Source-first digest for monthly 2026_05 rank 20, rank_id p026.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
The paper targets autoregressive streaming video diffusion, where a causal student must generate long videos efficiently from a much more expensive teacher. Distribution matching distillation (DMD) is the base acceleration strategy, but the authors argue that standard DMD treats every rollout, frame, and pixel as equally useful supervision. Their core diagnosis has two parts: Inter-Reliability, where different student rollouts give DMD gradients of uneven trustworthiness, and Intra-Perplexity, where different regions and frames within one rollout still have different amounts of improvable quality. The problem statement is visualized in Figure 1.
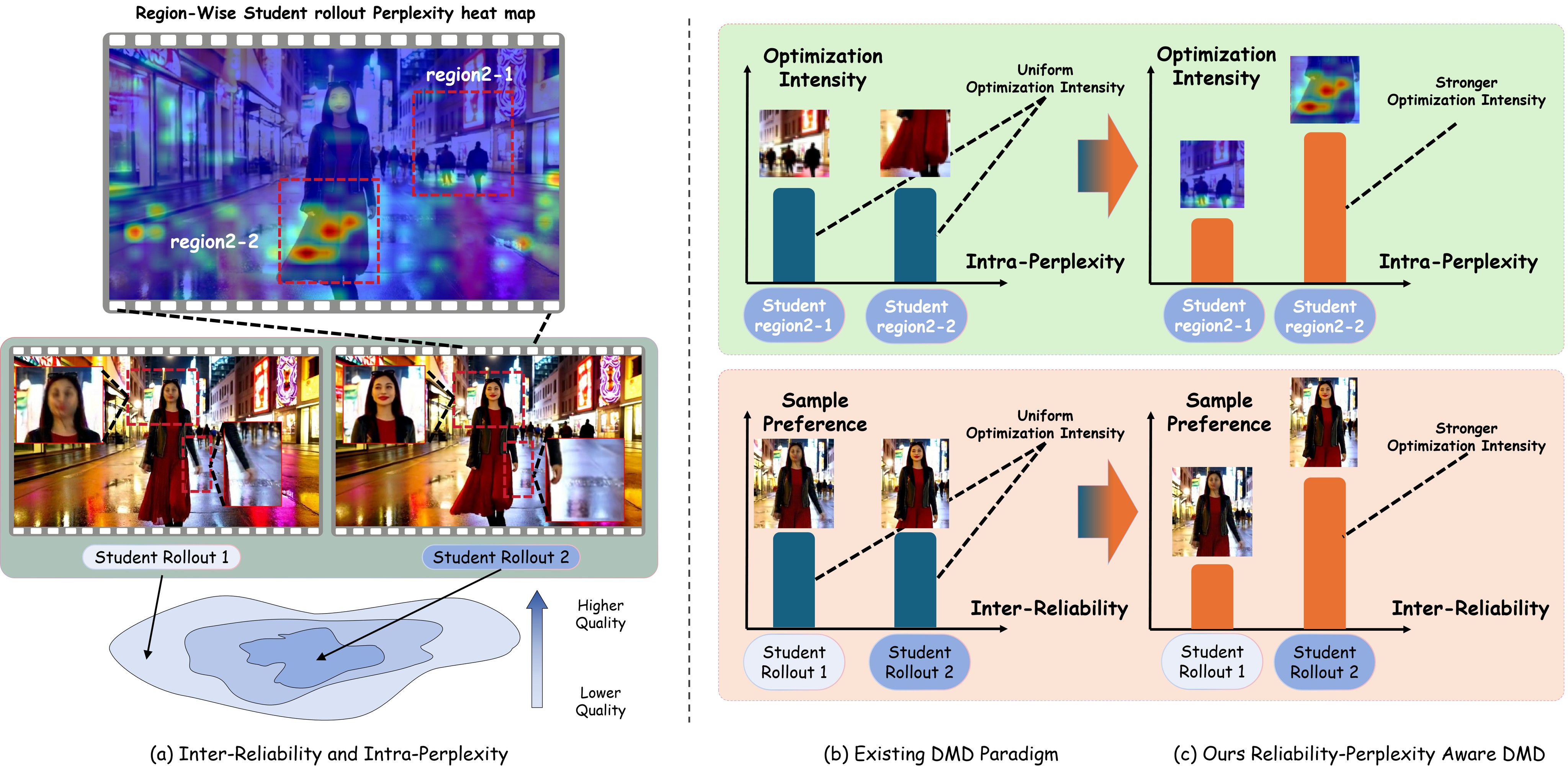
Stream-R1 is the authors' answer: use one pretrained video reward model twice, first as a scalar rollout reliability signal and second as a gradient-saliency source for spatial and temporal weighting. The intended advantage is practical rather than architectural: it changes the training loss, keeps the student architecture unchanged, and adds no inference-time cost. The central claim is summarized in Table 1.
