Source-first digest for checked paper rank 1, rank_id p002.
- Routing status:
success - PDF extraction: not used
Motivation / Background
Embodied AI is still split across narrow model families: robot manipulation policies, navigation agents, egocentric human-motion predictors, and vision-language systems are often trained with different architectures, output conventions, and evaluation protocols. Qwen-VLA argues that these tasks share the same core conditional prediction problem: given visual context, language, and an embodiment/control description, predict a future action or trajectory sequence.
The paper's main move is to extend a strong Qwen3.5 vision-language backbone with a DiT-style flow-matching action expert, then train it over a heterogeneous mixture of robot, human, simulation, navigation, and vision-language data. The intended payoff is a single model that can switch between task families and robot embodiments through text prompts rather than task-specific heads; the full architecture is summarized in Figure 1.
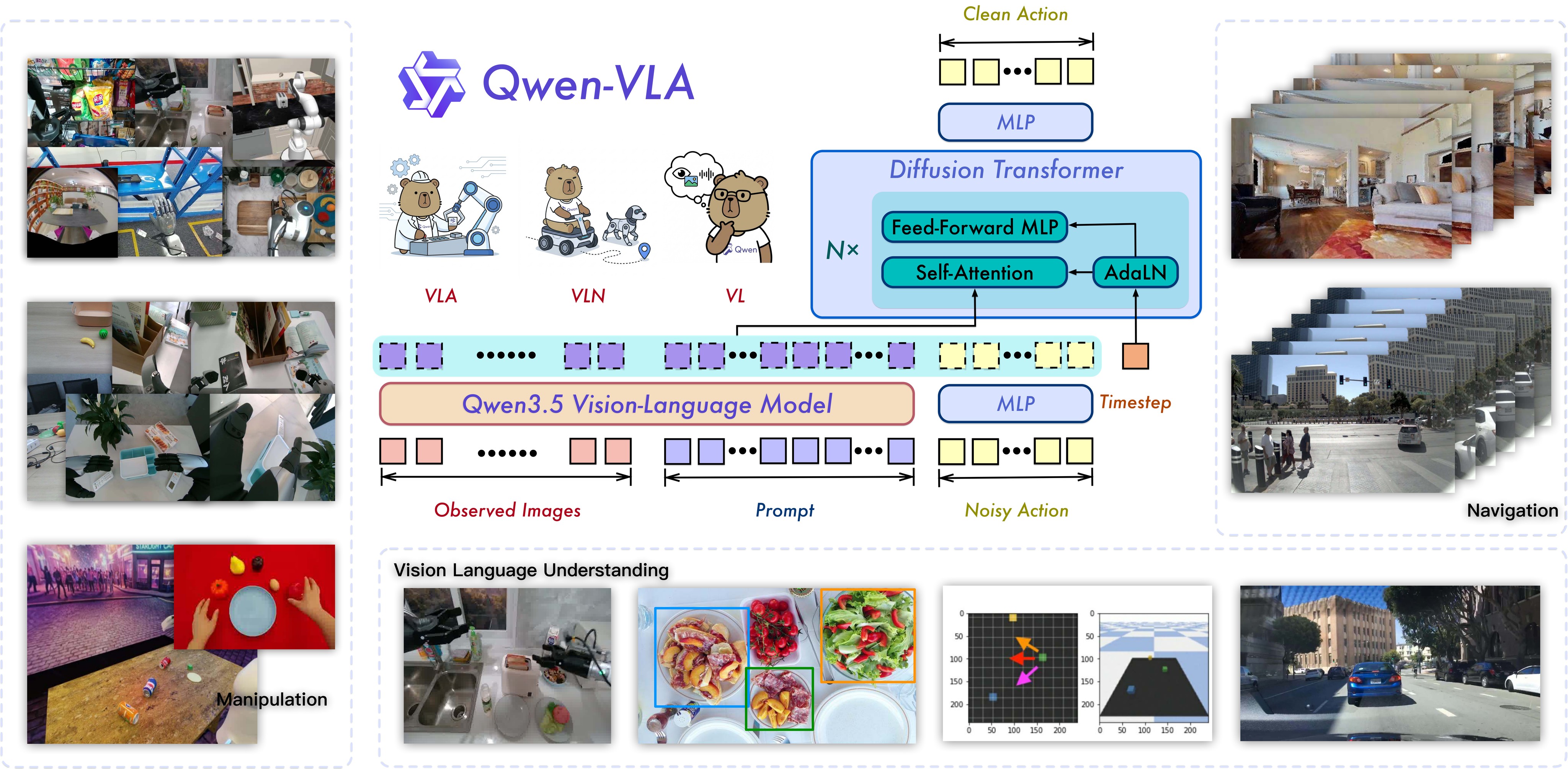
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Manipulation, navigation, egocentric action modeling, and trajectory prediction can be handled as one action-and-trajectory prediction problem with a shared VLM + action decoder. | 4 | overview, action interface, simulation manipulation, navigation |
| C2 | Embodiment-aware prompting plus a padded/masked action tensor lets one architecture cover different robot platforms, action dimensions, control rates, and horizons. | 4 | action interface, robot embodiments, projection ablation, state conditioning |
| C3 | The staged recipe, especially text-to-action DiT pretraining before visual grounding, improves action learning and downstream performance. | 5 | training recipe, T2A ablations, RL stages |
| C4 | Large-scale joint pretraining transfers to real ALOHA manipulation and improves out-of-distribution robustness. | 4 | data mixture, real ALOHA results, static OOD manipulation, real OOD qualitative evidence, limitations |
| C5 | A single generalist can match or exceed many specialist manipulation policies across several simulation benchmarks. | 5 | simulation manipulation |
| C6 | The same model family can compete in VLN-CE navigation and zero-shot dynamic manipulation. | 4 | navigation, DOMINO |
| C7 | Vision-language co-training helps difficult embodied tasks without obvious degradation on simpler action benchmarks. | 4 | VL co-training |
| C8 | Proprioceptive state is not essential for the reported RoboTwin setting; visual observations plus embodiment prompts are almost enough. | 3 | state conditioning |
Scores are support-from-paper scores, not independent reproduction scores. Broad deployment claims are capped below 5 when the evidence is strong but limited by benchmark scope, short-horizon evaluation, or single-platform real-world validation.
