Source-first digest for monthly 2026_05 rank 22, rank_id p010.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
Reinforcement learning from verifiable rewards gives math-reasoning models a clean final-answer signal, but the reward is sparse: a rollout is marked right or wrong without saying which token or reasoning turn mattered. The paper studies whether on-policy self-distillation can provide that missing token-level credit signal without using a stronger outside teacher. In this setup, the student samples a solution, and a copy of the same model is re-run with privileged context such as a verified solution and feedback.
The surprising empirical starting point is that this self-teacher often hurts difficult math reasoning. The authors argue that the teacher becomes too much like an oracle: once it sees the verified solution, it boosts tokens already implied by that solution and suppresses the exploratory tokens that make long reasoning work. The overview and HMMT 2025 learning curve in Figure 1 frame the diagnosis and the proposed reversal.
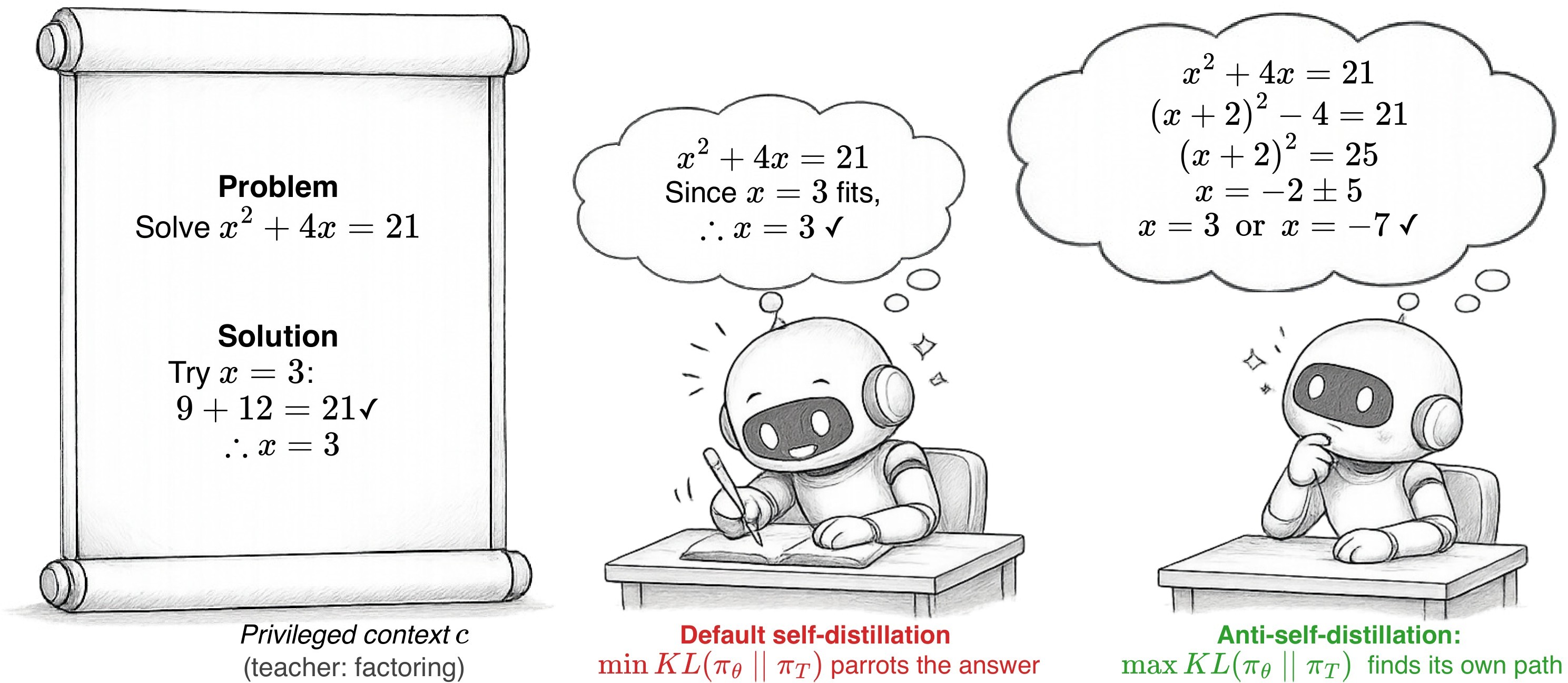
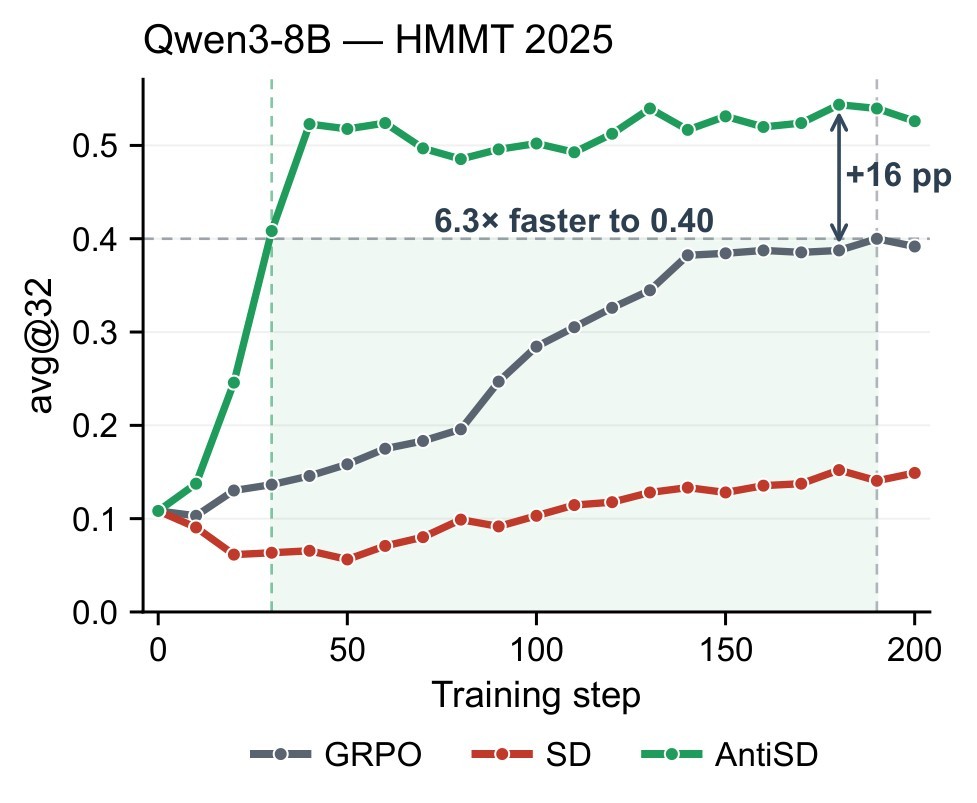
Claims And Evidence
Support scores are support-from-paper scores, not independent reproduction scores.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Default self-distillation has a structural shortcut bias on math reasoning because the privileged context rewards already-implied tokens and penalizes deliberation tokens. | 4 | problem setup, PMI diagnosis, per-token trace |
| C2 | AntiSD is a simple drop-in modification: reverse the token-level sign, use bounded Jensen-Shannon ascent, and shut it off with an entropy gate. | 4 | method equations, key equations, hyperparameters |
