Source-first digest for monthly checked paper rank 6, rank_id p020.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
PhysBrain 1.0 argues that embodied models should not learn physical competence only from robot trajectories. Robot demonstrations are expensive, embodiment-specific, and narrow relative to the breadth of physical interaction humans see in ordinary first-person video. The paper's slogan is "understanding first, action next": first train a VLM to represent physical commonsense from egocentric interaction video, then adapt those priors to robot action.
The main empirical question is whether human first-person video can be systematically compiled into useful supervision for physical reasoning, and whether the resulting priors improve downstream embodied control after robot-specific adaptation. This matters for spatial-intelligence work because the paper treats scene layout, object state, metric distance, contact progression, and instruction-conditioned task structure as pre-action knowledge rather than as byproducts of imitation learning.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Large-scale egocentric human interaction video can be converted into structured physical QA rather than only generic captions. | 4 | problem framing, data engine, QA example, QA families |
| C2 | The data engine targets physical commonsense broadly: object state, spatial dynamics, metric depth, affordance, planning, temporal order, and general multimodal retention. | 4 | data engine, depth augmentation, QA families, embodied reasoning format |
| C3 | The VLA architecture is designed to adapt to action while preserving the base model's general multimodal and physical priors. | 4 | training pipeline, dual-pathway equation, robot adaptation |
| C4 | Action-conditioned language alignment is intended to reduce visual shortcuts when limited robot data make instructions predictable from scenes. | 3 | language alignment equations, training pipeline, discussion limits |
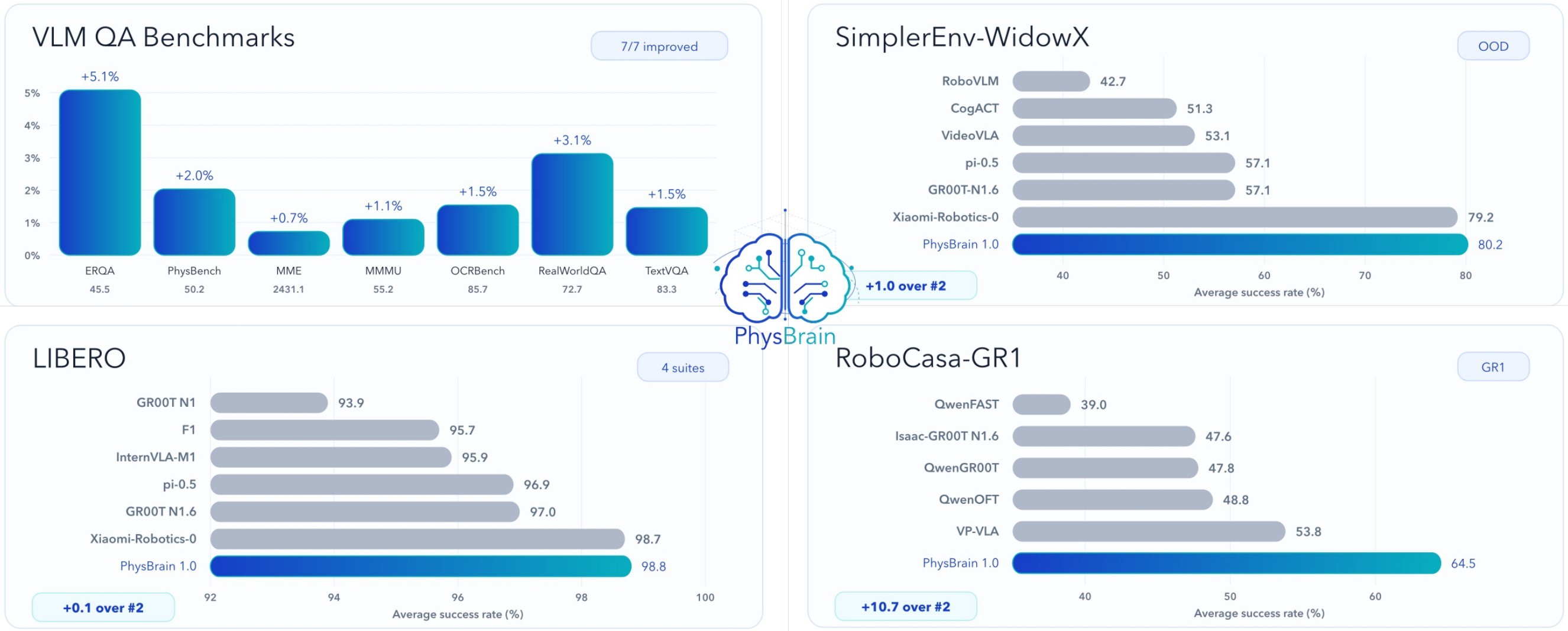
| C5 | PhysBrain improves the base VLM on reported physical and general multimodal QA benchmarks. | 4 | VLM result figure, VLM gains table |
