Source-first digest for monthly checked paper rank 9, rank_id p024.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
Vision-language models can already answer visual grounding prompts by generating coordinate tokens, but most systems serialize a 2D region into a 1D text stream. The paper's starting point is that a bounding box is not four unrelated next-token predictions: the coordinates are a coupled geometric unit. Sequential coordinate generation therefore creates two problems at once: it is slow at inference time, and it asks the model to learn box geometry through a representation that fragments the object.
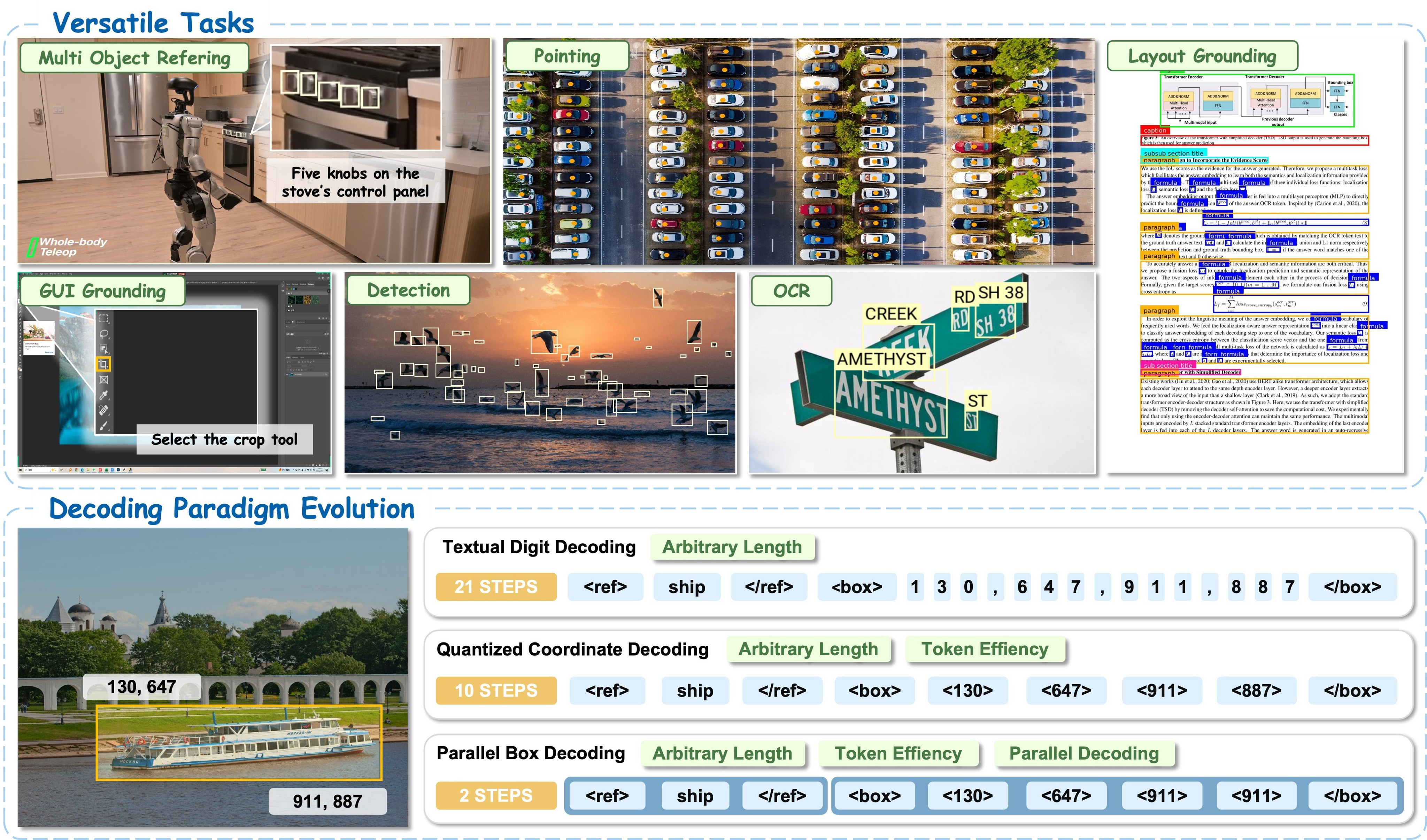
The paper's scope is summarized in Figure 1: one VLM is asked to support object detection, referring expression comprehension, GUI grounding, OCR, layout grounding, and pointing, while replacing token-by-token box generation with atomic box prediction.
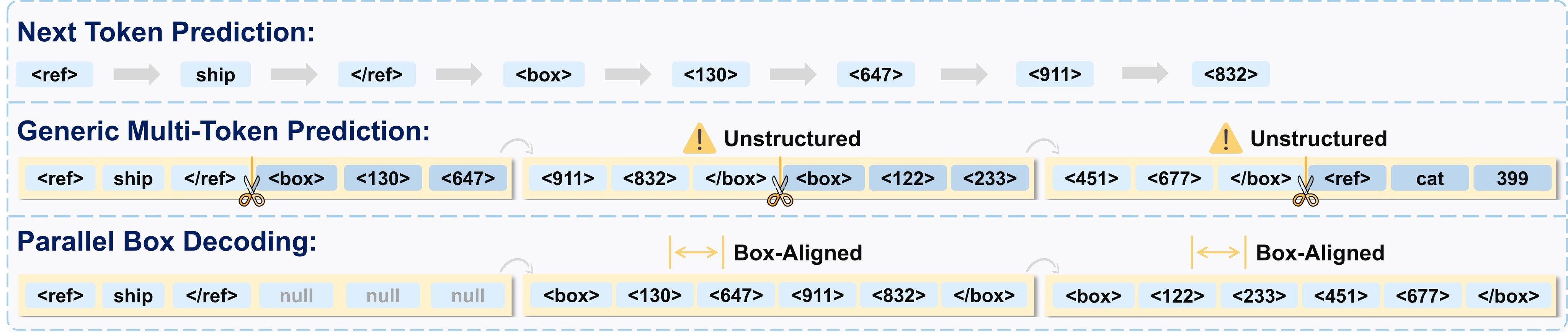
The comparison in Figure 2 makes the modeling objection more concrete. Standard next-token prediction (NTP) emits coordinates one at a time, and generic multi-token prediction (MTP) can split tokens across object and box boundaries. LocateAnything instead aligns each parallel block with a box or point, so the parallel step has the same semantic granularity as the geometry.