| C3 | Across five 4B-30B models on math benchmarks, AntiSD reaches GRPO-level accuracy 2 to 10x faster and improves final average accuracy on every model. | 5 | main results, pass-at-k coverage, training dynamics |
| C4 | The improvement is not just less variance or mode concentration; HMMT pass@k stays ahead across k, suggesting broader problem coverage. | 4 | pass-at-k coverage, main results |
| C5 | Sign reversal is the dominant change, while JSD shaping, additive composition, and the entropy gate determine whether the run is stable across models. | 4 | failure modes, Qwen3-4B ablation, training dynamics |
| C6 | The scope is still narrow: the main evidence is math RLVR with one code probe, and extensions to multi-turn agents, larger scales, and multimodal settings remain future work. | 3 | code probe, continual AntiSD, limitations |
Core Technical Idea
The paper's central move is to interpret the self-teacher log-ratio as conditional pointwise mutual information. Let the student distribution be \(\pi_S(\cdot \mid x, y_{\lt t})\), the privileged self-teacher be \(\pi_T(\cdot \mid x, c, y_{\lt t})\), and define \(u_t = \log \pi_T(y_t) - \log \pi_S(y_t)\). Then:
Under default self-distillation, the token reward is \(+u_t\). Tokens that become more likely once the verified solution is known get positive reward; tokens that the oracle-conditioned teacher views as unnecessary get negative reward. In the paper's diagnostic example, this means structural and answer-committing tokens are rewarded, while exploratory words such as "Wait", "Let", and "Maybe" are suppressed. Figure 2 shows both a single-rollout trace and an aggregate heatmap of this split.

