Source-first digest for monthly 2026_05 rank 4, rank_id p011.
- Routing status:
success - PDF extraction: not used
Motivation / Background
Most recent multimodal systems still split understanding and generation into different mechanisms. Perception usually depends on pretrained vision encoders, while image generation usually depends on VAEs or other latent bottlenecks. SenseNova-U1 argues that this split is not only an implementation detail: it creates separate objectives, representation spaces, and deployment paths that make unified multimodal intelligence harder to obtain.
The paper's answer is NEO-unify, a native pixel-word architecture that removes separate VEs and VAEs, uses lightweight patch interfaces, and trains understanding and generation inside one Mixture-of-Transformers backbone. The intended outcome is a model that can read, reason, draw, edit, interleave text and images, and show early VLA/world-model behavior without routing across separate modality-specific systems. The high-level scope is summarized in Figure 1.
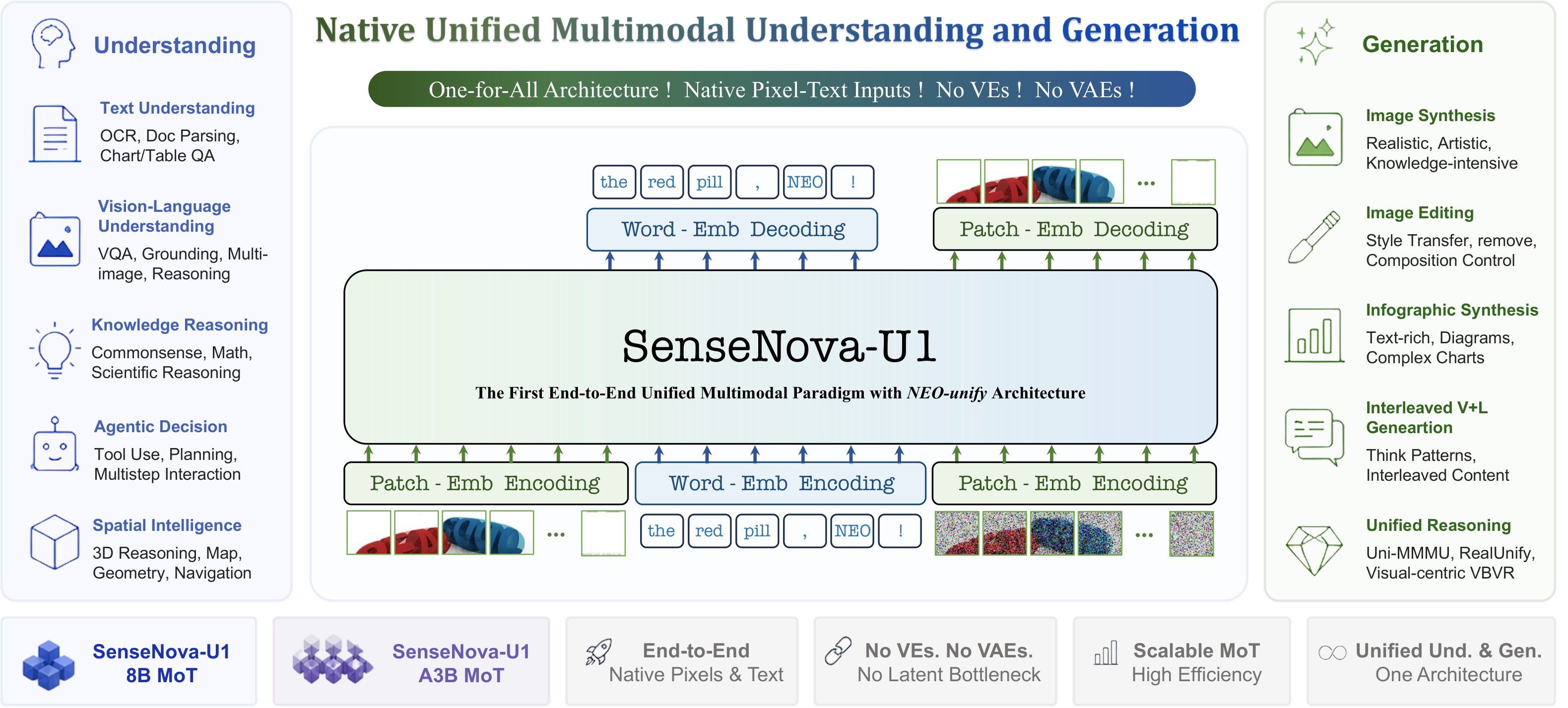
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Understanding and generation can be trained as synergistic views of one native pixel-word process rather than separate VE/VAE pipelines. | 4 | overview, architecture, joint objective, unified reasoning |
| C2 | The near-lossless visual interface preserves useful semantic and pixel-level information without pretrained vision encoders or latent autoencoders. | 3 | visual interface, reconstruction ablation |
| C3 | Native MoT routing lets understanding and generation co-train with limited objective conflict. | 4 | MoT design, co-training ablation, scaling curves |
| C4 | SenseNova-U1 remains competitive on multimodal understanding, text reasoning, agentic benchmarks, and spatial intelligence despite being a unified model. | 4 | understanding table, text and agent table |
| C5 | Unified modeling does not sacrifice image generation: the model is strong on compositional, dense-prompt, text-centric, infographic, and knowledge-centric generation. | 5 | generation table, text-rich generation table, infographic results, showcase figures |
| C6 | Image editing works in the same native framework, but specialist editors still lead on several editing axes. | 3 | editing table, reasoning-editing table, limitations |
| C7 | Interleaved generation and bidirectional understanding-generation tests support real cross-modal synergy, not only colocated skills. | 4 | interleaved table, Uni-MMMU and RealUnify |
| C8 | VLA and world-model behavior is promising but preliminary because the paper provides visual qualitative evidence rather than full embodied benchmark suites. | 2 | VLA visualization, world modeling visualization |
Scores are support-from-paper scores, not independent reproduction scores. I cap claims when evidence is mainly qualitative, when baselines are mostly benchmark-specific, or when the result is inherited from a smaller NEO-unify ablation rather than measured directly on the final SenseNova-U1 variants.
