Source-first digest for monthly 2026_05 rank 14, rank_id p012.
- Routing status:
success - PDF extraction: not used
Motivation / Background
The paper argues that autonomous research systems should be evaluated as iterative scientific workflows, not as one-shot paper generators. Existing systems are portrayed as brittle along three linked dimensions: single-agent hypothesis generation can confirm its own assumptions, execution failures often terminate a run rather than become evidence, and each run starts without structured memory of prior failures.
The core problem framing is that real research cycles through hypothesis, experiment, failure, revision, and accumulated judgment. AutoResearchClaw is proposed as a research amplifier that makes that loop explicit: it combines structured debate, self-healing execution, verifiable reporting, human checkpoints, and cross-run lessons. The pipeline view in Figure 1 is the best compact source for this full-loop framing.
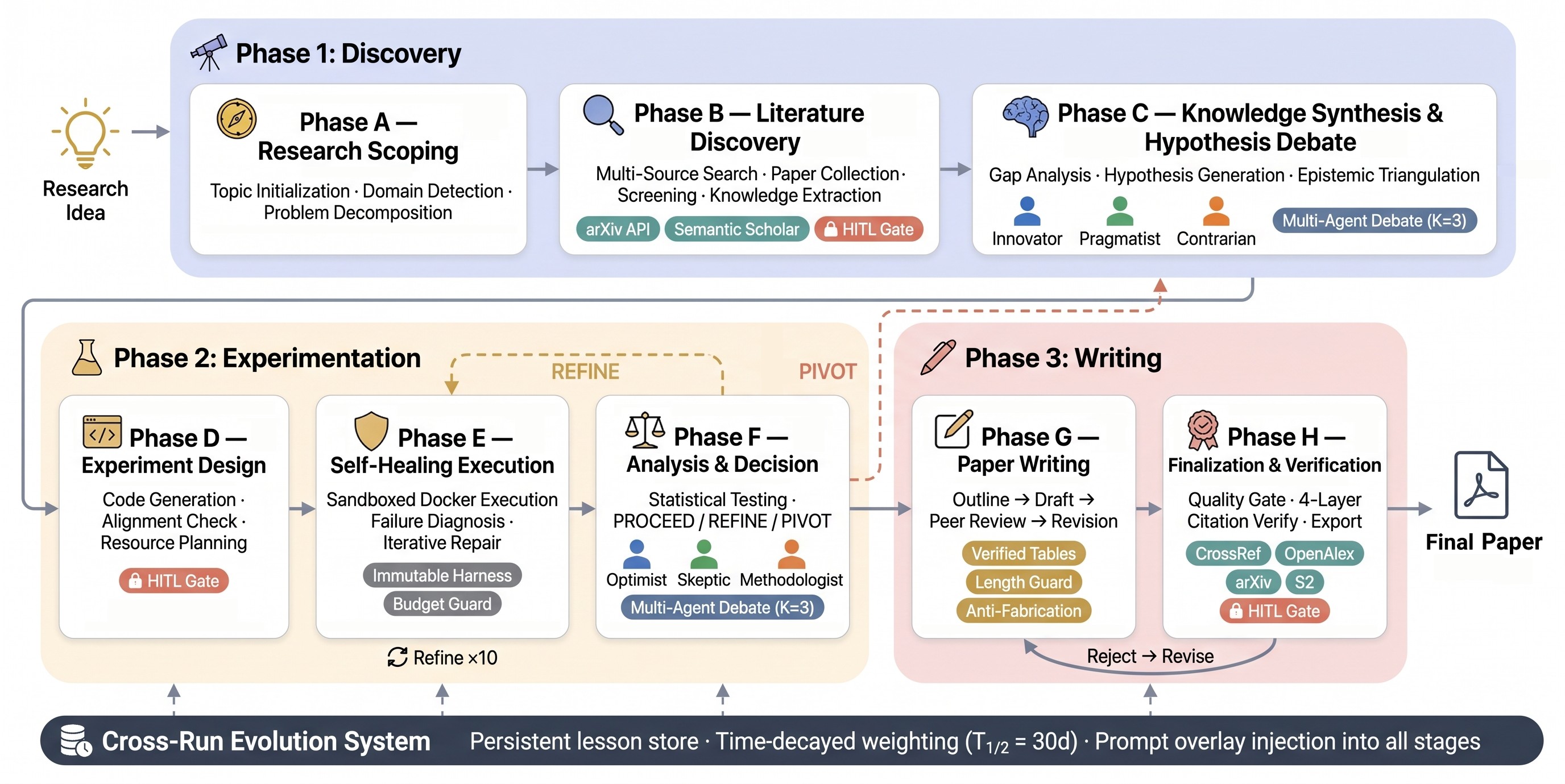
The paper's main contribution is not a new foundation model. It is an orchestration architecture for scientific agents: a 23-stage pipeline with explicit contracts, domain-aware prompt banks, sandboxed execution, checked numerical registries, citation verification, and modes for different levels of human collaboration. The main claims are summarized in Table 1.
