Source-first digest for monthly 2026_05 rank 17, rank_id p043.
- Routing status:
success - Extraction route:
full_markdown - PDF extraction: not used
Motivation / Background
The paper argues that interactive video world models need a broader evaluation contract than ordinary text-to-video systems. A useful interactive world model has to render plausible video, initialize the requested world, execute user controls, remember state over turns, and obey physical or causal constraints. The authors frame these as five game-engine-like roles: renderer, director, controller, memory, and engine. Existing benchmarks cover parts of this stack, but not the whole combination of open-domain scenes, first- and third-person perspectives, multiple interaction types, multi-turn state, and physics.
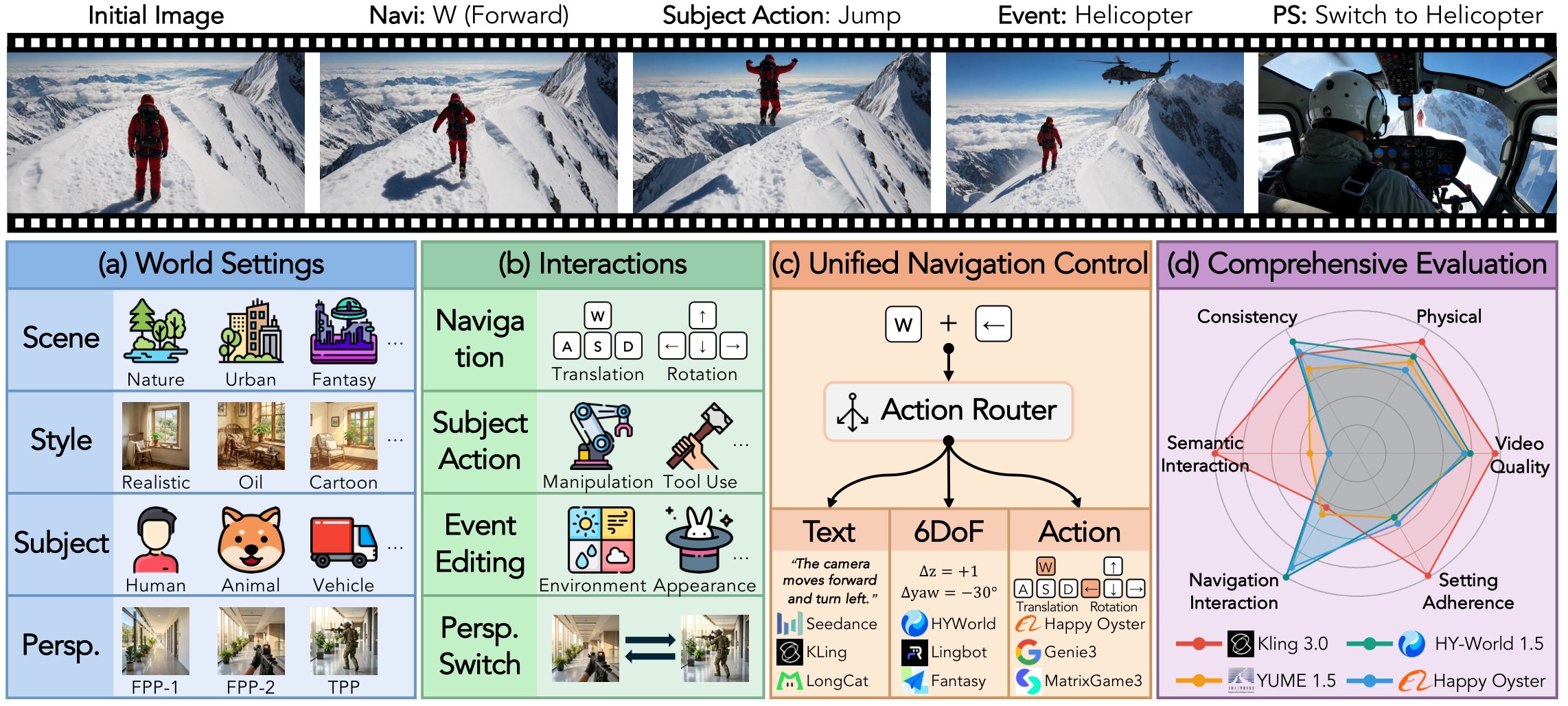
Figure 1 is the paper's compact thesis: a benchmark case should specify both the world setting and a multi-turn interaction sequence, then evaluate not just the final clip quality but whether each requested turn remains controllable and coherent.
| Benchmark family | Main coverage | Missing piece relative to WBench |
|---|---|---|
| Video-generation suites such as VBench | Visual quality, perceptual realism, text alignment | No action input or multi-turn interaction |
| World-model suites such as MIND / WorldMark | Navigation or memory-oriented interaction | Limited semantic interactions, perspective coverage, or physics scope |
| Autonomous-driving or robotics suites | Domain-specific control and dynamics | Not open-domain, not both first- and third-person |
| WBench | Text, camera, and action inputs; FPP and TPP; navigation, subject action, event editing, perspective switching; quality, setting, interaction, consistency, physics | The paper still limits itself to discrete action sequences rather than continuous control |
Table 1. Benchmark-coverage framing. This digest table condenses the source benchmark-comparison table and related-work discussion. The key gap is unified evaluation of multi-turn interactive video, not simply another video-quality leaderboard.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | WBench fills a real benchmark gap by jointly covering open-domain settings, both perspectives, four interaction types, multi-turn evaluation, and five evaluation dimensions. | 5 | problem framing, dataset design, evaluation suite, benchmark coverage table |
| C2 | The dataset is broad enough to expose different failure modes: 289 cases, 1,058 turns, 2-9 turns per case, multiple scenes, styles, subjects, and interaction subtypes. | 5 | dataset design, dataset statistics table, dataset distribution figure |
| C3 | The navigation design is a meaningful cross-paradigm bridge because text, 6-DoF pose, and discrete keyboard controls are aligned to the same underlying action semantics. | 5 | navigation design, navigation action table, navigation definition figure |
| C4 | The evaluation suite is not one scalar metric; it uses 22 sub-metrics across video quality, setting adherence, interaction adherence, consistency, and physics compliance. | 5 | evaluation suite, metric summary table, NavScore equations |
| C5 | Across 20 models, no model dominates all dimensions; text-driven models lead setting and physics, while native-control world models lead navigation. | 5 | experiment protocol, key results table, results pattern |
| C6 | Navigation is structurally decoupled from rendering, consistency, and physical compliance, so high video quality does not imply controllable motion. | 5 | cross-dimension analysis, correlation figure, turn degradation figure |
| C7 | The automatic metrics are reasonably aligned with human preference at model-ranking granularity, with Spearman correlations at least 0.94 across ten aspects. | 5 | human validation, human alignment figure, human platform figure |
| C8 | The benchmark is strong but not complete: it focuses on discrete actions, still relies partly on LMM-based physical judging, and needs broader domains and real-time evaluation. | 4 | limitations |
Support scores are support-from-paper scores, not independent reproduction scores. A score of 5 means the claim is directly backed by source definitions, figures, tables, or experiments. A score of 4 means the paper gives substantial evidence but the claim still depends on benchmark design choices or automated judges.