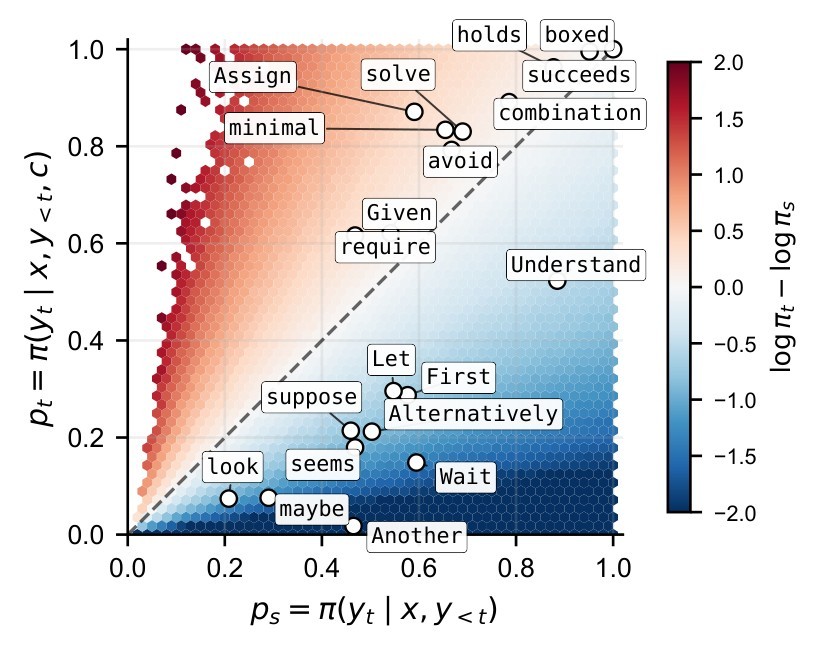
| Source equation | Digest role | Formula |
|---|---|---|
eq:sd |
Default self-distillation objective | \(\mathcal{L}_{\mathrm{SD}}=\mathbb{E}_{x,y\sim\pi_S}\sum_t D_{\mathrm{KL}}(\pi_S(\cdot\mid x,y_{\lt t})\|\mathrm{sg}[\pi_T(\cdot\mid x,y_{\lt t})])\) |
eq:adv-combined |
How dense token credit is mixed into GRPO | \(A_{i,t}=A_i^{\mathrm{seq}}+\lambda\delta_t\) |
eq:thm1-grad |
Why default SD gives reward \(+u_t\) | \(\nabla_\theta D_{\mathrm{KL}}(\pi_S\|\pi_T)=-\mathbb{E}_{v\sim\pi_S}[u_v\nabla_\theta\log\pi_S(v)]\) |
eq:pmi |
Meaning of the self-teacher log-ratio | \(u_t=\mathrm{PMI}(y_t;c\mid x,y_{\lt t})\) |
eq:antisd-advantage |
AntiSD token advantage | \(A_t^{\mathrm{AntiSD}}=-\varphi(u_t),\quad \varphi(u)=\frac{1}{2}(\mathrm{softplus}(u)-\log 2)\) |
| gate update | Stability mechanism | \(g=0\) when teacher entropy falls below \(\tau_{\mathrm{down}}\), otherwise \(\lambda=g\lambda_{\max}\) |
The key equations in Table 1 define the full method. AntiSD does not add a learned process reward model. It changes the sign and shape of the existing self-teacher signal. Instead of descending reverse KL toward the teacher, it ascends a Jensen-Shannon divergence. The induced advantage \(-\varphi(u_t)\) is positive for deliberation tokens, negative for shortcut tokens, and bounded on the over-sampled deliberation side by the JSD softplus shape.
