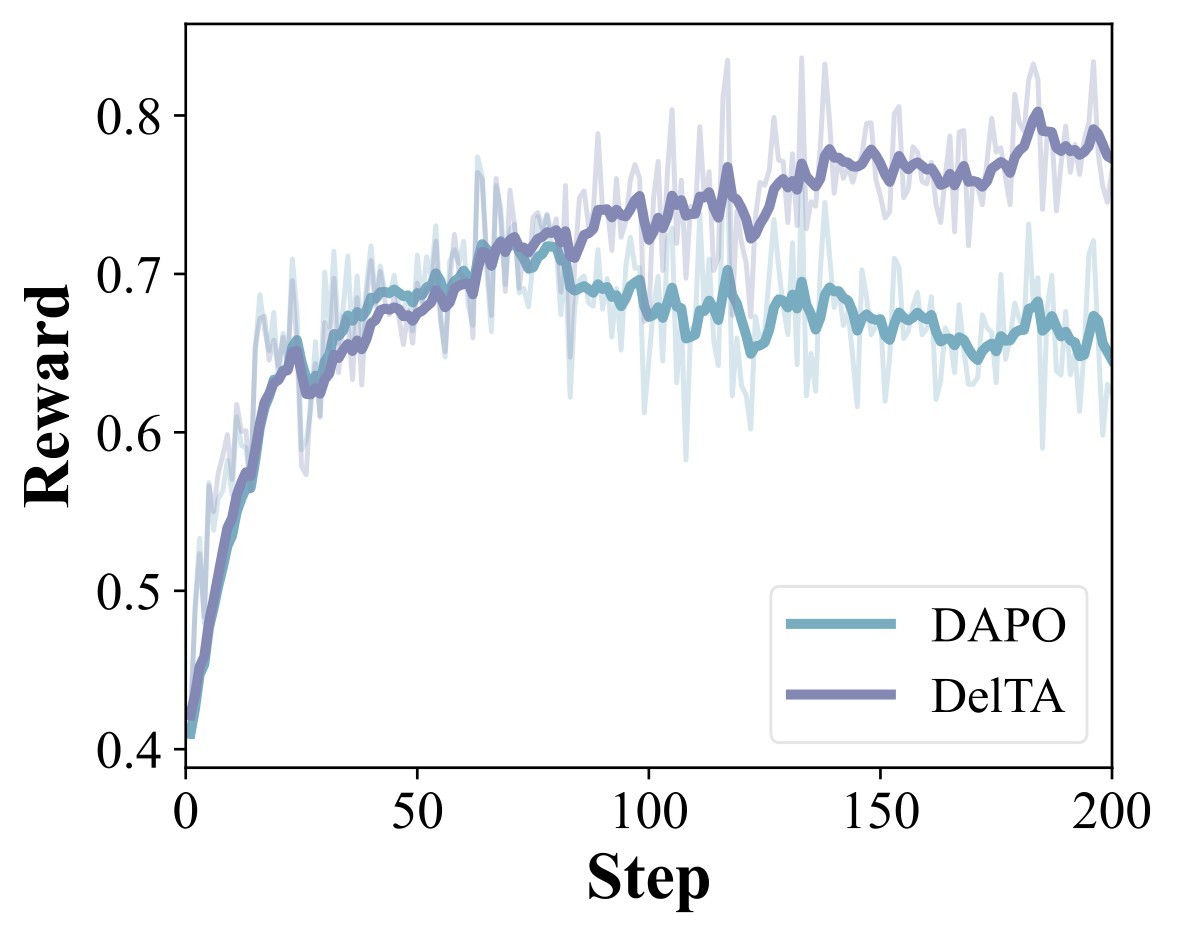
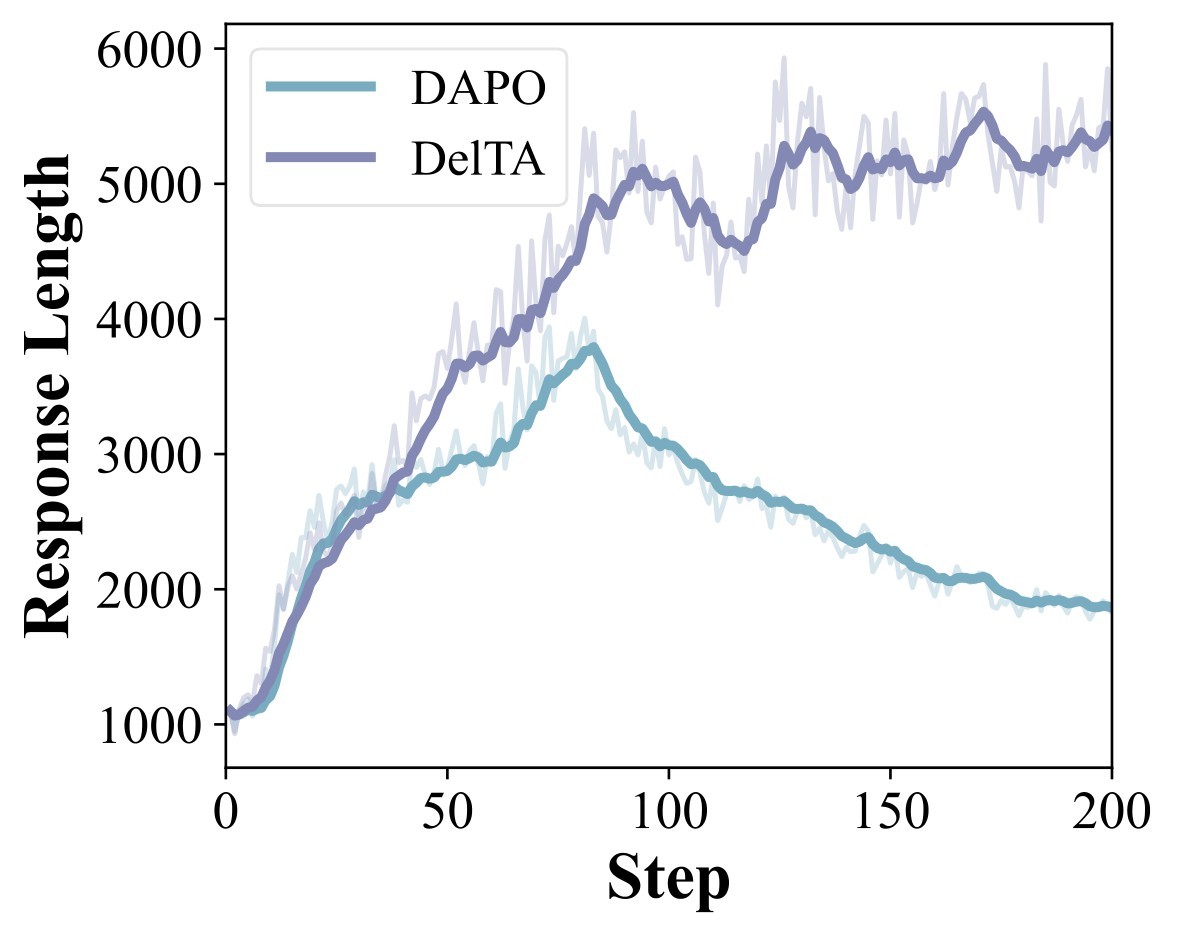
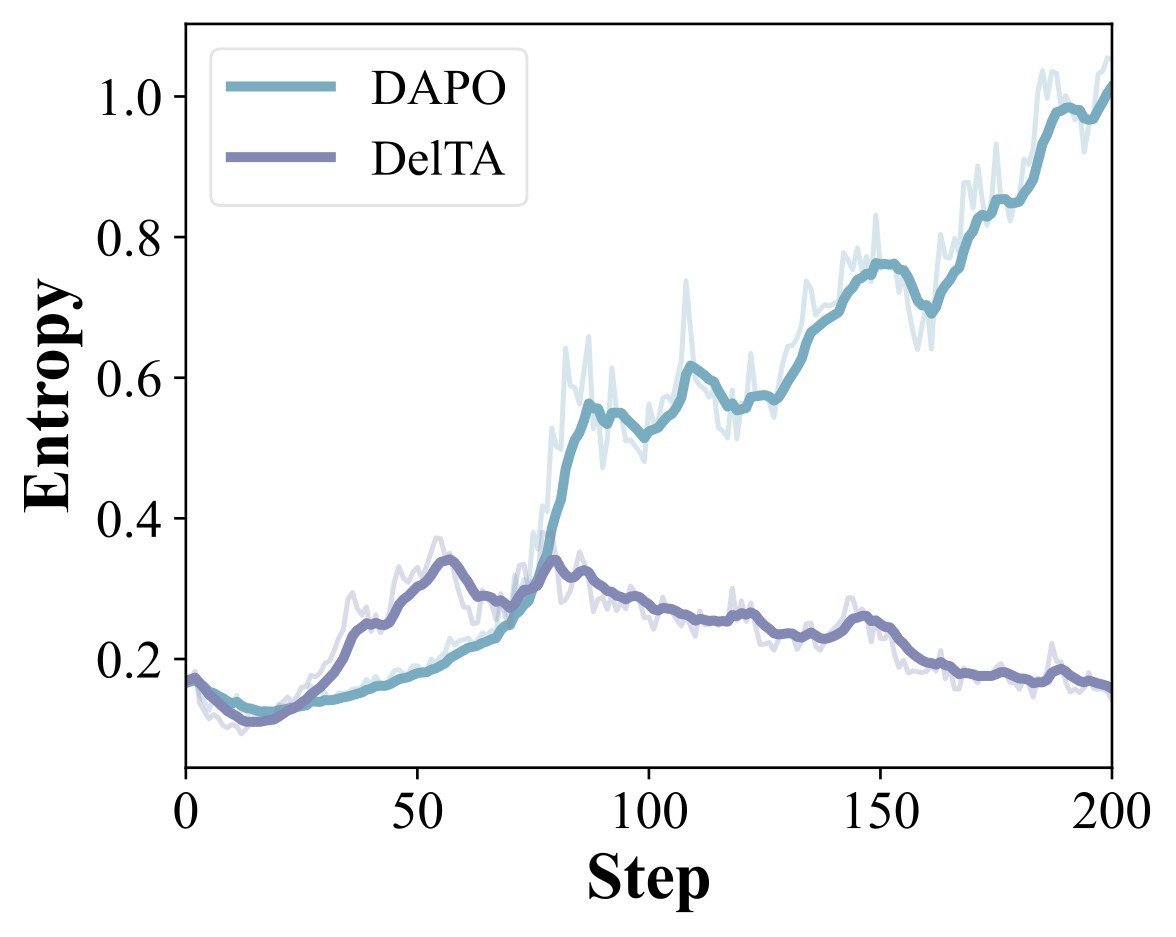
fig_0002, label fig:training_dynamics, original LaTeX assets figs/dyna/reward.pdf, figs/dyna/leng.pdf, and figs/dyna/entropy.pdf, copied from ranking cache files fig002_01_reward.jpg, fig002_02_leng.jpg, and fig002_03_entropy.jpg.The analysis section asks whether the opposite-side comparison and the coefficient design are actually necessary. Table 4 collects the quantitative diagnostic rows, while Figure 3 and Figure 4 show source visual evidence for token selection and token-weight interpretation.