Claims And Evidence
Support scores are support-from-paper scores, not independent reproduction scores. A score of 5 means the claim is directly supported by paper equations, tables, figures, or ablations. A score of 4 means the paper reports direct evidence, but the claim still depends on the authors' benchmark, reward model, or evaluation setup. A score of 3 means the paper provides plausible support, but the evidence is mostly qualitative or diagnostic.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Uniform DMD is a poor fit for streaming video distillation because rollout-level reliability and within-rollout saliency vary substantially. | 5 | problem framing, contribution, Figure 1 |
| C2 | Stream-R1 operationalizes this diagnosis as two reward-guided weights: an Inter-Reliability scalar and an Intra-Perplexity spatiotemporal map. | 5 | method overview, key equations, Figure 2, method map |
| C3 | The method is a training-objective change rather than an inference architecture change, so the reported speed is inherited from the distilled streaming student. | 4 | implementation details, Table 3, short-video results |
| C4 | On short 5-second VBench evaluation, Stream-R1 reports the best total and semantic scores among compared methods and improves over Reward Forcing. | 4 | short-video results, Table 4 |
| C5 | On long-video evaluation, the paper reports stronger quality retention than Reward Forcing across automated, VLM, human-preference, and qualitative evidence. | 4 | long-video results, VLM and human evidence, Figure 3, Figure 4, Table 5, Table 6 |
| C6 | The ablation supports the claim that temporal decomposition is a major contributor, while the spatial and balanced reward terms provide smaller gains. | 4 | ablation evidence, Table 7 |
| C7 | The saliency visualization is consistent with the intended mechanism, but it is a controlled diagnostic rather than a full causal proof. | 3 | saliency visualization, Figure 5 |
Core Technical Idea
The paper's technical move is to split reward-guided distillation into a whether-to-learn decision and a where-to-learn decision. The first decision weights whole rollouts, while the second weights spatiotemporal elements within a rollout. Figure 2 shows the full path from the fake rollout to the DMD loss, reward score, reward gradients, and final weighted objective.
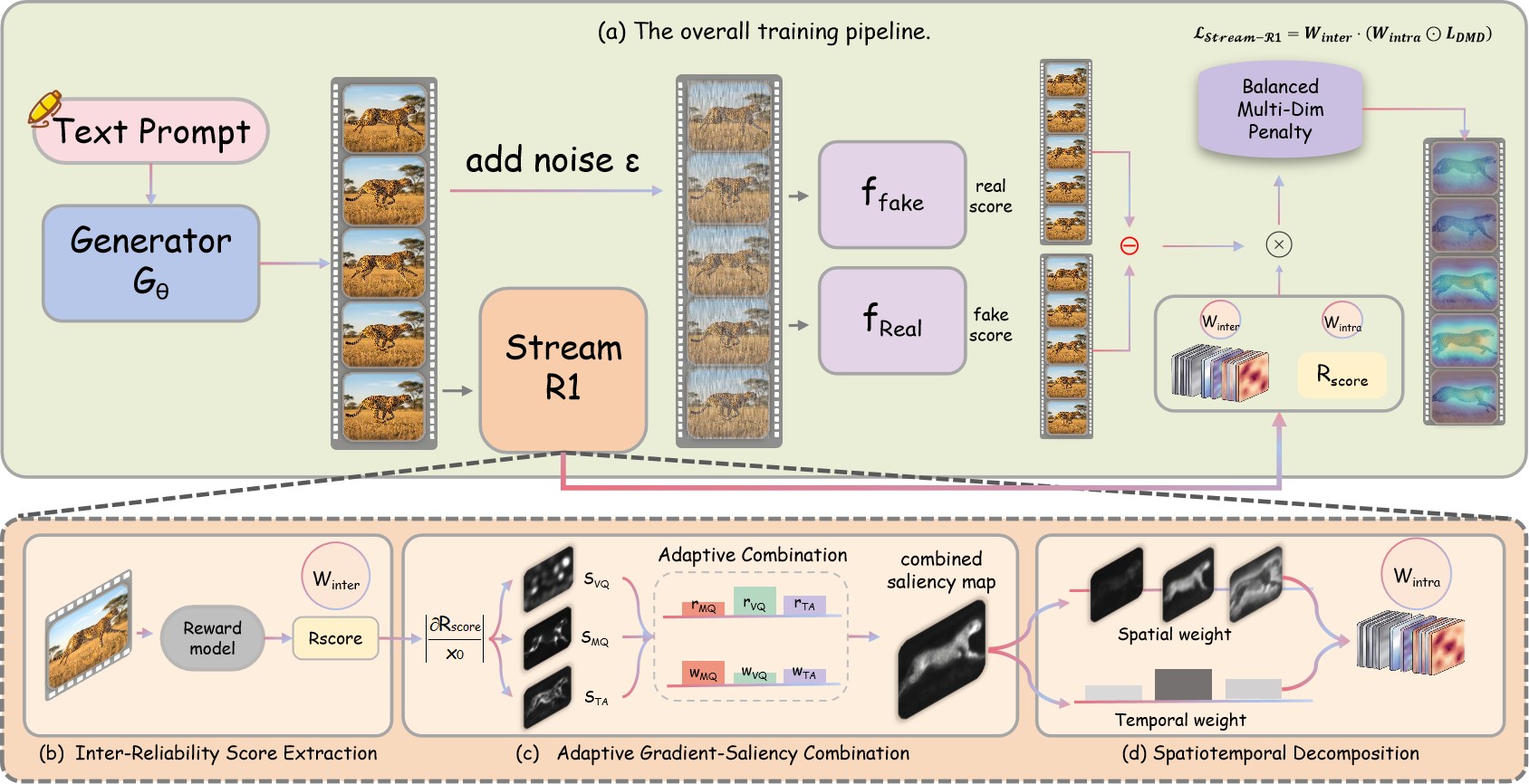
The baseline DMD gradient is the difference between fake and real score estimates:
The base DMD loss supervises the clean latent against a stop-gradient target built from the normalized gradient:
Stream-R1 adds a rollout-level weight from the balanced final reward:
For intra-rollout weighting, it back-propagates each reward dimension \(d \in \{\text{VQ}, \text{MQ}, \text{TA}\}\) to pixels:
Per-dimension saliency maps are combined with larger weight on currently weaker reward dimensions:
The combined saliency is factored into temporal and spatial weights. The final intra-rollout map is:
The balanced reward subtracts a penalty when improvement across quality dimensions diverges:
The full training loss is the DMD loss with both weights:
The design decomposition is summarized in Table 2.
| Component | Level | Signal source | What it changes | Digest reading | ||
|---|---|---|---|---|---|---|
| Base DMD | Rollout latent | \(f_{\text{fake}} - f_{\text{real}}\) | Student matches teacher distribution with a stop-gradient target | Strong baseline, but uniformly weights all elements. | ||
| Inter-Reliability | Sample / rollout | Balanced reward \(r_{\text{final}}\) | Multiplies the rollout loss by \(\exp(\beta r_{\text{final}})\) | High-reward rollouts are treated as more reliable DMD supervision. | ||
| Gradient saliency | Pixel and frame | \( | \partial R_d(\mathbf{V})/\partial \mathbf{V} | \) | Extracts local reward sensitivity | Reward is no longer only a scalar preference score. |
| Adaptive fusion | Quality dimension | VQ, MQ, TA scores | Emphasizes lower-scoring dimensions through softmax weights | The method tries to avoid optimizing only the easiest axis. | ||
| Spatiotemporal decomposition | Frame and pixel | Combined saliency volume | Builds \(W_{\text{intra}}\) from temporal and spatial weights | The training signal focuses on frames and regions with more remaining quality deficiency. | ||
| Final objective | Whole loss | \(W_{\text{inter}}\) and \(W_{\text{intra}}\) | Reweights DMD without changing inference architecture | Training is more expensive, but inference is unchanged. |
Method Details
The implementation uses Reward Forcing as the training framework, with Wan2.1-T2V-1.3B as student and Wan2.1-T2V-14B as teacher. Training videos are 5 seconds at \(832 \times 480\), generated chunk-wise with 3 latent frames per chunk and denoising steps \([1000, 750, 500, 250]\). The reward axes are visual quality, motion quality, and text alignment. The implementation settings are listed in Table 3.