Core Technical Idea
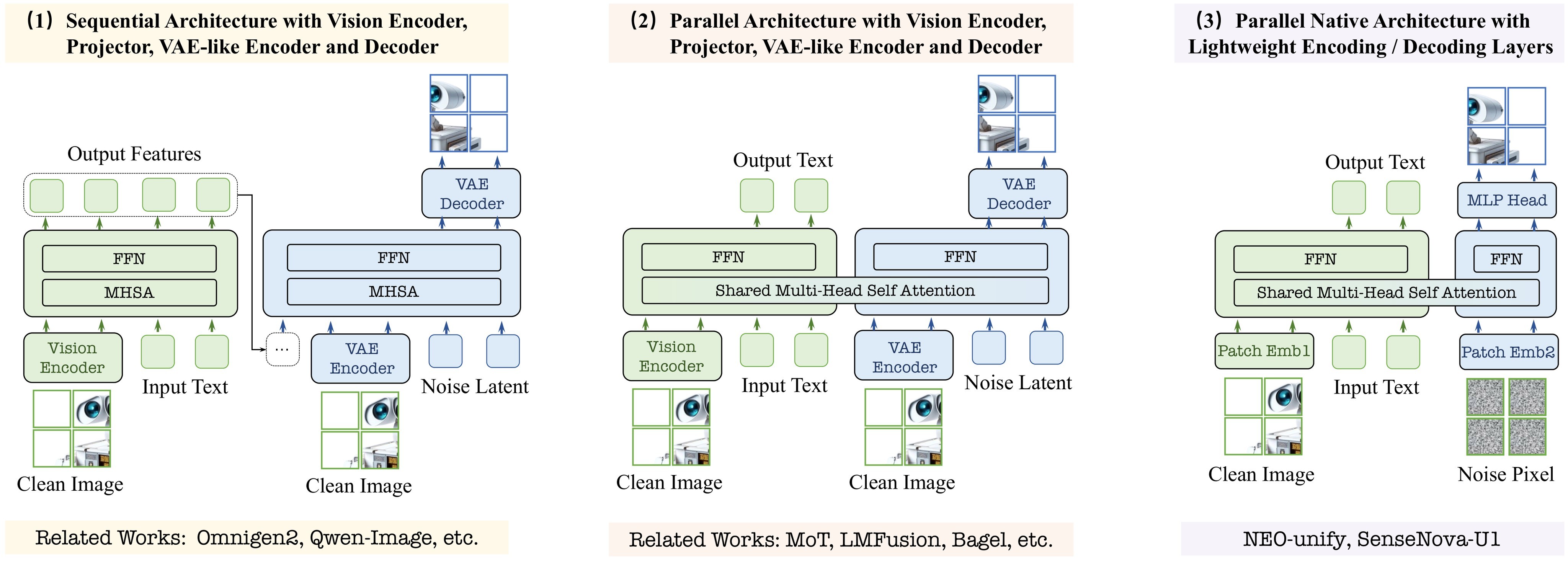
SenseNova-U1 makes three architectural moves:
- Near-lossless visual interface. Images/noise are converted into 32 by 32 patch tokens through two convolutional layers with GELU and 2D sinusoidal positions. The generation stream predicts pixel patches directly with an MLP-like head, rather than decoding through a VAE.
- Native pixel-word sequence modeling. Text tokens and image tokens are projected into one embedding space, delimited by image boundary tokens, and processed jointly.
- Native Mixture-of-Transformers. Clean understanding tokens and noisy generation tokens share attention context but use token-type-routed projections, normalizations, and feedforward blocks. This keeps the architecture unified while decoupling parameters enough to reduce interference.
The architecture is shown in Figure 2, and the two released variants are summarized in Table 1.
| Configuration | SenseNova-U1-8B-MoT | SenseNova-U1-A3B-MoT |
|---|---|---|
| Patch size | \(32 \times 32\) | \(32 \times 32\) |
| Pre-buffer | Yes | No |
| Layers | 42 | 48 |
| Heads, Q / KV | 32 / 8 | 32 / 4 |
| Head size, T / H / W | 64 / 32 / 32 | 64 / 32 / 32 |
| Hidden size | 4,096 | 2,048 |
| Understanding / generation experts | 1 / 1 | 128 / 32, A8 |
| Understanding / generation params | 8.2B / 8.2B | 30.0B / 8.2B, A3B |
Table 1. Model configurations. This table comes from the LaTeX source table tab:model_config; it matters because the paper's main comparison is not only small versus large, but dense symmetric streams versus stream-wise MoE.
The training objective combines text understanding and pixel-space visual generation:
For understanding, the model uses autoregressive next-token loss over text conditioned on multimodal context:
For generation, it applies rectified-flow style pixel-space modeling. A clean image \(\mathbf{x}\) and Gaussian noise \(\boldsymbol\epsilon\) are interpolated with a resolution-adaptive noise scale \(\sigma_R\):
The model predicts a clean signal and converts it into a velocity:
The generation loss is:
For image-conditioned generation and editing, the paper uses a unified classifier-free guidance rule with separate text and image-context strengths:
The reported practical setting is \(\gamma = 4\), \(\gamma_{\mathrm{img}} = 1\), timestep shift 3.0, and global CFG renormalization.
Method Details
Training Recipe
The model is trained in a staged sequence, with pure understanding first, generation pretraining second, joint mid-training third, and unified SFT fourth. Table 2 compresses the stage table recovered from the flattened LaTeX source.
| Stage | Main role | Steps | Data mix | Key settings |
|---|---|---|---|---|
| Stage 1, understanding warmup | Adapt NEO backbone and attention fusion | 120K | 100% understanding | LR \(2\times10^{-5}\), seq length 32768, 0.75T tokens |
| Stage 2-I, generation pretraining | Establish text-to-image generation branch | 120K | 100% generation | LR \(2\times10^{-4}\), gen resolution \(256^2\) to \(512^2\) |
| Stage 2-II, high-res generation | Continue high-resolution generation | 60K | 100% generation | LR \(1\times10^{-4}\), gen resolution \(512^2\) to \(2048^2\) |
| Stage 2-III, expanded generation | Add editing, reasoning, and interleaved data | 120K | 56% generation, 37% editing, 7% interleaved | Cosine LR \(1\times10^{-4}\) to \(2\times10^{-5}\) |
| Stage 3, unified mid-training | Jointly train both branches | 84K | 33% understanding, 37% generation, 24% editing, 6% interleaved | \(\lambda_1=0.1\), \(\lambda_2=1.0\), 1.19T tokens |
| Stage 4, unified SFT | Instruction alignment across modalities | 9K | Same ratios as Stage 3 | Cosine LR \(2\times10^{-5}\) to 0 |
Table 2. Training stages. The important design is not simply "more data"; Stage 2 deliberately lets the generation branch learn pixel synthesis before the unified model is jointly optimized.
