Source-first digest for monthly checked paper rank 16, rank_id p030.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
Visual agents often reuse skills as text prompts, code snippets, execution graphs, or learned routines. MMSkills argues that this representation is incomplete for agents that operate from screenshots or game frames. A reusable GUI or game procedure is not only an instruction sequence; it also needs evidence for when the procedure is applicable, when it should be skipped, what visual cue confirms progress, and what visible state signals completion.
The paper's introductory MMSkills example shows the central failure mode: text-only guidance can describe a chart-creation procedure, but miss whether the live spreadsheet is in the state where that procedure should be applied.
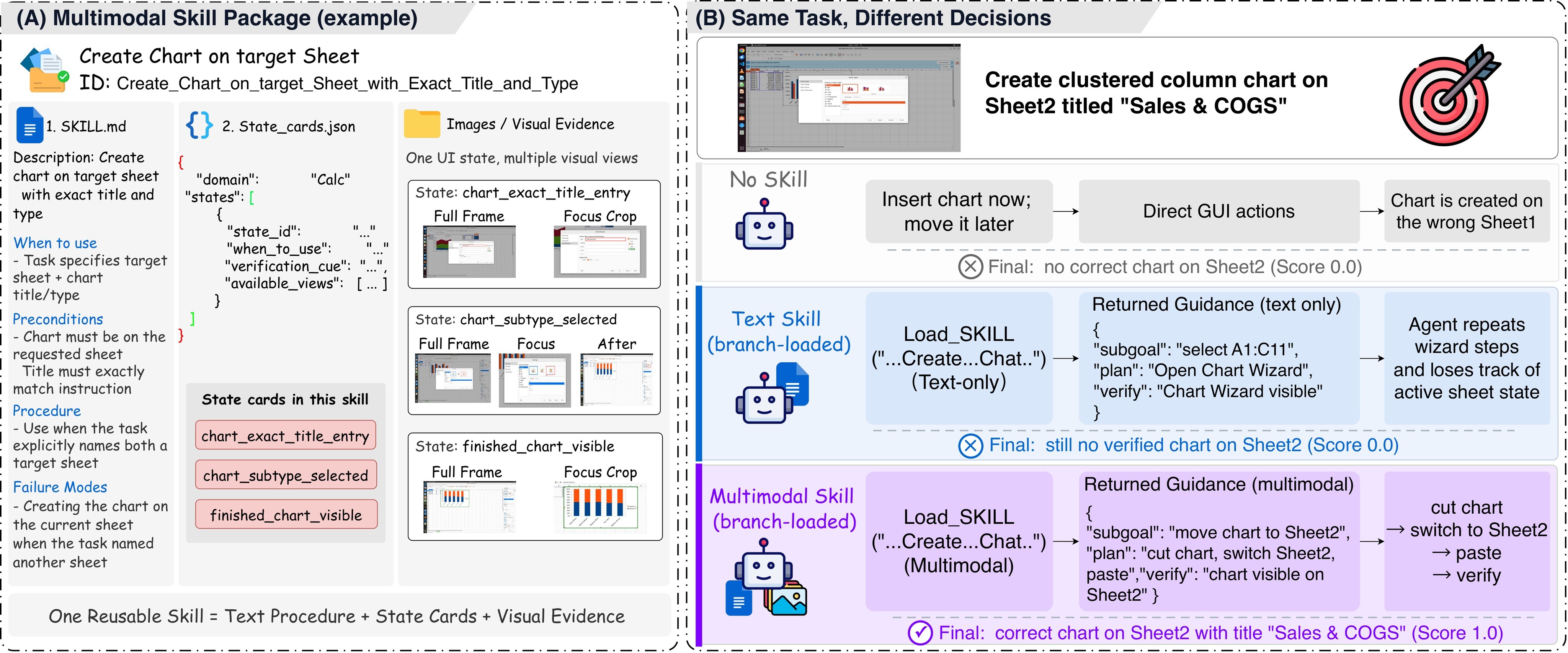
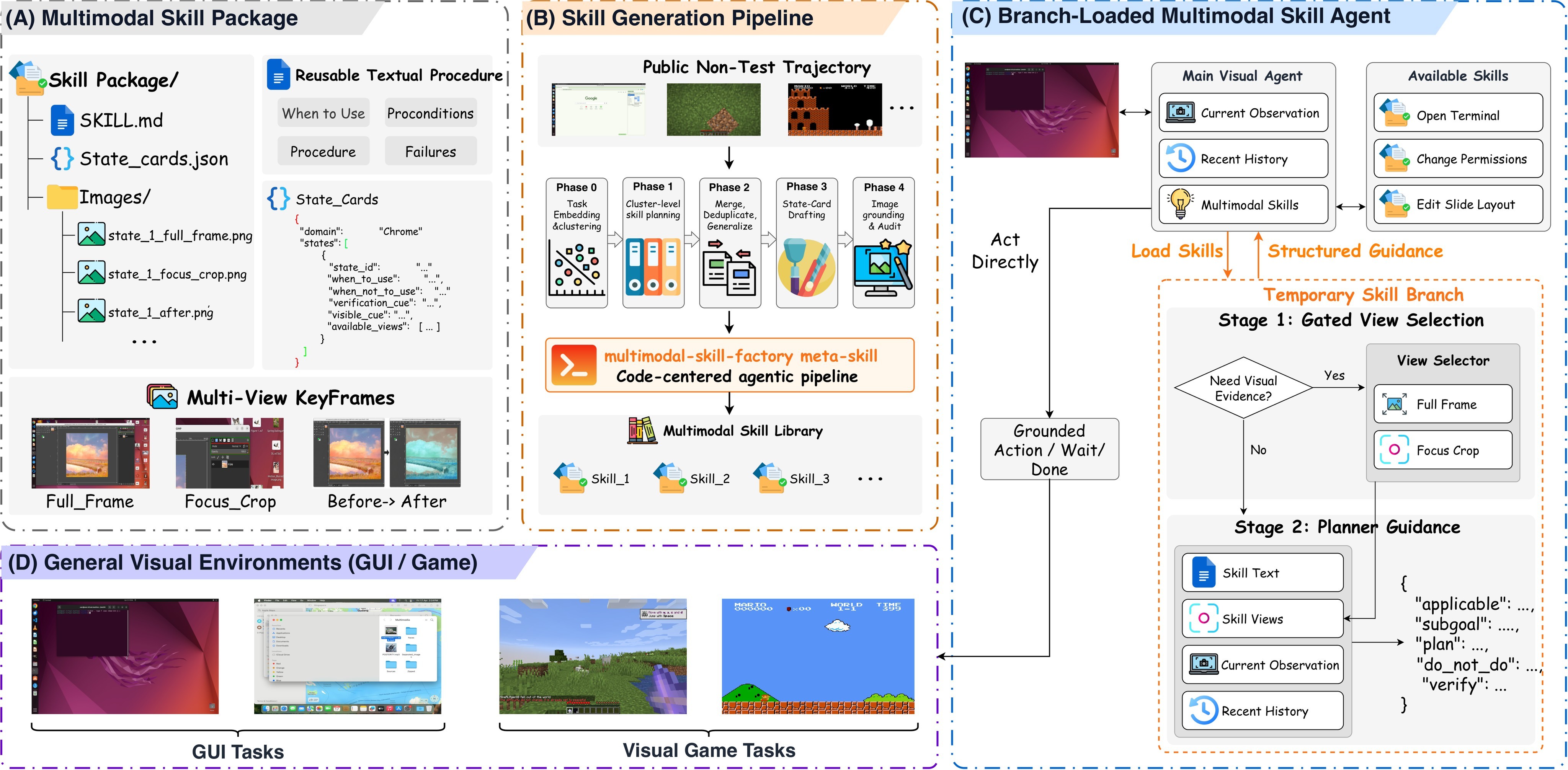
The paper formalizes this as multimodal procedural knowledge. Its answer is a three-part framework: a multimodal skill package, an agentic trajectory-to-skill Generator, and a branch-loaded runtime agent. The system overview is the best high-level map of those pieces.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Visual-agent skills need multimodal procedural knowledge, not only text or code-level action recipes. | 4 | problem framing, package equations, Figure 1, Figure 2 |
| C2 | MMSkills defines a compact reusable package that binds a descriptor, procedure, runtime state cards, and aligned keyframe bundles. | 5 | package equations, method overview |