| Diagnostic | Setting | AIME25 | AIME26 | HMMT25 | HMMT26 | Avg. | Interpretation |
|---|---|---|---|---|---|---|---|
| Within-side comparison | DelTA | 26.46 | 28.12 | 18.54 | 20.27 | 23.27 | Reference. |
| Within-side comparison | DAPO | 23.33 | 24.17 | 12.08 | 16.86 | 19.05 | Baseline. |
| Within-side comparison | Within-side only | 21.67 | 22.08 | 11.04 | 17.05 | 17.94 | Own-side centrality alone is worse than DAPO. |
| Component ablation | Full DelTA | 26.46 | 28.12 | 18.54 | 20.27 | 23.27 | Reference. |
| Component ablation | w/o adaptive \(\gamma\) | 25.00 | 26.04 | 16.04 | 17.99 | 21.19 | Scale adaptation helps. |
| Component ablation | w/o \(h(\alpha)\) | 24.37 | 26.87 | 15.42 | 17.42 | 20.93 | Soft assignment helps. |
| Component ablation | w/o \(\lambda\)-norm | 24.37 | 26.25 | 15.83 | 19.32 | 21.39 | Coefficient-mass normalization helps. |
| Component ablation | w/o range map | 24.79 | 25.83 | 15.83 | 17.05 | 20.78 | Bounded coefficients are more stable than raw scores. |
