Source-first digest for monthly 2026_05 rank 23, rank_id p039.
- Routing status:
success, routefull_markdown - PDF extraction: not used
Motivation / Background
The paper studies test-time scaling for streaming video generation. Its starting point is that video generation can benefit from spending more compute at inference time, but conventional diffusion-video test-time scaling explores a high-dimensional latent space and repeats multi-step denoising for many candidates. The authors argue that this is especially inefficient for long videos because the method has to search over both visual content and temporal history. Streaming generation changes the search geometry: video is produced chunk by chunk, often with only a few denoising steps per chunk, so the paper frames it as a "shallow search tree with wide branches." This problem framing is the basis for the claim matrix in Table 1.
The proposed Stream-T1 framework adds three test-time mechanisms around a LongLive-style autoregressive video model: Stream-Scaled Noise Propagation, Stream-Scaled Reward Pruning, and Stream-Scaled Memory Sinking. The paper's core claim is not simply that it samples more candidates. It claims that Stream-T1 actively steers the next chunk by reusing historically good noise, selecting candidates with short-term and long-term reward signals, and updating the KV-cache sink according to reward-derived memory gates. The high-level flow is shown in Figure 1, and the full branch trajectory for the illustrated case is shown in Figure 2.
Claims And Evidence
Support scores are support-from-paper scores, not independent reproduction scores. A score of 5 means the claim is directly supported by paper equations, tables, figures, or ablations. A score of 4 means the paper reports direct evidence, but the claim still depends on the authors' benchmark, reward model, or evaluation setup. A score of 3 means the paper gives plausible support but leaves a numerical inconsistency, missing ablation, or qualitative gap.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Streaming video generation is a more cost-effective target for video test-time scaling than standard diffusion-video search because chunks use a smaller local search space and fewer denoising steps. | 4 | problem framing, contribution framing, pipeline |
| C2 | Stream-T1 is a three-part active test-time framework rather than plain candidate selection: it propagates noise, prunes by rewards, and updates memory. | 5 | method overview, method map, pipeline, search trajectory |
| C3 | Noise propagation correlates the current chunk's initial noise with the previous best trajectory while preserving a standard Gaussian marginal. | 5 | key equations, noise propagation |
| C4 | Reward pruning combines frame-level spatial quality and sliding-window temporal quality, then prunes a beam-expanded pool from \(K \times M\) candidates back to top \(K\). | 5 | reward pruning, key equations, method map |
| C5 | Memory sinking uses reward feedback to decide whether evicted KV-cache chunks are discarded, EMA-compressed, or appended as new long-term anchors. | 5 | memory sinking, key equations, pipeline |
| C6 | Against CausVid, Self-forcing, and LongLive, Stream-T1 reports the strongest overall 5-second and 30-second benchmark profile, with a few metric-specific exceptions. | 4 | short-video results, long-video results, 5s table, 30s table, qualitative results |
| C7 | Compared with passive test-time scaling baselines, the active Stream-T1 intervention is stronger on most 30-second metrics, but the recovered table shows Best-of-N higher on imaging quality. | 3 | TTS comparison, TTS table |
| C8 | The ablation supports all three modules as useful for temporal consistency, although the best imaging-quality number comes from removing memory sinking. | 4 | ablation evidence, ablation table, ablation figure |
Core Technical Idea
The core technical idea is to make every generated chunk depend on a rewarded history, not only on the model's default autoregressive state. Built on LongLive, Stream-T1 maintains a beam of candidate histories. Before producing a new chunk, it initializes the chunk's noise from historically successful noise. After generation, it scores the expanded candidate set using both image- and video-level reward models. After pruning, it updates memory according to whether the evicted context is high quality and whether it marks a transition. This flow is summarized in Table 2.