| C3 | The Generator can turn public non-evaluation trajectories into reusable multimodal skill libraries through clustering, procedure induction, grounding, and audit. | 4 | generator pipeline, source data coverage, source/package table |
| C4 | Branch loading reduces direct-context pressure by selecting needed state cards and views in a temporary branch, then returning structured guidance to the main trajectory. | 4 | runtime equations, branch runtime, prompt surfaces, prompt table |
| C5 | MMSkills improves reported performance across OSWorld and auxiliary GUI/game benchmarks for multiple model families. | 5 | OSWorld results, OSWorld table, auxiliary results, auxiliary table |
| C6 | State cards, keyframes, branch loading, and view selection each matter; removing them weakens the system. | 4 | ablation evidence, ablation figure |
| C7 | MMSkills changes behavior, not only final success rate: agents invoke skills more often, take fewer steps, and show less repetitive low-level action. | 4 | skill usage, usage table, behavior shift, behavior figures |
| C8 | The approach remains limited by source-trajectory coverage, generated-skill errors, visual-grounding mistakes, and extra branch-loading cost. | 3 | limitations, case studies |
Support scores are support-from-paper scores, not reproduction scores. A score of 5 means the claim is directly backed by equations, tables, or controlled experiments inside the paper; lower scores mark claims with more qualitative or implementation-dependent evidence.
Core Technical Idea
MMSkills changes the stored skill artifact. A text-only skill says what to do. An MMSkill says what to do, when it applies, when it does not apply, what visual cue matters, and what evidence verifies progress or completion.