After SFT, the paper adds generation post-training. Dynamic resolution warmup gates candidate resolution sampling by difficulty:
Text-rendering RL uses OCR overlap:
For one reward group, OCR and style rewards are combined as:
The text-rendering RL run uses 600 epochs, learning rate \(1\times10^{-5}\), KL coefficient \(\beta=0.01\), \(N=48\) prompts per epoch, \(K=16\) samples per prompt, 10-step flow matching, guidance 4.0, and a 200-epoch resolution warmup. The later general RL stage interleaves text/style and aesthetic reward groups; the 8B variant trains for 1,600 epochs and the A3B variant for 200.
Inference Infrastructure
The paper keeps the user-facing model unified but splits serving into two specialized engines because understanding and generation have different runtime bottlenecks. Figure 3 shows the disaggregated LightLLM/LightX2V serving setup, and Figure 4 shows the hybrid attention kernel.
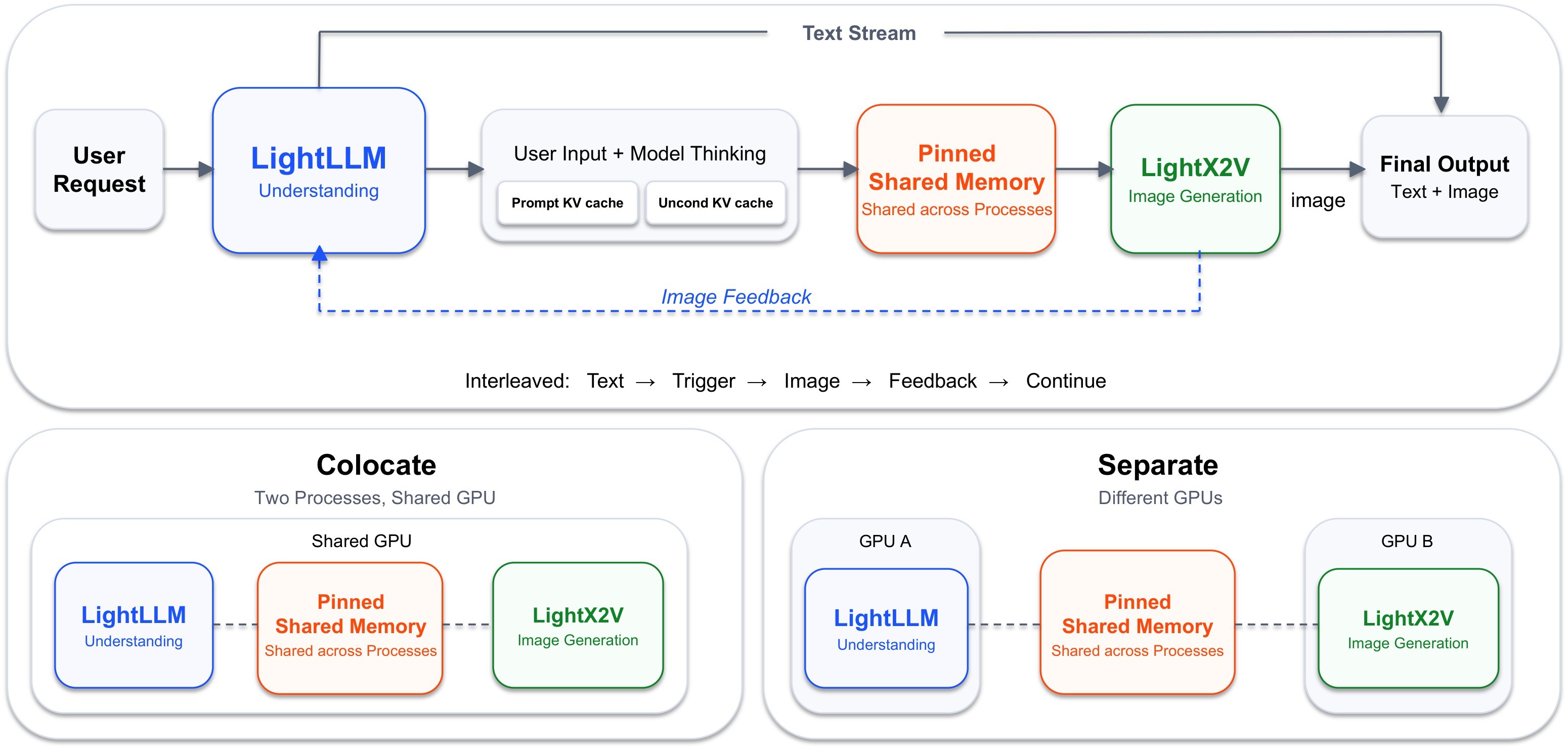
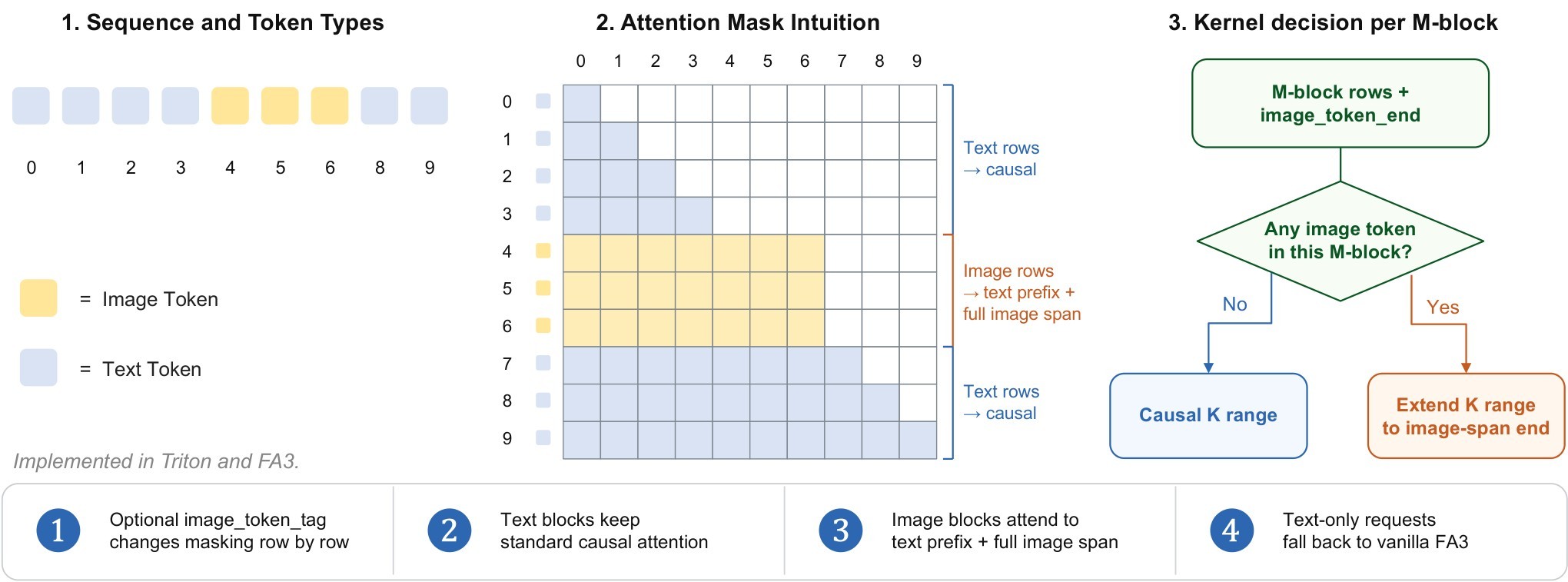
The infrastructure supports separate and colocated deployment. For \(2048 \times 2048\) generation with SenseNova-U1-8B-MoT, both modes support TP2+CFG2; in separate mode, the paper reports per-step latencies of 0.415 seconds on 5090 and 0.443 seconds on L40S GPUs.