The work is also motivated by deployment: GUI agents, robotics, real-time detection, dense OCR, and embodied interaction need fast region-level grounding. The paper frames LocateAnything as a unified generative grounding and detection framework that can trade off speed and spatial robustness through Fast, Slow, and Hybrid decoding modes.
Claims And Evidence
Support scores are support-from-paper scores, not reproduction scores. Table-backed and ablation-backed claims receive higher scores; qualitative or deployment-generalization claims are capped lower.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Serializing a box as coordinate tokens is both a speed bottleneck and a poor fit for coupled geometry; PBD is a better output unit. | 5 | problem setup, decoding comparison, block formulation, ablation |
| C2 | The block-based model and joint NTP/MTP training preserve causal language-model behavior while enabling box-level parallel decoding. | 4 | block formulation, training mask, key formulas, ablation |
| C3 | Hybrid decoding keeps most of the PBD speed gain while repairing format irregularity and spatial ambiguity with local NTP re-decoding. | 4 | hybrid fallback, mode summary, ablation |
| C4 | The large LocateAnything-Data engine gives broad supervision across detection, GUI, referring, OCR, layout, and pointing. | 4 | dataset scale, data engine, dataset statistics, prompt table |
| C5 | On the reported benchmarks, LocateAnything improves the speed-accuracy frontier against VLM grounding baselines such as Qwen3-VL and Rex-Omni. | 5 | main detection table, dense detection table, open-world table, speed evidence |
| C6 | The method is strongest as a practical hybrid system rather than as pure Fast decoding: Slow is often most accurate, Fast is fastest, Hybrid is the default compromise. | 5 | mode summary, mode table, hybrid fallback |
| C7 | PBD is not tied to one backbone and transfers to a Qwen3-VL-4B controlled ablation. | 3 | backbone generalization, ablation |
| C8 | The paper's qualitative examples support broad task coverage, but they should be read as illustrative rather than as independent quantitative evidence. | 2 | qualitative overview, qualitative comparisons |
Core Technical Idea
The central technical move is to change the unit of generation. Instead of generating a box as:
LocateAnything normalizes coordinates to [0, 1000], discretizes them into coordinate tokens, and groups the resulting output into box-aligned blocks:
Conditioned on visual tokens \(Z\) and a text query \(\mathcal{E}\), the block sequence is modeled autoregressively across blocks:
Each block has constant length \(L=6\), enough for a box token wrapper plus four quantized coordinates. Padding with <null> keeps tensor shapes uniform. The important detail is that tokens inside the current block are predicted together, while blocks still follow causal order.
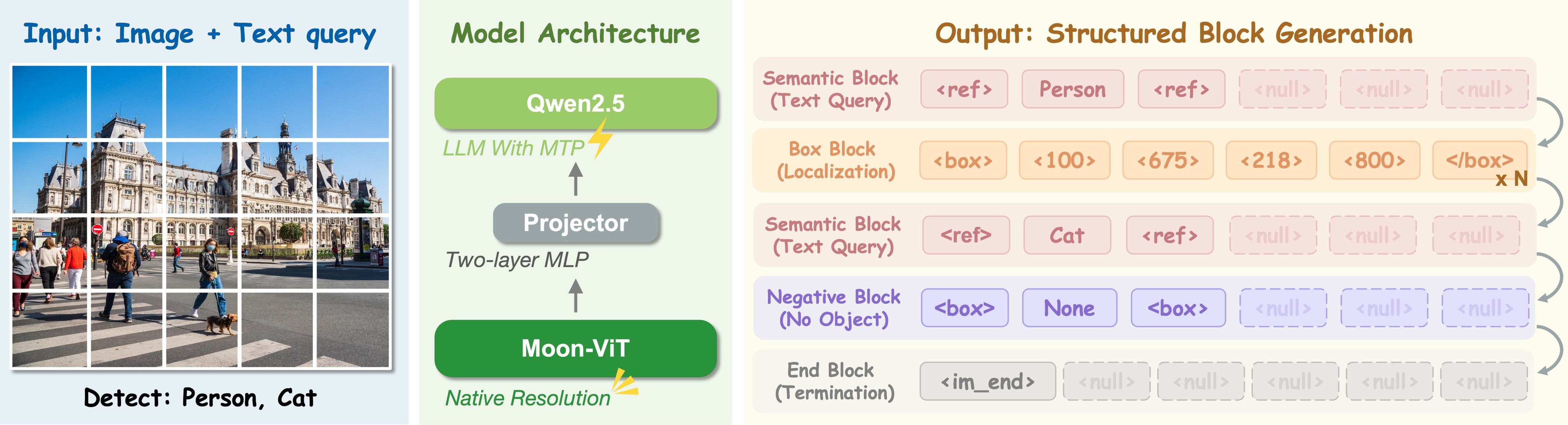
Figure 3 shows the resulting architecture and four functional block types: Semantic, Box, Negative, and End. This gives the model a way to generate object identity, one or more regions, explicit absence, and sequence termination with one shared output grammar.
The joint training sequence concatenates shared visual and query context, the NTP stream, and the block-wise MTP stream:
The training target is the same ground truth represented twice: once as a token-level sequence and once as a block-level sequence. The paper's objective is:
The structured equation index reported zero display equations, so the formulas above are key inline formulas recovered from the LaTeX-derived Markdown and flattened TeX, not from raw PDF extraction.
Method Details
Joint NTP-MTP Attention
The dual stream would leak answers if the autoregressive stream could attend to future block tokens. LocateAnything therefore uses the heterogeneous attention pattern illustrated in Figure 4.
