Source-first digest for monthly 2026_05 rank 8, rank_id p027.
- Routing status:
success - PDF extraction: not used
Motivation / Background
The paper argues that current Vision-Language-Action models are strong at scene understanding and language-conditioned generalization, but still miss capabilities needed for difficult robot work: motion awareness, long-term memory, and physical sensing. RLDX-1 is positioned as a full deployment stack, not just a new policy head: it combines a temporally aware VLM, a multi-stream flow-matching action model, synthetic data for rare dexterous scenarios, staged training, RL refinement, and latency-oriented inference optimization.
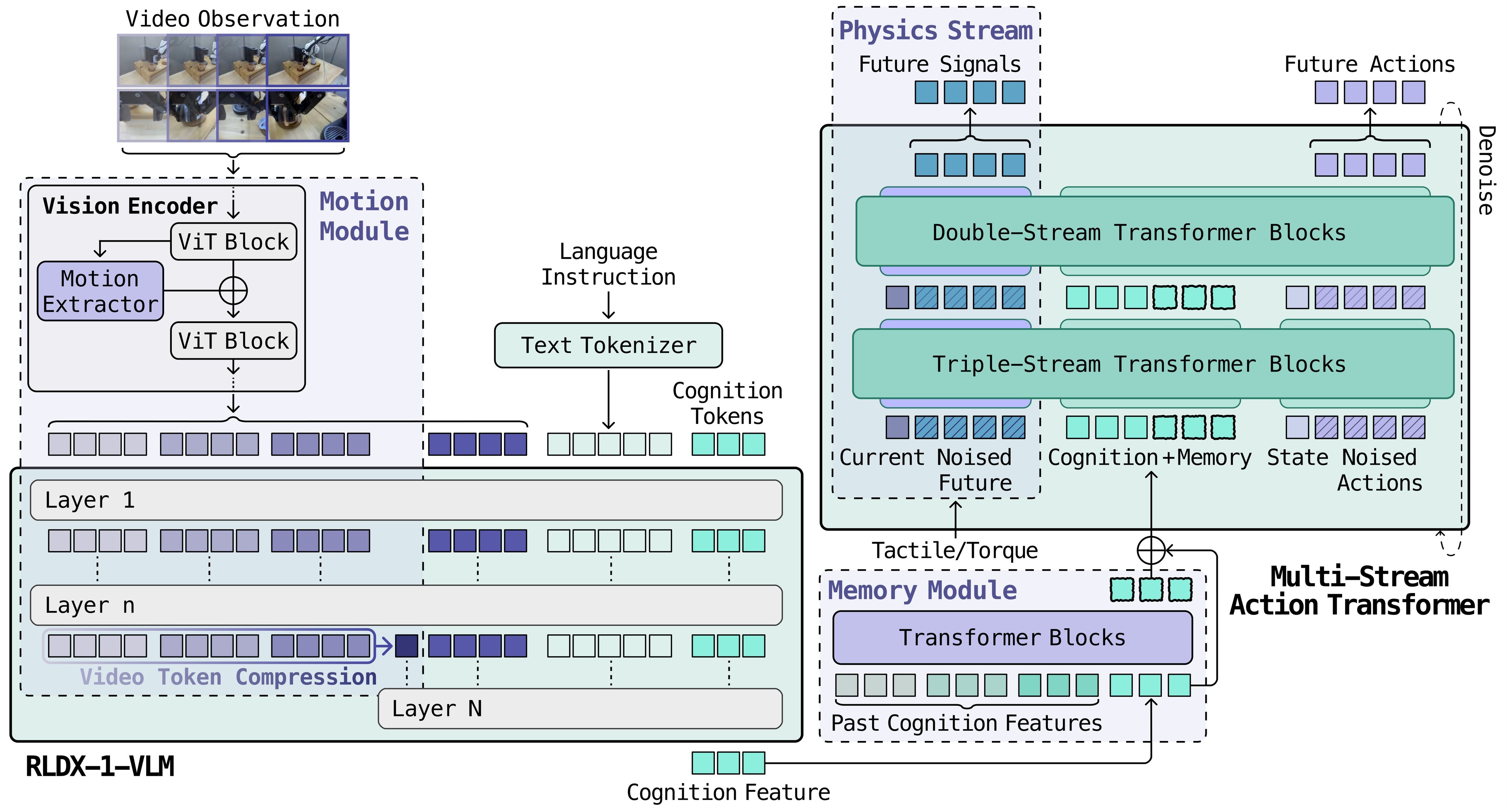
The target setting is broad: single-arm grippers, dual-arm systems, and humanoids with dexterous hands. The core test is whether a policy can handle tasks where a static image and instruction are not enough, such as moving conveyors, hidden-object memory, tactile plug insertion, fragile egg grasping, and torque-based pouring. The architecture overview in Figure 1 is the best single view of that design.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | RLDX-1's main contribution is a system-level answer to VLA failure modes that require temporal dynamics, history, and physical feedback, not only better visual-language grounding. | 5 | problem framing, architecture and MSAT, real-world results |
| C2 | The Multi-Stream Action Transformer is a plausible architecture for heterogeneous robot inputs because it keeps modality-specific streams while allowing joint self-attention and flow-matching action generation. | 5 | architecture and MSAT, flow equations, functional modules |
| C3 | Synthetic robot video plus IDM action annotation and filtering is useful in this paper's setting, especially for rare humanoid manipulation cases. | 4 | data and training, synthetic pipeline, ablation and post-training |
| C4 | The three-stage training recipe is central: broad multi-embodiment pre-training, embodiment-specific mid-training for new modalities, and task-specific post-training/RL. | 4 | data and training, training stages, ablation and post-training |
| C5 | The reported experiments show RLDX-1 outperforming recent frontier VLAs across simulation, humanoid, and FR3 real-robot tasks. | 5 | simulation results, simulation table, real-world results, real-world table |