Core Technical Idea
Qwen-VLA has two modules:
- A Qwen3.5-4B multimodal backbone for image/video/language perception, grounding, and reasoning.
- A single-stream DiT-style flow-matching action expert that receives VLM hidden states plus a noisy action chunk and predicts a velocity field for denoising continuous actions.
At time step \(t\), all tasks are written as:
Here \(o_t\) is visual context, \(x\) is the task instruction, \(e\) is the embodiment/control prompt, and \(z\) is an optional task-family identifier. The target \(y\) is a future action or trajectory sequence: robot end-effector deltas, joint positions, navigation waypoints, human hand trajectories, or related structured motion.
The model does not claim that all robots share a physical action semantics. Instead, it standardizes the tensor interface. Each dataset keeps its native control convention; a sample uses the leading \(c\) channels of a fixed \(K\)-channel action tensor and masks the unused padded channels. The flow-matching action loss first averages error per active channel and then averages across active channels:
This is the core engineering pattern: keep the VLM/action decoder shared, put embodiment semantics in text, and make the continuous action side robust to different dimensions through padding, masks, and per-dataset normalization.
Method Details
Embodiment Prompting
Each training example is prepended with a prompt of this form:
The robot is{robot_tag}with{single arm / dual arms}[, waist][, and mobile base]. The control frequency is{FPS}Hz. Please predict the next{chunk_size}control actions to execute the following task:{ori_instruction}.
The prompt supplies platform, arm configuration, control convention, control frequency, and prediction horizon. Table 1 shows the range of robot and human embodiments represented by this interface. At deployment, the paper says the prompt can be swapped to describe a new physical robot while leaving the model architecture unchanged.
| Robot | Arms | Action type |
|---|---|---|
| WidowX | Single | \(\Delta\)EEF + G |
| Google Robot | Single | \(\Delta\)EEF + G |
| Franka Panda | Single / Dual | \(\Delta\)EEF + G; Abs Joint + G |
| ARX5 | Dual | \(\Delta\)EEF + G |
| Fourier GR-1 | Dual | \(\Delta\)EEF + G |
| Mobile ALOHA | Dual | \(\Delta\)EEF + G; Abs Joint + G |
| AgiBot A2-D | Dual | Abs Joint + G; Abs Joint + DH |
| Galaxea R1 | Dual | Abs Joint + G |
| AIRBOT MMK2 | Dual | Abs Joint + DH |
| TienKung | Dual | Abs Joint + G; Abs Joint + DH |
| Real Human | Dual | \(\Delta\)EEF from MANO |
Table. Representative robot embodiments. EEF means end-effector pose, G means gripper, DH means dexterous hand. This table supports the claim that the training corpus spans single-arm, dual-arm, dexterous, and human-motion formats.