| Setting | Value reported in source |
|---|---|
| Student | Wan2.1-T2V-1.3B |
| Teacher | Wan2.1-T2V-14B |
| Base framework | Reward Forcing, initialized from an ODE regression checkpoint |
| Training prompts | Filtered VidProM with LLM-based prompt rewriting |
| Resolution and duration | 5-second videos at \(832 \times 480\) |
| Chunking | 3 latent frames per chunk, attention window size 9 |
| Stream-R1 saliency | Pixel-level gradients for VQ, MQ, and TA |
| Adaptive saliency temperature | \(\tau = 1.0\) |
| Weight floors | \(\sigma_{\min}=0.15\), \(\tau_{\min}=0.20\) |
| Inter-reliability inverse temperature | \(\beta = 2.0\) |
| Optimization | 1,000 steps on 8 A100 GPUs, effective batch size 64 |
| Generator / fake-score learning rates | \(2.0 \times 10^{-6}\) / \(4.0 \times 10^{-7}\) |
| EMA | decay 0.99 starting from step 200 |
| Training time | approximately 56 hours |
The method has one important tradeoff. It claims no additional inference cost because the generated student model is unchanged, but training adds reward-model scoring and reward-gradient backpropagation. The paper says this overhead is negligible relative to diffusion-model forward and backward passes, but the source does not provide a separate wall-clock ablation for the reward-gradient module.
Experiments And Results
For short-video evaluation, the paper generates 5-second videos for 946 VBench prompts, rewritten with Qwen2.5-7B-Instruct and sampled with 5 seeds. Table 4 is the headline result: Stream-R1 reports Total 84.40, Quality 85.14, and Semantic 81.44. Relative to Reward Forcing, this is +0.27 Total, +0.30 Quality, and +0.12 Semantic at the same reported FPS. Relative to the Wan2.1 teacher, it has lower Quality but higher Total and Semantic while running much faster.
| Model | Params | FPS | Total | Quality | Semantic |
|---|---|---|---|---|---|
| LTX-Video | 1.9B | 8.98 | 80.00 | 82.30 | 70.79 |
| Wan2.1 | 1.3B | 0.78 | 84.26 | 85.30 | 80.09 |
| SkyReels-V2 | 1.3B | 0.49 | 82.67 | 84.70 | 74.53 |
| MAGI-1 | 4.5B | 0.19 | 79.18 | 82.04 | 67.74 |
| NOVA | 0.6B | 0.88 | 80.12 | 80.39 | 79.05 |
| Pyramid Flow | 2B | 6.70 | 81.72 | 84.74 | 69.62 |
| CausVid | 1.3B | 17.00 | 82.88 | 83.93 | 78.69 |
| Self Forcing | 1.3B | 17.00 | 83.80 | 84.59 | 80.64 |
| LongLive | 1.3B | 20.70 | 83.22 | 83.68 | 81.37 |
| Rolling Forcing | 1.3B | 17.50 | 81.22 | 84.08 | 69.78 |
| Reward Forcing | 1.3B | 23.10 | 84.13 | 84.84 | 81.32 |
| Stream-R1 | 1.3B | 23.10 | 84.40 | 85.14 | 81.44 |
For long-video evaluation, the paper follows Reward Forcing and generates 10s, 30s, 60s, 120s, and 180s videos from the first 128 MovieGen Video Bench prompts. Figure 3 reports that Stream-R1 stays above Reward Forcing across six VBench metrics at all durations, with the gap widening at 120s and 180s. The paper interprets this as evidence that temporal weighting slows quality drift in autoregressive rollouts.