Claims And Evidence
Support scores are support-from-paper scores, not independent reproduction scores. A score of 5 means the claim is directly backed by the paper's architecture, source tables, figures, or ablations. A score of 4 means the paper reports direct evidence, but the evidence depends on the authors' benchmark and judge setup. A score of 3 means the paper gives plausible supporting evidence but the claim is partly normative or forward-looking.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | AutoResearchClaw reframes autonomous research as a closed loop over discovery, experimentation, writing, and cross-run learning rather than a linear idea-to-paper pipeline. | 5 | problem framing, contribution, Figure 1, method map |
| C2 | The five mechanisms - multi-agent debate, self-healing execution, verified reporting, HITL collaboration, and cross-run evolution - address different failure modes and interact. | 5 | mechanism evidence, component ablation, Table 2, Table 3 |
| C3 | On ARC-Bench experiment-stage comparison, AutoResearchClaw outperforms AI Scientist v2 and AIDE-ML, with the largest reported gap on result analysis. | 4 | evaluation setup, main results, Table 3 |
| C4 | Targeted human collaboration is better than both no oversight and dense step-by-step oversight in the reported HITL ablation. | 4 | HITL modes, case study, Figure 2, Table 3 |
| C5 | The system design can extend beyond ML topics to biology, statistics, and high-energy physics through domain-specialized agents and sandboxes. | 4 | cross-domain evidence, Table 3 |
| C6 | Verification is necessary but not sufficient: numeric registries and citation checks reduce fabrication, while human and debate mechanisms are still needed for scientific meaning. | 5 | verification evidence, component ablation, case study, ethics |
| C7 | The appropriate framing is research augmentation, not replacement of expert scientific judgment. | 3 | HITL evidence, ethics, practical takeaways |
Core Technical Idea
The system is a 23-stage research pipeline with three phases: Discovery, Experimentation, and Writing. Its key design move is to connect stage contracts, debate, execution repair, verification, and human input into one pipeline rather than treating them as optional wrappers. Table 2 maps the five mechanisms to the paper's stated failure modes.
| Mechanism | Where it acts | Failure mode it targets | Digest reading |
|---|---|---|---|
| Multi-agent debate | Hypothesis generation and result analysis | Single-agent confirmation, weak assumptions, oversold conclusions | Debate is used as a structured adversarial review layer, not just brainstorming. |
| Self-healing execution | Code generation, experiment run, iterative refine | First runtime error stops progress; failed attempts lose information | Failures become signatures for repair, refine, or pivot decisions. |
| Verifiable result reporting | Paper drafting, strict sections, citation pipeline | Fabricated numbers and hallucinated references | The writing agent can consume verified outputs but cannot invent or modify measurements. |
| HITL collaboration | Literature, hypothesis, design, analysis, drafting, quality gates | Humans are either absent or forced into every trivial step | CoPilot concentrates human effort at high-leverage decision points. |
| Cross-run evolution | Start and end of runs | Systems repeat avoidable failures across independent runs | Lessons are stored with severity and time-decayed weight, then injected into future prompts. |
Two extracted display equations are central enough to preserve. First, cross-run lessons are ranked by severity and recency:
Here \(s(l)\) is the lesson severity, \(\Delta t\) is elapsed time since the lesson was recorded, and \(T_{1/2}\) is the half-life. The paper reports a default \(T_{1/2}=30\) days and says this value kept lessons useful across roughly 3-5 later runs without accumulating contradictory stale advice.