Data Mixture
Table 2 shows that the pretraining mixture is dominated by robot manipulation but deliberately keeps navigation, synthetic simulation, and vision-language supervision in the same recipe.
| Data source | Proportion |
|---|---|
| Robot manipulation trajectories | 74.2% |
| Human egocentric trajectories | 6.0% |
| Navigation trajectories | 7.5% |
| Synthetic simulation trajectories | 3.7% |
| General vision-language data | 3.4% |
| Spatial grounding, 2D | 2.5% |
| Autonomous driving VQA | 2.4% |
| Fine-grained embodied action caption | 0.2% |
| Total | 100.0% |
The corpus is mostly action-bearing robot manipulation data, but it deliberately keeps non-action vision-language supervision in the mix. The paper's reason is that action data teaches control while VQA, captioning, spatial grounding, and navigation preserve perception, object vocabulary, spatial semantics, and instruction following. Table 3 illustrates the fine-grained action-caption supervision used to make language more operational.
The robot manipulation portion includes public real-robot datasets, in-house trajectories, simulation trajectories, and more than 10,000 hours of heterogeneous robot interaction. The egocentric data contributes future wrist and hand-articulation targets, including PCA-reduced hand-pose coefficients. The synthetic pipeline contributes both vision-conditioned and text-only action data. The navigation data contributes waypoint-style continuous decisions.
| Coarse label | Fine-grained action caption |
|---|---|
| Pick up, rotate, and place the ceramic bowl. | Step 1: Pick up the ceramic bowl from the right far edge. Step 2: Rotate the bowl clockwise for two full circles. Step 3: Place the bowl at the center of the table. |
Table. Fine-grained embodied action caption example. This table is included because it shows how the paper tries to bridge coarse task labels and richer action-language supervision.
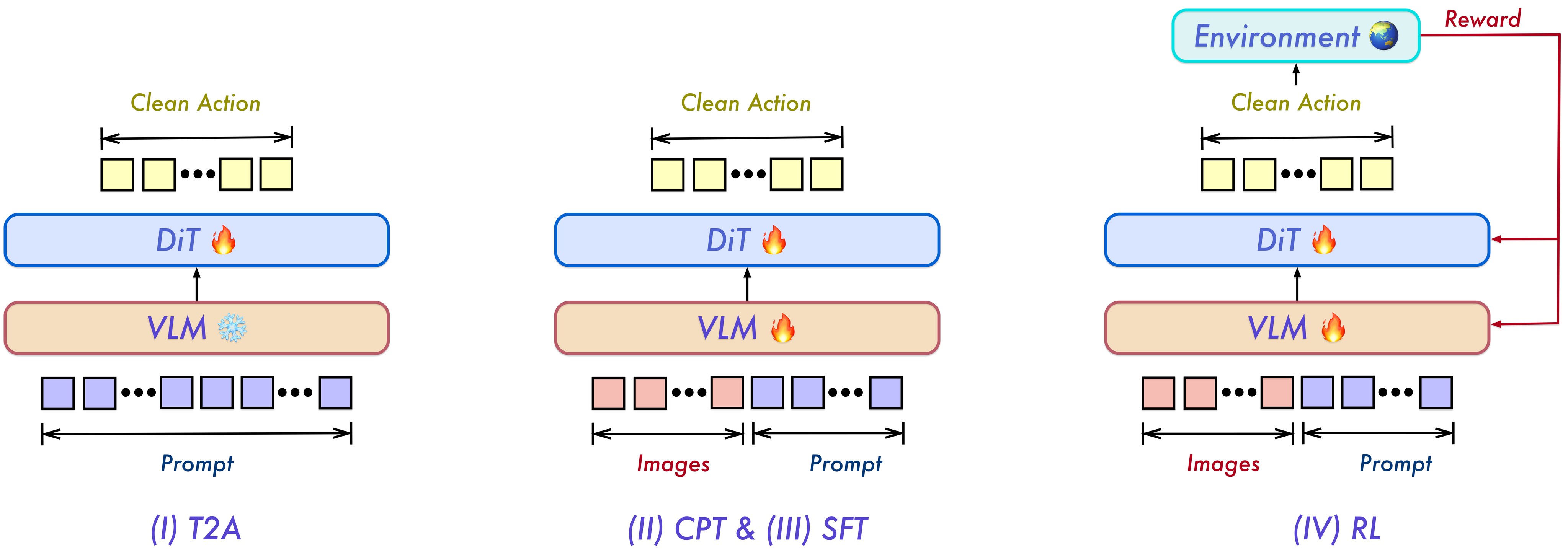
The staged recipe in Figure 2 is intentionally staged because the VLM is already pretrained but the action decoder starts random. The paper frames T2A as a "decompression" stage: a short language instruction and embodiment prompt must expand into a high-dimensional trajectory. Once the DiT has a language-indexed action prior, visual grounding can happen in CPT without making every early update pay the full cost of image conditioning.