Core Technical Idea
WBench treats an interactive world model as a conditional generator:
The benchmark decomposes each case into a world setting \(\mathcal{W}\), which fixes the initial world state \(o_0\), and an interaction sequence \(\mathcal{I}=(a_0,a_1,\ldots,a_{T-1})\), which specifies what the user does across consecutive turns. This separation is the important technical move: failures can be attributed to wrong initialization, wrong action execution, poor memory, or poor physics rather than collapsed into a generic video score.
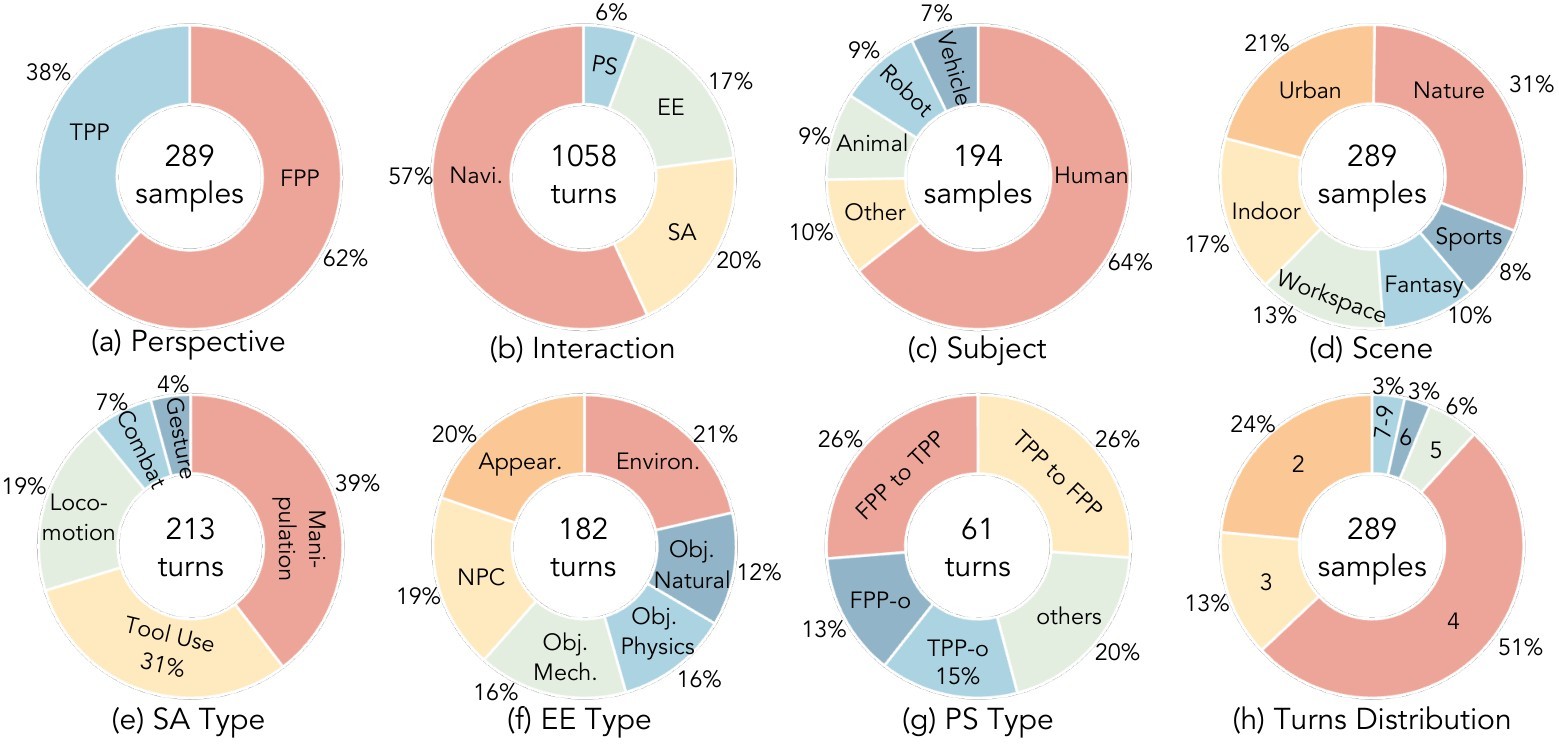
Figure 2 shows the dataset distribution, and Table 2 gives the digest-scale summary.
| Dataset axis | Value |
|---|---|
| Total cases / turns | 289 cases / 1,058 turns |
| Turns per case | 2-9 turns, average 3.7 |
| Perspective split | 62% first-person, 38% third-person |
| Interaction split | 57% navigation, 20% subject action, 17% event editing, 6% perspective switching |
| Scene split | Nature 31%, urban 21%, indoor 17%, workspace 13%, fantasy 10%, sports/game 8% |
| Explicit-subject cases | 194 cases |
| Subject split | Human 64%, animal 9%, robot 9%, vehicle 7%, miscellaneous object 10% |
| Style split | 52% photorealistic, 48% other styles including anime, cartoon, CG, oil painting, ink wash, pencil sketch, flat, and abstract |
| Longer sequences | 12% of cases have 5-9 turns, usually mixing subject action and event editing |
Table 2. WBench dataset statistics. The benchmark is designed to probe long-horizon state rather than single-shot prompt following.