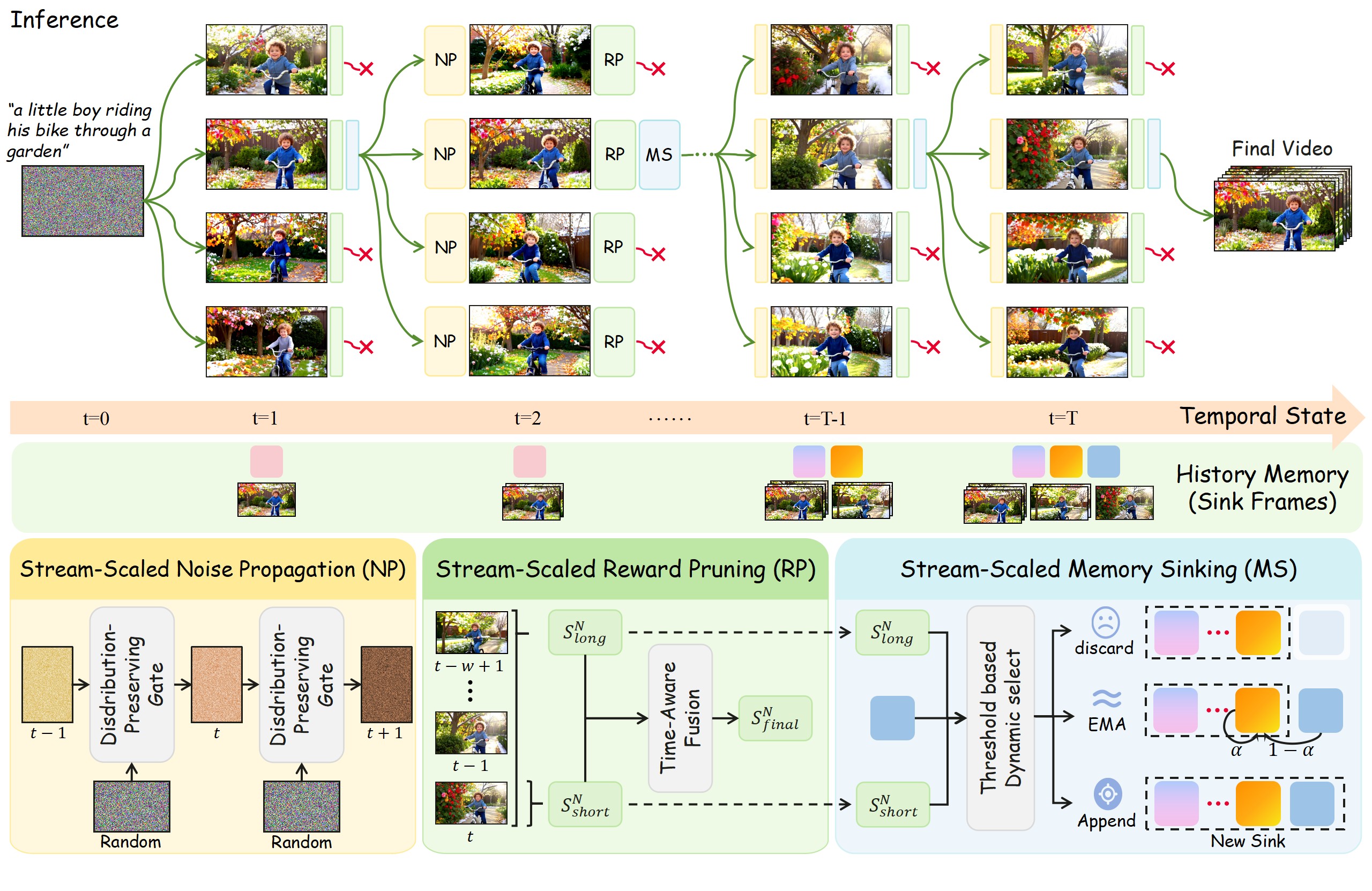
fig:pipeline, original LaTeX asset fig/pipeline.png, copied from the ranking cache to figs/fig001_01_pipeline.jpg.
fig:search, original LaTeX asset fig/search.png, copied from the ranking cache to figs/fig002_01_search.jpg.| Component | When it acts | Signal | What it changes | Digest reading |
|---|---|---|---|---|
| Beam expansion | Per chunk | \(K\) histories expanded by \(M\) alternatives | Candidate pool grows to \(K \times M\) | This is the ordinary search substrate. |
| Stream-Scaled Noise Propagation | Before synthesis | Previous best noise latent plus fresh Gaussian noise | Initial latent noise for the next chunk | Adds temporal correlation without changing the Gaussian marginal. |
| Stream-Scaled Reward Pruning | After chunk synthesis | Frame reward and sliding-window video reward | Keeps top \(K\) candidate histories | Balances local aesthetics and longer temporal coherence. |
| Stream-Scaled Memory Sinking | After pruning | Short-score quality gate and long-score transition detector | Routes evicted KV-cache chunks through discard, EMA, or append | Tries to avoid both context pollution and over-smoothed memory. |
The autoregressive diffusion chunk is modeled as a few-step denoising composition:
Noise propagation initializes the first chunk from a standard Gaussian and later chunks by spherical interpolation against the previous selected chunk noise:
Reward pruning splits candidate evaluation into a short image score and a long sliding-window video score:
The final pruning score increases short-score weight as generation advances, but caps it by \(\tau\):
Memory sinking uses two gates:
The routing choices are: keep the sink unchanged when the chunk fails the quality gate; EMA-compress \(K^n,V^n\) into the latest sink when quality is high and no transition is detected; or append \(K^n,V^n\) as a new anchor when quality is high and the long reward indicates a transition.