Synthetic Simulation
Figure 3 shows how the synthetic data covers both short atomic manipulation tasks and longer compositional task sequences.
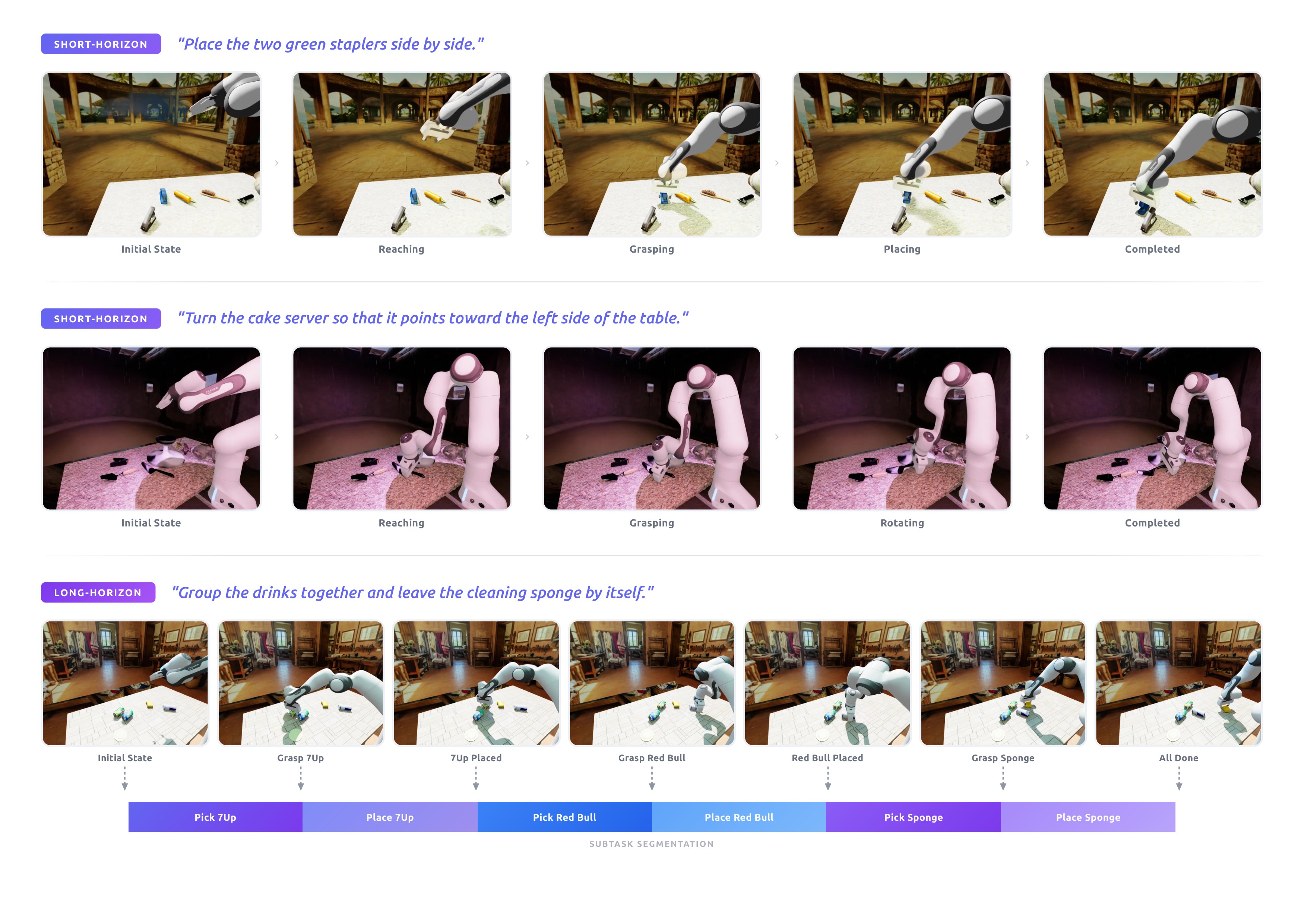
The synthetic vision-conditioned data uses an internal early version of RoboInF with IsaacLab and cuRobo. The paper reports 20 tabletop scenes, 10 object-pose configurations per scene, 450 manipulation tasks, 300 successful trajectories per task, and visual/control randomization. It also segments motion-planned trajectories into subtask trajectories, so the model sees both whole-task and intermediate-stage supervision.
