Source-first digest for checked paper rank 4, rank_id p004.
- Routing status:
success - PDF extraction: not used
- Source-side table supplement: LaTeX table files were used where the Markdown conversion left empty table placeholders.
Motivation / Background
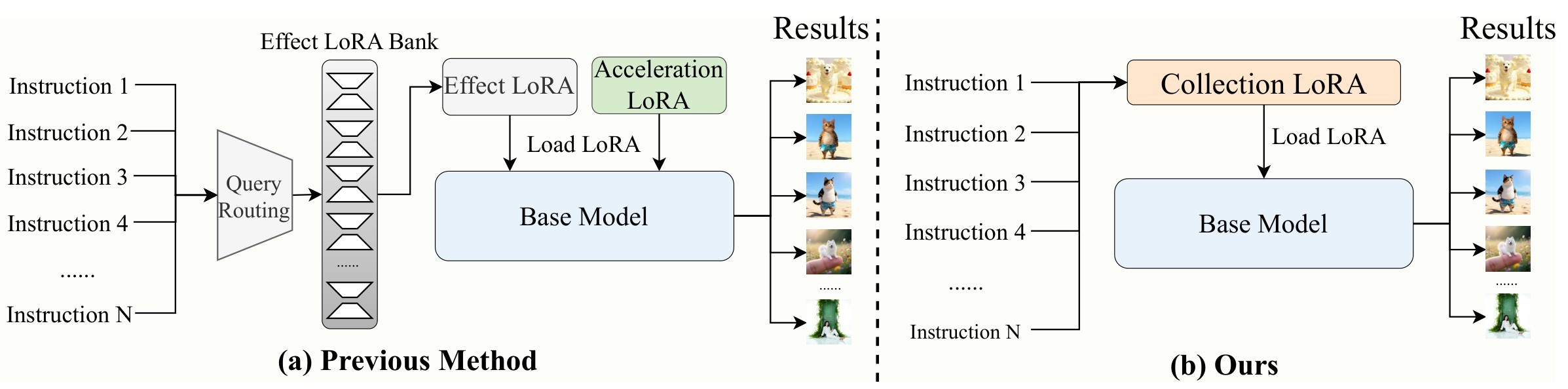
Customized image editing often uses one LoRA per visual effect, then cascades the chosen effect LoRA with an acceleration LoRA to get few-step generation. CollectionLoRA argues that this deployment pattern does not scale: storing many LoRAs increases memory cost, routing a prompt to the right LoRA adds latency and errors, and stacking effect plus acceleration LoRAs causes parameter interference that shows up as concept bleeding, semantic drift, and style degradation.
The paper's proposed replacement is to treat each single-effect LoRA as a teacher and distill the effects plus few-step inference behavior into one student LoRA. Figure 1 is the key motivation figure: the conventional path retrieves and composes modules at inference time, while CollectionLoRA turns the same bank into a single deployable adapter.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | A single CollectionLoRA can replace the 50-effect LoRA bank plus acceleration LoRA for the reported setting, removing runtime routing for 10-50 effects and keeping NFE at 8. | 5 | deployment paradigm, deployment cost, main quantitative results |
| C2 | The combination of PDSR, AOP, and C2F-DO is the main reason the multi-teacher student avoids concept collapse, over-smoothing, and catastrophic generalization loss. | 4 | framework, C2F behavior, ablation table, ablation visuals |
| C3 | On EffectBench, the 50-in-1 student matches or exceeds the reported single-effect teachers and naive multi-effect baselines on most quality and failure metrics. | 5 | main quantitative results, qualitative comparison |
| C4 | The approach scales beyond 50 effects and supports incremental extension, but the strongest scaling evidence is CLIP-only rather than a full metric suite. | 4 | scaling table, incremental table |
| C5 | CollectionLoRA has zero-shot two-effect composition ability. | 3 | composition figure |
| C6 | VSA/BCR and the user study indicate stronger subject consistency and style alignment than the baselines, with caveats from MLLM-based scoring and a 10-evaluator user study. | 4 | metrics setup, main quantitative results, user study |
Scores are support-from-paper scores, not independent reproduction scores. Claims with qualitative-only or narrow-metric evidence are capped below 5.