The core package is:
where \(D\) is a compact descriptor, \(P\) is the reusable textual procedure, \(S=\{S_j\}_{j=1}^{m}\) is a set of runtime state cards, and \(K=\{K_j\}_{j=1}^{m}\) is a set of aligned keyframe bundles.
A runtime state card is:
The available view vocabulary is:
Each procedural state has a matched image bundle:
This representation is the paper's main conceptual move. State cards are not captions; they are decision nodes. Keyframes are not demonstration replay; they are compact evidence for recognizing or verifying runtime state.
The Generator maps public trajectories into a domain-specific skill library:
with the staged pipeline:
The paper emphasizes that source trajectories are disjoint from evaluation tasks. The goal is to convert public interaction experience into reusable procedures and diagnostic visual states, not to store raw demonstrations or replay test episodes.
Method Details
Branch-Loaded Runtime
At runtime, the main agent either acts directly or consults a skill branch:
The branch returns structured guidance:
The branch first selects which state cards and views to inspect:
Then it plans from the live observation, selected cards, and selected views:
The key engineering claim is that reference images should not compete with the live screenshot in the main action context. Branch loading treats skill evidence like progressive disclosure: inspect just enough evidence in a temporary branch, distill the guidance, and let the main agent still ground actions in the current observation.
Prompt Interface
The prompt-surface figure exposes the concrete implementation interface behind the equations: one main skill-calling prompt, one gated state-view selection prompt, and one planner-JSON prompt.
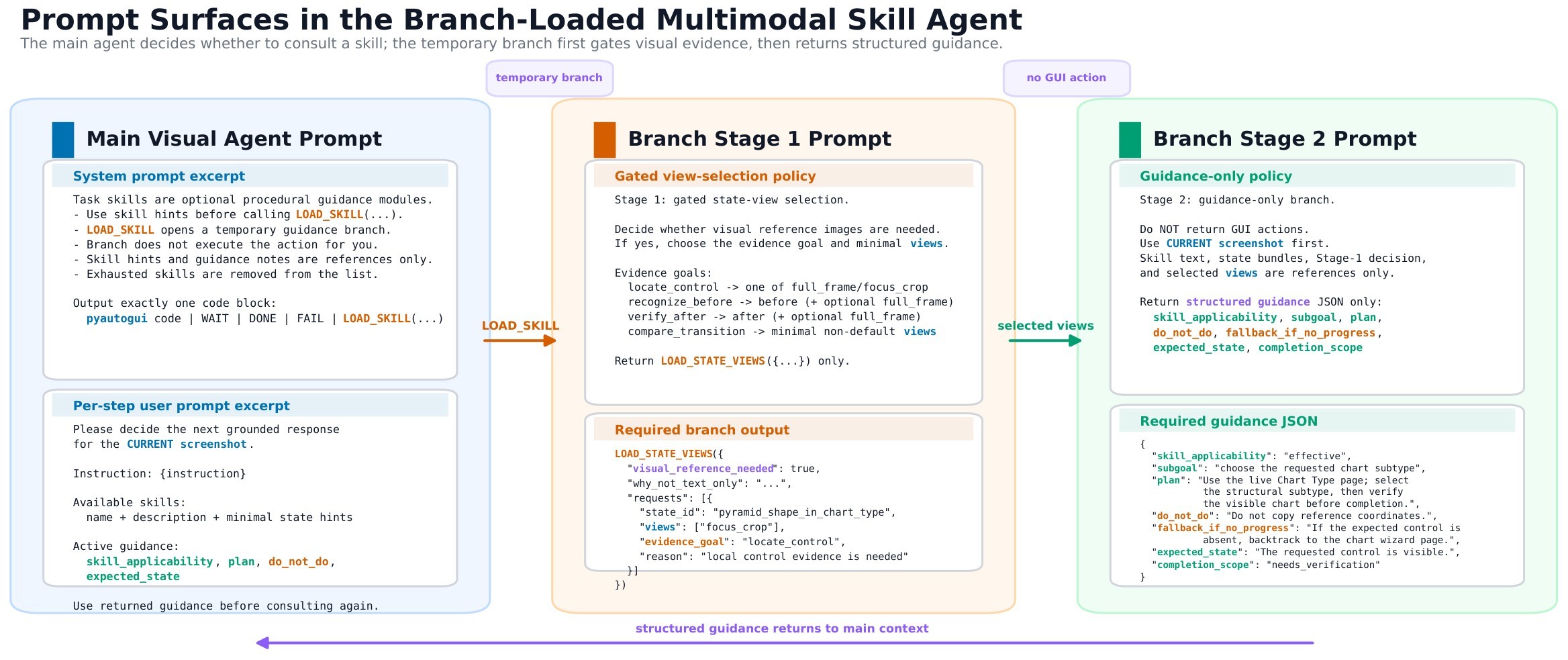
The prompt interface table condenses the appendix prompt templates.