| C6 | The VLA policy reports the best average score in all four simulation result tables: SimplerEnv-WidowX, SimplerEnv-GoogleRobot, RoboCasa-GR1, and LIBERO. | 5 | simulation summary, simulation table |
| C7 | In real-world Franka experiments, PhysBrain improves over pi_0.5 under the same post-training and evaluation protocol. |
4 | Franka setup, real-world results, real-world summary |
| C8 | The broad conclusion that human-derived physical priors improve embodied transfer is plausible but still bounded by annotation quality, depth errors, embodiment mismatch, and benchmark coverage. | 3 | simulation summary, real-world results, limitations |
Support scores are support-from-paper scores, not reproduction scores. Table-backed claims receive higher scores; architectural intent and broad transfer claims are capped when the paper does not isolate every confound with ablations.
Core Technical Idea
PhysBrain's central move is to place a structured physical-knowledge layer between raw human video and robot policy training. Raw first-person video is not used as generic caption data. It is first converted into scene meta-information with explicit fields for objects, spatial changes, and action execution, augmented with depth-aware relations, and rendered into natural-language QA.
The data engine has a compiler-like structure. Clips from Ego4D, BuildAI, EgoDex, EPIC, and SEA-Small are filtered for visual quality and camera motion. Selected clips are annotated into JSON-style records with scene_elements, spatial_dynamics, and action_execution. These records describe material cues, geometry, object state, initial layout, changes over time, and imperative execution details. The paper emphasizes that the structured record is not the final model target; it is a validated source artifact for downstream QA generation.
Depth-aware augmentation adds relative and absolute spatial supervision. For clips with object grounding metadata, the pipeline uses Depth Anything v3 to sample object-center depth and create a compact depth_info field. That supports questions about nearer/farther relations, reachability, object scale, and metric distances. This is the bridge from visual commonsense to continuous end-effector action: a model trained only on ordinal layout may know which object is closer, while a model exposed to metric depth has a stronger basis for reasoning about displacement.
