Source-first digest for monthly 2026_05 rank 15, rank_id p042.
- Routing status:
pandoc_failed; used flattened TeX plusequations.jsonandfigures.json - PDF extraction: not used
Motivation / Background
OpenSearch-VL targets the reproducibility gap around frontier multimodal search agents. The paper argues that strong systems now need to do more than answer from a single visual encoder pass: they must search, verify, repair weak visual evidence, and reason over multi-step tool observations. The authors frame existing frontier systems as hard to reproduce because the training data, trajectory generation, tool environment, and RL recipe are often proprietary or underspecified.
The paper's open recipe has three moving parts: high-quality image-grounded search data, a tool environment that combines retrieval with active perception, and a fatal-aware GRPO objective for long-horizon tool rollouts. The introduction states the intended public release scope as data, code, models, and training recipe, but this digest treats that as a paper-stated release plan rather than independently verified availability. The main claims and their support levels are summarized in Table 1.
The authors' core motivation is that multimodal deep search fails when the problem is reduced to one-step retrieval. Their training data is therefore designed to force a visual-to-text chain: first identify or repair the visual anchor, then traverse textual relations, then verify the answer. This matters for questions where the image alone does not expose the answer and a naive reverse-image or text search would create shortcuts.
Claims And Evidence
Support scores in Table 1 are source-support scores, not independent reproduction scores. A score of 5 means the claim is directly backed by source text, equations, tables, or figures. A score of 4 means the paper gives strong internal evidence but still depends on assumptions such as judge quality or benchmark representativeness. A score below 4 flags a claim that is partly prospective or externally fragile.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | OpenSearch-VL is presented as a fully open recipe for training multimodal deep-search agents, spanning data, tools, SFT, and RL. | 4 | open recipe, training setup, limitations |
| C2 | The data pipeline deliberately reduces shortcut solving by combining Wikipedia path sampling, fuzzy entity rewriting, source-anchor visual grounding, staged filtering, and a degradation-enhancement subset. | 5 | data pipeline, Figure 1, data ablation |
| C3 | The tool environment is broader than retrieval-only search: it includes text search, image search, OCR, crop, sharpen, super-resolution, and perspective correction. | 5 | tool environment, Table 3, case study |
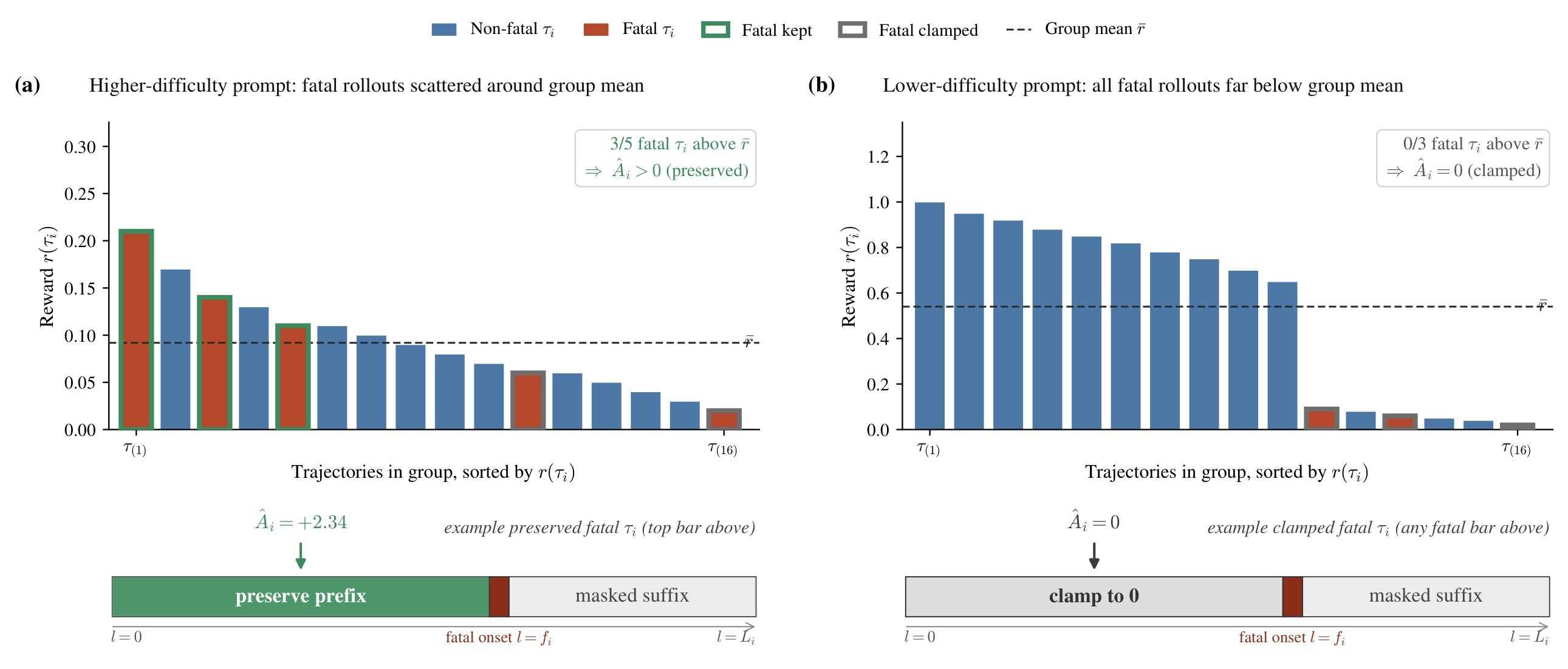
| C4 | Fatal-aware GRPO preserves useful pre-failure reasoning by masking post-failure tokens and clamping fatal-trajectory advantages to be non-negative. | 5 | fatal-aware GRPO, key equations, Figure 2, Figure 5 |
| C5 | The reported benchmark gains are large: the 30B-A3B OpenSearch-VL agent improves the Qwen3-VL-30B-A3B agentic baseline average from 47.8 to 61.6. | 5 | main results, Table 4 |
| C6 | The ablations support both main design families: removing data-pipeline safeguards causes large SFT drops, and adding fatal masking plus one-sided clamping beats vanilla GRPO. | 5 | ablation, Table 5, Figure 3, Figure 4 |
| C7 | The recipe is promising but not fully self-contained experimentally: tool drift, proprietary LLM judges, API dependence, and missing multi-seed error bars remain limitations. | 5 | limitations, main results |
Core Technical Idea