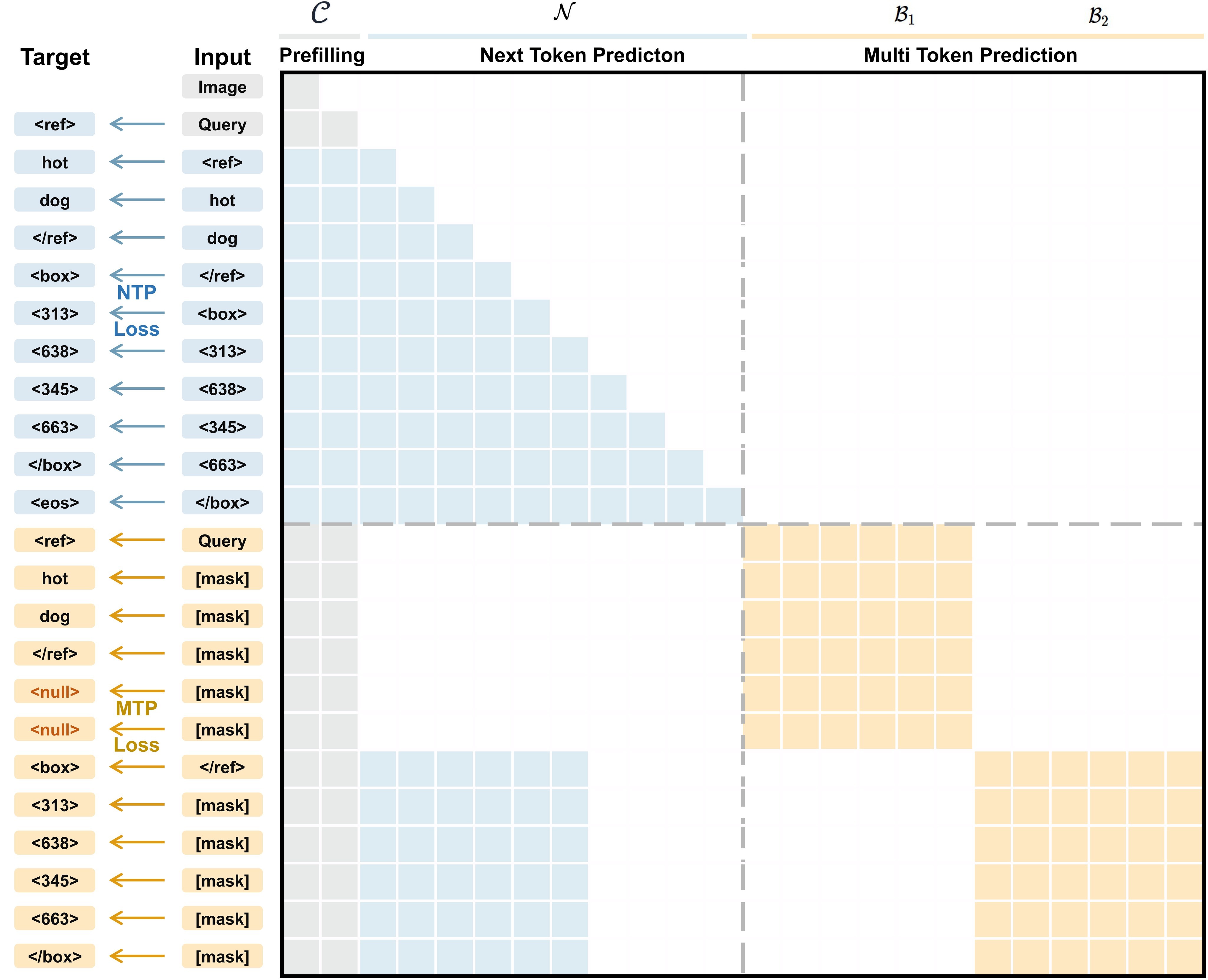
This mask is the mechanism that lets the model keep ordinary causal LM behavior while training a block-level prediction interface. During inference, previously committed tokens remain in the KV cache, and the active MTP block attends bidirectionally inside itself. After the MTP step, only actually committed output tokens are kept in cache; mask tokens and duplicated anchors are evicted.
On-Demand Decoding
PBD is fast, but the paper identifies two hard cases. Format irregularity happens around category or object-boundary transitions, where a block can mix structural and coordinate tokens. Spatial ambiguity happens in dense grids, where parallel coordinate distributions can blur between adjacent objects. Figure 5 shows the repair policy.

The ambiguity trigger is explicit:
where the coordinate space is normalized to [0, 1000]. The three inference modes are:
- Slow Mode: pure NTP, maximum stability, lower throughput.
- Fast Mode: pure MTP over box-aligned blocks, maximum throughput.
- Hybrid Mode: MTP by default, local NTP fallback when format or spatial checks fail.
The inference hyperparameters reported in the source are temperature 0.7, top-p 0.9, repetition penalty 1.1, BF16 precision, batch size 1, MTP block size \(n_{\text{future}}=6\), and maximum new tokens 8192.