Objectives And Post-Training
The joint pretraining objective combines continuous action flow matching with next-token vision-language loss:
After CPT, the paper defines Qwen-VLA-Base. SFT jointly fine-tunes on vision-language samples, navigation episodes, and manipulation demonstrations. The SFT weights are reported as 0.1 for vision-language next-token prediction and 1.0 for manipulation/navigation action prediction.
RL uses PPO with sparse binary success rewards in simulation. For the actor:
and the total loss is:
The paper calls out a nontrivial PPO detail: flow-matching policies do not expose autoregressive token probabilities. Qwen-VLA estimates log-probabilities by treating denoising transitions as Gaussian steps in a stochastic process, storing denoising states during rollout, and recomputing the velocity field under the current policy during PPO updates.
Experiments And Results
Simulation Manipulation
Table 4 compares Qwen-VLA against specialist manipulation policies across simulated manipulation benchmarks.
| Method | Type | LIBERO | RoboCasa-GR1 | Simpler-WidowX | RoboTwin-Easy | RoboTwin-Hard |
|---|---|---|---|---|---|---|
| \(\pi_0\) | Specialist | 94.4 | - | - | 65.9 | 58.4 |
| StarVLA-OFT | Specialist | 96.6 | 48.8 | 64.6 | 50.4 | - |
| GR00T N1.6 | Specialist | 97.2 | 49.9 | 63.2 | 47.6 | - |
| \(\pi_{0.5}\) | Specialist | 97.6 | 37.0 | 46.9 | 82.7 | 76.8 |
| ABot-M0 | Specialist | 98.6 | 58.3 | - | 86.0 | 85.0 |
| Being-H0.5 | Specialist | 97.6 | 53.3 | - | - | - |
| Qwen-VLA-Base | Generalist | 90.8 | 40.4 | 64.3 | 64.3 | 66.4 |
| Qwen-VLA-Instruct | Generalist | 97.9 | 56.7 | 73.7 | 86.1 | 87.2 |
Table. Robot manipulation results across benchmarks. Qwen-VLA-Instruct is best on Simpler-WidowX and both RoboTwin splits, second on LIBERO and RoboCasa-GR1. This directly supports C5.
The main nuance is that the paper compares a single generalist against specialists that are usually adapted per benchmark. The generalist claim is strongest where Qwen-VLA-Instruct wins or nearly matches the best specialist. It is weaker on RoboCasa-GR1, where ABot-M0 remains higher at 58.3 versus 56.7.
Real ALOHA Manipulation
Figure 4 shows the physical ALOHA task families, with in-domain and OOD results summarized in Table 5 and Table 6.

| Model | Pick and Place | Table Cleaning | Bowl Stacking | Bowl Pick and Place | Towel Folding | Fine-grained Manipulation | Avg. |
|---|---|---|---|---|---|---|---|
| GR00T N1.6 | 30.8 | 38.5 | 53.8 | 19.2 | 19.2 | 10.3 | 28.6 |
| \(\pi_{0.5}\) | 73.1 | 84.6 | 88.5 | 69.2 | 80.8 | 33.3 | 71.6 |
| Qwen-VLA-aloha, w/o pretrain | 30.8 | 53.8 | 61.5 | 64.1 | 50.0 | 30.8 | 48.5 |
| Qwen-VLA-aloha, w/ pretrain | 96.2 | 92.3 | 98.7 | 87.2 | 65.4 | 61.5 | 83.6 |
Table. Real-world in-domain performance. Fine-tuning from Qwen-VLA-Base raises the ALOHA average from 48.5 to 83.6, which is the paper's clearest real-world transfer evidence.
| Model | Color | Instance | Position | Background | Instruction | Avg. |
|---|---|---|---|---|---|---|
| GR00T N1.6 | 46.2 | 38.5 | 3.8 | 19.2 | 19.2 | 25.4 |
| \(\pi_{0.5}\) | 57.7 | 61.5 | 19.2 | 26.9 | 42.3 | 41.5 |
| Qwen-VLA-aloha, w/o pretrain | 42.3 | 30.8 | 34.6 | 30.8 | 42.3 | 36.2 |
| Qwen-VLA-aloha, w/ pretrain | 88.5 | 76.9 | 53.8 | 80.8 | 84.6 | 76.9 |
Table. Real-world OOD performance. The pretrained ALOHA variant is best in all five reported generalization categories. This supports the transfer claim, though the evidence is still one physical platform.