The core idea is to train a multimodal agent on tasks that require active visual grounding plus external evidence acquisition, rather than tasks answerable from parametric memory, the raw image, or one retrieval call. Figure 1 is the source paper's overview of that data pipeline.
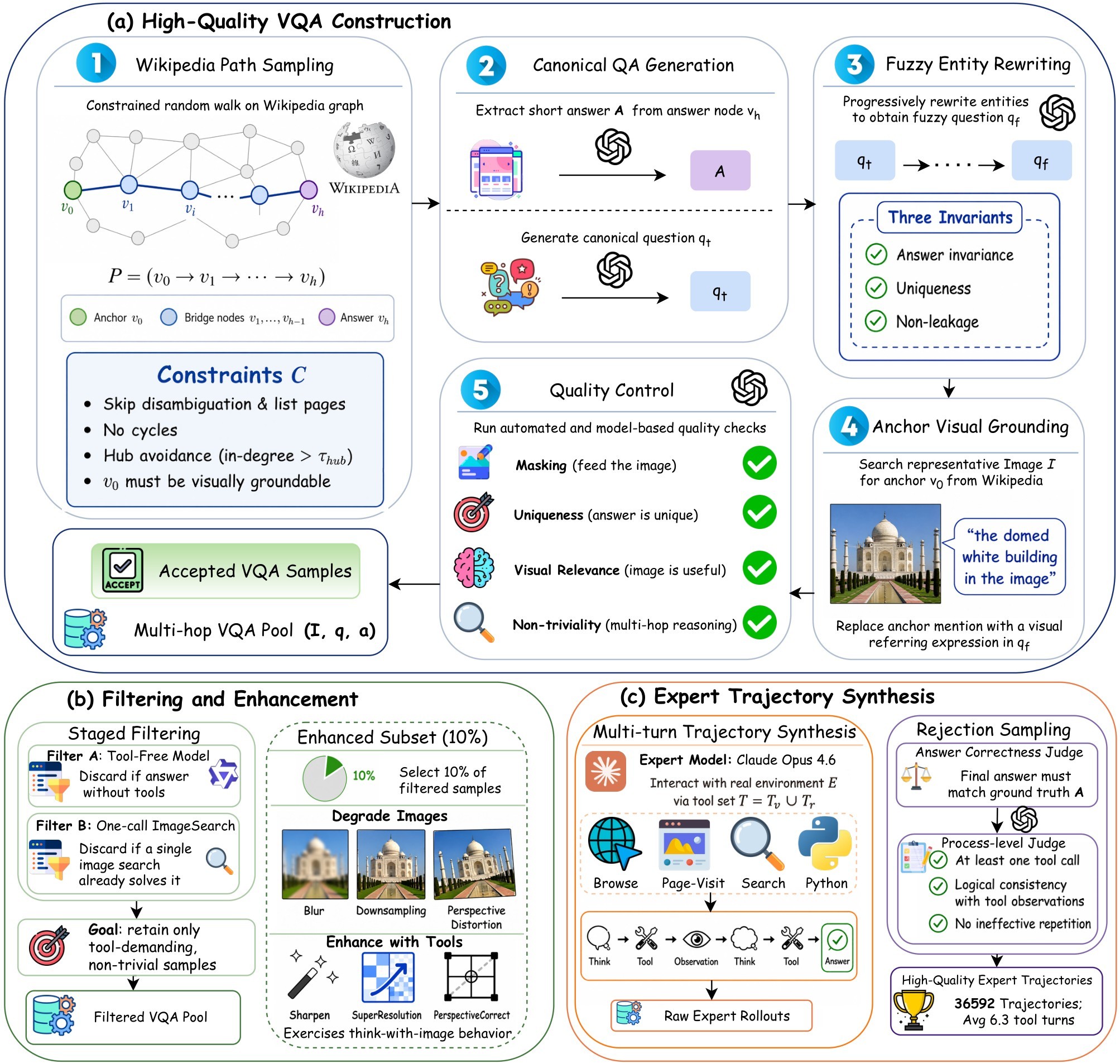
The data starts from a constrained random walk over the Wikipedia hyperlink graph. Each path assigns a role to nodes: \(v_0\) is the visual anchor, intermediate nodes are bridges, and \(v_h\) supplies the answer attribute. The paper then rewrites explicit entity names into fuzzy descriptors while keeping the answer invariant and unique. The final visual question replaces the source anchor with an image reference, forcing the agent to identify the visual entry point before following textual relations.
The authors add two filters that directly target shortcut behavior. First, a frozen Qwen3-VL-32B model discards examples answerable without tools. Second, it discards examples solvable with a single ImageSearch call. A 10 percent enhancement subset further degrades images with blur, downsampling, or perspective distortion, then pairs those cases with the corresponding image-repair tools. The resulting SFT corpus contains 36,592 rejected-and-filtered expert trajectories with an average of 6.3 tool-invocation turns; the RL set contains 8K examples sampled from the filtered VQA pool.

The appendix example illustrates why the anchor/answer split matters. If the image were the answer entity, reverse-image search would expose the answer directly. If fuzzy rewriting were removed, a plain text query would do the same. If hub avoidance were removed, descriptors become ambiguous. The example and Figure 6 make the paper's data construction less abstract: the question is intentionally designed so the image is load-bearing but not answer-revealing.