Core Technical Idea
CollectionLoRA rewrites deployment from "retrieve and compose LoRAs" into "sample one student LoRA conditioned by prompt-space effect identifiers." The baseline deployment equation is:
The proposed deployment equation is:
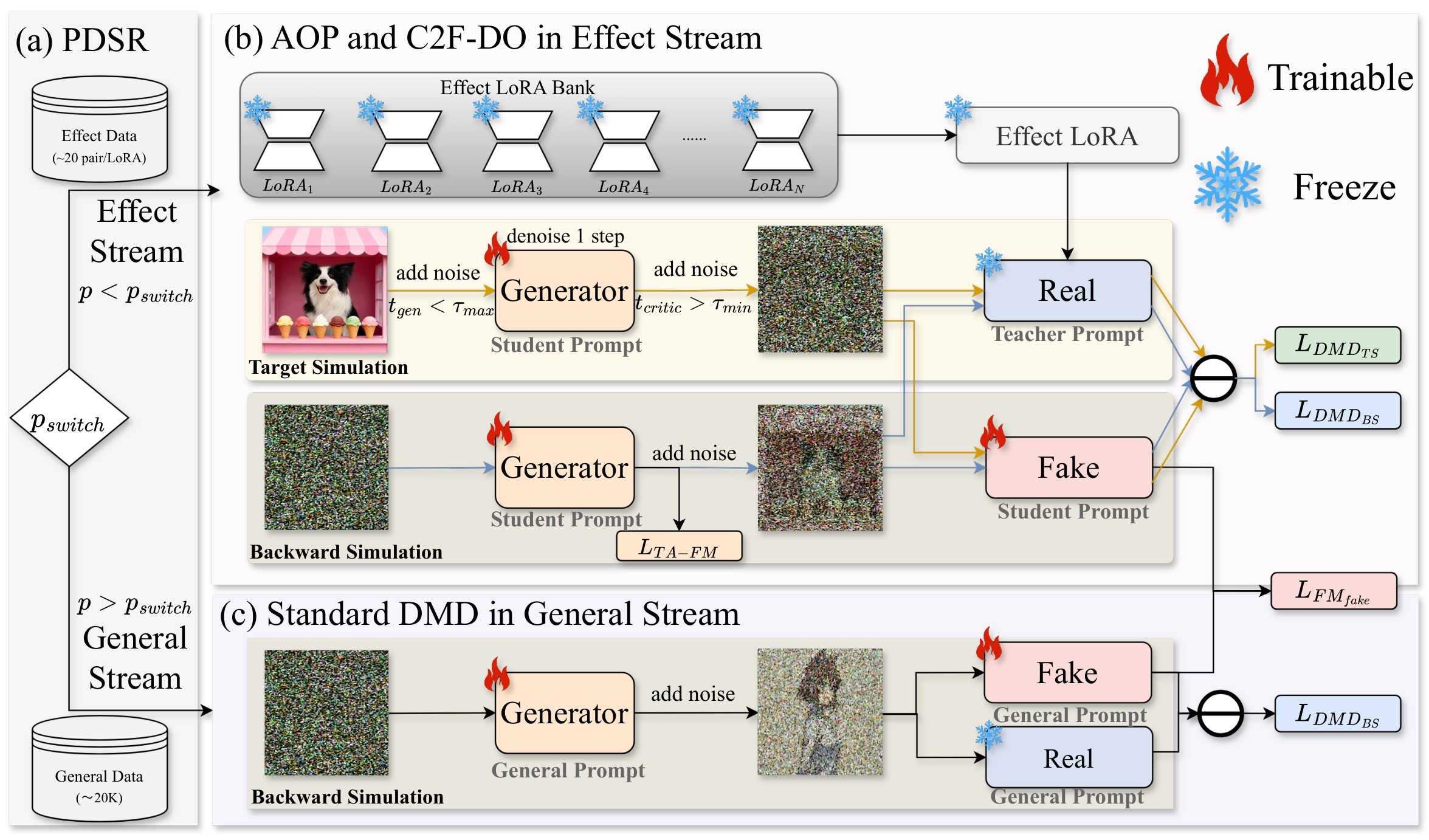
The method then has three moving parts:
- Probabilistic Dual-Stream Routing (PDSR): at each step, sample \(p \sim \mathcal{U}(0,1)\). If the step is routed to the general stream, distill from the base model on unlabeled general images; if routed to the effect stream, sample a frozen effect teacher from the LoRA bank.