Navigation
Table 7 tests whether the same model family can operate in VLN-CE navigation rather than only robot manipulation.
| Method | R2R NE down | R2R OS up | R2R SR up | R2R SPL up | RxR NE down | RxR SR up | RxR SPL up | RxR nDTW up |
|---|---|---|---|---|---|---|---|---|
| NaVid | 5.7 | 49.2 | 41.9 | 36.5 | 5.7 | 45.7 | 38.2 | - |
| Uni-NaVid | 5.6 | 53.3 | 47.0 | 42.7 | 6.2 | 48.7 | 40.9 | - |
| NaVILA | 5.2 | 62.5 | 54.0 | 49.0 | 6.8 | 49.3 | 44.0 | 58.8 |
| StreamVLN | 5.0 | 64.2 | 56.9 | 51.9 | 6.2 | 52.9 | 46.0 | 61.9 |
| Qwen-VLA-Base | 5.2 | 61.7 | 53.8 | 49.4 | 6.4 | 55.1 | 45.8 | 56.2 |
| Qwen-VLA-Instruct | 5.1 | 69.0 | 57.5 | 51.2 | 5.8 | 59.6 | 47.8 | 57.1 |
Table. VLN-CE results. Qwen-VLA-Instruct leads R2R Oracle Success and Success Rate, and leads RxR SR/SPL. StreamVLN remains best on R2R NE/SPL and RxR nDTW, so the navigation claim is competitive rather than dominant.
Static OOD Manipulation
The SimplerEnv-OOD benchmark fine-tunes only on simple Bridge pick-and-place data, then evaluates unseen spatial relations, reversed color-object bindings, and novel manipulation primitives.
Table 8 isolates these static out-of-distribution manipulation shifts.
| Method | MoveAway | MoveRight | PlaceNear | PlaceRight | PutFront | StackYellow | Avg. |
|---|---|---|---|---|---|---|---|
| \(\pi_{0.5}\) | 26.1 | 0.0 | 0.0 | 32.1 | 13.0 | 4.2 | 12.6 |
| Qwen-VLA-Base | 31.3 | 31.6 | 16.7 | 47.1 | 6.3 | 18.8 | 25.3 |
| Qwen-VLA-Instruct | 43.8 | 33.3 | 39.6 | 47.9 | 4.2 | 22.9 | 32.0 |
Table. SimplerEnv-OOD. Qwen-VLA-Instruct improves the average from 12.6 for \(\pi_{0.5}\) to 32.0. The one exception is PutFront, where \(\pi_{0.5}\) is higher.
Dynamic OOD Manipulation
Table 9 evaluates zero-shot dynamic manipulation on DOMINO against both dynamic-data fine-tuned and zero-shot baselines.
| Method | Training category | SR % up | MS up |
|---|---|---|---|
| OpenVLA | Fine-tuned on dynamic data | 1.5 | 6.1 |
| RDT-1B | Fine-tuned on dynamic data | 5.3 | 17.7 |
| \(\pi_0\) | Fine-tuned on dynamic data | 8.2 | 24.0 |
| \(\pi_{0.5}\) | Fine-tuned on dynamic data | 9.6 | 26.2 |
| InternVLA-M1 | Fine-tuned on dynamic data | 5.4 | 27.6 |
| VLA-Adapter | Fine-tuned on dynamic data | 4.4 | 24.3 |
| \(\pi_0\)-FAST | Fine-tuned on dynamic data | 3.5 | 20.9 |
| OpenVLA-OFT | Fine-tuned on dynamic data | 9.1 | 24.1 |
| StarVLA-OFT | Fine-tuned on dynamic data | 10.9 | 30.5 |
| PUMA | Fine-tuned on dynamic data | 17.2 | 35.0 |
| OpenVLA-OFT | Zero-shot to dynamic manipulation | 6.7 | 20.0 |
| \(\pi_{0.5}\) | Zero-shot to dynamic manipulation | 7.5 | 20.4 |
| LingBot-VLA w/ depth | Zero-shot to dynamic manipulation | 11.8 | 26.7 |
| LingBot-VA | Zero-shot to dynamic manipulation | 24.1 | 36.1 |
| Qwen-VLA-Base | Zero-shot to dynamic manipulation | 21.1 | 37.4 |
| Qwen-VLA-Instruct | Zero-shot to dynamic manipulation | 26.6 | 39.5 |
Table. DOMINO. Qwen-VLA-Instruct is best overall in success rate and manipulation score. This is notable because the paper says it uses only current-frame observations and no dynamic-manipulation fine-tuning.
The qualitative ALOHA examples in Figure 5 show what the real-world OOD categories look like, but they should be read alongside the quantitative OOD table.

T2A And Training Ablations
Figure 6 is the main evidence for the staged text-to-action initialization recipe.