| C6 | The inference stack materially reduces latency for real-time robot deployment, reaching 43.7 ms for the all-modality model on the reported desktop setup. | 5 | inference optimization, latency table |
| C7 | The RL and test-time sampling sections support a narrower claim: post-training and critic-guided sampling can help difficult dexterous tasks, but the strongest evidence is task-specific and sampling can hurt converged policies. | 4 | ablation and post-training, BoN figure, practical caveats |
Support scores are support-from-paper scores, not independent reproduction scores. A score of 5 means the paper directly backs the claim with architecture definitions, equations, tables, or experiments; a score of 4 means the evidence is substantial but still depends on internal evaluations, selected tasks, or system-specific implementation choices.
Core Technical Idea
RLDX-1 keeps a familiar VLA skeleton but adds explicit machinery for functions that normal image-conditioned policies often miss. The VLM is based on Qwen3-VL 8B and is adapted with robot VQA data. It outputs cognition tokens: 64 learned query tokens that attend to video and language and then pass action-relevant state to the action model.
The three functional additions are summarized in Table 1. Motion awareness uses multi-frame observations plus a space-time self-similarity module in the vision encoder, inserted after the 9th layer. Long-term memory keeps a queue of the last \(n_\text{mem}=3\) cognition features, sampled at action-chunk intervals, and runs them through a causal Transformer. Physical sensing adds a physics stream for torque and tactile signals, with future physical-signal prediction as auxiliary training.
| Capability | RLDX-1 mechanism | Practical role |
|---|---|---|
| Motion awareness | Multi-frame video, STSS motion module, and temporal token compression after early LLM layers | Track dynamic scenes such as conveyors and Pong-like motion |
| Long-term memory | Queue of prior cognition features plus a lightweight causal Transformer | Remember hidden or previously observed state, such as which box contains an object |
| Physical sensing | Separate physics stream for torque/tactile inputs plus future physical-signal prediction | Handle occluded contact and force-sensitive tasks such as plug insertion, card sliding, and pouring |
Table 1. Functional modules. This table condenses the architecture sections of the source paper into the three functions the authors evaluate later in ALLEX and FR3 experiments.