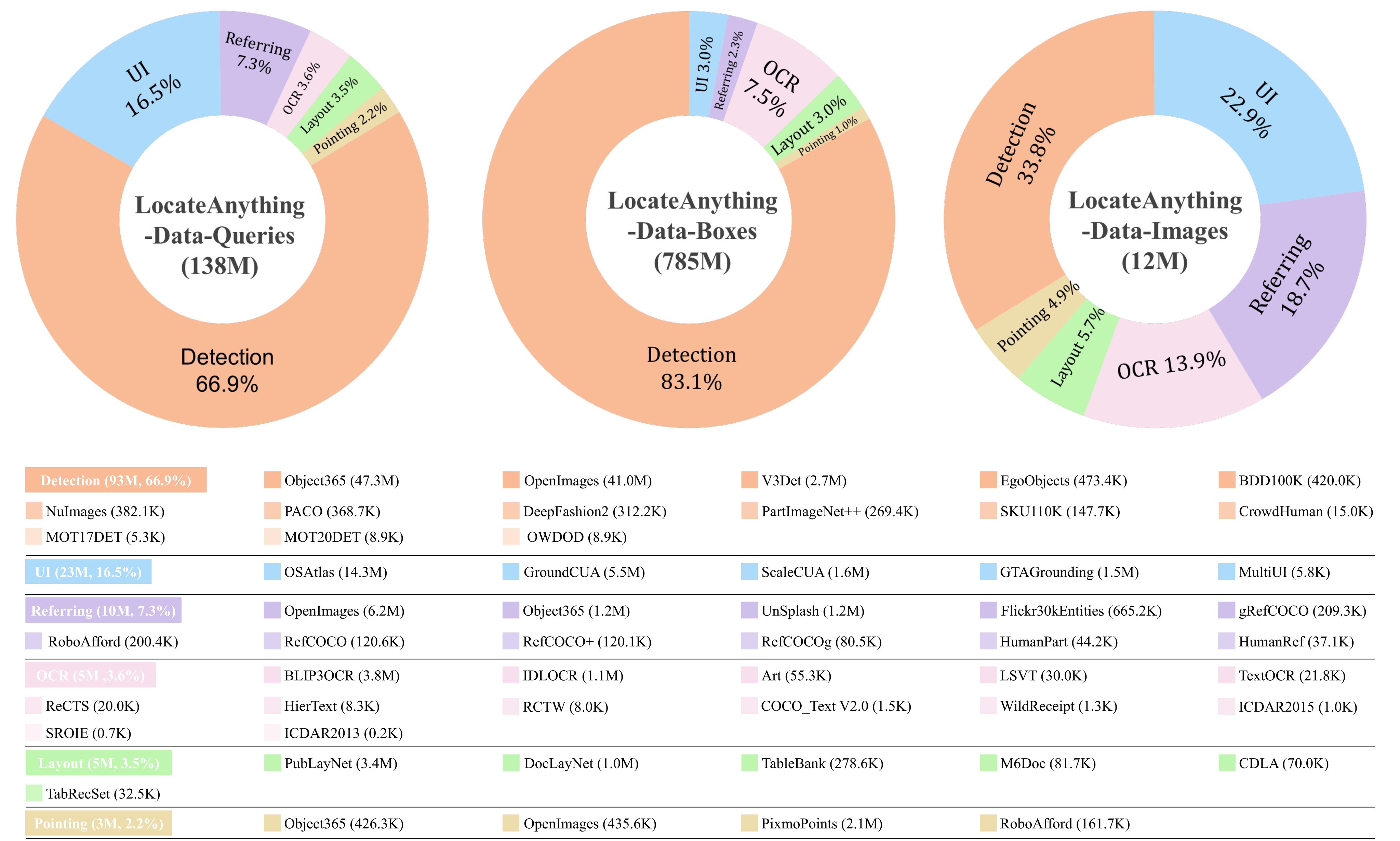
LocateAnything-Data
The method is coupled to a large data engine. The main text reports 12M unique images, 138M natural-language queries, and 785M annotated boxes; the supplementary table reports over 139M queries after domain breakdown. Figure 6 is the paper's visual summary of this corpus.
The data engine in Figure 7 has two paths. For detection datasets with ground-truth boxes, Qwen3-VL synthesizes richer object-centric queries, Molmo proposes points, and points inside the target boxes are kept. For unlabeled images, Qwen3-VL proposes queries, Molmo or Rex-Omni/SAM 3 supplies geometry, and Qwen3-VL post-verifies the boxes.
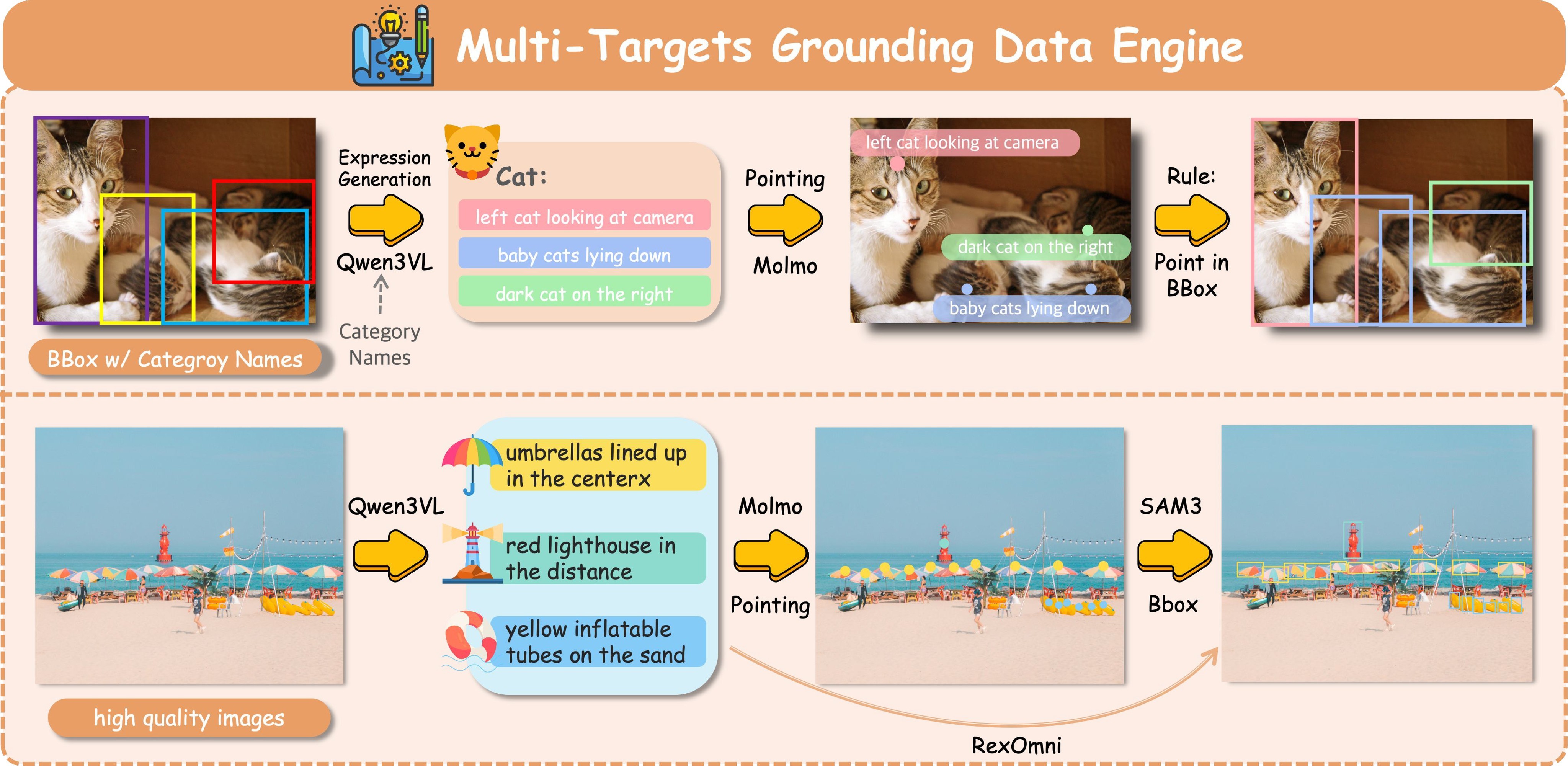
The source also highlights negative examples. Detection, layout, referring, and pointing domains include negative samples so the model can learn the Negative block and avoid predicting regions for absent objects.