| Surface | Reads | Emits | Guardrail |
|---|---|---|---|
| Main agent | Current screenshot, previous steps, candidate skills, active planner memo | One GUI action, DONE, WAIT, FAIL, or LOAD_SKILL(...) |
Use skill hints as references only; verify before DONE; avoid repeated unproductive loops. |
| Stage 1 branch | Live screenshot, skill text, state-card manifests, previous steps | LOAD_STATE_VIEWS(...) JSON |
Load no images when text is enough; keep evidence minimal with at most a bounded number of states/views. |
| Stage 2 branch | Live screenshot, Stage 1 decision, selected state cards/views | JSON guidance with applicability, subgoal, plan, do-not-do, fallback, expected state, completion scope | Do not emit GUI actions; reference views are never coordinate templates. |
Source Data And Skill Library Scale
The paper's source construction is important because it separates skill generation from evaluation. GUI MMSkills come from OpenCUA Ubuntu/macOS source trajectories, VAB-Minecraft skills use official training episodes, and Super Mario skills come from separate source cases. The source coverage table summarizes the library scale most relevant for interpreting the results.
| Source/evaluation area | Evaluation tasks | Unique skills | State cards | Views | Notes |
|---|---|---|---|---|---|
| OSWorld | 360 | 247 | 879 | 1,898 | Average 1.21 skills/task; 879 full-frame and 876 focus views; 143 transition cards. |
| macOSWorld | 143 | 248 | 522 | 1,097 | Average 1.73 skills/task; 522 full-frame and 522 focus views; 53 transition cards. |
| VAB-Minecraft | official test set | 24 | 79 | 185 | Official training set used as source; average 3.29 cards/skill. |
| Super Mario Bros | held-out cases | 10 | 34 | 48 | Skills extracted from separate source runs over four source cases. |