Method Details
OpenSearch-VL defines a multi-turn trajectory in which the agent conditions on accumulated images, previous actions, and previous observations, then emits either a tool call or a final response. Table 2 lists the most important formal objects, and Table 3 lists the tool suite.
| Object | Source label | Digest interpretation | ||
|---|---|---|---|---|
| \(h_l = (\mathcal{I}_l, q, \mathbf{a}_{<l}, \mathbf{o}_{<l})\) | eq:history |
The state is not just text; it includes the active visual context plus action and observation history. | ||
| \(\tau = \{(h_0,a_0,o_0), \dots, (h_L,a_L)\}\) | eq:trajectory |
Training and RL operate over full multi-turn ReAct-style trajectories. | ||
| \(o_l = \mathcal{E}(c_l,h_l)\) routed to image or text observations | eq:obs-routing |
Visual tools can return new images, while retrieval and OCR return text-like observations. | ||
| \(\pi_\theta(\tau \mid I_0,q) = \prod_l P_\theta(z_l \mid h_l)P_\theta(c_l \mid h_l,z_l)\) | eq:traj-likelihood |
The model is trained on reasoning traces and commands, not on exogenous tool observations. | ||
| \(a(q_f)=a(q_t)\), \( | \mathcal{R}(q_f) | =1\), and no path aliases in \(q_f\) | eq:fuzz-invariants |
Fuzzy rewrites must preserve answer, uniqueness, and non-leakage. |
Table 2. Key formulation equations. The equations come from equations.json and the flattened TeX source, with HTML rendering avoided in this task.
| Tool family | Tools | Role in the recipe |
|---|---|---|
| Retrieval | TextSearch, ImageSearch |
Acquire external factual and visual-entity evidence. |
| Image enhancement | Sharpen, SuperResolution, PerspectiveCorrect |
Repair blur, low resolution, or skew before search or OCR. |
| Attention and parsing | Crop, OCR |
Focus on diagnostic regions and decode text/layout from images. |