The action model is the Multi-Stream Action Transformer. MSAT starts from a flow-matching DiT action model but separates cognition, action/proprioception, and physical signals into streams. In early blocks, streams keep their own normalization and QKV projections; queries, keys, and values are concatenated for joint self-attention and then split back. This gives each modality its own representation while still allowing cross-modal action generation.
The source paper's two explicit display equations define the action chunk denoising objective and Euler integration. Normalized into standard notation, the training loss is:
At inference time, action chunks are generated over denoising timesteps by:
Here \(c_t\) includes the current cognition features, memory features, proprioceptive state, and physical signals when available. The physics stream uses an analogous flow-matching objective for future torque/tactile trajectories, encouraging the model to internalize interaction dynamics rather than treating physical feedback as an unused side channel.
Method Details
RLDX-1 uses a mix of public, in-house, and synthetic robot data. Public data gives a broad prior: Open-X-Embodiment, DROID, Galaxea Open-World, Agibot World, Fourier ActionNet, and Humanoid Everyday. In-house data supplies what public data lacks: ALLEX humanoid torque feedback and FR3 tactile/torque sensing. Synthetic data fills rare humanoid and dexterous scenarios that would be expensive to collect directly.
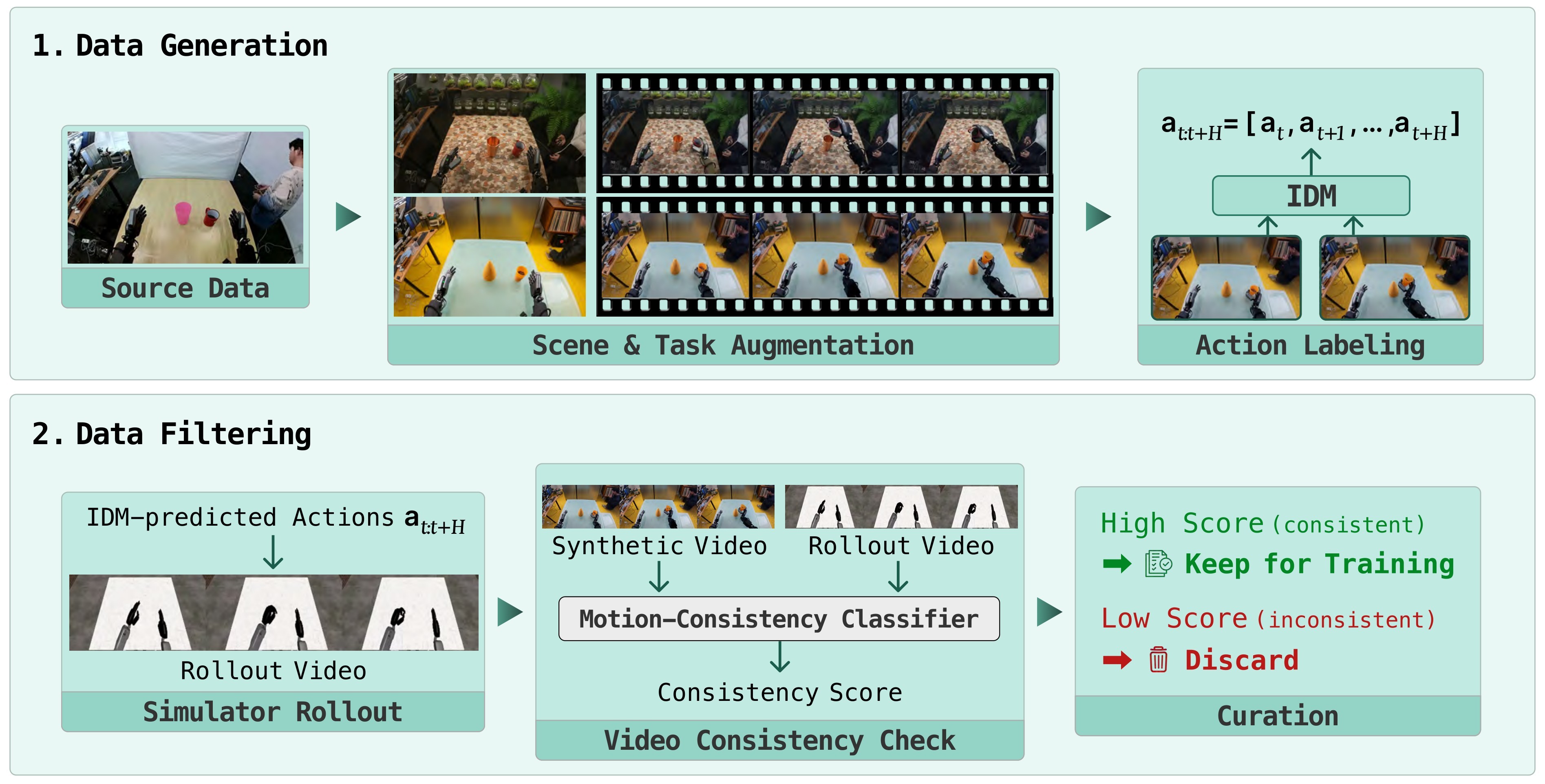
Figure 2 shows the synthetic-data pipeline. A source demonstration is diversified by task augmentation and scene augmentation, an inverse dynamics model labels the generated video with actions, and two filters reject bad samples: video-quality filtering for instruction/plausibility failures and motion-consistency filtering for action/video mismatch.
The staged training recipe in Table 2 is important because each stage introduces a different capability and data source.