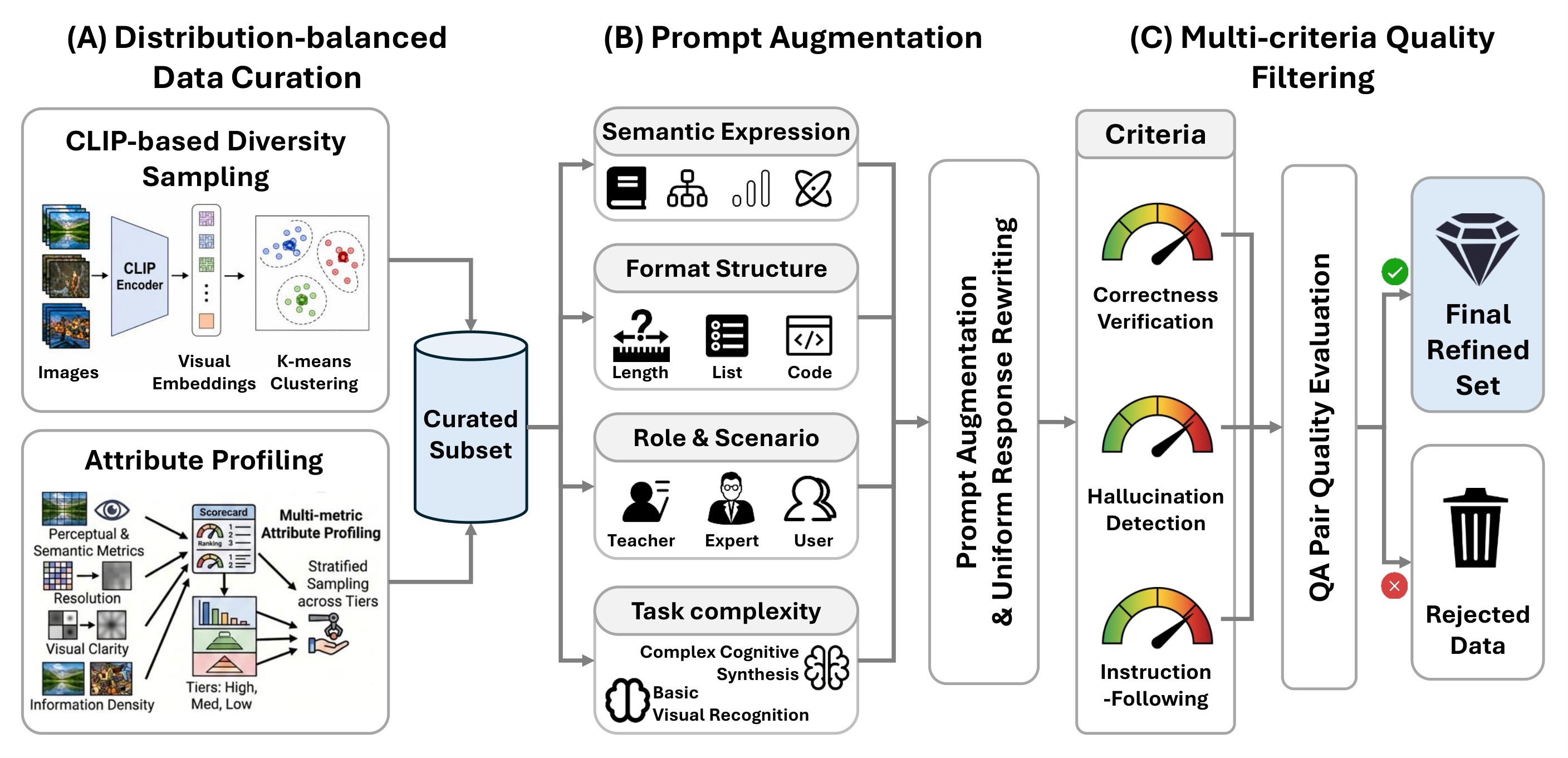
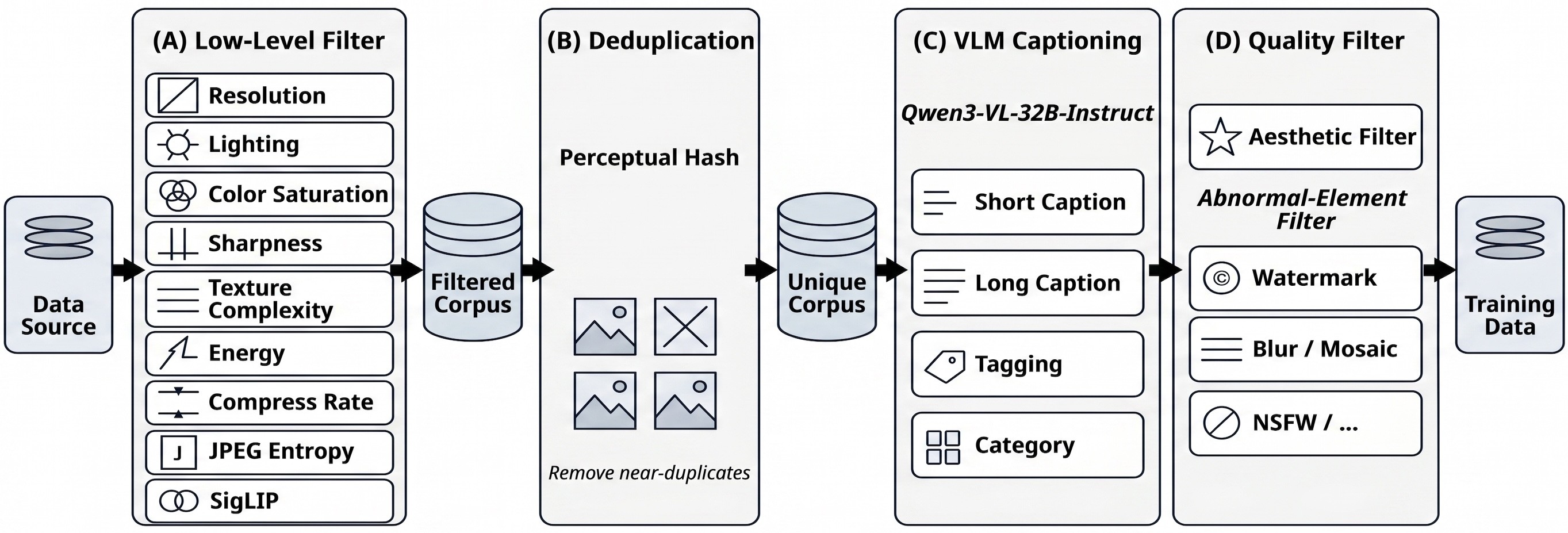
Data Construction
The understanding corpus and generation corpus are both heavily filtered. Figure 5 shows the understanding pipeline, Figure 6 summarizes the corpus distribution, and Figure 7 shows the generation filtering pipeline.
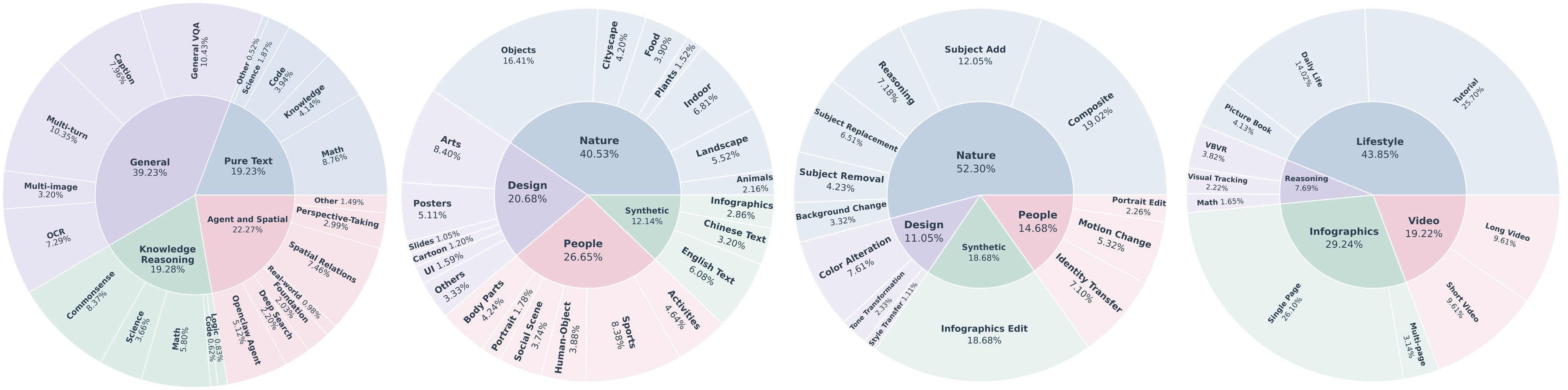
For interleaved data, the paper reports a compact corpus spanning video, lifestyle, infographics, and reasoning. Lifestyle is about 44%, infographics about 29%, video about 19%, and reasoning about 8%, with the reasoning subset including explicit chain-of-thought traces.
Experiments And Results
Understanding, Text, Agent, And Spatial Results
The paper evaluates understanding with EvalScope under an LLM-as-a-judge llm_recall strategy, using gpt-4o-mini-2024-07-18 as judge. The setup uses temperature 0.6, top-p 0.95, top-k 20, repetition penalty 1.0, 40,960 max sequence length, 600 second timeout, and internal thinking enabled.