The evaluation suite has five dimensions and 22 sub-metrics. All sub-metric scores are linearly rescaled to \([0,100]\), higher is better.
| Dimension | What it checks | Representative sub-metrics or mechanisms |
|---|---|---|
| Video quality | Perceptual quality independent of control | Aesthetic quality, imaging quality, temporal flicker, dynamic degree, motion smoothness, HPSv3-Norm |
| Setting adherence | Whether the generated video realizes the world setting | Scene adherence and subject adherence via VLM checks |
| Interaction adherence | Whether requested turns are executed | NavScore with pose estimation; event editing, subject action, and perspective switching via structured VLM protocols |
| Consistency | Whether identity, background, geometry, perspective, and continuity persist | Subject/background consistency, gated spatial consistency, segment continuity, perspective consistency, geometric and photometric consistency |
| Physical compliance | Whether events obey plausible physical and causal rules | Causal fidelity plus visual plausibility from a fine-tuned Qwen3-VL-30B-A3B judge |
Table 3. Evaluation suite. WBench is best read as a diagnostic grid. It deliberately keeps interaction, memory, and physics separate because they fail differently.
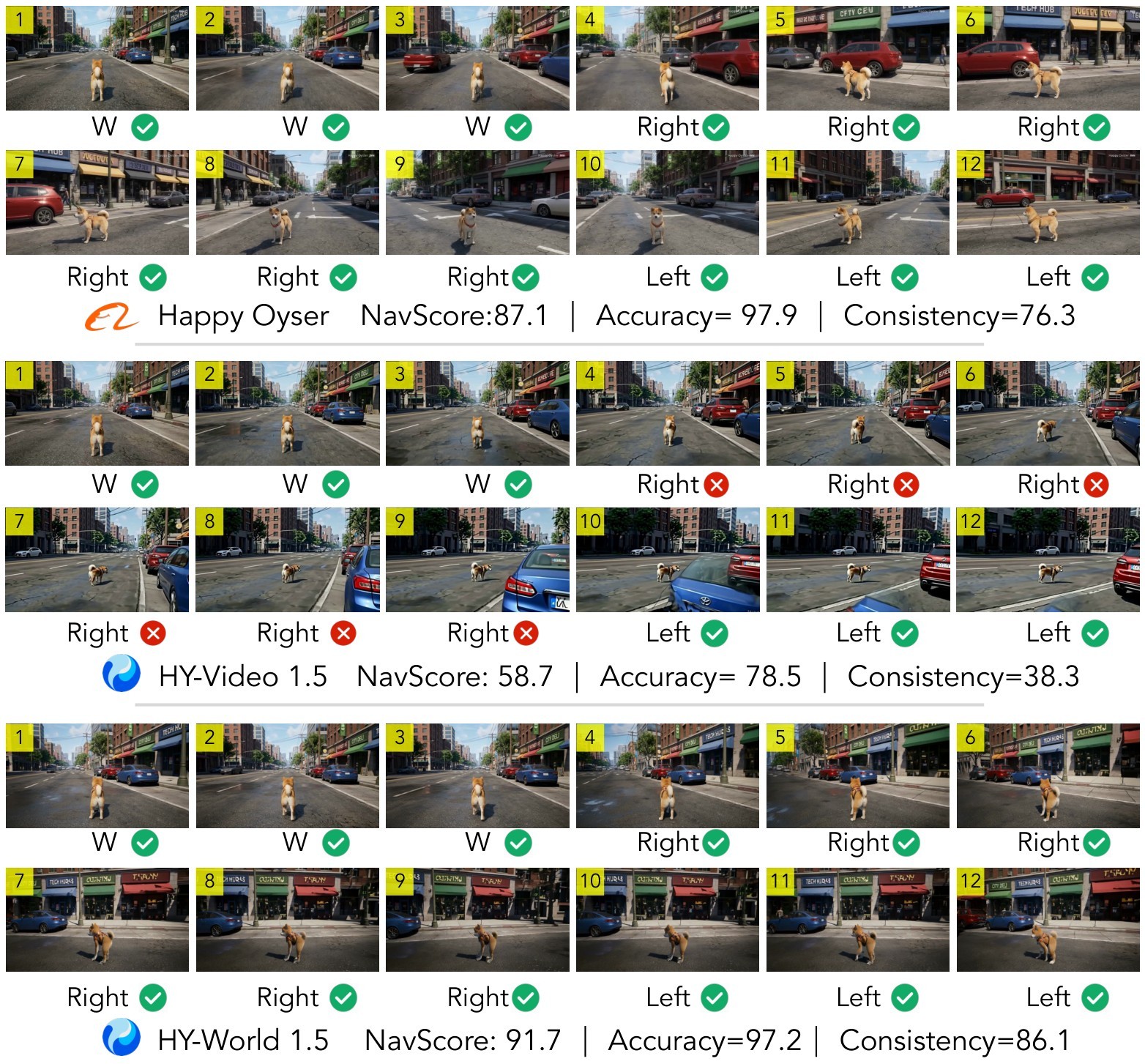
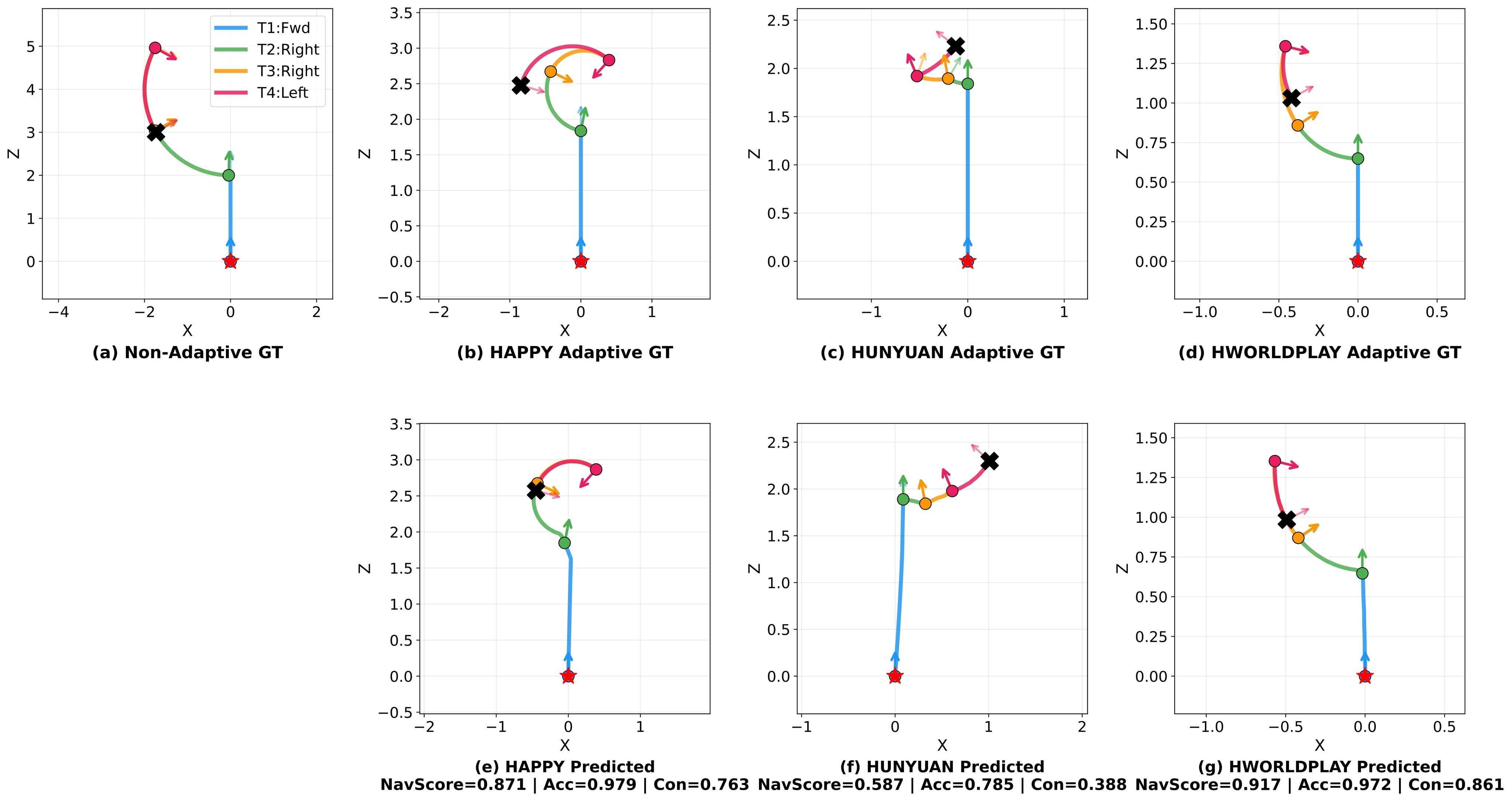
The most distinctive metric is NavScore, which compares estimated camera trajectories against synthetic ground-truth trajectories derived from the action sequence. The benchmark uses MegaSaM for camera pose estimation, then resamples both predicted and ground-truth trajectories to \(K=20\) arc-length points per turn. The normalized translation and rotation errors are:
For repeated or symmetric actions, WBench also computes cross-turn consistency:
The final navigation score is:
This design avoids treating scale mismatch as the only error. The adaptive ground truth follows each model's motion magnitude, then penalizes wrong direction or wrong shape, as illustrated in Figure 16.
Method Details
The dataset starts from world settings with four attributes: scene, style, perspective, and subject. Initial frames are generated or collected, then manually checked for quality and prompt-frame consistency. Interactions are setting-aware: annotators create physically executable, semantically coherent sequences, such as reasonable movement through a space or a weather transition in an outdoor scene.
Figure 6, Figure 7, Figure 8, Figure 9, and Figure 10 are the appendix galleries that make the coverage concrete rather than purely statistical.




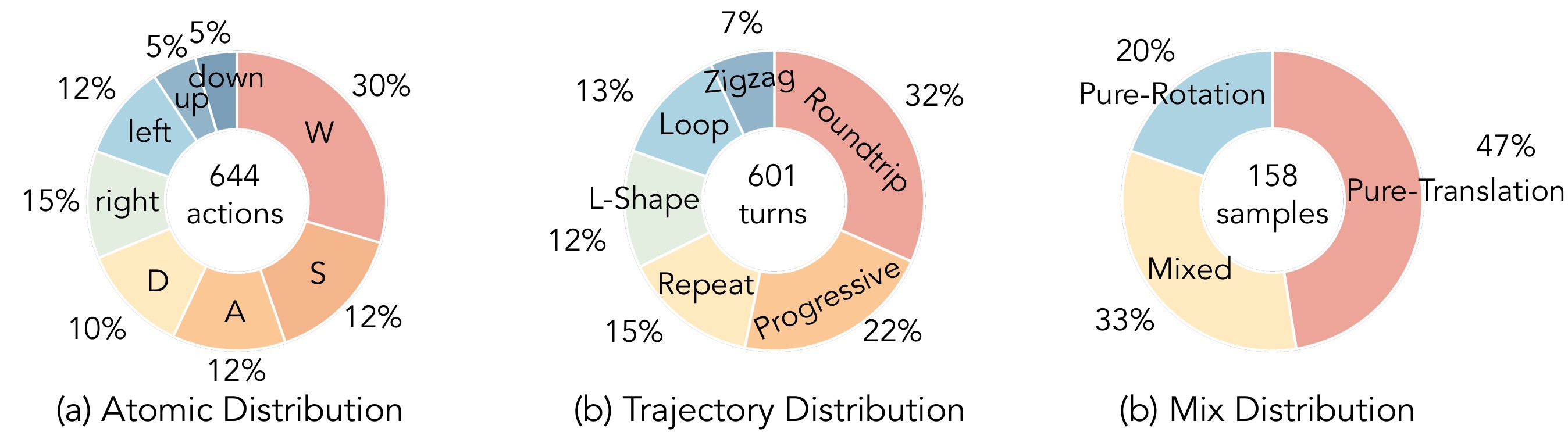
The interaction taxonomy has four top-level classes. Navigation uses translational W/S/A/D and rotational arrow-style controls. Subject action covers manipulation, locomotion, tool use, combat, and gestures. Event editing covers exogenous changes such as weather shifts, object appearances, time-of-day shifts, and object-state transitions. Perspective switching covers first-person to third-person transitions, third-person to first-person transitions, same-subject switches, multi-subject switches, and scope-mode transitions, shown in Figure 11.