Method Details
Stream-Scaled Noise Propagation is motivated by the observation that nearby latent states often share generation quality. Instead of sampling each chunk's initial noise independently, the method conditions \(x_T^n\) on the previously selected \(x_T^{n-1}\) through the interpolation in the key equations. The design gives adjacent chunks a controllable correlation through \(\beta\), while the fresh \(\epsilon\) term preserves the marginal Gaussian distribution. This is why C3 receives a high support score in Table 1: the equation directly backs the stated mechanism.
Stream-Scaled Reward Pruning is the search filter. For each chunk, \(K\) live histories are each expanded into \(M\) alternatives, producing \(K \times M\) candidate continuations. A short score averages frame-level image rewards for spatial fidelity, and a long score uses a video reward model over a sliding window of recent chunks for text alignment, visual quality, and motion coherence. The final score in the key equations increases the short-score contribution later in the video while capping that contribution to reduce repetition or stagnation.
Stream-Scaled Memory Sinking is the long-horizon context mechanism. LongLive starts from a sliding-window cache with attention sinks, but fixed sinks can over-anchor early frames and uniform EMA can blur distinct semantic states. Stream-T1 uses the reward scores from pruning to decide what to do with the KV-cache chunk evicted from the local window: discard low-quality chunks, EMA-compress high-quality non-transition chunks, or append high-quality transition chunks as new anchors. The append/EMA/discard policy is the most direct mechanism behind the paper's long-video consistency claim.
The experiments instantiate Stream-T1 on LongLive built from Wan2.1-T2V-1.3B. The initial KV cache has attention window size 9 and sink size 3. The short reward can use image reward models such as HPSv3, ImageReward, and MHP; the long reward can use video reward models such as VisionReward, VideoAlign, and VideoLLaMA3 over a 10-chunk sliding window. The generated videos are reported at 16 FPS and \(832 \times 480\) resolution. These settings are summarized in Table 3.
| Setting | Value reported in source |
|---|---|
| Base generator | LongLive built on Wan2.1-T2V-1.3B |
| Test-time algorithm | Beam search with \(K\) histories and \(M\) chunk expansions |
| Initial KV-cache strategy | Attention window size 9 and sink size 3 |
| Short-sequence reward | Image reward models such as HPSv3, ImageReward, and MHP |
| Long-sequence reward | VisionReward, VideoAlign, and VideoLLaMA3 over a 10-chunk window |
| Output setting | 16 FPS at \(832 \times 480\) |
| Short benchmark | 946 VBench prompts, 5-second clips |
| Long benchmark | First 128 MovieGen prompts, 30-second clips |
| Metrics | VBench/VBench-long plus VideoAlign VQ, MQ, and TA |
Experiments And Results
For 5-second clips, the paper compares CausVid, Self-forcing, LongLive, and Stream-T1 on 946 VBench prompts. Table 4 shows that Stream-T1 has the best Subject Consistency, Background Consistency, Motion Smoothness, Aesthetic Quality, VideoAlign MQ, and VideoAlign TA. The exceptions matter: Self-forcing has the highest Imaging Quality, and CausVid has the highest VideoAlign VQ.
| Method | Subject | Background | Motion | Imaging | Aesthetic | VQ | MQ | TA |
|---|---|---|---|---|---|---|---|---|
| CausVid | 96.33 | 95.56 | 98.66 | 69.69 | 62.90 | 0.433 | 0.550 | 1.020 |
| Self-forcing | 95.26 | 95.67 | 98.67 | 71.61 | 63.97 | 0.099 | 0.088 | 1.193 |
| LongLive | 97.00 | 96.78 | 99.12 | 71.28 | 65.28 | 0.285 | 0.350 | 1.193 |
| Stream-T1 on LongLive | 97.25 | 97.05 | 99.15 | 71.42 | 65.98 | 0.426 | 0.629 | 1.305 |
For 30-second videos, Table 5 is stronger for Stream-T1. It reports the best VBench-long Subject Consistency, Background Consistency, Motion Smoothness, Imaging Quality, and Aesthetic Quality, plus best VideoAlign VQ and TA. CausVid remains higher on VideoAlign MQ. The qualitative comparison in Figure 3 is consistent with the paper's claim that Stream-T1 preserves long-horizon appearance and temporal coherence better than the baselines.