Table 3 condenses the multimodal understanding and spatial-intelligence table recovered from flattened LaTeX. The strongest evidence is not that SenseNova-U1 wins every column; it is that an encoder-free unified model stays close to or above strong understanding-only VLMs across diverse categories.
| Benchmark | SenseNova-U1 8B-Think | Qwen3VL 8B-Think | Qwen3.5 9B | SenseNova-U1 30BA3B-Think | Qwen3VL 30BA3B-Think | Qwen3.5 35BA3B |
|---|---|---|---|---|---|---|
| MMMU | 74.78 | 74.10 | 78.40 | 80.55 | 76.00 | 81.40 |
| MMMU-Pro | 67.69 | 60.40 | 70.10 | 72.83 | 63.00 | 75.10 |
| MathVista-mini | 84.20 | 81.40 | 85.70 | 85.30 | 81.90 | 86.20 |
| MathVision | 75.82 | 62.70 | 78.90 | 79.63 | 65.70 | 83.90 |
| MMBench-EN | 90.25 | 87.50 | 90.10 | 91.59 | 88.90 | 91.50 |
| OCRBench-v2 | 61.30 | 61.55 | 66.54 | 68.64 | 61.50 | 73.71 |
| VSI-Bench | 62.66 | 56.61* | 55.67* | 56.90 | 51.56* | 58.10* |
| MindCube-Tiny | 62.01 | 43.17 | 57.59 | 70.86 | 40.86 | 63.46 |
Table 3. Selected multimodal and spatial benchmarks. Asterisks mark Qwen variants that used 128 frames for best performance under the paper's EASI note; the standard protocol otherwise uses 32 frames on VSI-Bench.