The navigation design is perspective-dependent. The same key means camera motion in first-person mode but subject or orbital motion in third-person mode; Table 4 and Figure 12 capture that mapping.
| Type | Key | First-person semantics | Third-person semantics |
|---|---|---|---|
| Translation | W |
Camera pushes forward | Subject walks forward |
| Translation | S |
Camera pulls backward | Subject steps backward |
| Translation | A |
Camera strafes left | Subject moves left |
| Translation | D |
Camera strafes right | Subject moves right |
| Rotation | left |
View turns left | Camera orbits left |
| Rotation | right |
View turns right | Camera orbits right |
| Rotation | up |
View tilts up | Camera elevates |
| Rotation | down |
View tilts down | Camera descends |
Table 4. Navigation action semantics. The mapping is central to fair comparison because it lets text, pose, and action interfaces be evaluated against equivalent spatial intent.

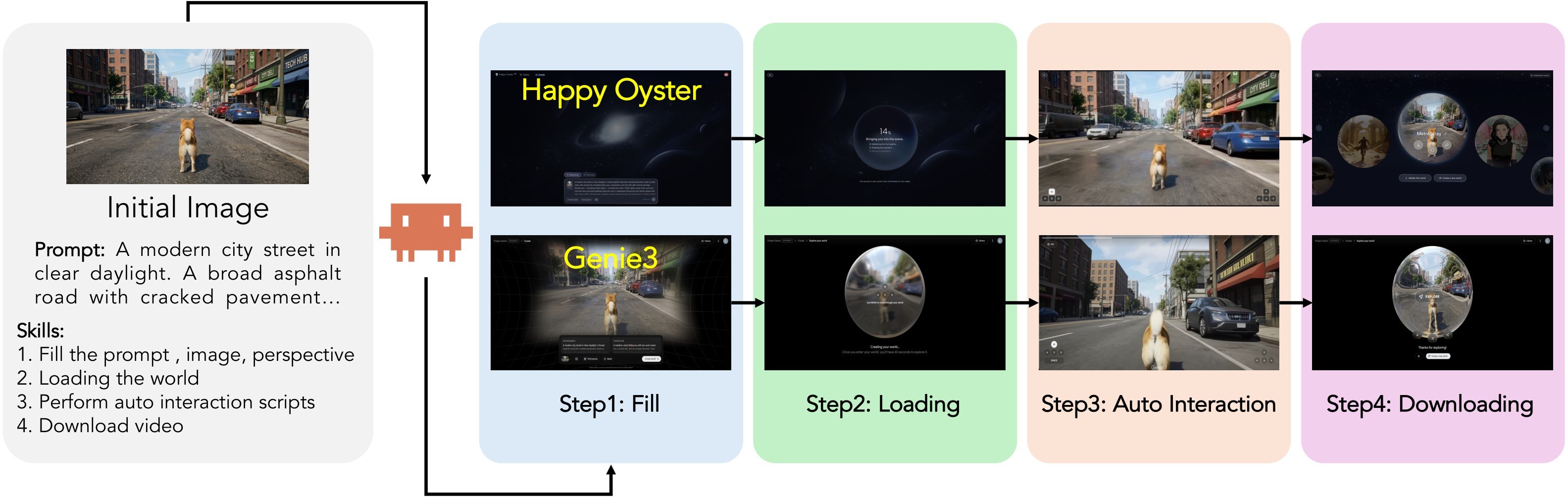
For web-only systems such as Genie 3 and Happy Oyster, the authors automate the web interface instead of changing the benchmark. Figure 14 shows the pipeline: fill prompt and image, wait for world loading, execute each 5-second turn, and download the recorded video.
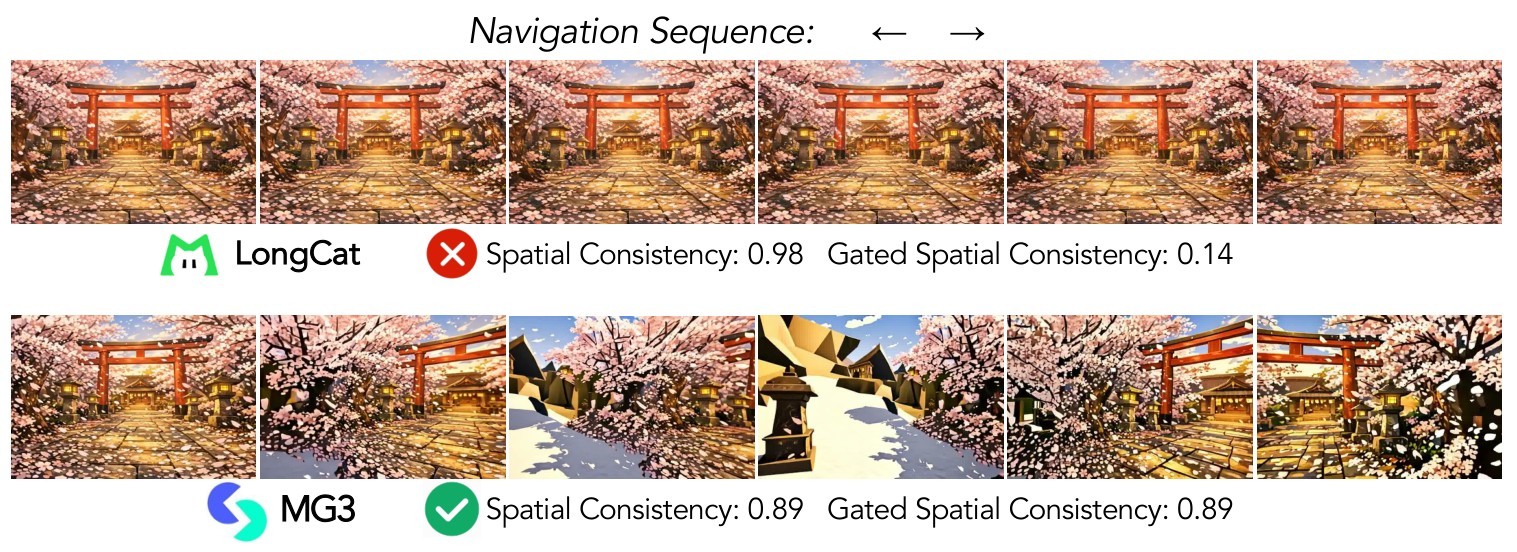
Several consistency and physics metrics are worth calling out because they guard against shortcut behavior. Gated spatial consistency penalizes a model that appears consistent only because it barely moves:
Perspective consistency tracks target centroids with SAM2 masks:
Reconstruction consistency uses depth and pose to back-project and reproject pixels:
It then measures geometric error and photometric agreement:
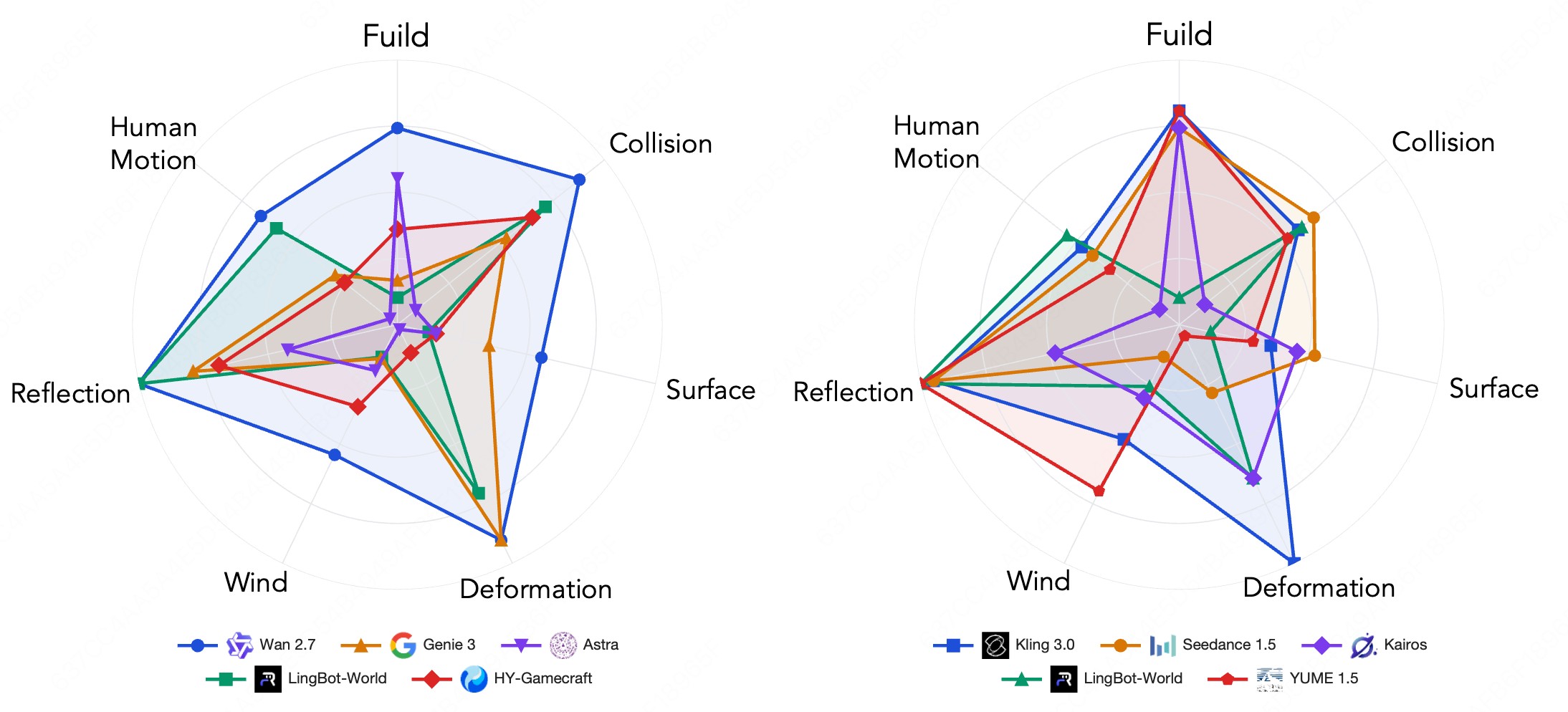
For physical compliance, causal fidelity uses a two-stage VLM protocol: global rendering-physics and causal-consistency scoring, then scene-aware scoring over selected sub-dimensions such as fluid/smoke, collision, surface tracks, deformation, wind, reflection, and human motion. Visual plausibility is a separate fine-tuned Qwen3-VL-30B-A3B score. The visual-plausibility head renormalizes probabilities over five rating tokens and takes their expected value:
Experiments And Results
The experiments evaluate 20 models across three paradigms. The text-driven group has 9 models and supports all four interaction types on the full 289-case split. The camera-controlled group has 5 models and the action-conditioned group has 6 models; both are restricted to the shared 158-case navigation subset. Semantic interactions are text-only and therefore only appear for text-driven systems.
| Result slice | Best / key value | Digest reading |
|---|---|---|
| Video quality | Seedance 1.5 average 82.1; Wan 2.7 average 81.5 | Visual quality is close to saturated and no longer the main bottleneck |
| Setting adherence | Wan 2.7 average 91.4; Kling 3.0 average 91.0 | Text-driven systems remain much stronger at broad world-setting following |
| Navigation, text-driven | YUME 1.5 reaches 72.0 | Navigation-specific tuning helps text-driven models but does not close the gap |
| Navigation, camera-controlled | HY-World 1.5 reaches 87.5; group average 76.0 | Native geometric control is strongest for camera movement |
| Navigation, action-conditioned | Happy Oyster reaches 85.1; Matrix-Game 3.0 reaches 83.5; group average 77.7 | Direct action interfaces are competitive with camera-control models |
| Semantic interactions | Kling 3.0 / Wan 2.7 lead event editing and subject action; perspective switching average is 30.7 | Promptable semantic edits are still hard, and perspective switching is the weakest semantic interaction |
| Consistency | LingBot-World average 89.9 | Camera-control and explicit state designs can excel at temporal and spatial consistency |
| Physical average | Wan 2.7 reaches 71.8; text-driven average 67.0 vs camera 64.2 and action 61.7 | Physical correctness appears more tied to broad generative priors than control specialization |
Table 5. Key result slices. These values come from the main results table and the per-dimension analysis. The paper's strongest conclusion is that different model families win different capabilities.