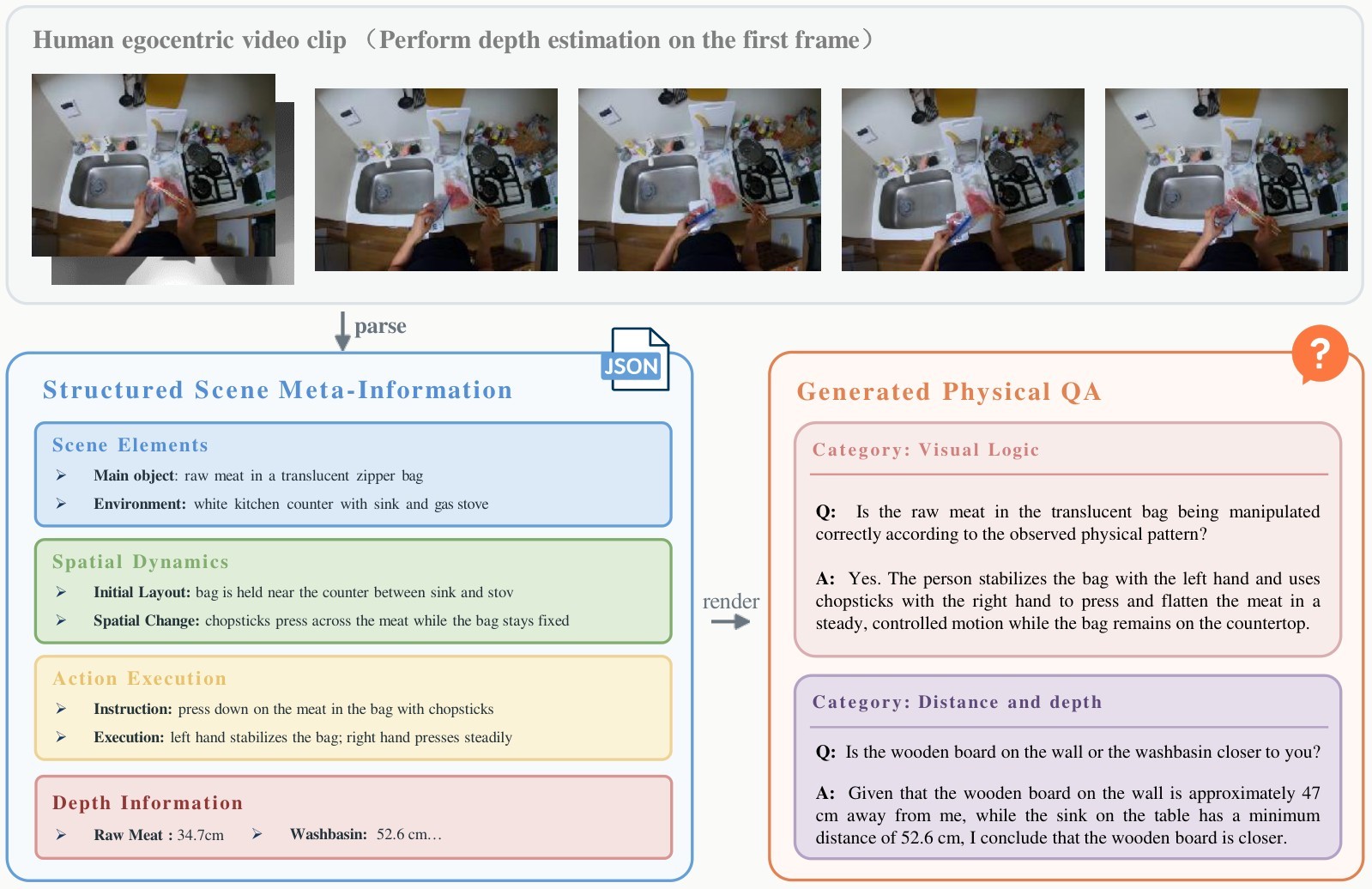
| Capability group | Example QA families from the paper | Intended training role |
|---|---|---|
| Spatial and metric grounding | spatial relations, distance and depth, size estimation, grounding and coordinates, viewpoint reasoning | Learn 3D layout, metric distance, object location, and viewpoint consistency. |
| Embodied decision making | next-step prediction, route planning, affordance and safety, long-horizon planning | Connect perception to feasible action choices and multi-step task decomposition. |
| Dynamics and time | object state change, action recognition/counting, temporal ordering, action localization, causal/counterfactual reasoning | Model change, contact sequence, and why/what-if physical reasoning. |
| Fine-grained perception | counting, fine-grained attributes, existence checking | Reduce hallucination and improve attribute-sensitive physical reading. |
| General retention | OCR, chart/data analysis, science/technical knowledge, visual logic | Preserve broad multimodal competence while adding physical priors. |
Table 1. QA capability coverage. The QA family table condenses the source table into the main capability groups used to turn one physical clip into many supervised reasoning targets.
For physical interaction questions, answers follow an embodied reasoning order:
The paper treats this as a training format for organizing perception before action. In other words, the model should identify the environment, characterize the object and its state, reason about spatial layout, and only then describe execution.
Quality control is applied at stage boundaries. The pipeline filters low-quality or unstable clips, requires parseable JSON with expected fields, checks depth assets and object-grounding paths, and assigns failure statuses rather than silently passing malformed records into QA generation. This does not eliminate semantic noise, but it makes many failure modes visible before training.