| Domain | Queries | Negative samples | Mean targets/query | Mean categories/query | Mean query length | Mean targets/image |
|---|---|---|---|---|---|---|
| Detection | 93,351,373 | 21,021,509 | 6.29 | 2.47 | 24.19 | 30.68 |
| GUI | 23,009,535 | 0 | 1.03 | 1.03 | 4.07 | 7.95 |
| Referring | 10,141,597 | 93,396 | 2.12 | 0.89 | 5.48 | 9.65 |
| OCR | 5,052,040 | 0 | 11.89 | 10.4 | 1.17 | 28.67 |
| Layout | 4,859,914 | 1,384,804 | 4.92 | 1.31 | 2.2 | 21.17 |
| Pointing | 3,148,098 | 353,366 | 3.25 | 0.89 | 2.63 | 14.92 |
Table 1. Dataset statistics. This table is reconstructed from main.flattened.tex because the Markdown conversion left the table body empty. It explains why the training set supports both dense multi-object boxes and negative abstention.
Figure 8 complements Table 1 by showing the long-tailed number of targets per query.
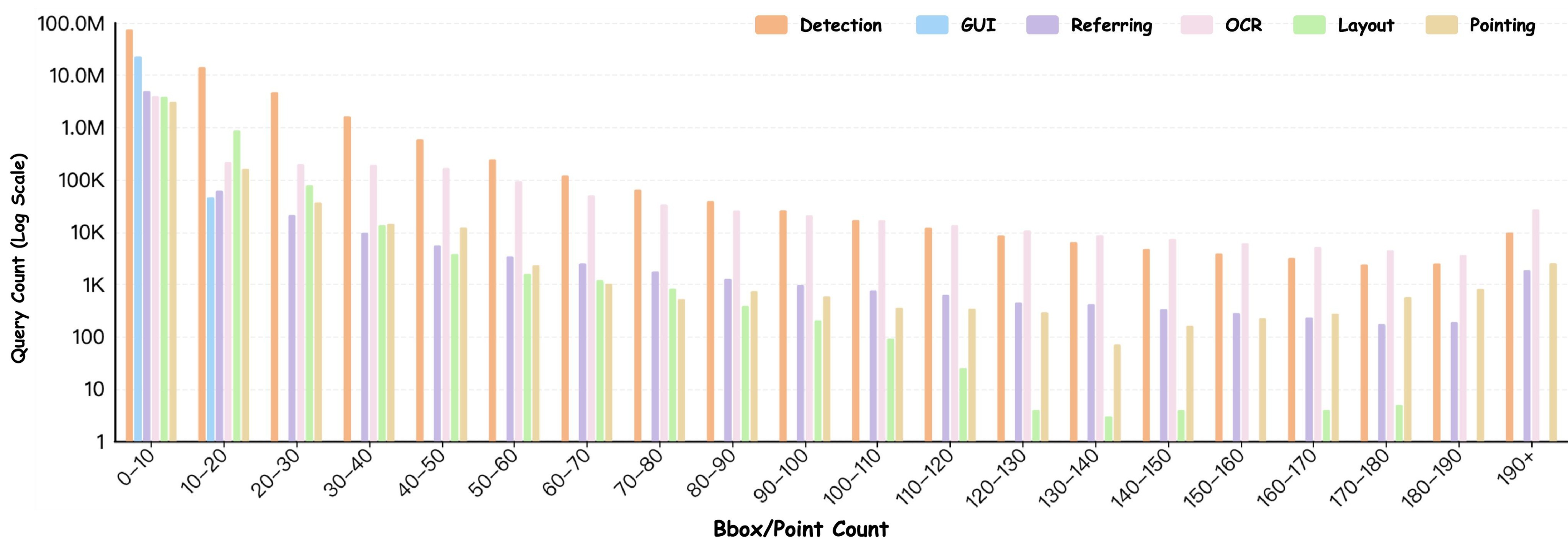
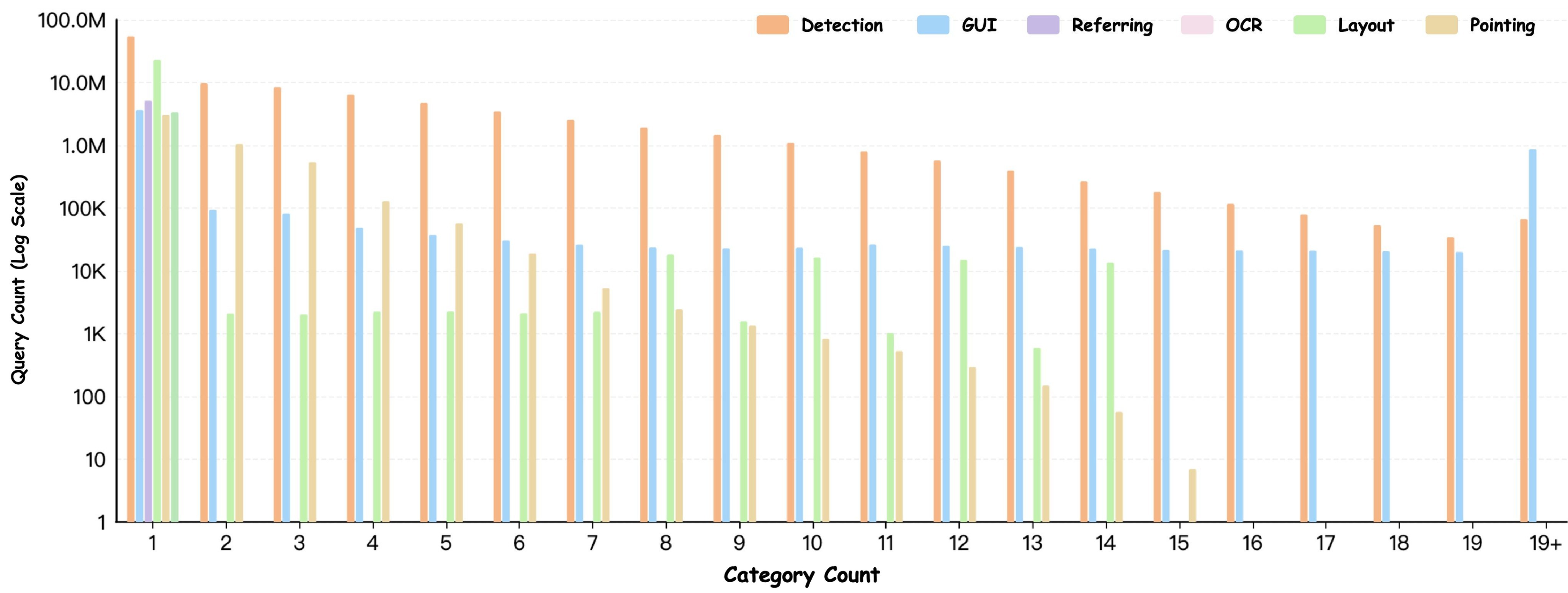
Figure 9 shows the query-length distribution across domains.
| Task family | Output | Example prompt template |
|---|---|---|
| Object Detection | Box | Locate all instances matching [CATEGORIES]. |
| Object Detection | Single or multiple boxes | Locate one or all instances matching [PHRASE]. |
| Text Grounding | Box | Please locate the text referred as [PHRASE]. |
| Scene Text Detection | Box | Detect all the text in box format. |
| Document Layout Analysis | Box or point | Detect categories, locate a phrase, or point to [PHRASE]. |
| Pointing | Point | Point to [PHRASE]. |
Table 2. Prompt design. The prompt families show how the same decoder is used for box and point outputs across detection, OCR, layout, referring, GUI, and pointing tasks.
Experiments And Results
Main Detection And Grounding Results
The main comparison in Table 3 reports hybrid-mode LocateAnything on LVIS and COCO, with throughput measured as boxes per second on one NVIDIA H100 at batch size 1.
| Method | Throughput BPS | LVIS mean F1 | COCO mean F1 | Notes |
|---|---|---|---|---|
| Qwen3-VL-4B | 1.1 | 43.5 | 46.1 | Textual/serial VLM baseline |
| Qwen3-VL-8B | 1.0 | 44.8 | 45.7 | Larger textual/serial VLM baseline |
| SEED1.5-VL | n/a | 46.7 | 51.4 | Best LVIS F1@0.5 among VLM baselines |
| Rex-Omni-3B | 5.0 | 46.9 | 52.9 | Quantized coordinate specialist |