Experiments And Results
The paper evaluates four questions: overall performance, ablations, skill-usage dynamics, and low-level behavior shift. The strongest quantitative evidence is in the OSWorld and auxiliary benchmark tables.
The OSWorld table condenses the paper's application-level OSWorld results to the overall success-rate column. MMSkills improve overall success for every listed base model.
| Base model | No skill | Text-only | MMSkills | MMSkills gain vs no skill |
|---|---|---|---|---|
| Gemini 3.1 Pro | 44.08 | 40.76 | 50.11 | +6.03 |
| Gemini 3 Flash | 36.65 | 40.27 | 47.97 | +11.32 |
| Qwen3-VL-235B | 21.34 | 28.57 | 39.17 | +17.83 |
| GLM-5V | 28.71 | 36.61 | 38.51 | +9.80 |
| Kimi-K2.6 | 34.98 | 39.66 | 46.59 | +11.61 |
| Qwen3-VL-8B-Instruct | 10.78 | 14.93 | 25.40 | +14.62 |
The Qwen3 rows are the cleanest evidence for the "smaller/weaker model" claim. Qwen3-VL-235B gains 17.83 points on OSWorld, while Qwen3-VL-8B-Instruct more than doubles from 10.78 to 25.40.
The auxiliary results table shows the same pattern beyond Ubuntu desktop tasks. macOSWorld gains are strongest for Gemini 3 Flash and Qwen3-VL-235B; VAB-Minecraft and Super Mario show consistent improvements in the completed model runs.
| Base model | macOSWorld overall: no/text/MMSkills | VAB success: no/text/MMSkills | Super Mario total perf.: no/text/MMSkills |
|---|---|---|---|
| Gemini 3 Flash | 55.94 / 53.85 / 65.73 | 67.24 / 68.96 / 73.28 | 411.00 / 548.00 / 624.00 |
| Qwen3-VL-235B | 47.55 / 43.36 / 51.75 | 52.59 / 55.17 / 62.07 | 454.50 / 610.50 / 788.00 |
| GLM-5V | 34.97 / 51.75 / 51.75 | 56.03 / 61.20 / 68.10 | 612.75 / 794.50 / 950.50 |
| Qwen3-VL-8B-Instruct | 6.29 / 4.90 / 6.29 | 23.28 / 29.31 / 38.79 | 415.25 / 596.50 / 764.00 |
Ablations
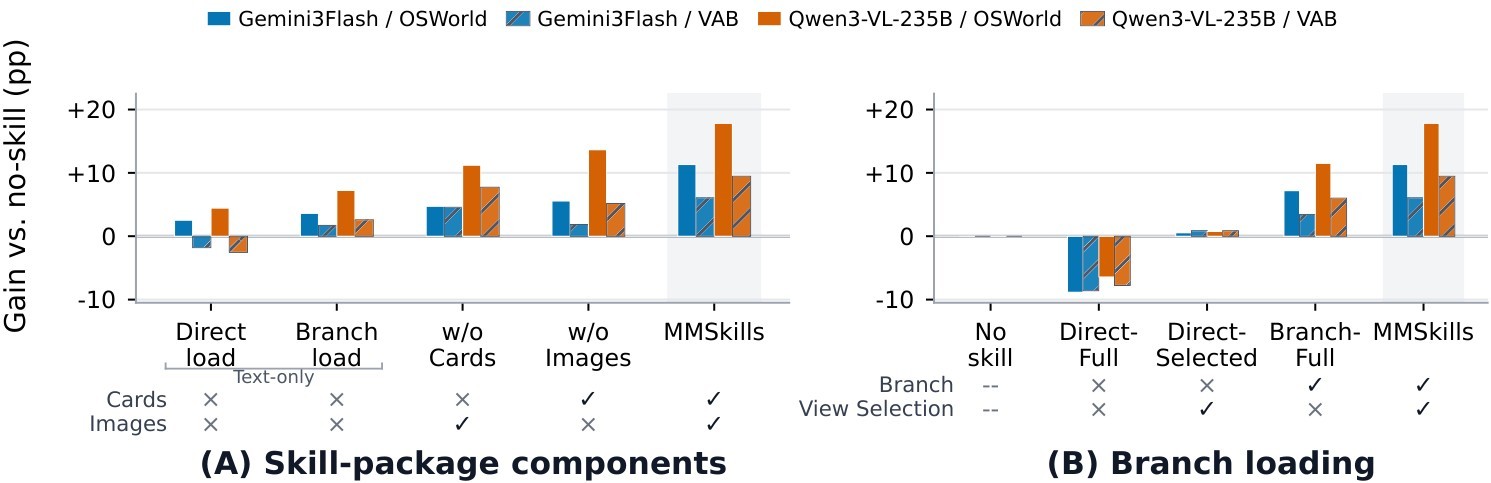