Method Details
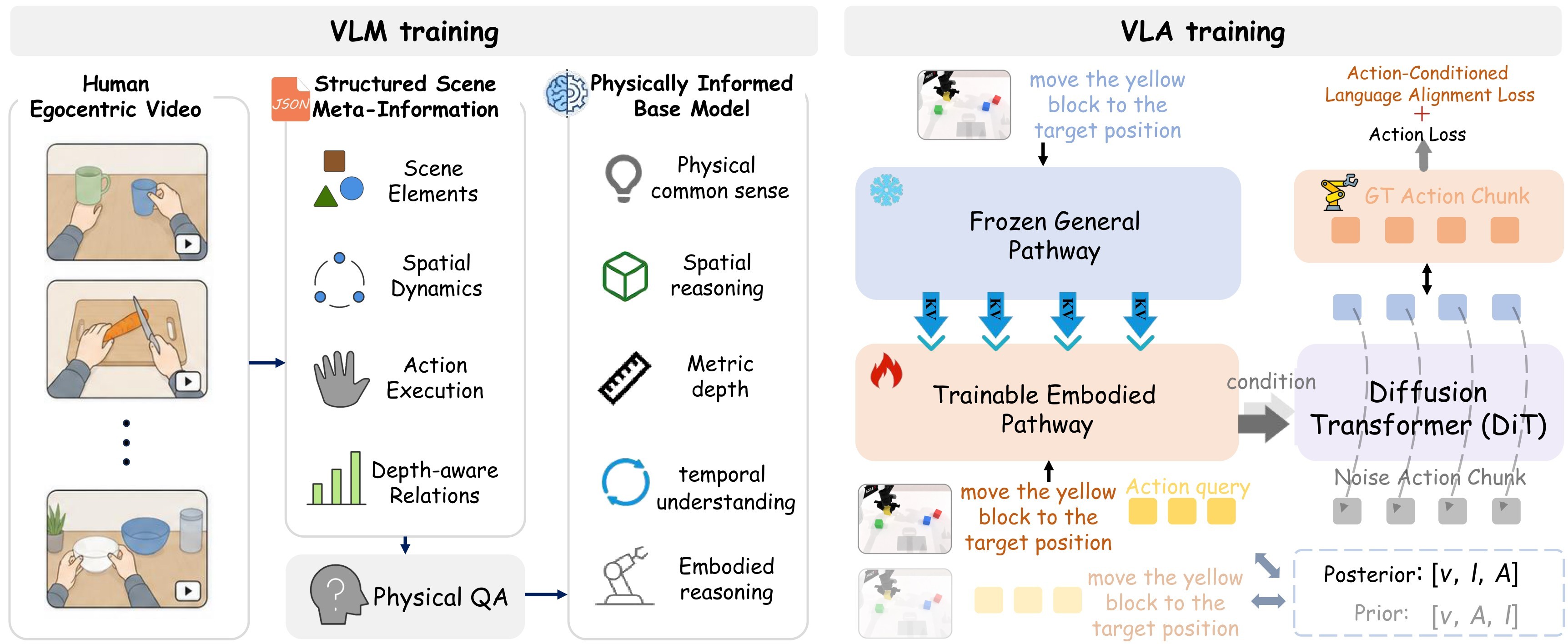
Physically Informed Base Model
PhysBrain starts from a general multimodal backbone and adapts it with the generated physical QA. This stage is deliberately not a robot-control stage. It teaches the base VLM to organize first-person physical scenes around objects, relations, depth, task feasibility, temporal dynamics, and execution plans. General multimodal QA is mixed in as retention data so physical tuning does not erase OCR, chart, logic, and knowledge capabilities.
Capability-Preserving VLA Adaptation
The robot adaptation architecture separates a frozen general pathway from a trainable embodied pathway. If \(\mathbf{H}_G^l\) and \(\mathbf{H}_E^l\) are the layer-\(l\) hidden states, the embodied pathway uses stop-gradient key/value features from the general pathway:
This is the main preservation mechanism. The action-learning gradients specialize the embodied pathway and action decoder while the frozen general branch remains a semantic reference.
Action-Conditioned Language Alignment
The paper argues that limited robot data can make language weakly used: in a narrow dataset, the scene may predict the command well enough that the policy learns a visual shortcut. PhysBrain compares two action-query contexts. The prior sequence lets action queries attend to vision but not the instruction:
The posterior sequence lets action queries attend to both vision and language:
The paired branches support a likelihood-ratio-style alignment term that encourages the action representation to keep instruction-relevant information. This is a design claim rather than a fully isolated ablation claim in the extracted text, so it receives a moderate support score.
Unified Action Generation
Continuous actions are generated from the language-conditioned action-query states with a flow-matching decoder. Let \(\mathbf{a}_1\) be the ground-truth action trajectory, \(\mathbf{a}_0 \sim \mathcal{N}(0,I)\) be Gaussian noise, \(\mathbf{a}_t=(1-t)\mathbf{a}_0+t\mathbf{a}_1\), and \(\mathbf{C}\) be the query-state condition. The decoder optimizes:
The predicted trajectory is represented in an end-effector-frame action space with translation and rotation. The method link back to the data engine is direct: metric depth and spatial QA are meant to make continuous pose displacement easier to interpret before action fine-tuning.