The paper's main result is not "model X wins." It is that interactive world modeling decomposes into partially independent skills. Text-driven models have broad semantic and physical priors. Camera- and action-conditioned models are better at motion control. Some models get high consistency partly by producing little motion, which is why gated spatial consistency matters.
Figure 3 shows the cross-dimension correlations and setting-level difficulty deviations.
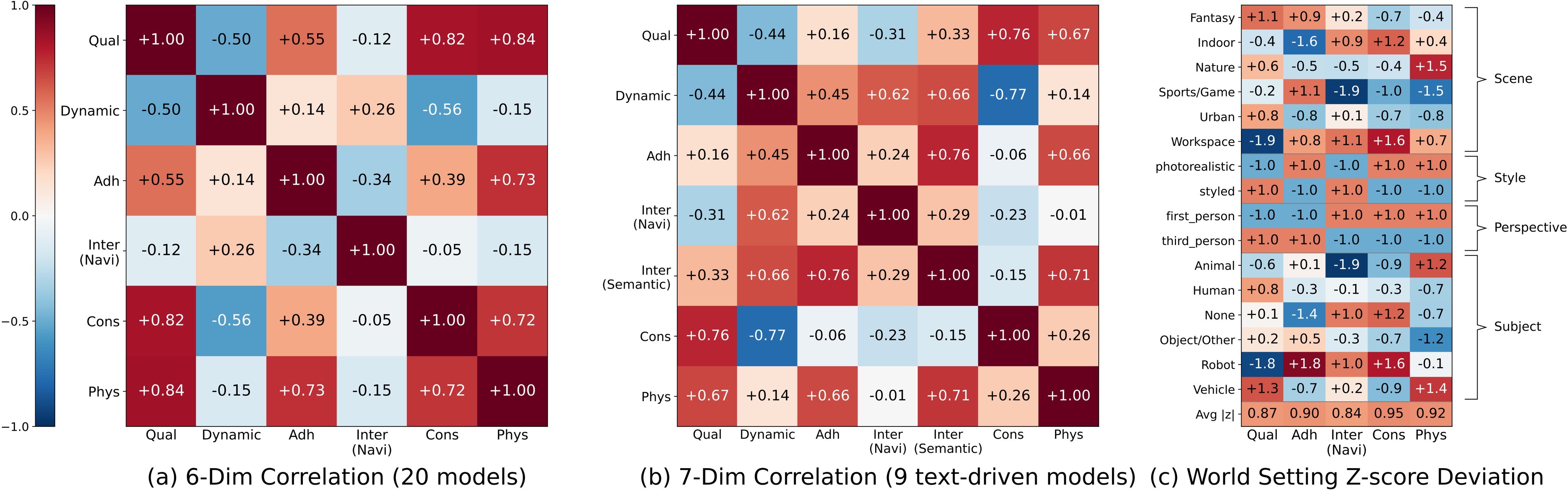
The strongest diagnostic points are:
- Navigation has near-zero correlation with video quality \((r=-0.12)\), consistency \((r=-0.05)\), and physical compliance \((r=-0.15)\).
- Physical compliance correlates with video quality \((r=0.84)\) and consistency \((r=0.72)\), but not navigation.
- For text-driven models, semantic interaction aligns more with setting adherence \((r=0.76)\) than navigation \((r=0.29)\).
- Camera control does not imply perspective consistency: HY-World 1.5 leads navigation but is only rank 8 among 11 world models on perspective consistency, and Matrix-Game 3.0 is navigation rank 3 but perspective rank 11.
- Structured difficulty is visible: first-person navigation is easier \((z=+1.0)\), sports/game scenes and animal subjects are harder \((z=-1.9)\), and workspace scenes and robot subjects are easier \((z=+1.6\) and \(z=+1.0)\).
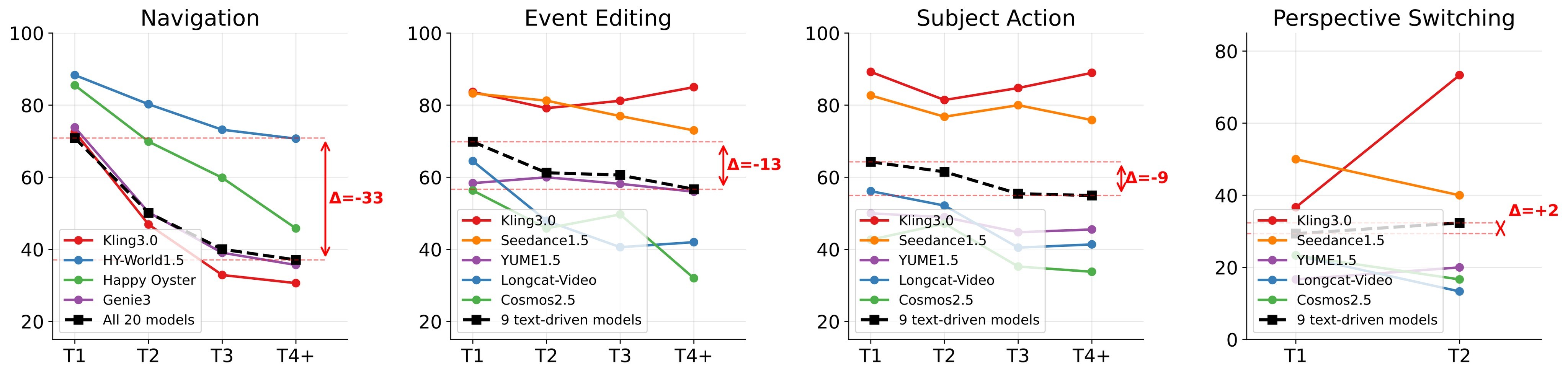
Figure 4 shows why the multi-turn part matters: navigation loses 33 points from turn 1 to turn 4+, while event editing and subject action fall by 13 and 9 points, and perspective switching stays low because its baseline is already weak.