Second, ARC-Bench scoring aggregates leaf-level rubric scores:
The important point is that result analysis (RA) receives double weight in the main strict protocol, because the authors treat scientific claim discipline as the main difference between autonomous research and automated scripting.
Method Details
Debate. The paper uses \(K=3\) agents in two places. At hypothesis time, Innovator, Pragmatist, and Contrarian roles generate, feasibility-check, and attack hypotheses before synthesis into 2-4 falsifiable hypotheses. At result-analysis time, Optimist, Skeptic, and Methodologist roles separate supported claims from unsupported ones, scrutinize statistical significance, and look for leakage or reproducibility failures.
Execution and repair. Research plans are scored for implementation complexity using factors such as architectural depth, file count, domain difficulty, dependency chains, historical failure rate, and control-flow complexity. Plans above a threshold \(\tau=0.6\) are routed to an external coding agent; simpler plans use the built-in multi-phase code generator. Generated code runs in Docker with a three-phase network policy: dependency installation, data acquisition, then no-network experiment execution. The Pivot/Refine loop chooses among Proceed, Refine, and Pivot after failures or degenerate results.
Verification. AutoResearchClaw builds a verified numeric registry from execution outputs and injects pre-built tables from that registry into the drafting prompt. A post-hoc verifier checks strict-section numeric claims against the registry. Citation verification uses CrossRef, OpenAlex, arXiv lookup, and Semantic Scholar fallback before an LLM relevance check labels references as Verified, Suspicious, or Hallucinated.
Human collaboration. The seven modes range from Full-Auto through Gate-Only, Thorough, CoPilot, Step-by-Step, Pre-Experiment, and Post-Experiment. CoPilot targets six high-leverage points: literature screening, hypothesis generation, experiment design, result analysis, paper drafting, and quality gate. The paper also describes SmartPause, an uncertainty-driven pause policy that should ask for human input when the system's confidence is low.
Cross-run evolution. At the end of a run, the system extracts lessons from repair attempts, pivot/refine decisions, HITL feedback, and verification failures. These lessons are retrieved by category and weighted with the half-life equation in the equation evidence. The design is deliberately model-agnostic: lessons are injected as prompt overlays rather than through retraining.
Experiments And Results
The benchmark suite has a 25-topic ML ARC-Bench core plus a 20-topic scientific-domain extension. The experiment-stage protocol grades Code Development (CD), Code Execution (CE), and Result Analysis (RA) at weights 25:25:50. Two independent agent reviewers grade each framework-topic cell; leaf disagreements above \(|\Delta| > 0.20\) are re-adjudicated. The results snapshot in Table 3 combines the most important reported quantitative evidence.
On the 25-topic ARC-Bench experiment-stage comparison, AutoResearchClaw CoPilot reports an overall strict score of 0.648 versus 0.511 for AIDE-ML and 0.419 for AI Scientist v2. The paper highlights result analysis as the biggest gap: CoPilot scores 0.523 versus 0.261 for AI Scientist v2, which the authors attribute to result-stage debate and verified result reporting.
For cross-domain coverage, the paper reports AutoResearchClaw CoPilot averages of 0.912 on biology, 0.898 on statistics, and 0.489 on HEP-ph, with an overall score of 0.867. AIDE-ML and AI Scientist v2 fail the physics and biology stacks under the reported setup and score much lower overall. This is supportive of the domain-specialized-agent design, but it depends heavily on the authors' sandbox and software-stack conditions.