| Component ablation | w/o refinement | 23.13 | 25.42 | 15.42 | 16.29 | 19.97 | One-shot initial centroids are insufficient. |
| Proxy ablation | Base DelTA | 26.46 | 28.12 | 18.54 | 20.27 | 23.27 | Default output-row proxy. |
| Proxy ablation | Top-\(K\) hidden-gradient proxy | 27.08 | 27.71 | 20.83 | 21.78 | 24.29 | Another proxy can work even better. |
| Proxy ablation | Random \(\lambda\) | 22.50 | 22.50 | 11.87 | 16.67 | 18.34 | Random reweighting is not enough. |
Table 4. Diagnostics. The results support the paper's claim that opposite-side contrast, bounded soft coefficients, refinement, normalization, and non-random coefficient signal each matter.
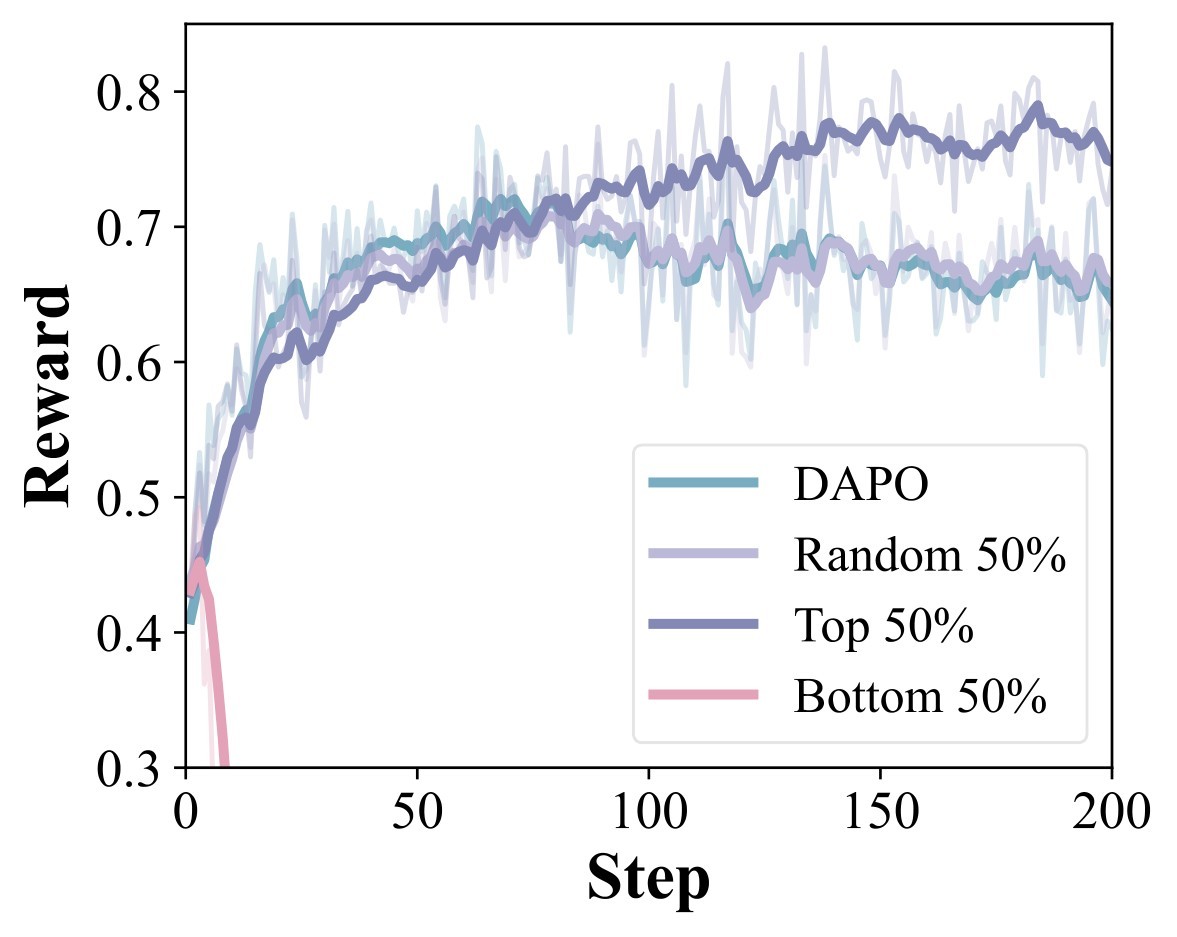
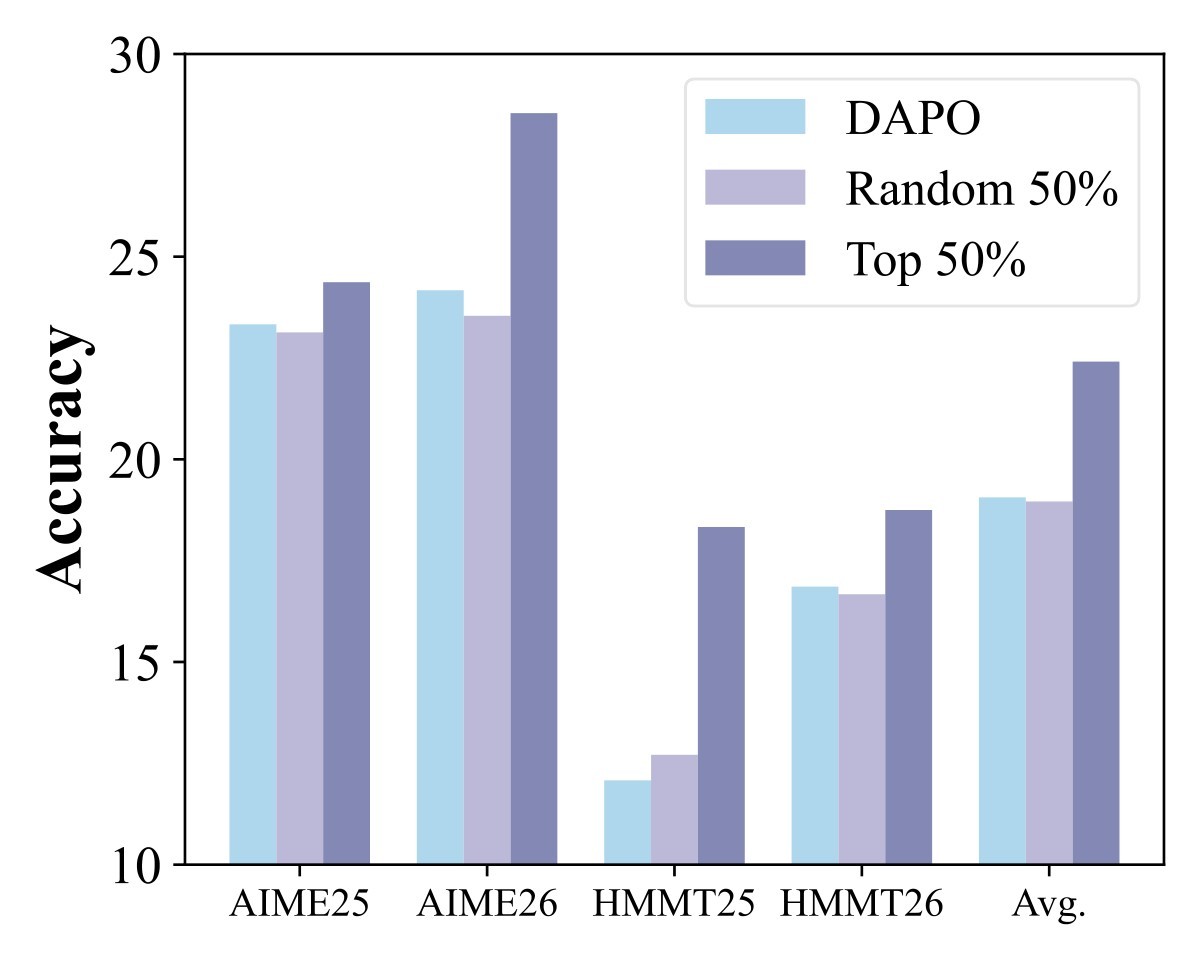
fig_0003, labels fig:reward_mask and fig:acc_mask, original LaTeX assets figs/mask/reward_mask.pdf and figs/mask/acc_mask.pdf, copied from ranking cache files fig003_01_reward_mask.jpg and fig003_02_acc_mask.jpg.The paper also tests transfer beyond the main Qwen3 math setting. Table 5 summarizes the main supplementary results and the reported overhead.