Robot adaptation is still required. The paper adapts PhysBrain to each benchmark's embodiment-specific data: Bridge data for SimplerEnv-WidowX, Google Robot adaptation data for SimplerEnv-GoogleRobot, the official LIBERO demonstrations, RoboCasa-GR1 teleoperation simulation data, and separately collected Franka vegetable demonstrations for real-world experiments. The claim is therefore data-efficient adaptation, not robot-data-free control.
Experiments And Results
VLM Results
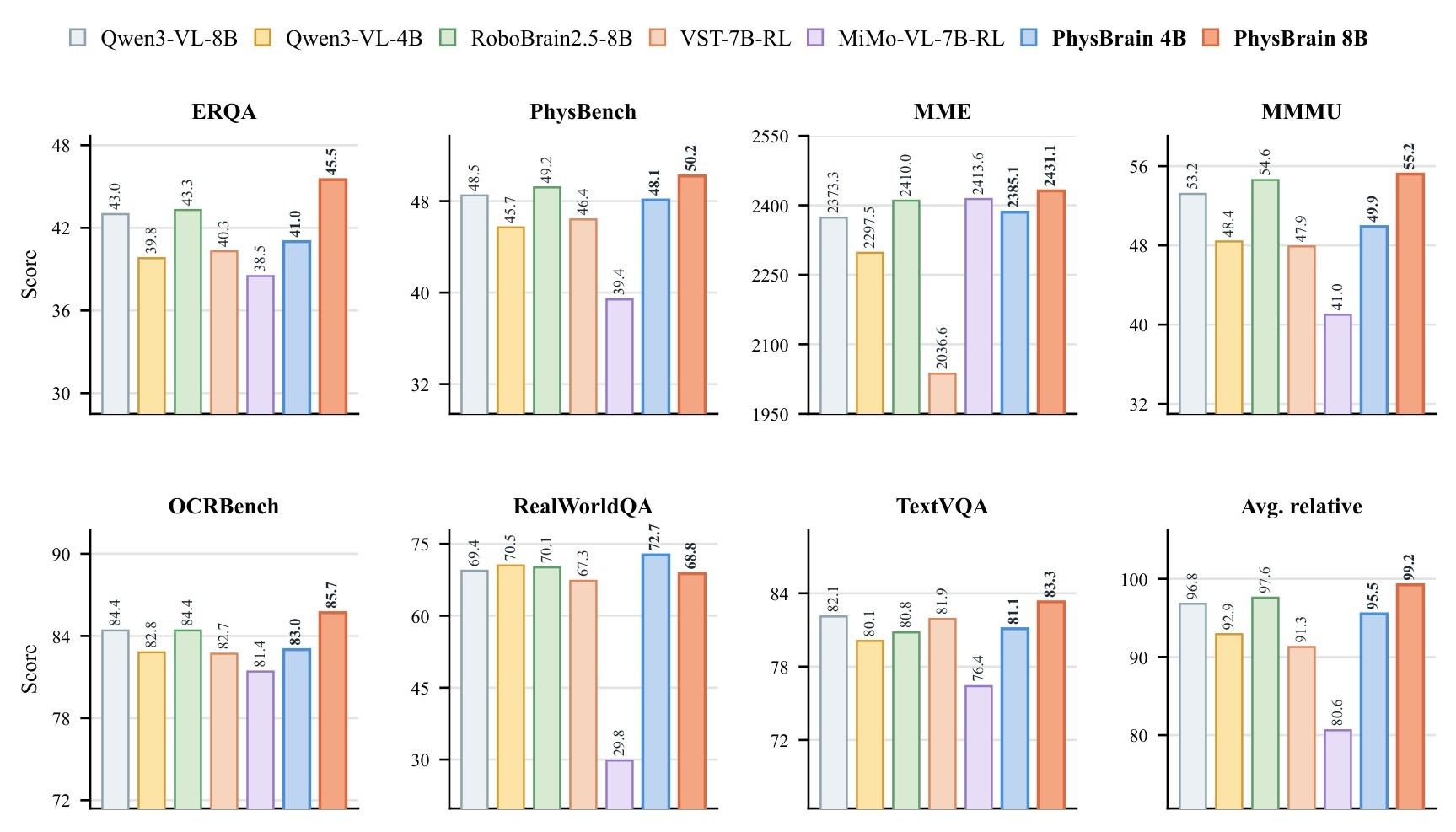
| Reported comparison | Baseline | PhysBrain | Gain |
|---|---|---|---|
| ERQA, 8B scale | 43.0 | 45.5 | +2.5 |
| PhysBench, 8B scale | 48.5 | 50.2 | +1.7 |
| MME, 8B scale | 2373.3 | 2431.1 | +57.8 |
| MMMU, 8B scale | 53.2 | 55.2 | +2.0 |
| RealWorldQA, 4B scale | 70.5 | 72.7 | +2.2 |
Table 2. Text-reported VLM gains. The VLM gains table lists the numeric improvements explicitly described in the source text. The result supports the claim that physical QA tuning did not simply trade off broad multimodal competence for embodied-only specialization.