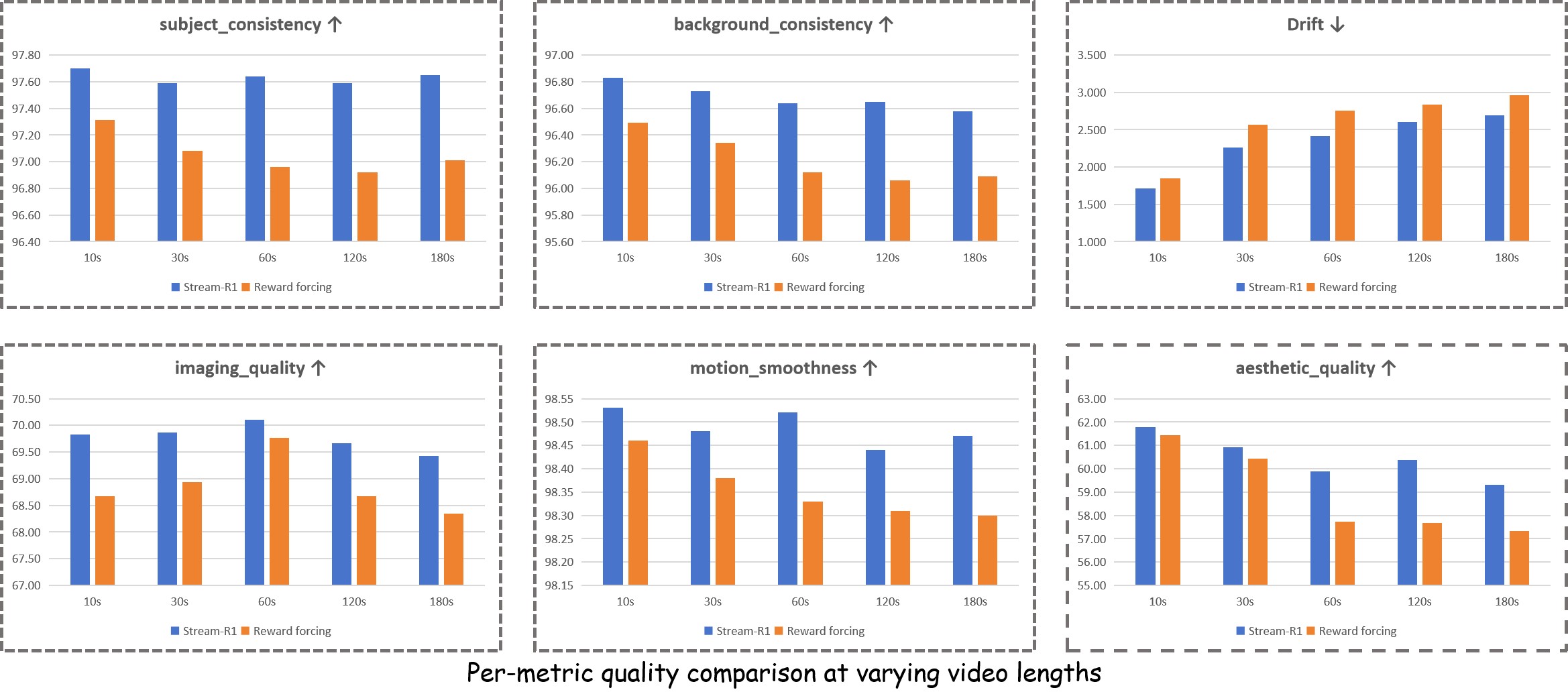

The paper adds two preference-style evaluations. First, Qwen3-VL-235B-A22B-Instruct scores 128 60-second videos from 1 to 5 on visual quality, motion dynamics, and text alignment; Table 5 reports Stream-R1 as best on Visual and Text but second on Dynamic. Second, five annotators compare 50 anonymized 60-second A/B pairs; Table 6 reports Stream-R1 preferred on all five dimensions, with the strongest margins on dynamic reasonableness and visual quality.