Table 3. OpenSearch-VL tool suite. The source table describes seven tools and the appendix gives implementation details, including Serper/JINA/Qwen3-32B for text search, Polaris Lens for image search, OpenCV-style local image enhancement, and remote PaddleX-backed OCR.
Training is sequential. First, SFT maximizes the likelihood of reasoning trace \(z_l\) and command \(c_l\) over the 36,592 expert trajectories:
The paper's implementation details say all three model sizes use full-parameter finetuning with the vision tower and multimodal projector unfrozen, DeepSpeed ZeRO-3, bfloat16, a 32K-token cutoff, and 256 H20 GPUs for SFT. RL then uses an async SGLang rollout engine with Megatron-LM actor training over 64 H20 GPUs. These details support the "recipe" claim, but they also show that reproducing the exact scale is expensive.
Figure 2 summarizes the RL stage. The RL reward is a composite of format correctness, terminal answer accuracy, and query quality:
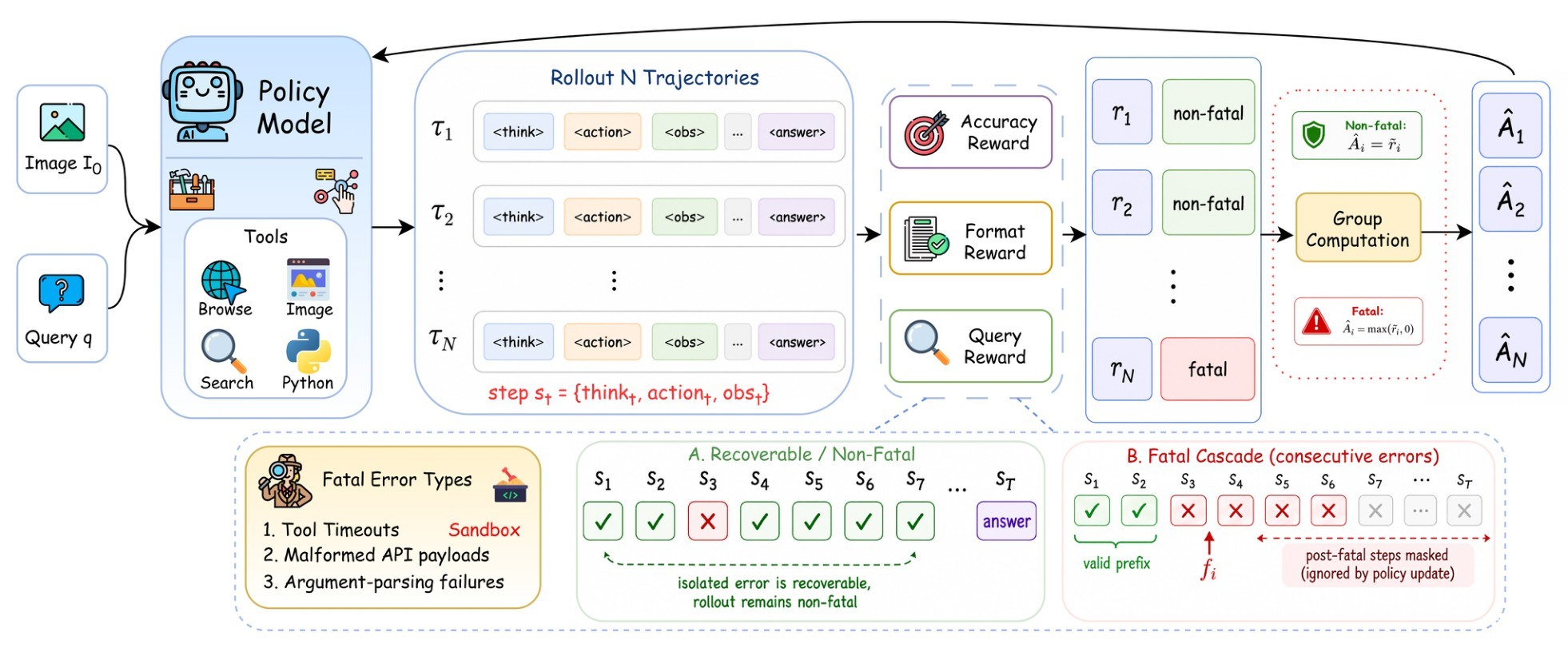
The paper's fatal-state logic is concrete: a trajectory becomes fatal after \(K=3\) consecutive tool-execution errors, including malformed calls, timeouts, or argument-parsing failures. The token mask then keeps generated tokens before the fatal step and zeros out post-failure generated tokens:
The advantage rule keeps ordinary GRPO advantages for non-fatal trajectories but clamps fatal trajectories to avoid negative gradients on potentially useful prefixes:
The final objective is the search-augmented GRPO surrogate over the multimodal environment \(\mathcal{E}\), with the fatal-aware mask \(M_{i,t}\) and the clamped advantage \(\hat{A}_i\):
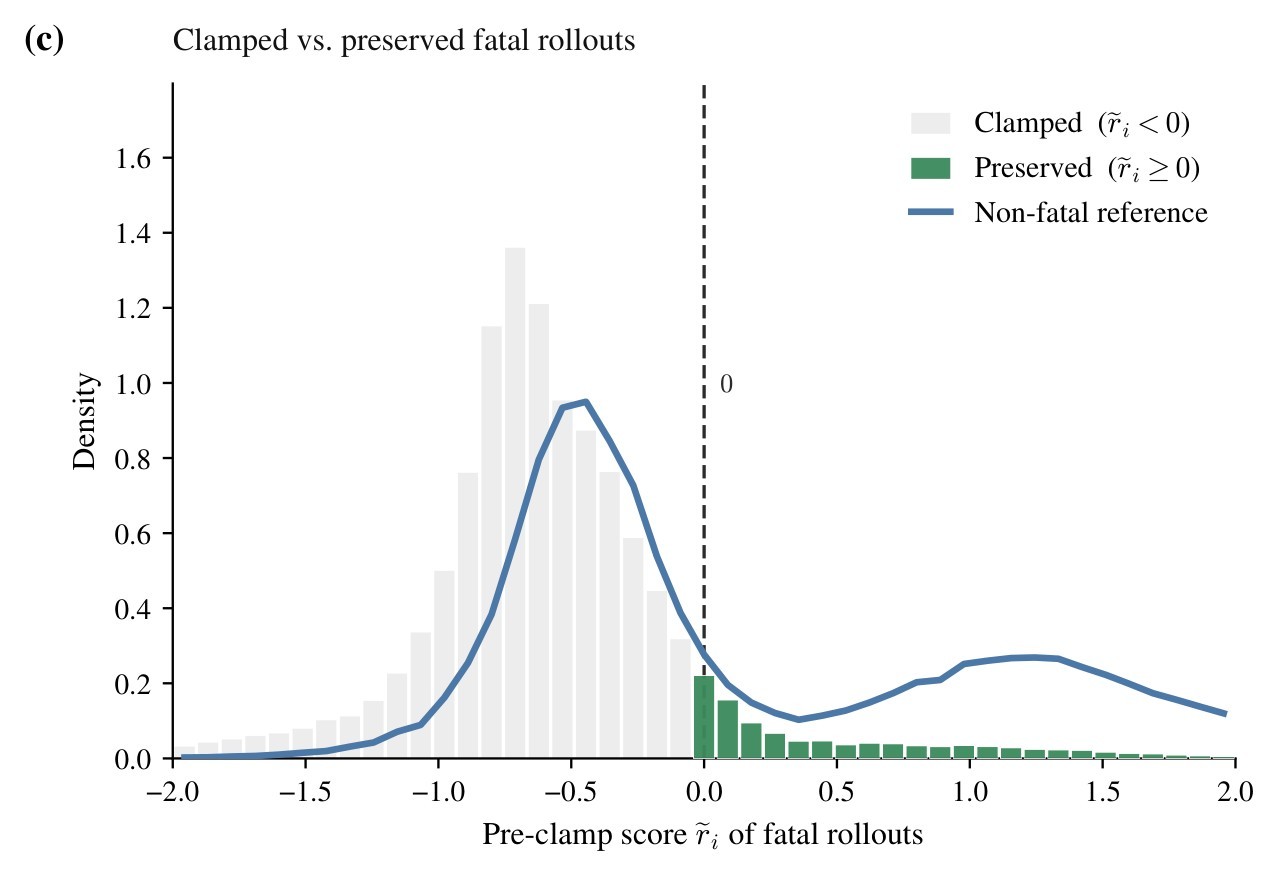