| Stage | Data and scale | Main purpose | Training details reported |
|---|---|---|---|
| Pre-training | Multi-embodiment public data plus 150K synthetic GR-1 humanoid episodes | Learn broad action priors and temporal manipulation behavior | 100K steps, global batch 8192, AdamW at \(1\times10^{-4}\), about 195 hours on 64 H200 GPUs |
| Mid-training | ALLEX in-house + 72K synthetic episodes at 5:5 sampling; FR3 DROID + in-house at 8:2 sampling | Specialize to target embodiments and add motion, memory, torque, and tactile modalities | 25K steps, batch 1024, AdamW at \(5\times10^{-5}\), 2K-step alignment warmup |
| Post-training | Task-specific demonstrations, adaptive data collection, and optional RECAP-style RL | Improve final deployment tasks and repair observed failure modes | Usually 30K steps per real task; RL trains a text-based VLM critic and then advantage-conditioned policy updates |
Table 2. Training stages. The authors present RLDX-1 as a progressively specialized policy: broad priors first, modality expansion second, task deployment third.
The inference section treats latency as a robotics problem: if inference is slow, the scene changes between observation and execution. The optimization stack has two layers. Static graph conversion precomputes configuration-dependent masks and rotary embeddings so the forward pass can be captured as one CUDA Graph. Custom kernels then fuse memory-bound operations around short-prefill attention blocks to reduce global-memory round trips. The reported latency numbers are summarized in Table 3.
| Inference stack | Without physics/memory | All-modality model |
|---|---|---|
| PyTorch Eager | 67.0 ms | 71.2 ms |
| CUDA Graph + Torch Compile | 56.9 ms, 1.18x | 59.6 ms, 1.19x |
| + Static Graph Conversion | 46.2 ms, 1.45x | 48.9 ms, 1.46x |
| + Kernel Optimization | 41.6 ms, 1.61x | 43.7 ms, 1.63x |
Table 3. Inference latency. Measurements use the paper's ALLEX setup on RTX 5090, with dual-view 192 by 256 images, 4 frames, action horizon 40, and 4 Euler denoising steps.