The ablation figure supports two linked claims. First, complete MMSkills outperform text-only skills, MMSkills without state cards, and MMSkills without images. Second, branch loading and view selection are distinct: direct full loading can hurt by injecting unfiltered reference evidence, while the full two-stage branch-loaded design performs best.
Skill Usage And Interaction Dynamics
The skill usage table shows that MMSkills are not just extra context. They are called more often than text-only skills, yet reduce average trajectory length in every listed MMSkills condition.
| Benchmark | Model | Text-only invoked / steps | MMSkills invoked / steps | MMSkills selected views |
|---|---|---|---|---|
| OSWorld | Gemini 3 Flash | 41.11% / 15.64 | 62.50% / 11.86 | 79 full / 241 focus / 8 before / 24 after |
| OSWorld | Qwen3-VL-235B | 37.50% / 13.34 | 65.28% / 9.87 | 40 full / 27 focus / 17 before / 13 after |
| VAB-Minecraft | Gemini 3 Flash | 68.97% / 17.30 | 81.90% / 13.75 | 105 full / 205 focus / 15 before / 12 after |
| VAB-Minecraft | Qwen3-VL-235B | 54.31% / 31.36 | 64.66% / 27.07 | 98 full / 196 focus / 13 before / 10 after |
This is a useful diagnostic result. Text-only skills can add overhead; MMSkills increase skill invocation but reduce steps, suggesting that state-conditioned visual evidence helps the model recognize relevance and avoid exploratory loops.
Behavioral Shift
The main behavior figure argues that MMSkills change action patterns. The paper highlights Qwen3-VL-235B: click share drops from 75.8% to 63.7%, exact repeated actions fall from 21.8% to 6.2%, keyboard and DONE actions increase, and the longest same-mode run decreases.
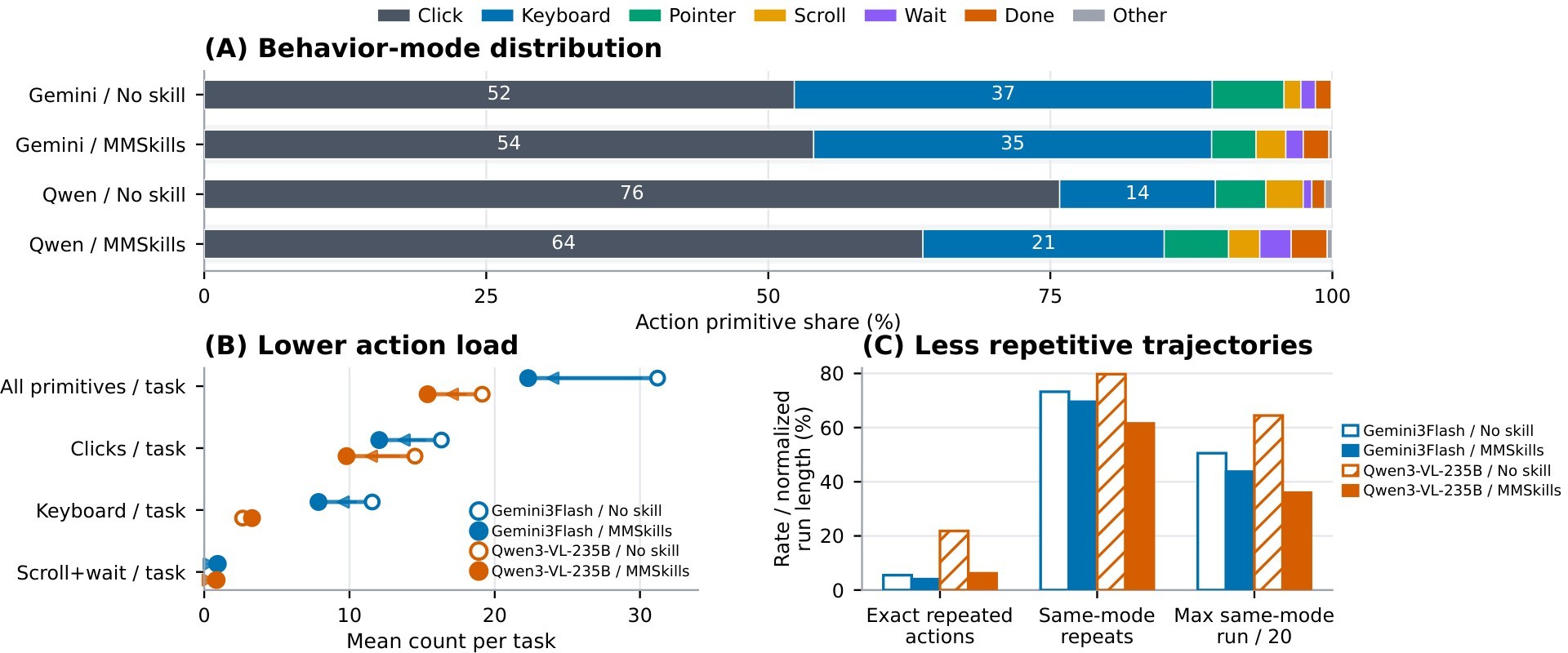
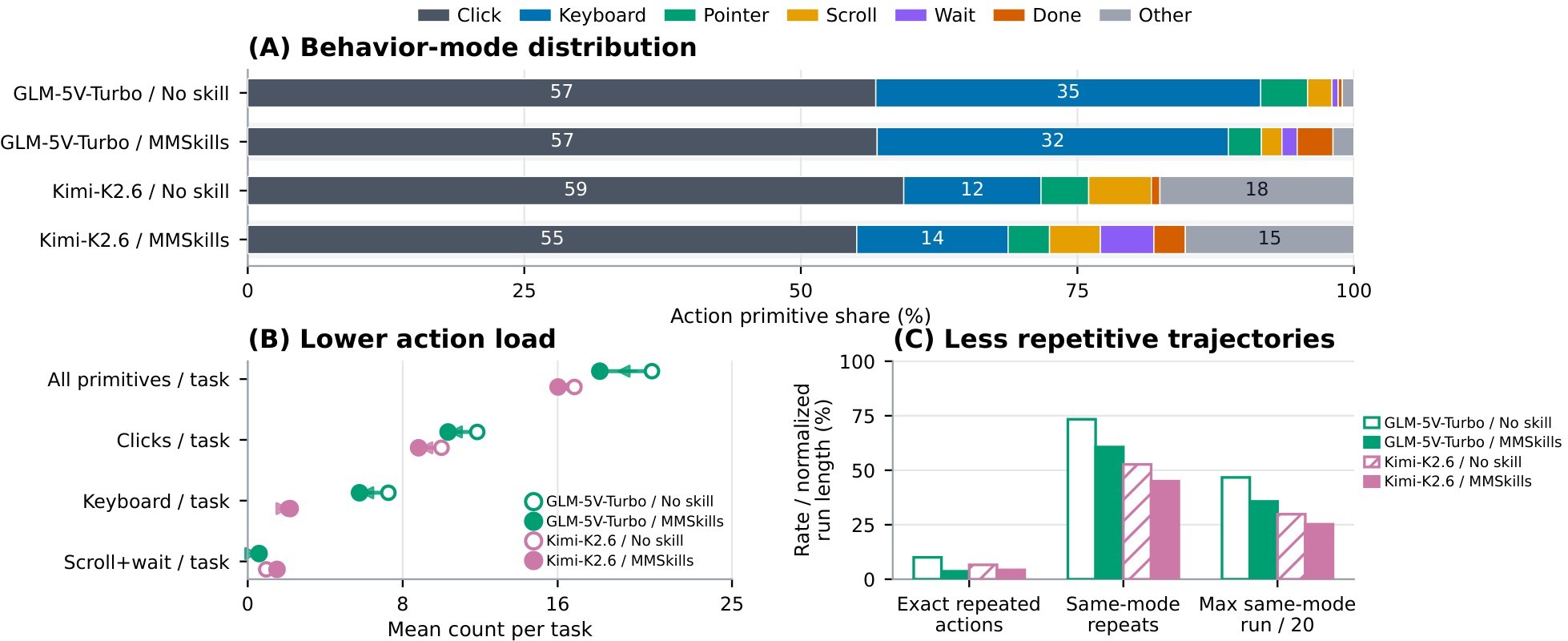
The additional behavior figure extends the same analysis to GLM-5V and Kimi-K2.6.