The component ablation says removing debate reduces quality by 1.37 points, removing self-healing cuts completion from 10/10 to 6/10, removing cross-run evolution reduces quality by 0.48 and completion by one topic, and removing verification inflates apparent accept count from 3/10 to 5/10 while introducing fabricated values in 3 of those 5 accepted papers. Combined removal of debate and healing drops completion to 4/10 and accept count to 0/4.
| Evidence block | Main numbers | What it supports | Caveat |
|---|---|---|---|
| ARC-Bench experiment-stage | CoPilot 0.648 overall; Full-Auto 0.596; AIDE-ML 0.511; AI Scientist v2 0.419 | AutoResearchClaw performs best under the reported strict judge | Internal benchmark and judge; not independently reproduced here |
| Result analysis gap | CoPilot RA 0.523 vs AI Scientist v2 RA 0.261 | Debate plus registry improve claim grounding | RA remains below 0.6, so absolute quality is still limited |
| HITL ablation | CoPilot mean quality 7.27 and 87.5% accept; Full-Auto 4.03 and 25%; Step-by-Step 5.19 and 50% | Targeted human input beats both extremes | Interventions are scripted, not live user studies |
| Cross-domain coverage | CoPilot 0.912 biology, 0.898 statistics, 0.489 HEP-ph, 0.867 overall | Domain-specialized sandboxes broaden task coverage | Physics score is weaker; baselines fail stack setup |
| Component ablation | w/o debate quality 4.25; w/o self-healing completion 6/10; w/o verification apparent accept 5/10 with fabrication | Mechanisms address distinct failure modes | Best-of-3 setting is favorable and manual audit details are summarized |

Figure 2 is the clearest qualitative example of the paper's argument. Full-Auto passes the numeric registry because the zero values are real logged values, but the result is scientifically uninformative because all compared strategies collapse to identical outputs. CoPilot adds targeted guidance about whether cross-validation strategies produce nonzero contrasts, whether leave-one-out cross-validation fits the budget, and whether claims stay within the logs. This supports the paper's stronger point: verification blocks fabrication, but it does not by itself prove that the experiment answers the research question.
Practical Takeaways
The responsible-use section frames AutoResearchClaw as an amplifier for early-stage exploration, benchmark construction, education, and feasibility studies. The authors explicitly discourage treating it as a substitute for expert judgment or as a bulk paper-generation engine. The risk analysis centers on fabricated results, hallucinated citations, submission flooding, superficial novelty claims, and over-reliance on automated judgments.
| Takeaway | Why it matters | Source-backed caution |
|---|---|---|
| Use autonomous research systems where execution traces and metric registries exist. | Verification depends on captured artifacts, not prose. | The T10 case shows true numbers can still be scientifically meaningless. |
| Put humans at high-leverage gates rather than every step. | CoPilot beats Full-Auto and Step-by-Step in the reported HITL ablation. | The interventions were scripted; live collaboration may behave differently. |
| Treat failure as data. | Pivot/Refine and lesson storage convert failed attempts into future safeguards. | The paper still reports weak absolute execution and result-analysis scores. |
| Keep domain stacks explicit. | Biology, statistics, and HEP coverage depend on sandboxed specialist agents and packages. | Baseline failures in physics/biology are partly environment-stack failures. |
| Disclose and audit autonomous assistance. | The paper's ethics section says humans remain responsible for problem selection, interpretation, final claims, and submission decisions. | Verification reduces, but does not eliminate, scientific integrity risk. |
Reference Coverage: problem framing, Figure 1, contribution, Table 1, mechanism evidence, Table 2, equations, debate, execution, verification, HITL, evolution, evaluation setup, main results, cross-domain, component ablation, Table 3, Figure 2, case study, ethics, and Table 4 are all linked from main text.