Experiments And Results
The simulation suite tests broad VLA competence after fine-tuning: LIBERO, LIBERO-Plus, SIMPLER, RoboCasa Kitchen, GR-1 Tabletop, and RoboCasa365. Table 4 extracts the headline comparisons. The paper emphasizes that GR00T N1.6 is pre-trained with RoboCasa simulation data, while RLDX-1 reports stronger RoboCasa365 performance without simulation data during pre-training.
| Benchmark slice | RLDX-1 | Strong comparison in source table | Readout |
|---|---|---|---|
| LIBERO Avg. | 97.8 | \(\pi_{0.5}\): 96.9, GR00T N1.6: 96.7 | Small but consistent top score |
| LIBERO-Plus | 86.7 | \(\pi_{0.5}\): 86.5, GR00T N1.6: 72.6 | Robustness shift favors RLDX-1 over GR00T |
| SIMPLER Google-VA | 77.4 | \(\pi_{0.5}\): 68.4, GR00T N1.6: 57.1 | Stronger visual-variation transfer |
| SIMPLER WidowX | 71.9 | GR00T N1.5: 62.0, GR00T N1.6: 57.1 | Better third-person single-arm transfer |
| RoboCasa Kitchen | 70.6 | GR00T N1.6: 66.2 | Moderate gain on kitchen manipulation |
| GR-1 Tabletop | 58.7 | GR00T N1.5: 48.0, GR00T N1.6: 47.6 | Large humanoid simulation gain |
| RoboCasa365 Avg. | 32.1 | GR00T N1.6: 26.9 | Best on long-horizon household tasks |
Table 4. Simulation headline results. Values are success rates or average scores as reported in the source tables.
The real-world results are more central to the paper's claim because they align directly with the three functional modules. On OpenArm, RLDX-1 improves basic and instruction-following humanoid pick-and-place, including 54.2% on *Unseen Object* versus 37.5% for \(\pi_{0.5}\), and 87.5% on *Object Grounding* versus 33.3% for GR00T N1.6. On ALLEX and FR3, the tasks are explicitly grouped around motion, memory, and physical sensing. The ALLEX results in Figure 3 and FR3 results in Figure 4 are the paper's clearest evidence for those capabilities.
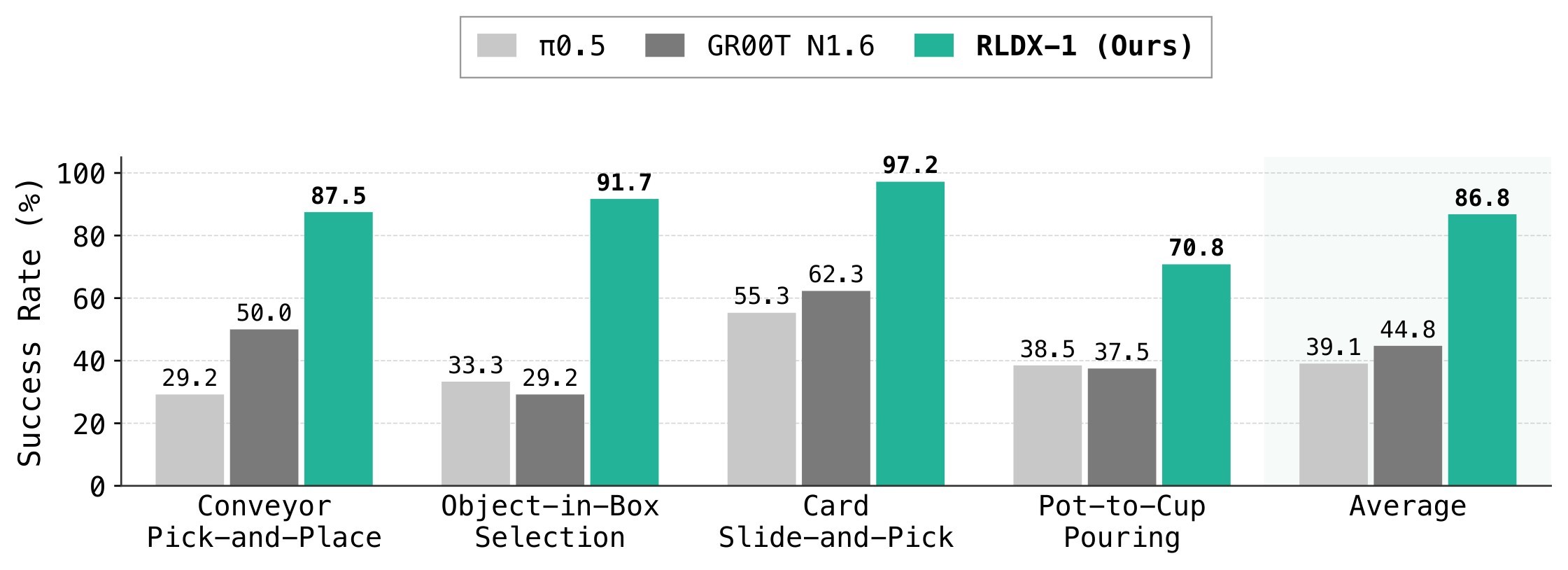