| LocateAnything-3B | 12.7 | 50.7 | 54.7 | Highest mean F1 among VLM-style methods and fastest reported throughput |
Table 3. LVIS and COCO results. LocateAnything improves mean F1 over Rex-Omni by +3.8 on LVIS and +1.8 on COCO while reporting 12.7 BPS versus Rex-Omni's 5.0 BPS.
The speed claim is strongest when comparing decoding representations: the main table reports 12.7 BPS for LocateAnything, 5.0 BPS for Rex-Omni, and roughly 1.0-1.1 BPS for Qwen3-VL-style textual decoding. This supports the paper's claim of 2.5x throughput over Rex-Omni and more than 10x over textual-coordinate VLMs in the reported setup.
Table 4 focuses on dense and small-object settings. It is important because dense scenes are exactly where a parallel decoder could blur boxes if the formulation were weak.
| Method | Dense200 mean F1 | VisDrone mean F1 |
|---|---|---|
| Grounding DINO-Swin-T | 33.1 | 38.5 |
| SEED1.5-VL | 53.2 | 27.4 |
| Rex-Omni-SFT-3B | 46.4 | 32.4 |
| Rex-Omni-3B | 58.3 | 35.8 |
| LocateAnything-3B | 58.7 | 39.9 |
Table 4. Dense detection. LocateAnything is only slightly above Rex-Omni on Dense200 mean F1, but it improves VisDrone mean F1 by 4.1 points over Rex-Omni and is much faster in the main throughput comparison.
Table 5 condenses GUI, document, OCR, and referring results.
| Benchmark | LocateAnything result | Best comparison named in source | Interpretation |
|---|---|---|---|
| ScreenSpot-Pro Avg | 60.3 | GUI-Owl-32B at 58.0; UI-Venus-1.5-2B at 57.7 | Strong GUI grounding despite a 3B model size |
| DocLayNet mean F1 | 76.8 | DocLayout-YOLO at 81.1; Rex-Omni at 70.7 | Below a specialized layout detector, above VLM specialists |
| M6Doc mean F1 | 70.1 | Rex-Omni at 55.6 | Large gain on document layout grounding |
| TotalText mean F1 | 43.3 | Rex-Omni at 40.6; Qwen3-VL-8B at 37.3 | Best reported OCR-region grounding among listed VLMs |
| HumanRef mean F1 | 78.7 | Rex-Omni at 79.9; SEED1.5-VL at 81.6 | Competitive but not best on this referring benchmark |
| RefCOCOg test mean F1 | 77.6 | DeepSeek-VL2-Small at 81.6 | Strong but not top on classic REC |
Table 5. Open-world localization. The paper's broadest evidence is not that LocateAnything wins every dataset, but that it remains competitive or leading across GUI, dense detection, layout, OCR, and referring while preserving high decoding throughput.