| Method | Subject | Background | Motion | Imaging | Aesthetic | VQ | MQ | TA |
|---|---|---|---|---|---|---|---|---|
| CausVid | 97.91 | 96.74 | 98.15 | 66.32 | 59.71 | -0.144 | 0.328 | 0.501 |
| Self-forcing | 97.18 | 96.37 | 98.35 | 68.35 | 59.19 | -0.461 | -0.216 | 0.656 |
| LongLive | 97.90 | 96.82 | 98.78 | 68.99 | 61.56 | -0.169 | -0.002 | 1.073 |
| Stream-T1 on LongLive | 98.43 | 97.18 | 99.03 | 69.10 | 62.11 | -0.073 | 0.226 | 1.170 |

fig:results, original LaTeX asset fig/results.png, copied from the ranking cache to figs/fig003_01_results.jpg.The paper also compares active Stream-T1 against passive test-time scaling variants on 30-second generation. Table 6 reports that Stream-T1 improves over LongLive, Best-of-N, and Beam Search on most metrics. There is a source-level inconsistency: the paper text says Stream-T1 is state-of-the-art across all evaluative metrics, but the recovered table lists Best-of-N at 69.34 Imaging Quality versus Stream-T1 at 69.10. The digest therefore scores C7 as 3 rather than 5.
| Method | Subject | Background | Motion | Imaging | Aesthetic | VQ | MQ | TA |
|---|---|---|---|---|---|---|---|---|
| LongLive | 97.90 | 96.82 | 98.78 | 68.99 | 61.56 | -0.169 | -0.002 | 1.073 |
| LongLive + Best-of-N | 98.13 | 96.88 | 98.86 | 69.34 | 61.97 | -0.083 | 0.062 | 1.160 |
| LongLive + Beam Search | 98.28 | 97.03 | 98.90 | 69.05 | 61.85 | -0.077 | 0.165 | 1.159 |
| LongLive + Stream-T1 | 98.43 | 97.18 | 99.03 | 69.10 | 62.11 | -0.073 | 0.226 | 1.170 |
The ablation studies isolate the three modules on 30-second generation. The text and Figure 4 say removing memory sinking hurts background stability, removing noise propagation introduces local structural artifacts, and removing reward pruning causes semantic misalignment and lower aesthetic quality. Table 7 supports the broad story, but it also shows tradeoffs: removing memory sinking gives the highest Imaging Quality, while Stream-T1 wins the consistency, motion, aesthetic, VQ, MQ, and TA metrics.

fig:ablation, original LaTeX asset fig/ablation.png, copied from the ranking cache to figs/fig004_01_ablation.jpg.| Variant | Subject | Background | Motion | Imaging | Aesthetic | VQ | MQ | TA |
|---|---|---|---|---|---|---|---|---|
| w/o Memory Sinking | 98.30 | 97.04 | 98.92 | 69.51 | 61.90 | -0.083 | 0.188 | 1.146 |
| w/o Noise Propagation | 98.35 | 97.14 | 98.98 | 69.07 | 61.99 | -0.094 | 0.176 | 1.164 |
| w/o Reward Pruning | 98.04 | 96.88 | 98.87 | 69.17 | 61.22 | -0.173 | 0.014 | 1.035 |
| Full Stream-T1 | 98.43 | 97.18 | 99.03 | 69.10 | 62.11 | -0.073 | 0.226 | 1.170 |
Practical Takeaways
The useful reading is that Stream-T1 is a test-time controller for streaming video generation: it does not introduce a new backbone, but it uses extra inference-time candidate generation, reward evaluation, and memory routing to make chunk-by-chunk video more stable. It is most compelling when the application can afford more generation-time compute for long-video quality. It is less compelling if the strict requirement is single-pass latency, because the method explicitly expands candidates and evaluates reward models at test time.
| Practical point | Why it matters |
|---|---|
| Best fit | Long or streaming text-to-video generation where temporal drift is more damaging than extra inference compute. |
| Main mechanism to copy | Couple beam search with active state changes: noise initialization, reward-aware pruning, and reward-aware memory updates. |
| Most concrete equations | Noise interpolation, short/long reward fusion, and quality/transition memory gates in the key equations. |
| Strongest evidence | 30-second VBench-long and VideoAlign improvements in Table 5, plus qualitative stability in Figure 3. |
| Main caveat | The reported gains depend on the selected reward models and benchmark prompts; there is no independent reproduction in the source. |
| Table inconsistency | The passive-TTS comparison claims all-metric superiority, but Table 6 lists a higher imaging-quality score for Best-of-N. |
Reference Coverage
Anchor coverage links: claims table, problem framing, contribution framing, method overview, pipeline figure, search figure, method map, key equations, noise evidence, reward evidence, memory evidence, implementation evidence, implementation table, short-video evidence, 5s results table, long-video evidence, 30s results table, qualitative results figure, TTS comparison evidence, TTS comparison table, ablation evidence, ablation figure, ablation table, caveats, and practical takeaways table.