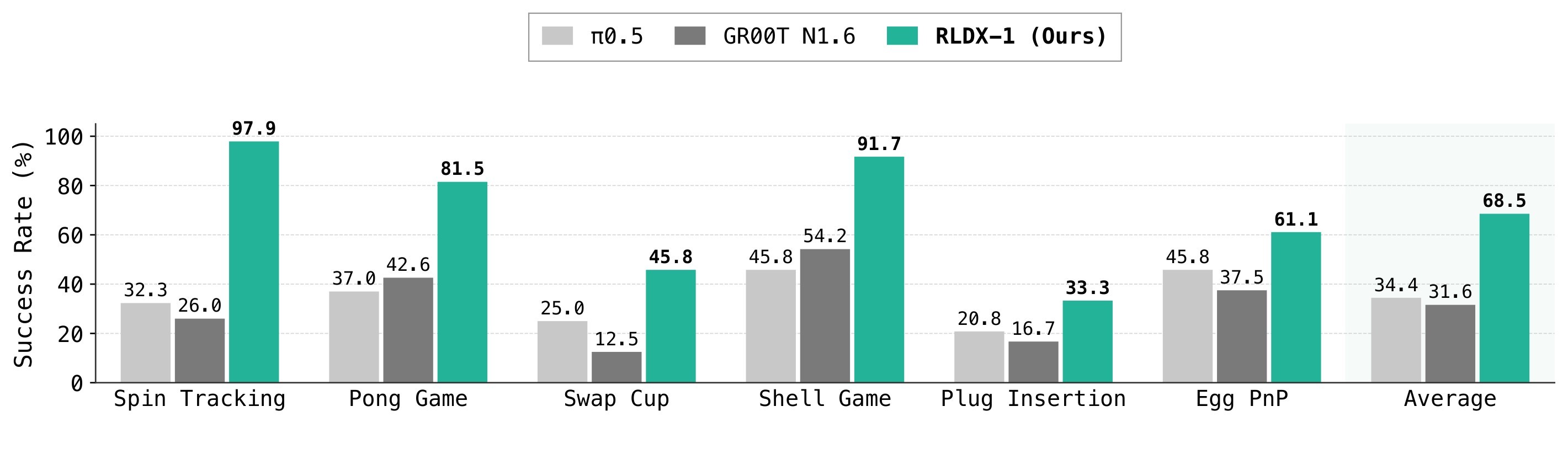
| Platform / capability | Task | RLDX-1 reported result | Baseline comparison |
|---|---|---|---|
| OpenArm / versatility | Basic Pick-and-Place | 50.0% | \(\pi_{0.5}\): 41.7%, GR00T N1.6: 37.5% |
| OpenArm / generalization | Unseen Object | 54.2% | \(\pi_{0.5}\): 37.5% |
| OpenArm / grounding | Object Grounding | 87.5% | GR00T N1.6: 33.3% |
| ALLEX / motion | Conveyor Pick-and-Place | 100% seen speeds, 75% unseen speeds | GR00T N1.6: 50.0% avg., \(\pi_{0.5}\): 29.2% avg. |
| ALLEX / memory | Object-in-Box Selection | 91.7% | GR00T N1.6: 29.2%, \(\pi_{0.5}\): 33.3% |
| ALLEX / contact | Card Slide-and-Pick | 97.2 progress score | Baselines show sliding/grasping/handover failures |
| ALLEX / physical sensing | Pot-to-Cup Pouring | 70.8 progress score | Baselines fail to complete full task in any trial |
| FR3 / motion | Spin Tracking | 97.9% | \(\pi_{0.5}\): 32.3%, GR00T N1.6: 26.0% |
| FR3 / motion | Pong Game | 81.5% | Source reports broad baseline underperformance |
| FR3 / memory | Shell Game | 91.7% | Baselines around 50.0% |
| FR3 / contact | Plug Insertion | 33.3% | \(\pi_{0.5}\): 20.8%, GR00T N1.6: 16.7% |
| FR3 / fragile grasp | Egg Pick-and-Place | 61.1% | \(\pi_{0.5}\): 45.8%, GR00T N1.6: 37.5% |
Table 5. Real-world results. This digest table groups the paper's reported results by the capability each task is meant to test.
The ablations mostly support the design choices rather than proving every module independently. The VLM analysis says the selected hidden layer matters: extracting from layer 18 gives 60.9% on RoboCasa Kitchen, compared with 51.1% from layer 8 and 56.3% from layer 28. Robot-specific VQA adaptation raises the same setup from 57.5% to 60.9%. Synthetic data scales GR-1 Tabletop from 41.0% with real-only pre-training to 50.1% at full synthetic scale, and an additional ALLEX pot-to-cup grasping experiment improves success from 66.7% with real data to 83.3% with real plus synthetic.