Interaction Case Studies
The appendix case studies are qualitative, but useful for understanding the runtime mechanics. The Calc case shows multiple spreadsheet skills being consulted at different stages of table construction. The terminal case shows branch guidance helping the agent recover from a brittle command path and verify the final archive structure.
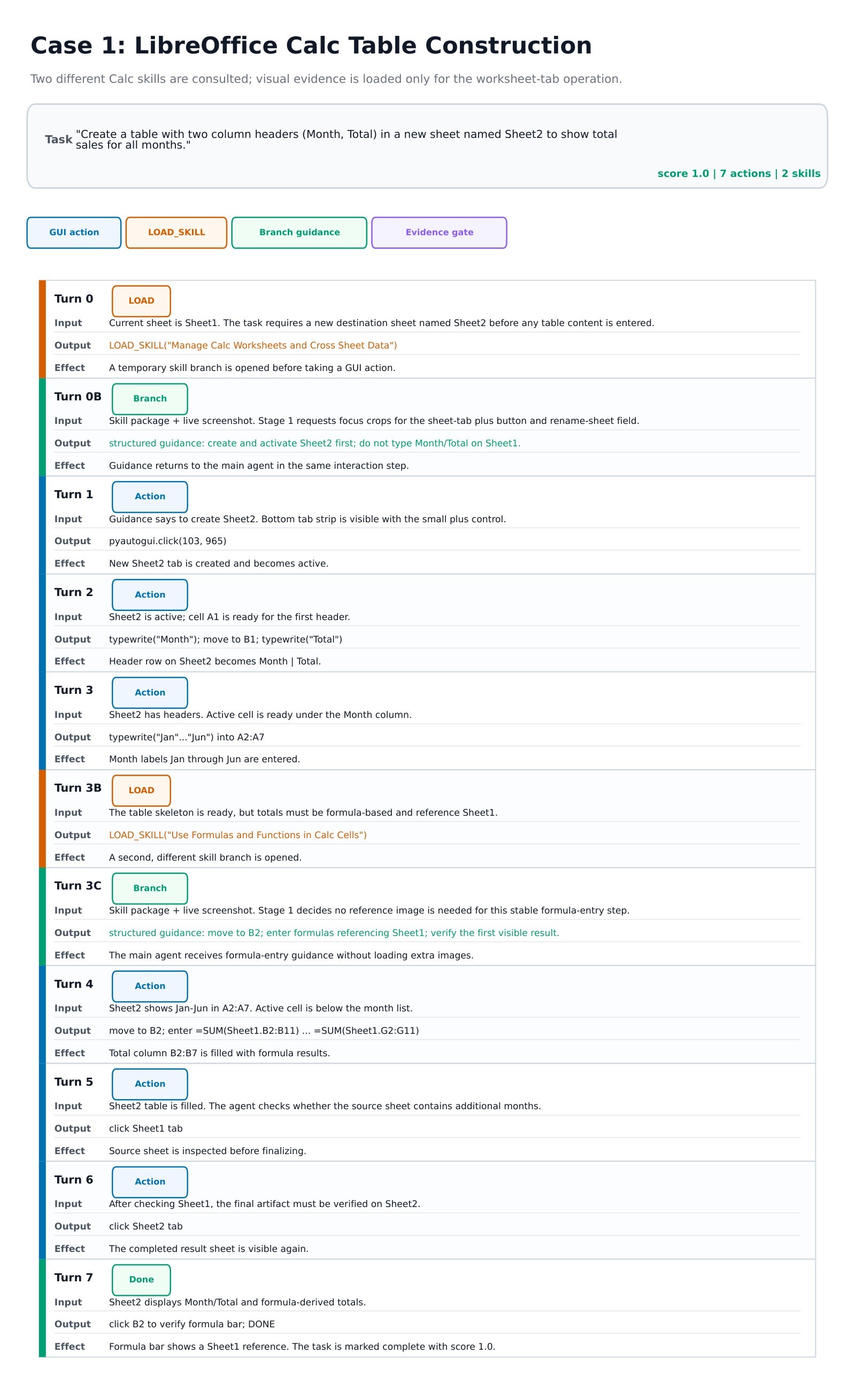
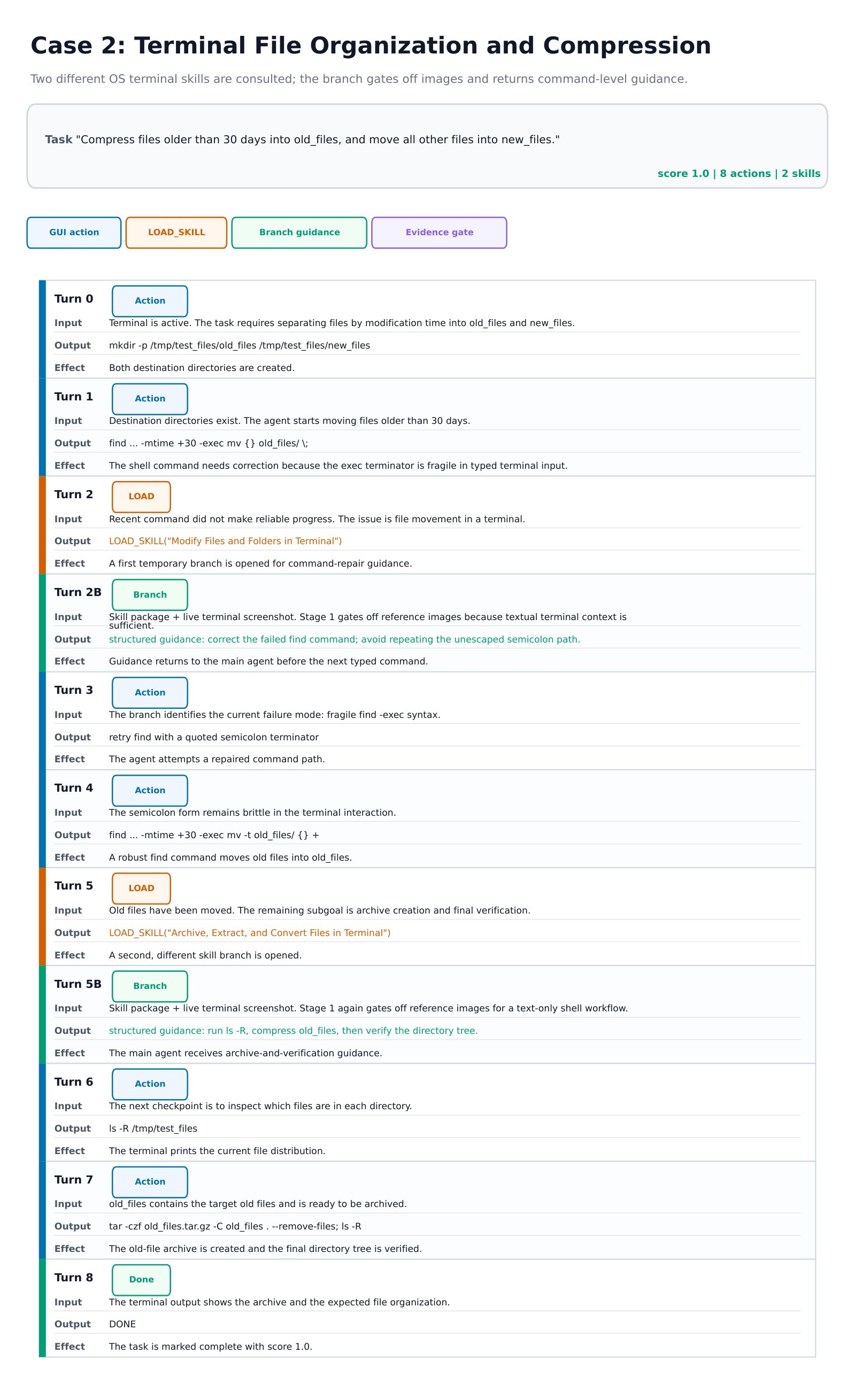
Practical Takeaways
1. The most transferable idea is the state card. A useful visual-agent skill should explicitly encode when to use it, when not to use it, visible cues, and verification cues. The state card is what turns an instruction into reusable procedural knowledge.
2. The strongest systems result is that multimodal skill evidence helps weaker models most. The Qwen3-VL-8B and Qwen3-VL-235B improvements suggest that external visual procedural knowledge can compensate for weaker internal priors.
3. The branch is not just an implementation detail. Directly loading many reference images into the main action context can distract or over-anchor the model. The branch-loaded design lets the system inspect selected reference evidence, then return compact guidance.
4. The paper's evidence is strongest for benchmark performance and ablations, moderate for behavioral interpretation, and weaker for broad deployment claims. The interaction cases are useful illustrations, but not proof of robustness outside the evaluated tasks.
5. A production version would need stronger skill-library governance: source filtering, privacy controls for screenshots, generated-skill audits, online repair when a skill is misleading, and cost controls for branch calls.
Limitations
The paper's own limitations are practical and important. MMSkills depend on source-trajectory coverage, so the system is only as broad as the public non-test experience used to build it. Generated state cards and grounded keyframes can be wrong. Branch loading adds inference cost and wall-clock latency. The method also stores visual evidence, so real deployments need privacy filtering, access controls, and audit mechanisms before skills are shared or reused.
Reference Coverage
All explicit anchors introduced in this digest are linked here for validation coverage: evidence anchors problem, method overview, package equations, generator pipeline, runtime equations, branch runtime, source data, OSWorld results, auxiliary results, ablation, skill usage, behavior shift, case studies, and limitations; figure anchors intro, method, ablation, behavior, prompt surfaces, extra behavior, Calc case, and terminal case; table anchors prompt surfaces, source coverage, OSWorld overall, auxiliary results, and skill usage.