Method Details
AntiSD keeps the GRPO training loop and changes only the per-token auxiliary term. The base RL advantage \(A_i^{\mathrm{seq}}\) remains the group-normalized final-answer reward from GRPO. For each sampled token, the method computes the student log-probability \(s_{i,t}\), the stop-gradient privileged teacher log-probability \(t_{i,t}\), and \(u_{i,t}=t_{i,t}-s_{i,t}\). The training advantage becomes:
The entropy-triggered gate controls \(\lambda\). During five warmup steps with \(\lambda=0\), the method measures the median teacher entropy \(H_{\mathrm{warm}}\). It disables the AntiSD term when \(H < \tau_{\mathrm{down}}\), where \(\tau_{\mathrm{down}}=0.93H_{\mathrm{warm}}\), and re-enables it only when entropy recovers to \(H_{\mathrm{warm}}\). This Schmitt-trigger style rule is meant to avoid using the teacher after it has collapsed into a near-deterministic answer-template distribution.
The appendix proof adds two useful interpretations. First, the self-teacher signal telescopes over a trajectory:
So \(u_t\) can be viewed as a potential-based shaping increment. Second, the JSD derivative satisfies \(f'(\pi_S/\pi_T)=\frac{1}{2}(\log 2-\mathrm{softplus}(u))=-\varphi(u)\), giving the paper's one-step AntiSD advantage.
| Setting | Value |
|---|---|
| Models | Qwen3-8B, Qwen3-4B-Instruct-2507, Olmo-3-7B-Instruct, Olmo-3-7B-Think, Qwen3-30B-A3B |
| Training data | DAPO-Math-17k |
| Training steps | 200 |
| Batch size and group size | 32 problems, 8 rollouts per problem |
| Optimizer and learning rate | AdamW, \(1\times 10^{-6}\) |
| Training max sequence length | 32K |
| Evaluation | avg@32 on AIME 2024/2025/2026 and HMMT 2025; avg@4 on MinervaMath |
| AntiSD weight | \(\lambda_{\max}=0.5\) |
| Gate calibration | 5 warmup steps, \(\tau_{\mathrm{down}}=0.93H_{\mathrm{warm}}\), re-enable at \(H_{\mathrm{warm}}\) |
The shared run configuration in Table 2 matters for interpreting the claims: the reported gains are not from changing the model, dataset, rollout count, optimizer, or evaluation sampling. The privileged teacher context is a verified solution sampled from a successful rollout in the same batch when available, otherwise from the dataset, plus a correctness feedback string.