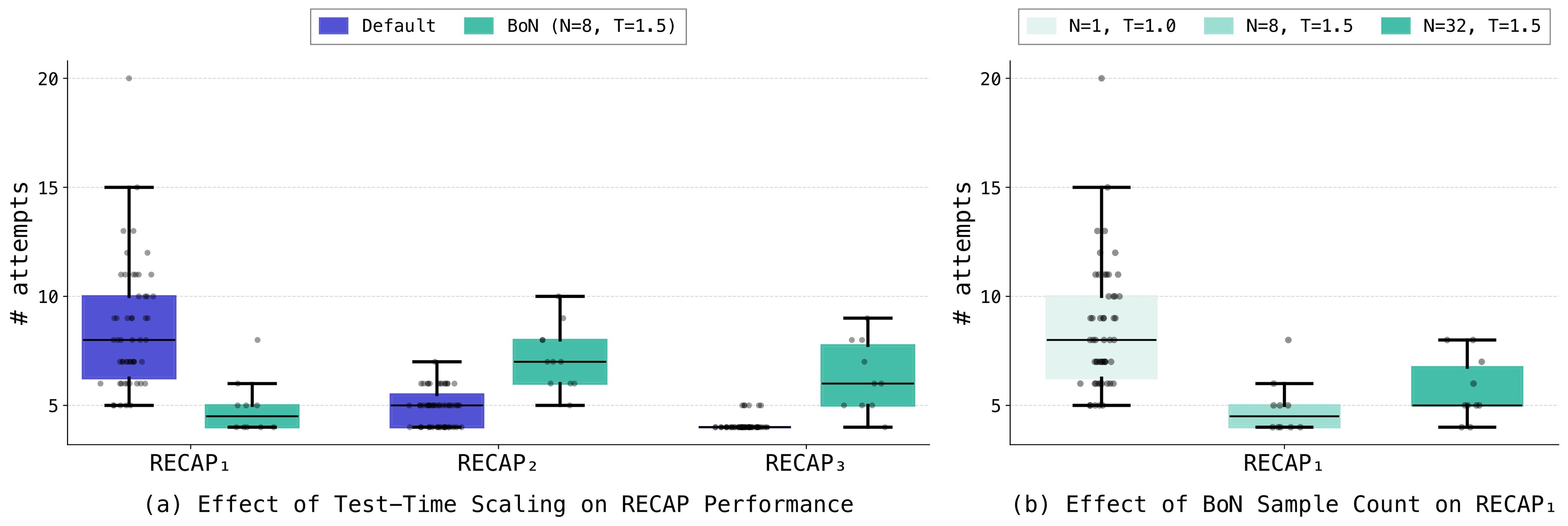
RL is evaluated on *Light Bulb Twisting*. RECAP-style post-training reduces the task from behavior cloning's \(1056 \pm 326\) frames and \(12.7 \pm 3.0\) twist attempts to RECAP3's \(353 \pm 22\) frames and \(4.1 \pm 0.3\) attempts. The paper then tests best-of-\(N\) action selection with a learned Q critic; Figure 5 captures the main caveat. Sampling helps the less-converged RECAP1 policy, reducing attempts from \(8.5 \pm 2.8\) to \(4.9 \pm 1.3\), but worsens RECAP2 and RECAP3, and increasing \(N\) from 8 to 32 does not help further.
| Analysis | Key source result | Interpretation |
|---|---|---|
| VLM extraction layer | Layer 18: 60.9%; layer 8: 51.1%; layer 28: 56.3% | Intermediate VLM features appear better balanced for action generation |
| Robot VQA adaptation | RLDX-1-VLM: 60.9%; Qwen3-VL 8B: 57.5% | Robot-specific VQA improves action-relevant grounding |
| Synthetic GR-1 data | 41.0% real-only to 50.1% full synthetic scale | Synthetic trajectories improve humanoid simulation performance |
| Additional ALLEX synthetic data | 66.7% to 83.3% success on pot-to-cup grasping | Synthetic data improves spatial generalization in this subtask |
| RL post-training | BC: \(12.7 \pm 3.0\) attempts; RECAP3: \(4.1 \pm 0.3\) | RL refinement helps the difficult light-bulb manipulation task |
| Best-of-\(N\) sampling | RECAP1 improves, RECAP2/3 degrade | Test-time sampling is not a universal substitute for RL convergence |
Table 6. Ablation and post-training takeaways. These results support the paper's design choices but remain tied to the authors' chosen benchmarks and task setups.
Practical Takeaways