VLA Simulation Results
The simulation suite covers four settings with different embodiments and task structures. SimplerEnv-WidowX and SimplerEnv-GoogleRobot test out-of-domain manipulation after embodiment-specific training. RoboCasa-GR1 tests bimanual dexterous tabletop manipulation across 24 tasks. LIBERO tests standardized Franka language-conditioned manipulation on Spatial, Object, Goal, and Long suites.
| Benchmark | PhysBrain average | Strongest prior in source table | Margin | Notes |
|---|---|---|---|---|
| SimplerEnv-WidowX | 80.2 | 79.2, Xiaomi-Robotics-0 | +1.0 | Best average across four held-out tasks; ties or leads on several task columns. |
| SimplerEnv-GoogleRobot | 91.33 | 89.03, Xiaomi-Robotics-0 | +2.30 | Reaches 100.0 on Pick Coke Can and improves Move Near from 88.8 to 94.8. |
| RoboCasa-GR1 | 64.5 | 53.8, VP-VLA | +10.7 | Best average over 24 tabletop manipulation tasks. |
| LIBERO | 98.8 | 98.7, Xiaomi-Robotics-0 | +0.1 | Near-saturated benchmark; still best average with 99.6 L-Spatial and 99.4 L-Goal. |
Table 3. VLA simulation summary. The simulation table condenses the four source result tables. It is strong evidence for reported benchmark performance, but it is still benchmark evidence rather than a complete causal isolation of the pretraining signal.
Real-World Franka Results


The real-world setup is a controlled comparison against pi_0.5: both models are post-trained on the same Franka data and evaluated over the same 50-trial protocol. Single-object trials count stable grasp-and-lift success. Long-horizon tasks require completing semantic instructions such as collecting all green vegetables or orange vegetables into a basket.
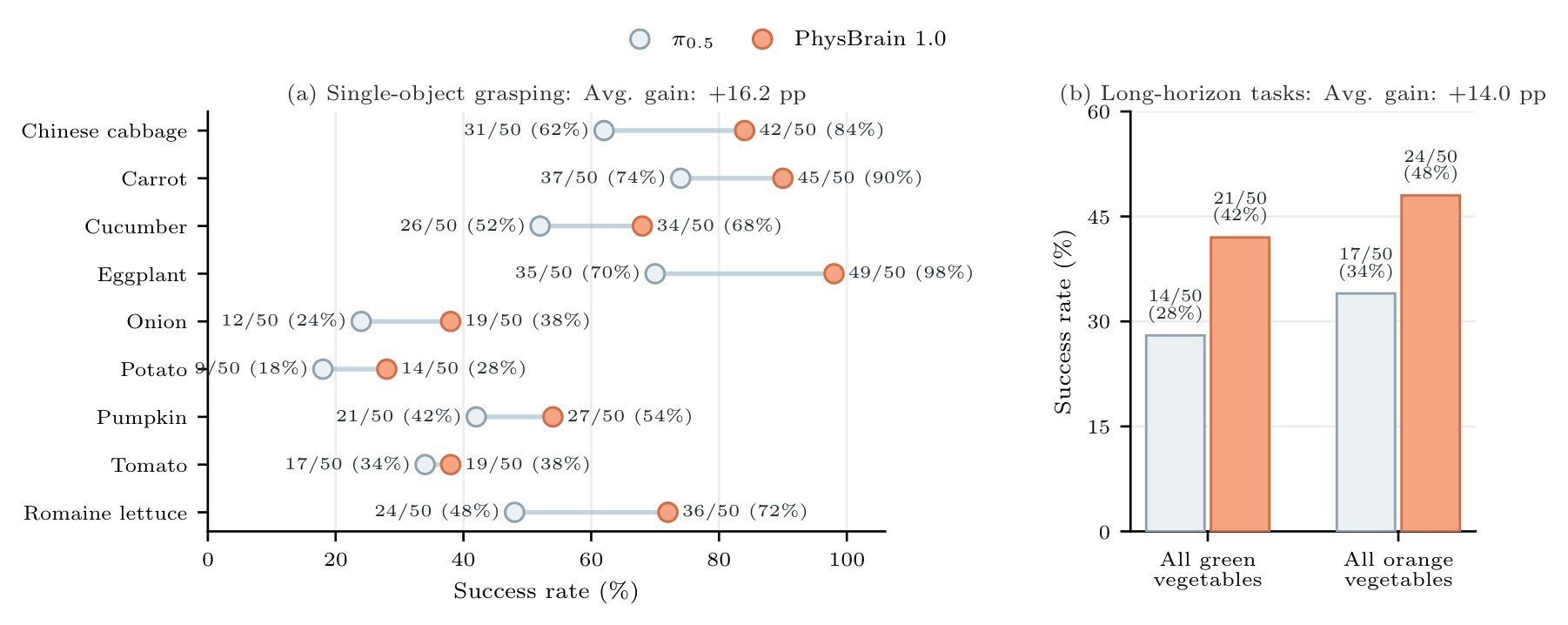
pi_0.5 on vegetable grasping and long-horizon semantic instructions. The source caption and text report that PhysBrain uses a single post-trained policy across categories and long-horizon tasks.| Setting | pi_0.5 |
PhysBrain 1.0 | Gain |
|---|---|---|---|
| Nine single-object grasping tasks | 212/450, 47.1% | 285/450, 63.3% | +16.2 percentage points |
| Two long-horizon semantic tasks | 31/100, 31.0% | 45/100, 45.0% | +14.0 percentage points |