Ablations
Table 6 is the strongest controlled evidence for PBD itself because the ablation models are trained only on COCO, isolating the decoding formulation from the 138M-query data scale.
| Ablation setting | Throughput BPS | Mean F1 | Takeaway |
|---|---|---|---|
| Textual NTP | 1.3 | 49.1 | Serial digit-like decoding is slow and less accurate. |
| Quantized NTP | 3.9 | 50.1 | Quantized coordinates speed up decoding but still serialize geometry. |
| PBD Slow | 3.9 | 52.1 | Box-aligned representation improves accuracy even without parallel speed. |
| PBD Fast | 16.9 | 49.6 | Maximum speed, with accuracy drop in hard scenes. |
| PBD Hybrid | 13.2 | 51.6 | Keeps most speed while recovering much of Slow-mode accuracy. |
| SDLM-B6 | 5.5 | 46.1 | Structure-agnostic block MTP underperforms box-aligned PBD. |
| Block Diff-B6 | 4.7 | 44.8 | Generic block diffusion is not enough for box geometry. |
Table 6. PBD ablations. The most important line is not only that Fast is 16.9 BPS, but that Slow PBD outperforms textual and quantized NTP at equal or better throughput. This supports the claim that box alignment improves supervision, not only latency.
Figure 10 visualizes the same speed pattern as the number of predicted boxes increases.
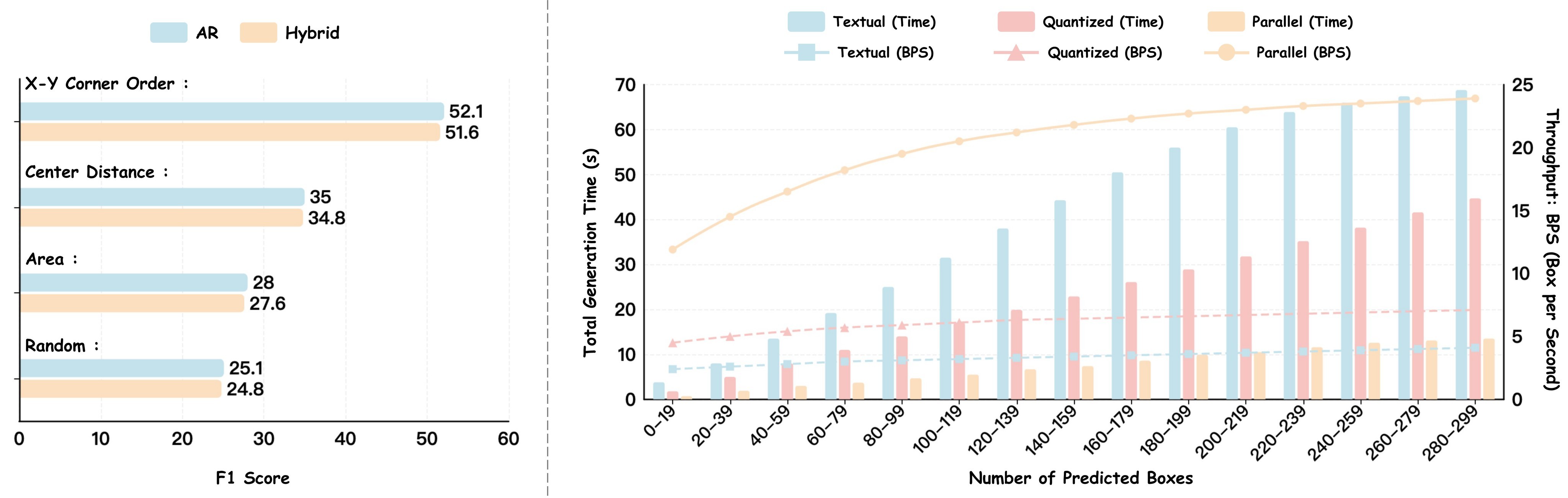
The paper also reports that X-Y corner order is the best output sorting strategy. That matters because the block decoder is still autoregressive across blocks, so a stable object ordering reduces duplicate and missing-box errors.
Decoding Mode Trade-Off
The supplementary mode table clarifies why Hybrid is the default.
| Task group / metric | Fast 15.3 BPS | Hybrid 12.7 BPS | Slow 4.3 BPS |
|---|---|---|---|
| COCO F1@mIoU | 52.2 | 54.7 | 55.1 |
| LVIS F1@mIoU | 47.0 | 50.7 | 52.6 |
| Dense200 F1@mIoU | 46.8 | 61.3 | 61.5 |
| VisDrone F1@mIoU | 34.4 | 39.8 | 40.2 |
| DocLayNet F1@mIoU | 67.2 | 77.7 | 80.4 |
| M6Doc F1@mIoU | 64.1 | 70.5 | 69.7 |
| ScreenSpot-Pro Acc | 59.7 | 60.3 | 60.5 |
| HumanRef F1@mIoU | 66.8 | 78.5 | 79.1 |
| RefCOCOg test F1@mIoU | 72.5 | 74.8 | 73.8 |
| COCO F1@Point | 83.1 | 83.9 | 84.8 |
Table 7. Fast, Hybrid, and Slow modes. Fast is the throughput extreme, Slow is usually the accuracy upper bound, and Hybrid is the practical middle. Dense200 is especially revealing: Hybrid nearly matches Slow while far exceeding Fast.
Pointing And Backbone Generalization
For point-based localization, the paper reports Hybrid-mode LocateAnything-3B at 83.9 F1@Point on COCO, 87.6 on Dense200, 84.7 on HumanRef, and 91.0 on RefCOCOg test. This is useful evidence that the block formulation is not restricted to boxes, though the digest should treat these as supplementary results because the main contribution is box decoding.
| Backbone | Decoding | F1 | BPS |
|---|---|---|---|
| Qwen3-VL-4B | NTP baseline | 50.8 | 2.8 |
| Qwen3-VL-4B | PBD Slow | 52.2 | 2.8 |
| Qwen3-VL-4B | PBD Fast | 49.6 | 11.4 |
| Qwen3-VL-4B | PBD Hybrid | 52.0 | 9.4 |
Table 8. Backbone generalization. This controlled result supports the claim that PBD is a decoding/formulation improvement rather than only a property of the LocateAnything-3B backbone.