Experiments And Results
| Model | Method | AIME24 | AIME25 | AIME26 | HMMT25 | Minerva | Average | Speedup |
|---|---|---|---|---|---|---|---|---|
| Qwen3-8B | GRPO | 73.5 | 65.2 | 64.2 | 39.2 | 45.1 | 57.4@200 | 1.0x |
| Qwen3-8B | SD | 40.1 | 30.5 | 26.9 | 14.9 | 40.7 | 30.6@200 | never |
| Qwen3-8B | AntiSD | 78.4 | 73.4 | 73.7 | 54.4 | 48.5 | 65.7@180 | 5.0x |
| Qwen3-4B-IT-2507 | GRPO | 67.8 | 57.7 | 63.5 | 34.1 | 33.2 | 51.3@200 | 1.0x |
| Qwen3-4B-IT-2507 | SD | 59.8 | 45.8 | 52.0 | 28.8 | 43.0 | 45.9@10 | never |
| Qwen3-4B-IT-2507 | AntiSD | 76.6 | 70.2 | 74.4 | 46.7 | 46.4 | 62.8@100 | 10.0x |
| Olmo3-7B-IT | GRPO | 57.0 | 45.3 | 52.1 | 31.2 | 29.1 | 43.0@190 | 1.0x |
| Olmo3-7B-IT | SD | 54.5 | 41.8 | 46.6 | 24.4 | 38.5 | 41.1@10 | never |
| Olmo3-7B-IT | AntiSD | 62.4 | 49.1 | 55.2 | 32.3 | 42.4 | 48.3@200 | 9.5x |
| Olmo3-7B-TK | GRPO | 76.5 | 71.7 | 75.3 | 50.5 | 46.4 | 64.1@80 | 1.0x |
| Olmo3-7B-TK | SD | 77.2 | 68.5 | 74.0 | 48.3 | 44.8 | 62.6@40 | never |
| Olmo3-7B-TK | AntiSD | 77.6 | 75.3 | 76.1 | 56.2 | 45.8 | 66.2@40 | 2.0x |
| Qwen3-30B-A3B | GRPO | 74.1 | 66.8 | 65.5 | 42.2 | 47.1 | 59.1@150 | 1.0x |
| Qwen3-30B-A3B | SD | 40.9 | 32.5 | 34.0 | 20.9 | 44.1 | 34.5@60 | never |
| Qwen3-30B-A3B | AntiSD | 79.4 | 75.6 | 74.1 | 55.2 | 49.7 | 66.8@140 | 2.9x |
Table 3 is the main empirical result. AntiSD beats GRPO's final average on every model, with gains from +2.1 points on the strongest Olmo3-7B-TK baseline to +11.5 points on Qwen3-4B-IT-2507. Default SD is consistently worse than GRPO, and sometimes collapses dramatically, which supports the paper's argument that the privileged-context signal has the wrong sign for this setting.
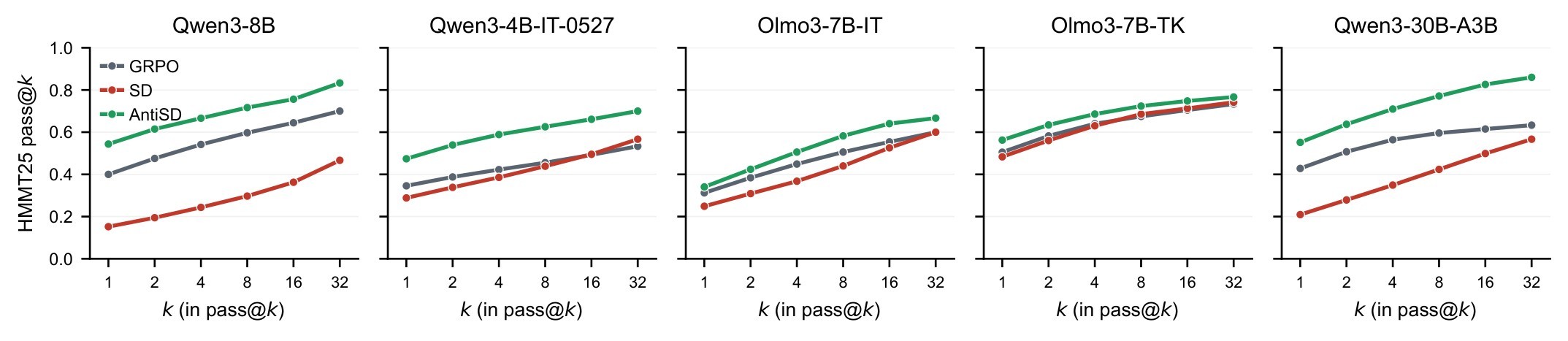
The pass@k evidence in Figure 3 is important because a self-distillation method could look better by reducing diversity and improving only pass@1. The paper reports that on Qwen3-8B, AntiSD is about 13 points ahead at \(k=1\) and still roughly 7 to 10 points ahead by \(k=32\), which is more consistent with solving additional hard problems.