The key mathematical move is not only the mask. The appendix derives group normalization over all \(G\) rollouts, including fatal ones, then applies the one-sided clamp only when assigning fatal-trajectory advantages. This creates a non-negative bias for fatal trajectories, which the authors explicitly acknowledge, but they argue it is benign because most fatal trajectories are clamped to zero and the preserved tail overlaps the high-score regime of non-fatal rollouts. The aggregate visualization in Figure 5 is the paper's empirical sanity check for that argument.
Experiments And Results
The evaluation covers seven knowledge-intensive multimodal search benchmarks: SimpleVQA, VDR, MMSearch, LiveVQA, BrowseComp-VL, FVQA, and InfoSeek. Baselines are grouped into direct reasoning, RAG workflow, and agentic workflow. Correctness is judged by a GPT-4o prompt aligned with the VDR-style evaluation protocol. Table 4 condenses the main benchmark table around the key comparisons.
| Comparison | Avg Pass@1 | Main interpretation |
|---|---|---|
| GPT-5 direct reasoning | 45.1 | Strong closed baseline without an explicit agent loop. |
| Gemini-2.5-Pro direct reasoning | 46.0 | Best direct-reasoning average in the source table. |
| GPT-5 RAG workflow | 53.6 | Retrieval helps, but the workflow is still not the trained OpenSearch-VL agent. |
| SenseNova-MARS-8B agentic | 52.7 | Strongest prior 8B-scale open agentic baseline in the table. |
| OpenSearch-VL-8B | 56.6 | Beats SenseNova-MARS-8B by 3.9 average points. |
| Qwen3-VL-30B-A3B agentic baseline | 47.8 | Same model family before the OpenSearch-VL recipe. |
| OpenSearch-VL-30B-A3B | 61.6 | Improves the corresponding Qwen3-VL agentic baseline by 13.8 average points. |
| Qwen3-VL-32B agentic baseline | 48.0 | Same model family at 32B. |
| OpenSearch-VL-32B | 63.7 | Highest average in the source table. |
Table 4. Main result digest. The source table also reports per-benchmark values; for the 30B-A3B comparison, the paper highlights gains of +13.3 on VDR, +24.5 on MMSearch, +10.2 on FVQA, and +16.2 on InfoSeek.