| Evidence family | Baseline | DelTA | Reported gain |
|---|---|---|---|
| Olmo3-7B-Base seven-math average | DAPO 19.01 | DelTA 22.80 | +3.79 average points |
| Code generation weighted average | DAPO 47.7 | DelTA 49.5 | +1.8 average points |
| Qwen3-8B OOD weighted average | DAPO 58.87 | DelTA 62.38 | +3.51 average points |
| Qwen3-14B OOD weighted average | DAPO 66.77 | DelTA 68.40 | +1.63 average points |
| First-step wall-clock overhead | DAPO reference | DelTA +37 seconds | About 10.2 percent of DelTA first-step time |
Table 5. Transfer and cost. The supplementary evidence supports generality across architecture, code generation, and OOD reasoning, while also showing the extra compute cost of coefficient estimation.
Figure 4 is qualitative but useful for interpreting what the coefficients emphasize. The paper reports that high-weight tokens include reasoning- or transformation-associated tokens such as scaffold, prime, =y, forward, and backward, while low-weight tokens include more background-like or entity-specific tokens such as Seat, domain, players, Vander, and Hamilton.


fig_0004, label fig:token_cloud, original LaTeX assets figs/token_c/high_w.pdf and figs/token_c/low_w.pdf, copied from ranking cache files fig004_01_high_w.jpg and fig004_02_low_w.jpg.The limitations are important for interpreting the result. First, DelTA's coefficients are estimated with a layer-restricted proxy rather than exact full-parameter token gradients. The source argues this is a practical necessity and supports robustness with proxy ablations, but it remains an approximation. Second, the evaluation is centered on math reasoning, with supplementary code, architecture, and OOD tests rather than broad RLVR coverage over multi-turn tool use or diverse verifiable domains. Third, coefficient estimation adds compute. The paper reports a modest overhead in its setting, but users with very long responses or constrained memory may face different tradeoffs. Finally, this digest does not independently reproduce the experiments.
Practical Takeaways
For RLVR work, the paper's most useful contribution is the discriminator lens: a response-level advantage does not explain token-level learning alone; the geometry of the aggregated token gradients determines which token probabilities move. That framing gives a concrete way to reason about credit assignment without adding dense process rewards or a learned value function.
DelTA is attractive when an existing DAPO/GRPO-style trainer already computes old log-probabilities and hidden states, because its coefficients are stop-gradient quantities that can be inserted as per-token multipliers. The method keeps the training objective close to the baseline, but changes which token-gradient directions receive emphasis.
The strongest empirical signal is the combination of Table 3, Table 4, and Figure 3: DelTA beats strong same-scale baselines, the within-side-only and random-weight controls fail, and the top-\(\lambda\)/bottom-\(\lambda\) split suggests the coefficients identify useful and harmful token-gradient directions rather than merely sparsifying the loss.
The main caution is that DelTA's mechanism is approximate and source-validated rather than independently reproduced here. Treat the method as a promising RLVR objective modification with strong internal evidence, not as a universally validated credit-assignment solution.
Reference Coverage
This digest links all explicit anchors used above: evidence anchors motivation, local discriminator, method, implementation, main results, diagnostics, generalization, and limitations; table anchors claims, key equations, main results, diagnostics, and transfer/cost; figure anchors DelTA overview, training dynamics, token selection, and token clouds.