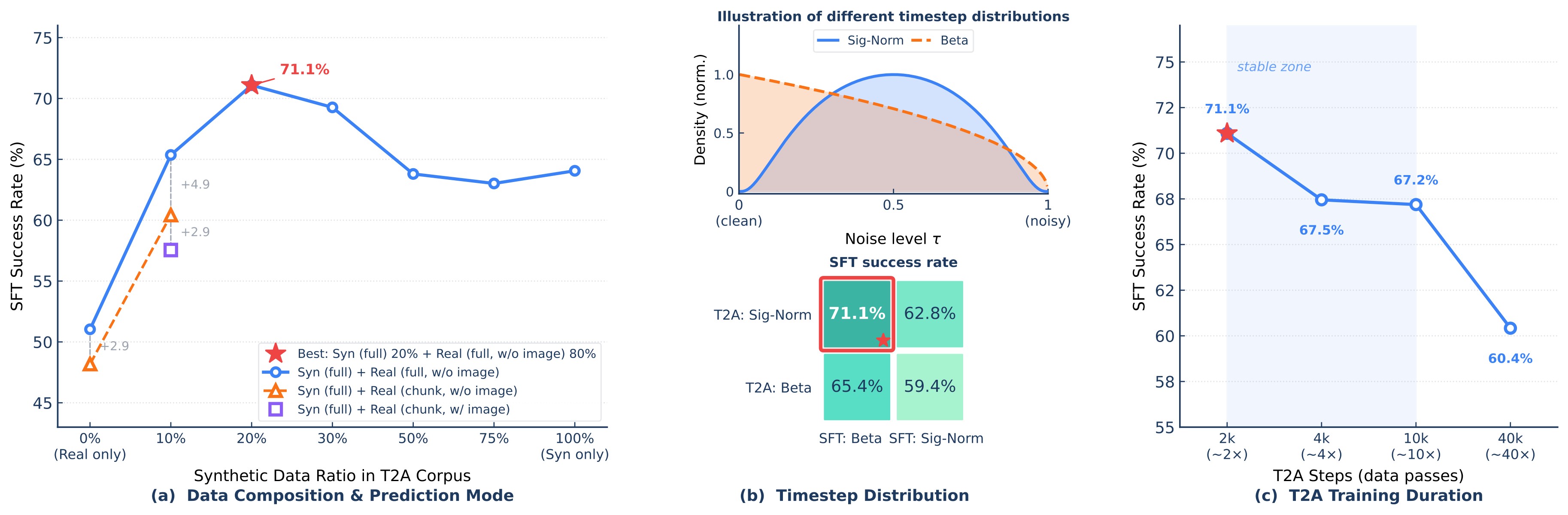
Key numbers from the text:
- Real-only T2A: 51.04%; synthetic-only T2A: 64.06%; about 20% synthetic + 80% real: 71.09%.
- At 10% synthetic, full-sequence prediction beats chunk prediction by 4.94 points.
- Including images during T2A hurts chunk-mode performance by 2.87 points.
- Sigmoid-Normal at T2A + Beta at SFT reaches 71.09%; swapping Beta into T2A drops to 65.36%; Sigmoid-Normal at SFT drops to 62.76%; Beta at both stages reaches 59.38%.
- Performance peaks at 2,000 T2A steps at 71.09%; 40,000 steps falls to 60.42%.
Figure 7 shows the effect of mixing vision-language data with VLA action training.