Table 4. Real-world Franka summary. The real-world summary table captures the paper's strongest real-robot evidence. The source text notes gains on every single-object category, with visible gains on deformable or visually ambiguous objects such as Chinese cabbage and romaine lettuce and on smooth objects such as eggplant.
Practical Takeaways
- Human video can be a physical-prior source. The paper's useful idea is not "train on more video" in a generic sense; it is to turn egocentric interaction video into structured, validated physical records before producing QA.
- Metric depth is part of the bridge to control. The data engine's relative and absolute depth supervision is explicitly connected to end-effector-frame action generation, where continuous displacement matters.
- Robot data remains necessary. PhysBrain shifts robot trajectories into an adaptation role. The policy still needs embodiment-specific demonstrations for WidowX, GoogleRobot, LIBERO, RoboCasa-GR1, and Franka.
- The architecture separates preservation from specialization. The frozen general pathway protects physical and multimodal priors, while the trainable embodied pathway and flow-matching decoder learn action.
- The strongest evidence is benchmark and real-robot performance, not complete causal decomposition. The paper reports broad gains, but the extracted text does not provide exhaustive ablations isolating each data-engine component, depth augmentation, language alignment objective, and adaptation module.
Limitations are explicit. Annotation quality remains dependent on upstream perception and model annotators. Depth supervision inherits object-grounding and depth-estimation errors. Human egocentric priors are not identical to robot embodiment constraints. SimplerEnv, LIBERO, RoboCasa, and the Franka vegetable setup are informative but do not cover all long-horizon autonomy, deformable manipulation, safety-critical execution, or closed-loop recovery under severe distribution shift.
Reference Coverage
Figure anchors: system overview, QA example, training pipeline, VLM results, Franka setup, real-world results.
Table anchors: QA families, VLM gains, simulation summary, real-world summary.
Evidence anchors: problem, data engine, depth QA, QA generation, reasoning format, quality control, architecture, dual pathway, language alignment, flow matching, robot adaptation, VLM results, VLA simulation, real-world setup, real-world results, limitations.