| Method on Qwen3-8B | HumanEval+ | MBPP+ |
|---|---|---|
| GRPO | 40.4 | 61.0 |
| AntiSD | 41.6 | 63.3 |
The code probe in Table 4 is smaller than the math study but directionally positive: AntiSD adds +1.2 on HumanEval+ and +2.3 on MBPP+. The authors interpret the smaller gap as plausible because executable-code reward is denser than final-answer math reward.
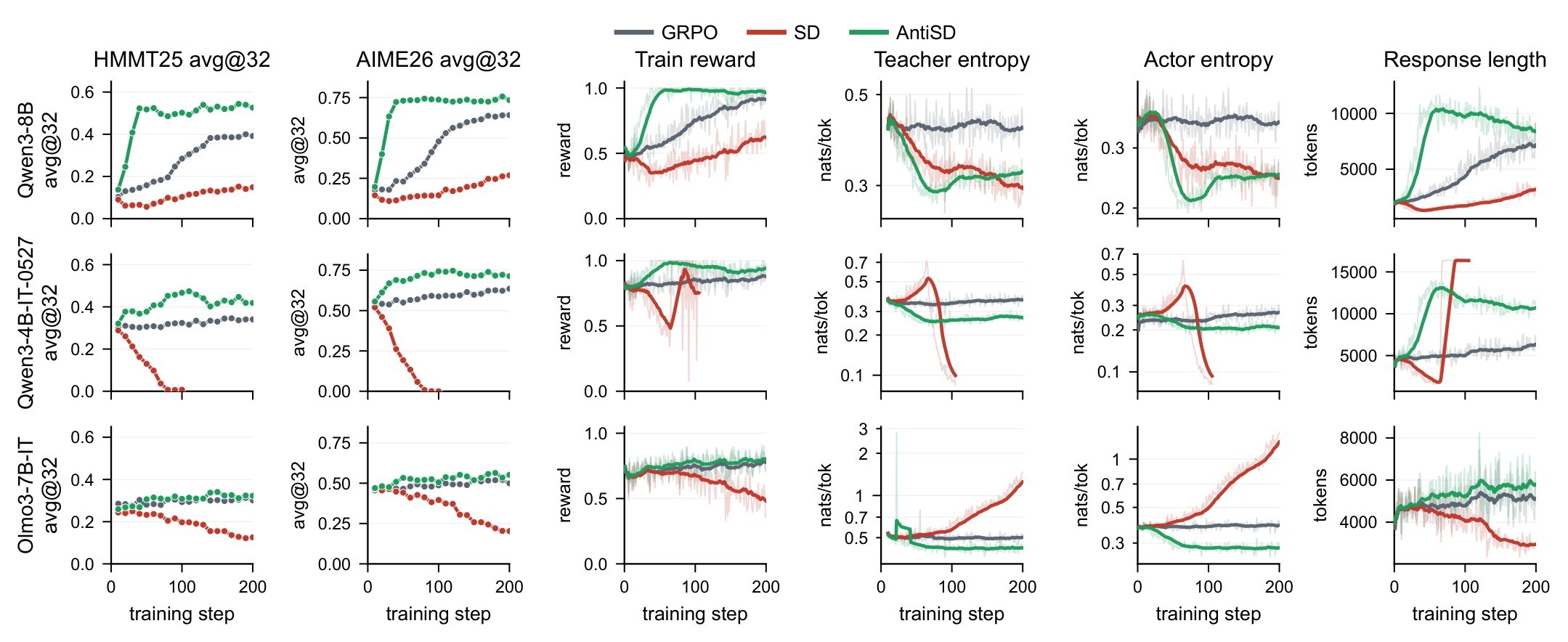
Figure 4 connects the static results to training behavior. AntiSD's train reward rises early, reaching roughly 0.95 within about 30 steps on Qwen3-8B and Qwen3-4B-IT-2507. GRPO reaches similar training reward only much later, and default SD never reaches it. The entropy traces also justify the gate: on Qwen, default SD can drive teacher and actor entropy toward collapse; on Olmo it can inflate entropy and drift.