The result pattern is consistent with the paper's thesis: plain direct reasoning is weaker than retrieval-augmented settings, but the largest gains come from a trained agentic loop with visual tools and RL. The 8B model already beats the listed 8B agentic baselines, and the 30B/32B variants exceed the corresponding Qwen3-VL agentic baselines by double-digit average margins.
The ablations in Table 5 are especially important because they test the recipe components rather than only the final benchmark score.
| Ablation family | Setting | Avg score | Delta / conclusion |
|---|---|---|---|
| SFT data | Full pipeline | 64.6 | Reference pipeline. |
| SFT data | Without source-anchor grounding | 53.1 | -11.5, shortcut-resistant grounding matters. |
| SFT data | Without fuzzy entity rewriting | 54.3 | -10.3, entity leakage is a major risk. |
| SFT data | Without staged filtering | 56.4 | -8.2, easy examples dilute the target behavior. |
| SFT data | Without enhancement subset | 63.3 | -1.3, image repair improves robustness but is not the main gain. |
| RL recipe | Qwen3-VL-8B baseline | 53.7 | Pre-SFT baseline. |
| RL recipe | + SFT only | 64.6 | SFT provides the largest first jump. |
| RL recipe | + Vanilla GRPO | 67.6 | Online exploration helps. |
| RL recipe | + Hard masking | 67.7 | Nearly flat relative to vanilla GRPO. |
| RL recipe | + Fatal masking only | 69.1 | Prefix preservation helps. |
| RL recipe | + Fatal masking + one-sided clamp | 71.8 | Best reported 8B ablation, +4.2 over vanilla GRPO. |
Table 5. Ablation digest. The top panel supports the data-pipeline design, and the bottom panel supports fatal-aware RL over vanilla or hard-masking variants.
The training curves in Figure 3 reinforce the ablation table by showing that fatal-aware GRPO maintains longer rollouts while reaching higher batch-level accuracy than vanilla GRPO and hard masking.
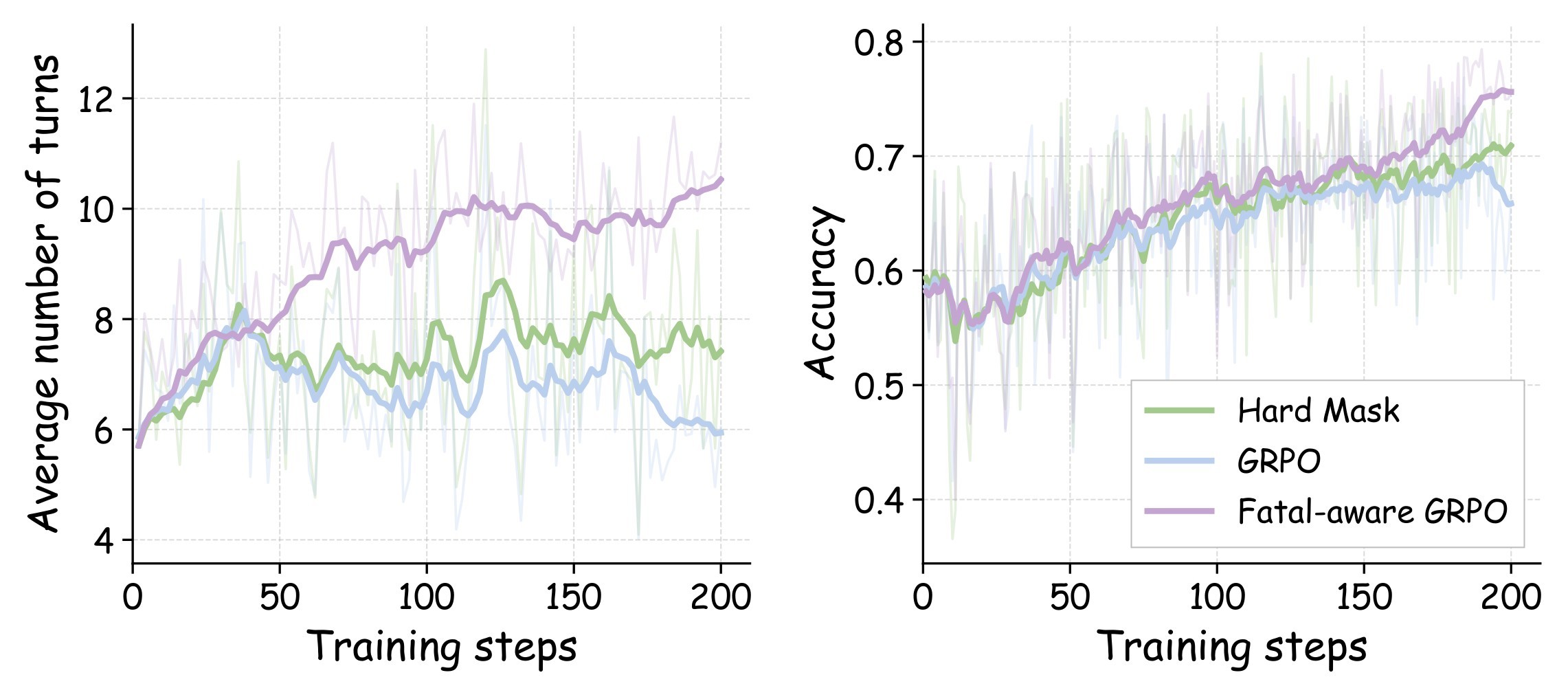
Figure 4 gives the intuition behind the one-sided clamp. In harder groups, some fatal prefixes still exceed the group mean and should be reinforced. In easier groups, fatal rollouts are below the successful rollouts and get zeroed rather than negatively training against their prefix.
The case study in Figure 7 shows the intended runtime behavior: crop first, image search to identify the bridge, then text search to verify the opening year. This is a qualitative example rather than benchmark evidence, but it makes the "verify, do not guess" behavior concrete.