The strongest practical message is that VLA deployment for dexterous manipulation needs a full stack. RLDX-1's gains do not come from one isolated component: the architecture makes room for time, memory, and force; the data pipeline provides scarce humanoid examples; the training stages introduce capabilities in a controlled order; and the inference stack makes the all-modality model fast enough for closed-loop execution.
For builders, the paper suggests several concrete lessons. First, adding physical sensors is useful only if the model has a structured way to process them and an objective that makes them predictive. Second, synthetic video data needs action consistency checks, not just visual filtering, because the policy learns from action labels. Third, real-robot policy evaluation should include tasks where current observation is insufficient; otherwise memory and physical sensing modules are hard to justify. Fourth, latency work is part of the policy design: the paper's best all-modality result is 43.7 ms per step, not just an offline success-rate number.
The main caveat is cost and reproducibility. The recipe uses very large training runs, in-house humanoid and tactile datasets, custom kernels, and many paper-reported real-robot trials. The reported results are strong evidence for the authors' system, but they are not yet an independent reproduction or a simple recipe for smaller labs. The test-time sampling section also warns against assuming more inference-time search always helps; it can move a converged policy away from the optimum.
Reference Coverage
Anchor coverage links: evidence problem, architecture, flow equations, data/training, inference, simulation, real-world, ablation/post-training, and caveats; figures architecture, synthetic pipeline, ALLEX results, FR3 results, and BoN sampling; tables functional modules, training stages, latency, simulation results, real-world results, and ablation results.