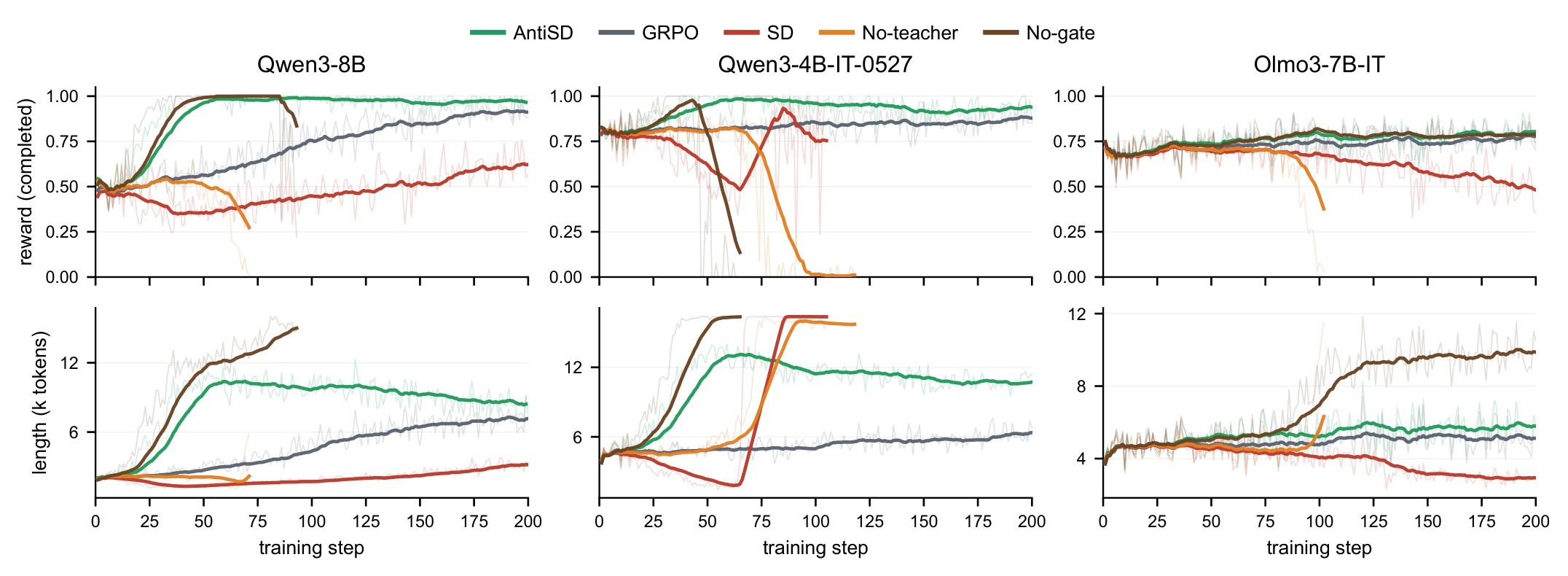
| Qwen3-4B-IT-2507 setting | Div | Gate threshold | Compose | Average | Speedup | Interpretation |
|---|---|---|---|---|---|---|
| GRPO | none | none | none | 51.3@200 | 1.0x | Sparse final reward only |
| AntiSD with reverse-KL ascent | rev. KL | 0.93 | additive | 49.5@10 | never | Sign reversal without JSD shape is unstable/weak |
| AntiSD, no gate | JSD | none | additive | 60.6@30 | 10.0x | Strong transient peak, but later collapse in Figure 5 |
| AntiSD, loose gate | JSD | 0.90 | additive | 54.5@20 | 10.0x | Too permissive on Qwen3-4B |
| AntiSD, tight gate | JSD | 0.95 | additive | 60.3@110 | 6.7x | Slower and slightly worse than canonical |
| AntiSD, multiplicative composition | JSD | 0.93 | multiplicative | 56.5@170 | 5.0x | Dampens token signal when GRPO advantage is small |
| AntiSD, student-perplexity gate | JSD | 0.93 | additive | 60.3@20 | 10.0x | Useful but below teacher-entropy gate |
| Canonical AntiSD | JSD | 0.93 | additive | 62.8@100 | 10.0x | Best average on this model |
Figure 5 and Table 5 separate the method's components. The most direct comparison is default SD versus AntiSD in the main table: reversing the sign changes Qwen3-8B average from 30.6 to 65.7. Among the remaining knobs, canonical JSD plus teacher-entropy gating is strongest on Qwen3-4B. The no-gate variant looks good early but collapses around step 90, so the reported peak is not a stable endpoint.
| Qwen3-8B setting | Steps | AIME24 | AIME25 | AIME26 | HMMT25 | Minerva | Average | Speedup |
|---|---|---|---|---|---|---|---|---|
| GRPO | 200 | 73.5 | 65.2 | 64.2 | 39.2 | 45.1 | 57.4@200 | 1.0x |
| AntiSD from base | 200 | 78.4 | 73.4 | 73.7 | 54.4 | 48.5 | 65.7@180 | 5.0x |
| AntiSD resumed from GRPO@200 | +50 | 74.9 | 72.4 | 73.0 | 54.0 | 50.6 | 65.0@30 | 5.0x |
The continual experiment in Table 6 asks whether AntiSD has to start from the base model. It nearly matches from-base AntiSD after resuming from a saturated GRPO checkpoint, reaching 65.0 average in 30 post-resume steps versus 65.7 for from-base AntiSD. That suggests the deliberation-token signal remains useful even when GRPO's trajectory-level reward has plateaued.