The limitations section is candid about several remaining risks. The tool environment can drift because web search ranking, fetching, and summarization can fail or change. The composite reward uses proprietary GPT-4o/GPT-5.4-style judges, which makes cost, version dependence, and open reproducibility concerns real. The query-quality reward scores textual query behavior and does not fully judge visual operations such as crop quality. Finally, the paper does not report multi-seed error bars for the large-scale runs, so the source table supports the reported recipe but not fine-grained variance claims.
Practical Takeaways
For builders of multimodal search agents, the paper's most useful takeaway is that data design and environment design are inseparable. If the dataset can be solved by entity-name leakage or one reverse-image call, RL will optimize the wrong behavior. OpenSearch-VL therefore makes the visual anchor useful but not answer-revealing, filters out no-tool and one-tool examples, and uses process judges to select trajectories that actually chain tools.
The second takeaway is that retrieval-only agents are incomplete for real images. The tool suite treats crop, OCR, sharpening, super-resolution, and perspective correction as first-class actions, not preprocessing hacks. That is a practical design choice for documents, signs, charts, screenshots, and low-quality photos where the agent must repair perception before it can retrieve facts.
The third takeaway is about RL failure handling. In long-horizon tool environments, a rollout can contain useful early reasoning followed by an unrecoverable tool-error cascade. Hard-discarding the rollout wastes data, while training on the suffix injects noise. Fatal-aware masking plus one-sided clamping is a pragmatic compromise: keep useful prefixes, suppress invalid suffixes, and never push the model away from a valid prefix simply because later tool calls failed.
The fourth takeaway is cautionary. The recipe is operationally heavy: large GPU counts, online tools, external APIs, and proprietary judges all appear in the source. The paper is valuable as a detailed recipe and internal evidence package, but exact reproduction will depend on whether the released code/data/models and tool stack match the paper's described environment.
Reference Coverage
Anchor coverage links: open recipe, data pipeline, tool environment, training setup, fatal-aware GRPO, key equations, main results, ablation, case study, limitations, Table 1, Table 2, Table 3, Table 4, Table 5, Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, and Figure 7.