| Benchmark | SenseNova-U1 8B-Think | Qwen3VL 8B-Think | Qwen3.5 9B | SenseNova-U1 30BA3B-Think | Qwen3VL 30BA3B-Think | Qwen3.5 35BA3B |
|---|---|---|---|---|---|---|
| MMLU-Pro | 81.44 | 77.30 | 82.50 | 84.04 | 80.50 | 85.30 |
| MMLU-Redux | 87.61 | 88.80 | 91.10 | 89.44 | 90.90 | 93.30 |
| C-Eval | 84.40 | 83.88 | 88.20 | 85.89 | 87.29 | 90.20 |
| SuperGPQA | 49.67 | 51.20 | 58.20 | 59.71 | 56.40 | 63.40 |
| IFEval | 91.13 | 83.20 | 91.50 | 92.39 | 81.70 | 91.90 |
| IFBench | 67.01 | 29.93 | 64.50 | 79.79 | 34.69 | 70.20 |
| Tau2 | 71.70 | 31.65 | 79.10 | 75.39 | 46.40 | 81.20 |
| Claw eval | 58.90 | 21.70 | 65.40 | 58.50 | 22.10 | 36.50 |
Table 4. Selected text, instruction, and agent results. The instruction-following and agent rows are the clearest wins for SenseNova-U1 over Qwen3VL variants; dense reasoning-focused Qwen3.5 still leads on several knowledge rows.
Image Generation
For general generation, the paper reports GenEval, DPG-Bench, OneIG, TIIF, CVTG-2K, LongText-Bench, WISE, IGenBench, and BizGenEval. Figure 8 and Figure 9 show qualitative examples, while Table 5 and Table 6 summarize the strongest quantitative claims.


| Benchmark | Metric | SenseNova-U1 8BA3B | SenseNova-U1 8B | Qwen-Image 20B | BAGEL 7B |
|---|---|---|---|---|---|
| GenEval | Overall | 0.91 | 0.91 | 0.87 | 0.82 |
| DPG-Bench | Overall | 88.14 | 87.78 | 88.32 | 85.07 |
| OneIG-EN | Overall | 0.543 | 0.549 | 0.539 | 0.361 |
| OneIG-ZH | Overall | 0.540 | 0.535 | 0.548 | 0.370 |
| TIIF short | Overall | 89.25 | 89.74 | 86.14 | - |
| TIIF long | Overall | 87.36 | 89.17 | 86.83 | - |
| WISE with CoT | Overall | 0.81 | 0.78 | - | 0.70 |
| WISE without CoT | Overall | 0.74 | 0.69 | 0.63 | 0.49 |
Table 5. Selected generation benchmarks. SenseNova-U1 is particularly strong on GenEval and TIIF. On DPG-Bench it is competitive but not the top overall row because Qwen-Image reports 88.32 and Seedream 4.5 reports 88.63.
| Benchmark | Metric | SenseNova-U1 8B | SenseNova-U1 8BA3B | Qwen-Image 20B | FLUX.1-dev 12B |
|---|---|---|---|---|---|
| CVTG-2K | Word accuracy average | 0.940 | 0.881 | 0.829 | 0.497 |
| LongText-Bench-EN | Accuracy | 0.979 | 0.950 | 0.943 | 0.607 |
| LongText-Bench-ZH | Accuracy | 0.962 | 0.955 | 0.946 | 0.005 |
Table 6. Text-centric generation. The 8B variant is the strongest SenseNova-U1 text-rendering model in these rows, especially on CVTG-2K and LongText-Bench.
| Benchmark | Metric | SenseNova-U1 8B | SenseNova-U1 8BA3B | Qwen-Image 20B | Z-Image-Turbo 6B |
|---|---|---|---|---|---|
| IGenBench | Overall | 0.51 | 0.42 | 0.36 | 0.35 |
| BizGenEval | Average hard / easy | 39.7 / 61.7 | 28.2 / 51.9 | 2.8 / 23.8 | - |
Table 7. Infographic and business visual generation. IGenBench and BizGenEval are important because they test layouts, charts, data constraints, text rendering, and domain knowledge rather than only natural-image aesthetics.
Image Editing
The editing results are more nuanced. SenseNova-U1 is competitive among unified open-source models, but it does not beat the strongest dedicated editing systems such as Qwen-Image-Edit-2511 or Seedream in the general editing table. The paper explicitly attributes part of the gap to editing data limitations.
| Benchmark | Metric | SenseNova-U1 8BA3B | SenseNova-U1 8B | Qwen-Image-Edit-2511 20B | BAGEL 7B |
|---|---|---|---|---|---|
| ImgEdit | Overall | 3.91 | 3.90 | 4.51 | 3.20 |
| GEdit-Bench-EN | Score | 8.07 | 8.27 | 8.30 | 7.36 |
| GEdit-Bench-ZH | Score | 7.36 | 7.49 | 8.20 | 6.83 |
| GEdit-Bench overall | Score | 7.32 | 7.47 | 7.88 | 6.52 |
Table 8. General editing. The unified native model clears older unified baselines, but dedicated editors still lead, especially on ImgEdit and GEdit overall.
| RISEBench row | Temporal | Causal | Spatial | Logical | Overall | IR | AC | VP |
|---|---|---|---|---|---|---|---|---|
| SenseNova-U1-SFT 8BA3B with CoT | 24.7 | 46.7 | 28.0 | 20.0 | 30.0 | 63.2 | 84.1 | 87.4 |
| SenseNova-U1-SFT 8B with CoT | 31.8 | 33.3 | 27.0 | 15.3 | 26.9 | 60.8 | 86.6 | 88.2 |
| SenseNova-U1-SFT 8BA3B | 25.9 | 41.1 | 26.0 | 7.1 | 25.3 | 57.4 | 82.6 | 85.4 |
| SenseNova-U1-SFT 8B | 22.4 | 33.3 | 27.0 | 11.8 | 23.9 | 58.2 | 84.1 | 82.4 |
| Qwen-Image-Edit-2511 20B | 21.2 | 18.9 | 31.0 | 4.7 | 19.4 | 49.9 | 71.0 | 91.5 |
Table 9. Reasoning editing. CoT helps substantially on RISEBench. For example, A3B logical score moves from 7.1 to 20.0, and overall rises from 25.3 to 30.0.