| Model | Visual | Dynamic | Text |
|---|---|---|---|
| SkyReels-V2 | 3.30 | 3.05 | 2.70 |
| CausVid | 4.66 | 3.16 | 3.32 |
| Self Forcing | 3.89 | 3.44 | 3.11 |
| LongLive | 4.79 | 3.81 | 3.98 |
| Reward Forcing | 4.82 | 4.18 | 4.04 |
| Stream-R1 | 4.92 | 4.04 | 4.11 |
| Dimension | Win | Tie | Lose | Win rate |
|---|---|---|---|---|
| Temporal Consistency | 25 | 1 | 24 | 51.0% |
| Dynamic Reasonableness | 30 | 3 | 17 | 63.0% |
| Visual Quality and Aesthetics | 29 | 2 | 19 | 60.0% |
| Text-Video Alignment | 22 | 9 | 18 | 54.1% |
| Overall Preference | 28 | 1 | 21 | 57.0% |
The ablation in Table 7 is the strongest internal evidence for the paper's component-level story. Spatial reward improves short Quality and long Total over the baseline. Balanced multi-dimensional reward gives a small semantic improvement in the sensitivity row. The largest step is adding temporal reward with \(\tau_{\min}=0.20\), which raises short Total to 84.40 and lowers long-video drift to 2.417. A higher temporal floor, \(\tau_{\min}=0.40\), degrades short Total to 83.42, supporting the authors' claim that preserving temporal contrast matters.
| Variant | Short Total | Short Quality | Short Semantic | Long Total | Drift |
|---|---|---|---|---|---|
| Baseline | 83.44 | 84.16 | 80.55 | 79.45 | 2.479 |
| + Spatial reward, \(\sigma_{\min}=0.15\) | 83.67 | 84.46 | 80.51 | 80.71 | 2.653 |
| + Balanced Multi-Dim reward, \(\sigma_{\min}=0.15\) | 83.67 | 84.45 | 80.54 | 80.72 | 2.651 |
| + Temporal reward, \(\tau_{\min}=0.20\) [Full] | 84.40 | 85.14 | 81.44 | 80.86 | 2.417 |
| \(\sigma_{\min}=0.30\), spatial only | 83.68 | 84.44 | 80.62 | 80.73 | 2.697 |
| \(\tau_{\min}=0.40\) | 83.42 | 84.21 | 80.24 | 80.40 | 2.475 |
The controlled saliency visualization in Figure 5 injects Gaussian blur into the lower half of frames and expands the corrupted region across time. The resulting reward-gradient saliency concentrates on degraded regions and temporal weights rise from 0.587 to 2.117 as the corrupted area grows. This is good mechanism-facing evidence that \(W_{\text{intra}}\) reacts to visible quality defects, but it does not by itself prove the full training improvement.

Practical Takeaways
Table 8 summarizes how I would read the paper operationally. The result is most useful for researchers already training distilled streaming video generators, because the method assumes access to DMD training, a reward model with differentiable video inputs, and enough compute for reward-gradient training. It is less immediately useful as an inference-time deployment trick because the gains come from training-time supervision design.
| Takeaway | Why it matters |
|---|---|
| The reward model is used as a localizer, not only a ranker. | Reward gradients become a spatial and temporal training signal, which is the main novelty beyond scalar Reward Forcing. |
| The method fits distillation pipelines that already have DMD machinery. | Stream-R1 modifies the loss around \(f_{\text{fake}}\), \(f_{\text{real}}\), and generated rollouts; it is not a plug-in sampler for arbitrary video models. |
| The strongest evidence is relative to Reward Forcing. | The most controlled comparison is the same speed and same base student, with better short and long quality metrics. |
| Long-video gains are more compelling than short-video gains. | Short VBench improvements are modest; long-horizon curves, VLM scores, human preference, and drift results better match the paper's motivation. |
| Reward-model dependence is a central risk. | If the reward model's gradients emphasize the wrong regions, the method can steer optimization toward reward artifacts. The paper mitigates this with multi-dimensional balancing but does not remove the dependency. |
| Training cost is not free. | The method claims zero inference overhead, but the reported run still uses 8 A100 GPUs for about 56 hours and adds reward-gradient computation during training. |
The clean bottom line: Stream-R1 is a targeted reward-distillation paper, not a new video architecture. Its strongest contribution is showing that scalar reward feedback can be decomposed into rollout-level reliability and within-rollout spatiotemporal saliency, and that this decomposition helps long streaming videos resist accumulated quality drift.
Reference Coverage
All explicit anchors in this digest are linked here for validation coverage: problem, contribution, method overview, key equations, implementation, short results, long results, VLM and human evidence, ablation, saliency visualization, practical takeaways, Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Table 1, Table 2, Table 3, Table 4, Table 5, Table 6, Table 7, and Table 8.