The paper's limitation is scope. The main experiments are math RLVR on Qwen3 and Olmo-3 family models, plus one code-reasoning probe. The authors explicitly leave multi-turn agentic settings, richer privileged contexts, larger model scales, and multimodal conditioning as future work. This keeps the support score for broad generality lower than the support score for the math-RLVR result.
Practical Takeaways
AntiSD is most compelling when three conditions hold. First, the task has sparse outcome reward but reliable verification, as in math RLVR. Second, a privileged context can be constructed during training, such as a verified solution plus correctness feedback. Third, default self-distillation would otherwise compress or shortcut the reasoning process.
For practitioners, the method is attractive because it is operationally small: compute a self-teacher log-ratio, pass it through the JSD-derived softplus shape, subtract it from the GRPO advantage, and gate it by teacher entropy. There is no external teacher, no learned process reward model, and no extra inference-time cost. The cost is that the method depends on careful online training instrumentation and a meaningful privileged context; if that context is weak, biased, or unavailable, the PMI signal may not be useful.
The paper also offers a useful diagnostic lens: when self-distillation shortens answers or destabilizes training, inspect which tokens the privileged teacher raises and lowers. If it rewards tokens that merely follow from knowing the answer and penalizes tokens that explore alternatives, default distillation is acting like shortcut reinforcement rather than process supervision.
Reference Coverage
This digest explicitly links all anchors used above: problem setup, overview figure, PMI diagnosis, PMI trace, method equations, key equations table, hyperparameters table, main results table, pass-at-k figure, code results table, training dynamics figure, failure modes figure, Qwen3-4B ablation table, continual AntiSD table, and limitations.