Interleaved Generation And Unified Reasoning
Interleaved generation is where the paper most directly tests whether the model can coordinate language and images over multiple steps. Table 10 covers OpenING and VBVR-Image preview; Table 11 covers generation-aids-understanding and bidirectional synergy.
| Benchmark | Metric | SenseNova-U1-SFT 8BA3B | SenseNova-U1-SFT 8B | Reference baseline |
|---|---|---|---|---|
| OpenING | Overall with CoT | 9.16 | 9.07 | GPT-4o + DALL-E3: 8.20 |
| VBVR-Image preview | Overall | 68.9 | 68.8 | VBVR-BAGEL: 36.5; BAGEL: 29.1 |
Table 10. Interleaved generation. These rows support the claim that SenseNova-U1 can sustain multi-step image-text coherence and reasoning-through-generation better than the compared unified baselines.
| Benchmark | Metric | SenseNova-U1-SFT 8B | SenseNova-U1-SFT 8BA3B | BAGEL 7B | Ovis-U1 1.2B |
|---|---|---|---|---|---|
| Uni-MMMU GaU | Avg | 35.0 | 32.6 | 20.5 | 14.1 |
| RealUnify | Avg-UEG | 55.7 | 52.8 | 47.7 | 39.3 |
| RealUnify | Avg-GEU | 47.5 | 47.0 | 35.8 | 29.5 |
| RealUnify | Overall avg | 52.4 | 50.5 | 42.9 | 35.4 |
Table 11. Unified reasoning. Uni-MMMU measures generation assisting understanding. RealUnify separates Understanding Enhances Generation and Generation Enhances Understanding, which is why it is central evidence for C7.
Ablation Studies
The ablations address three questions: whether the encoder-free visual interface preserves detail, whether MoT co-training creates manageable interaction between objectives, and whether data scale improves both generation and unified capabilities. Figure 10, Figure 11, Figure 12, Figure 13a, Figure 13b, Figure 13c, and Figure 13d show the visual evidence.


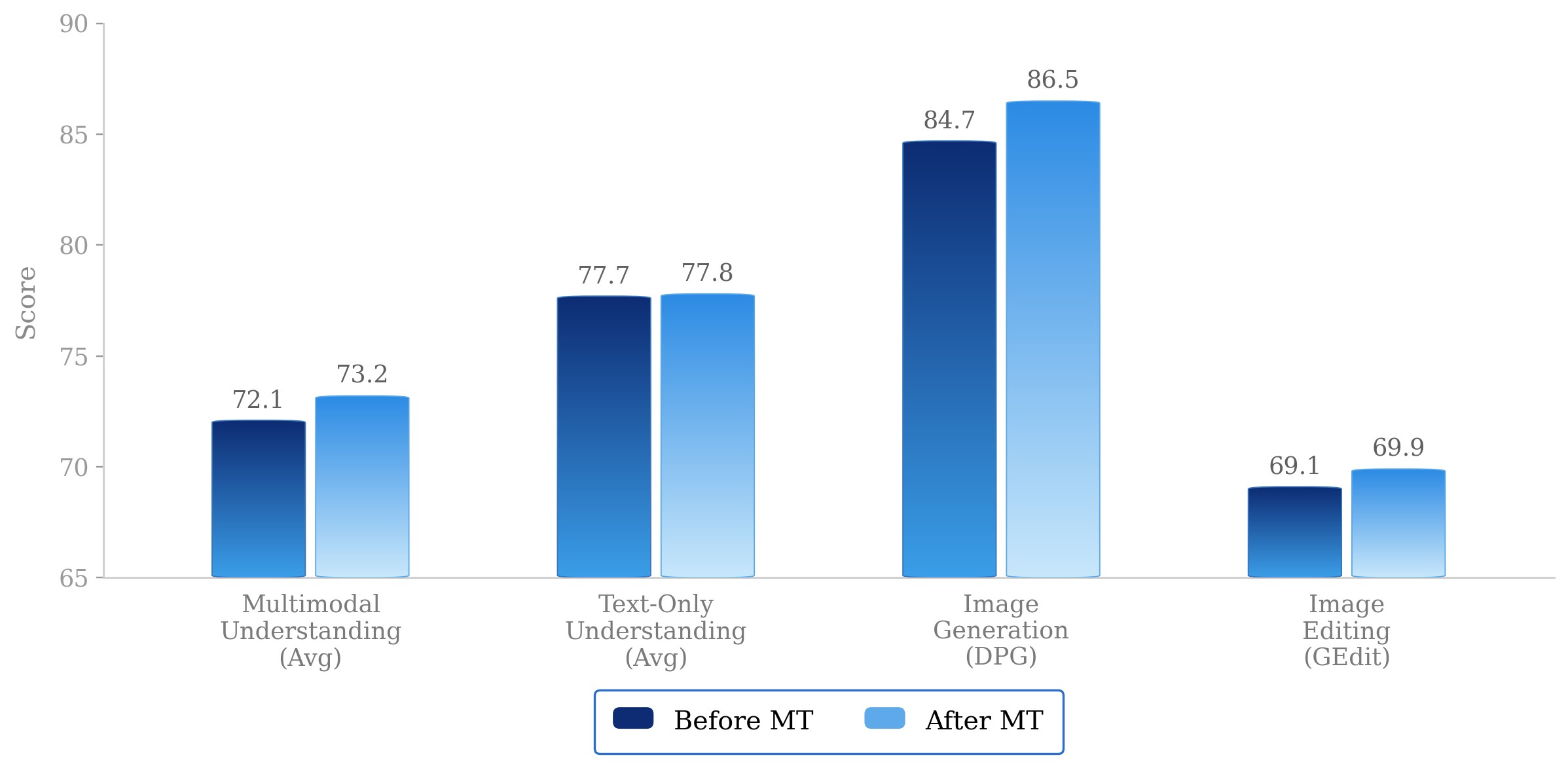
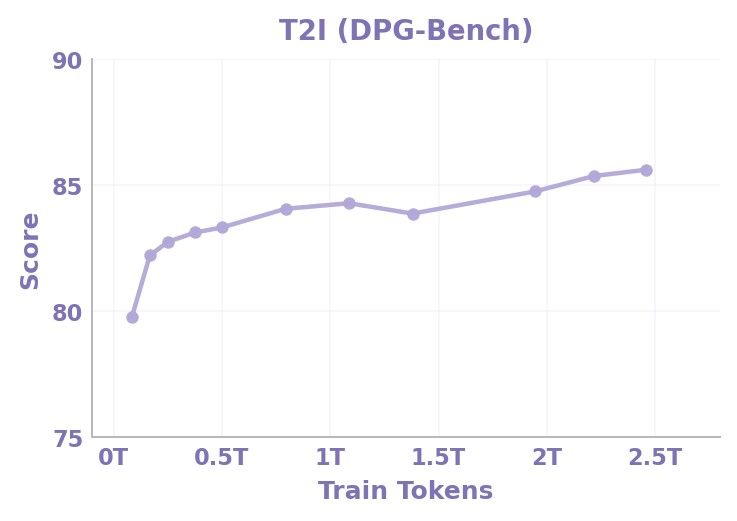
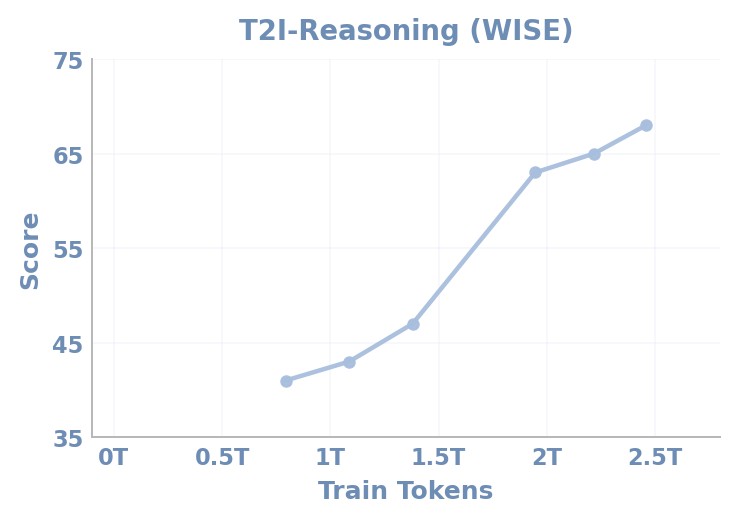
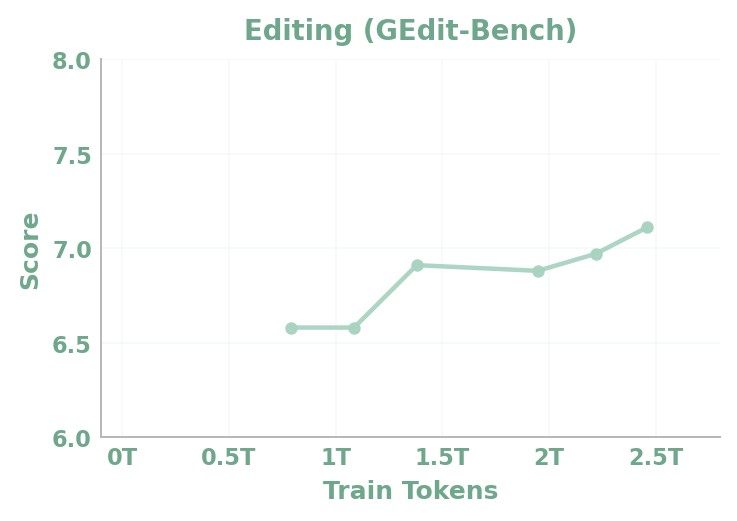
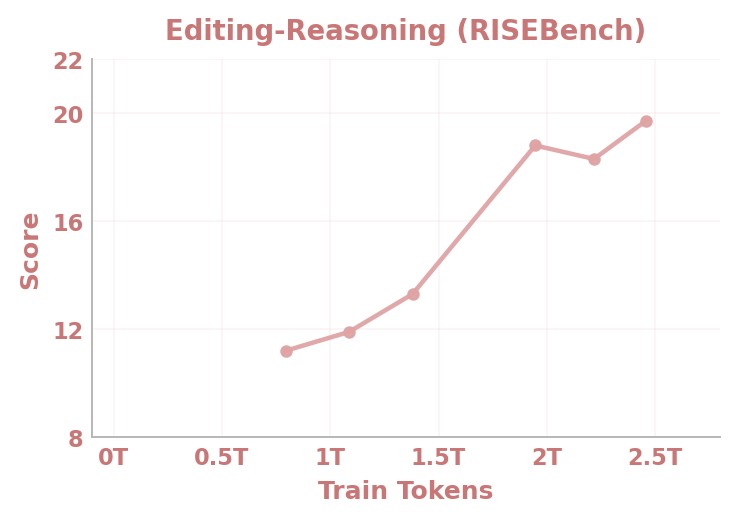
Figures 13a-13d. Data-scaling curves. These curves cover DPG-Bench, WISE, GEdit-Bench, and RISEBench. The paper interprets them as evidence that diverse data scale improves generation quality and understanding-generation synergy.
Preliminary VLA And World Modeling