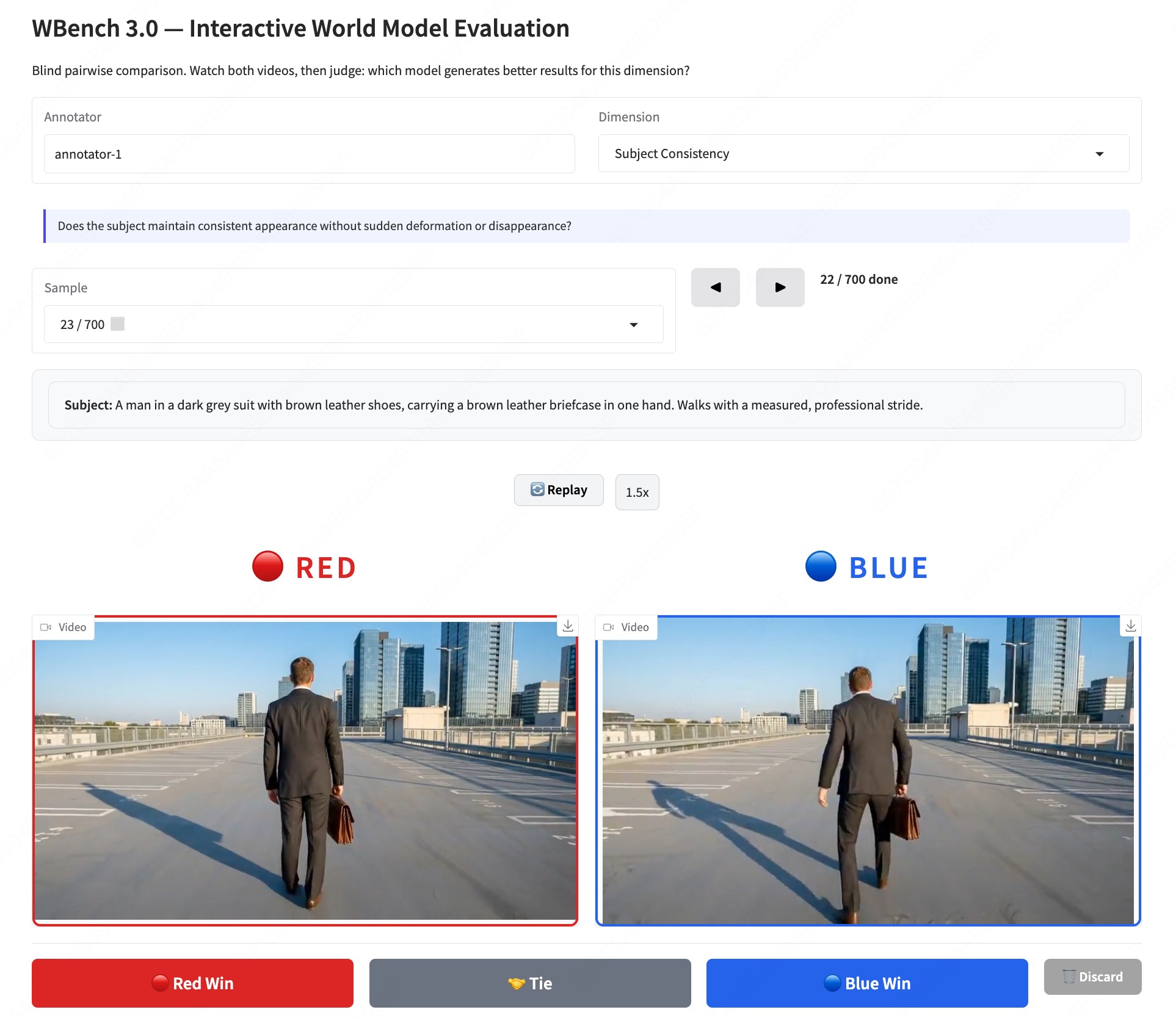
The human-alignment study recruits 400 crowdsourced annotators for blind pairwise comparisons across ten evaluation aspects. Ties count as 0.5 for each side, and per-model win rates are correlated against WBench scores. Figure 5 reports Spearman correlations of at least 0.94, with event editing, subject action, perspective switching, and spatial consistency reaching 1.00.

The qualitative figures show how the metrics behave on concrete cases. Figure 15 and Figure 16 explain navigation scoring. Figure 17, Figure 18, Figure 19, Figure 20, Figure 21, and Figure 22 cover semantic interaction, consistency, and physical compliance examples.




Practical Takeaways
- For benchmark users, WBench is most useful when the goal is diagnosing which part of interactive video world modeling fails: scene setup, control, memory, semantic editing, perspective, or physics.
- For model builders, the results argue against optimizing only video quality. Navigation is almost independent of video quality, and physical compliance follows different signals from control.
- For evaluation design, WBench's strongest idea is the dual-track navigation setup: one benchmark can compare text-prompted I2V, camera-conditioned generation, and discrete-action world models without forcing all systems into a single interface.
- For spatial-intelligence work, the hard cases are especially relevant: third-person control, sports/game scenes, animal subjects, long navigation sequences, and perspective switching expose subject-camera coupling failures.
- For deployment claims, the paper gives a caution: a model can look visually polished and still fail basic interaction or multi-turn controllability.
- Limitations: the current test set uses discrete action sequences rather than continuous control; physical compliance depends partly on LMM-based judging that may miss subtle effects; and the authors name broader domains plus real-time evaluation as future extensions.
Reference Coverage
All digest anchors are linked here as a final coverage check.
- Evidence anchors: problem framing, dataset design, evaluation suite, NavScore, navigation design, experiment protocol, results pattern, cross-dimension analysis, human validation, limitations.
- Table anchors: benchmark coverage, dataset statistics, evaluation suite, navigation actions, key results.
- Figure anchors: Figure 1, Figure 2, Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13, Figure 14, Figure 15, Figure 16, Figure 17, Figure 18, Figure 19, Figure 20, Figure 21, Figure 22, Figure 23.