Qualitative Results
Figure 11 shows the paper's main qualitative examples across attribute, part, reasoning, and spatial queries.

Figure 12 compares referring-expression grounding against Qwen3-VL and Rex-Omni.
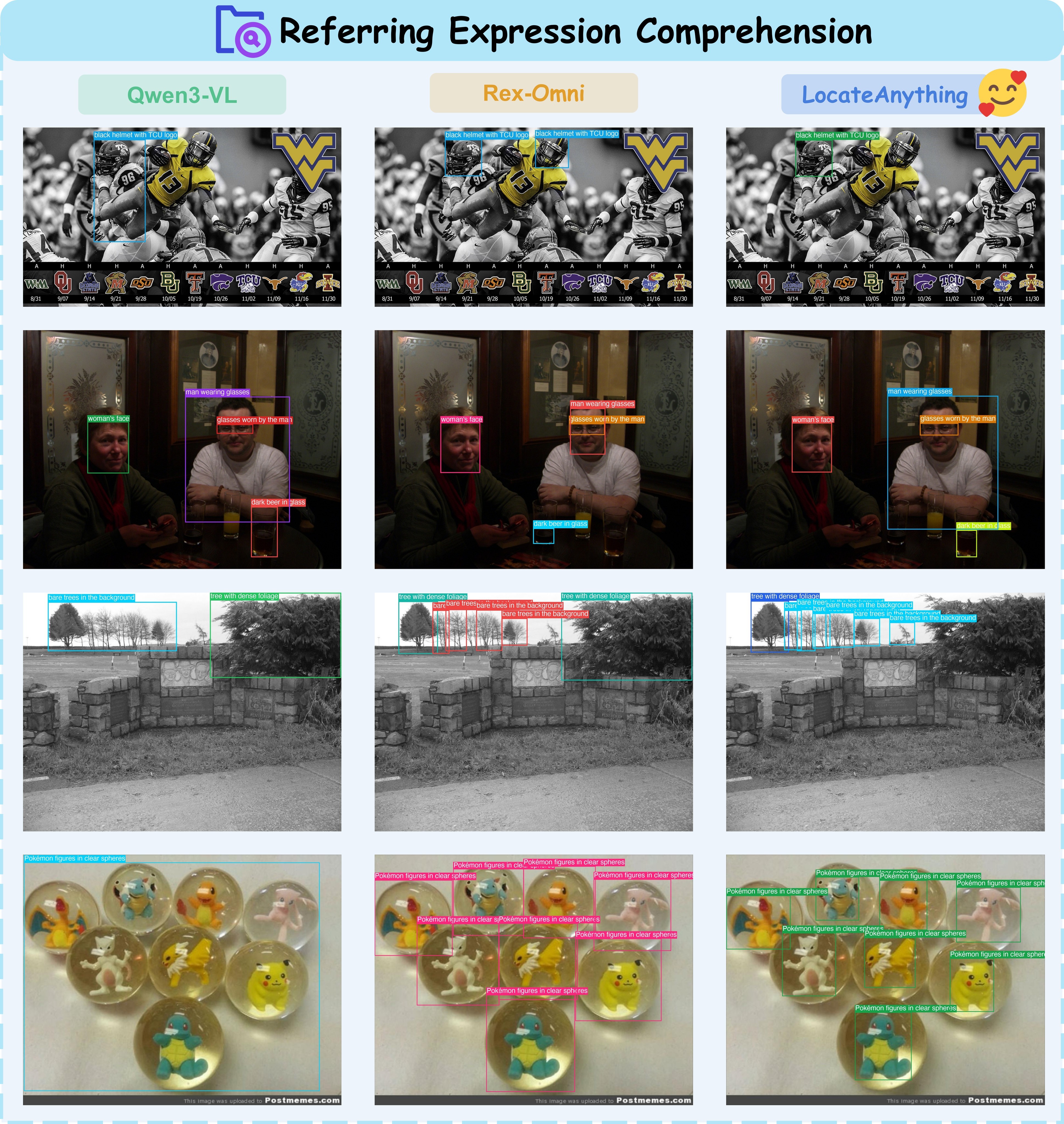
Figure 13 focuses on dense object detection.

Figure 14 shows OCR and document-style layouts.

Practical Takeaways
1. Use box-aligned units when geometry is the output. The paper's strongest contribution is not just parallelization; it is aligning the prediction unit with the spatial structure of the target.
2. Hybrid decoding is the practical default. Pure Fast mode is attractive for latency, but the paper's own results show that dense and ambiguous scenes need fallback. Hybrid mode keeps much of the speed while recovering most of Slow-mode accuracy.
3. Negative samples are a core part of the output grammar. The Negative block is only useful because the dataset includes absent-object queries. Without those examples, a generative detector can learn to hallucinate boxes.
4. The speed metric is compelling but hardware-specific. Throughput is reported as BPS on a single H100 with batch size 1. The qualitative conclusion should transfer, but the exact numbers should be remeasured for deployment hardware.
5. The broad benchmark suite matters. LocateAnything is not uniformly best on every single benchmark, especially against specialized detectors or some classic REC baselines. Its value proposition is the combined throughput, unified interface, and strong region-level performance across many task families.
6. The data engine is doing substantial work. PBD is supported by controlled COCO ablations, but the full model's open-world capability also depends on 138M+ query supervision, synthetic query/box generation, post-verification, and dense-scene Stage-2 tuning.
Reference Coverage
Figure links: Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13, and Figure 14.
Table links: claims, dataset statistics, prompt design, LVIS/COCO, dense detection, open-world localization, ablation, mode summary, and backbone generalization.
Evidence links: problem setup, decoding comparison, key formulas, block formulation, training mask, hybrid fallback, dataset scale, data engine, main results, speed, ablation, mode summary, pointing, backbone generalization, qualitative overview, and qualitative comparisons.