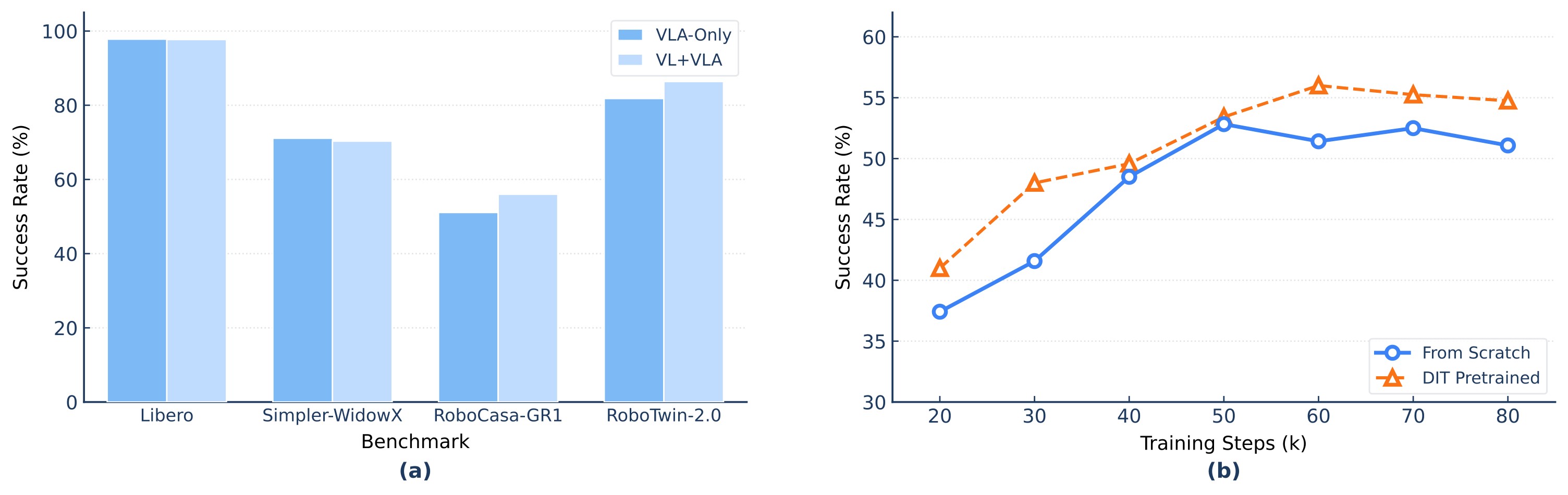
The projection design ablation in Table 10 motivates the paper's lightweight zero-padding interface.
| Benchmark | Bridge Only | Robocasa Only | Multi-MLP | Concat. | Zero-Pad |
|---|---|---|---|---|---|
| Bridge | 62.8 | - | 63.3 | 63.0 | 63.0 |
| Robocasa | - | 53.4 | 52.1 | 52.8 | 53.2 |
Table. Projection design ablation. Co-training is close to single-embodiment training. Zero-Padding is adopted because it is architecturally light: \(2h d_{max}\) projection parameters instead of \(2h\sum_i d_i\).
Table 11 separates the cumulative contribution of CPT, supervised fine-tuning, and RL.
| Stage | Simpler | RoboCasa | RoboTwin-E | RoboTwin-H | LIBERO | SimplerOOD | DOMINO SR | DOMINO MS |
|---|---|---|---|---|---|---|---|---|
| CPT | 64.3 | 40.4 | 64.3 | 66.4 | 90.8 | 25.3 | 21.1 | 37.4 |
| + SFT | 70.8 | 56.0 | 86.3 | 87.1 | 97.8 | 31.6 | 25.7 | 39.1 |
| + RL | 73.7 | 56.7 | 86.1 | 87.2 | 97.9 | 32.0 | 26.6 | 39.5 |
Table. Cumulative post-training effect. SFT contributes the large jump; RL adds smaller gains, especially on Simpler, and does not erase held-out performance in the reported table.
Table 12 is the narrow basis for the claim that explicit proprioceptive state is only marginally useful in this RoboTwin setup.
| Conditioning | RoboTwin-Easy | RoboTwin-Hard |
|---|---|---|
| No State | 88.7 | 87.4 |
| State in VLM Prompt | 89.3 | 88.7 |
| State in DiT | 89.4 | 88.3 |
Table. State conditioning ablation. Explicit proprioceptive state gives only marginal improvements in this setting. The evidence supports a narrow claim: on RoboTwin-2.0, the paper's visual setup plus relative action prediction makes extra state less important.
Practical Takeaways
- The most reusable idea is not simply "bigger VLA." It is the interface design: text specifies embodiment and control convention, while padded/masked continuous action tensors let one DiT handle different dimensions.
- The staged T2A recipe is the strongest method ablation. It gives a concrete recipe for initializing a continuous action decoder before expensive image-conditioned training.
- The evidence for broad generalist manipulation is strong in the reported benchmarks. The model is best or second-best across most simulation manipulation settings, and the real ALOHA pretraining comparison is substantial.
- Navigation is a credible but less dominant part of the story. Qwen-VLA leads several VLN-CE metrics but not all.
- The real-world evidence is promising but bounded: one ALOHA platform, mostly short-horizon categories, and benchmark-driven OOD slices.
- The paper itself notes open problems: long-tail contact-rich interactions, objective balancing between VL and action tasks, pure VL/navigation regressions, and long-duration deployment with memory, planning, and recovery.
The limitations section explicitly says embodied action data is still much smaller than vision-language pretraining data, joint VL/navigation/action optimization creates trade-offs, and evaluations remain short-horizon and benchmark-driven. Those caveats matter when interpreting the "unified embodied foundation model" framing.