The final experiments are qualitative visualizations rather than full embodied evaluations. They are still useful because they show what the authors mean by a path from passive multimodal understanding toward acting and predicting state transitions.


Practical Takeaways
1. The real contribution is architectural unification, not just benchmark breadth. SenseNova-U1 tries to remove the VE/VAE split and force pixel-word understanding, image synthesis, editing, and interleaving through one native modeling interface.
2. Parameter decoupling inside a unified backbone is the pragmatic compromise. The model is "single architecture" at the sequence and attention level, but projections, normalizations, and feedforward blocks are stream-routed by token type. That choice is what makes the unification claim more credible than a purely shared-backbone design.
3. Text rendering and structured visual generation are unusually central. The strongest generation evidence is not only natural-image quality; it is GenEval, TIIF, CVTG-2K, LongText-Bench, IGenBench, BizGenEval, and WISE, which stress layout, text, knowledge, and reasoning.
4. Editing is good but not solved. SenseNova-U1 beats many unified baselines, but dedicated editors still lead on general editing. The paper's own limitation is that editing supervision is still dominated by public resources and lacks broader pipelines and preference optimization.
5. The VLA/world-model story should be treated as roadmap evidence. The figures are promising, but they are not a substitute for benchmarked embodied control or closed-loop world-model evaluation.
6. For follow-up work, the most interesting tests are interference and transfer. A strong reproduction would vary the MoT decoupling, VE/VAE removal, data mixture, and post-training rewards to test whether the claimed synergy survives outside this training stack.
Reference Coverage
- Additional local references for validation and navigation: evidence-data, evidence-inference, evidence-training, fig-vla, fig-world-modeling, table-editing.
- Additional local references for validation and navigation: table-infographic, table-reasoning-editing, table-text-agent.