- Asymmetric Orthogonal Prompting (AOP): let teachers use their original prompts, but give the student a VLM-refined prompt plus an effect-specific trigger word:
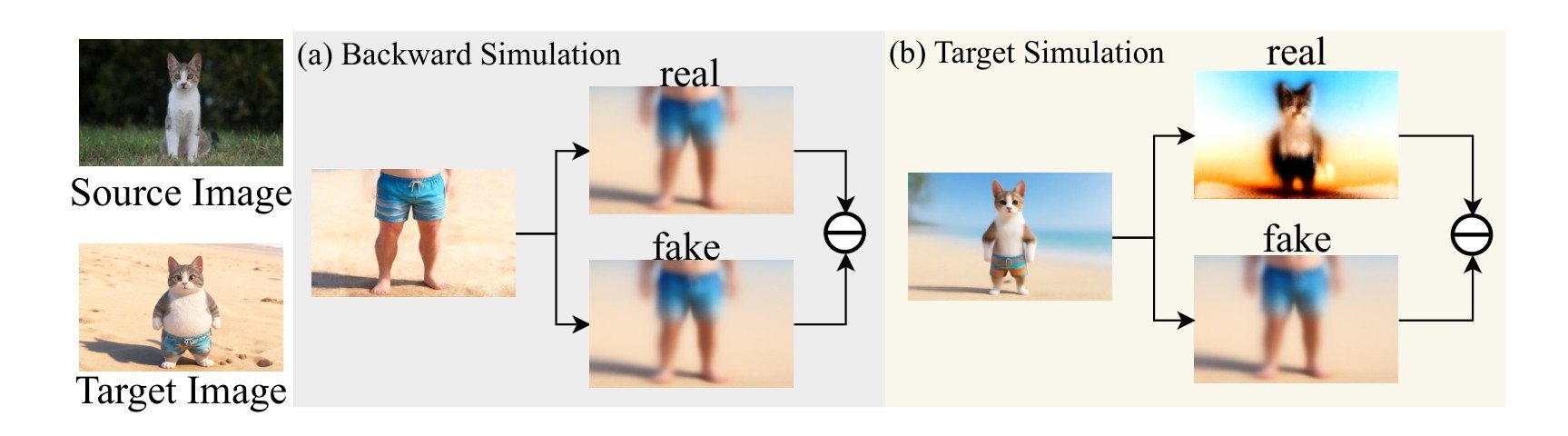
- Coarse-to-Fine Distillation Objective (C2F-DO): use trajectory anchoring to pull the cold-start student toward teacher outputs, then use target-simulated distribution matching and backward simulation to restore detail and match the target distribution.
The complete training flow is summarized in Figure 2.
Method Details
PDSR: Preserve Generalization While Distilling Effects
PDSR uses two logical streams rather than training only on the small paired effect set. The general stream uses 20K unlabeled general-domain source images and the frozen base model as teacher, applying backward-simulation DMD. The effect stream uses paired effect examples and a sampled effect teacher. The total objective is an indicator-gated mixture:
The paper's claim is pragmatic: PDSR is not just a data mixer; it regularly re-exposes the student to the base model's general prior so a 50-effect LoRA does not overfit to a narrow paired dataset.
AOP: Isolate Concepts in Prompt Space
AOP deliberately makes teacher and student prompts asymmetric. Each teacher keeps the original effect prompt used to train its single-effect LoRA. The student receives an automatically generated descriptive prompt plus a unique trigger word. The trigger words are intended to form orthogonal effect identifiers, while the VLM-written prompts provide semantic detail without manual prompt engineering. The supplement reports use of Qwen-VL-Max-Latest to refine student prompts from two sampled training pairs and the teacher prompt.
C2F-DO: Stabilize the Student Before Distribution Matching
Vanilla DMD is fragile when the student starts far from many heterogeneous teachers. The paper says the student can collapse to an intermediate manifold, while pure regression-style anchoring can smooth away high-frequency detail. C2F-DO combines three losses:
The paper visualizes the C2F failure modes and fixes in Figure 3, then gives supplementary gradient and timestep analyses in Figure 4 and Figure 5.


Training and Evaluation Setup
The main 50-effect model uses 50 specific effects, each with about 20 animal or portrait image pairs. The general stream uses 20K source images with MLLM-generated instructions and no target images. Evaluation uses EffectBench, with animal and portrait categories and 5,000 instructions per model. The base model is Qwen-Image-Edit-2509. Single-effect LoRAs train for 2,000 steps; the naive 50-in-1 flow-matching baseline trains for 30,000 steps; CollectionLoRA trains both generator and fake score model with LoRA learning rate \(10^{-4}\), fake:generator update ratio 5:1, generator training for 5,000 steps, \(p_{\text{switch}}=0.5\), \(\tau_{\text{max}}=750\), and \(\tau_{\text{min}}=500\) on 8 H800 GPUs.
Metrics are CLIP and DreamSim for style alignment, DINO for subject consistency, EditReward for instruction following and overall quality, and two MLLM-derived metrics: Bad Case Rate (BCR) and Valid Subject Alignment (VSA). VSA first checks whether the target effect was applied; failed effects get zero consistency before subject consistency is scored.
Experiments And Results
Main EffectBench Results
Table 1 is the main quantitative support for the 50-in-1 claim. CollectionLoRA is the only method that combines the 50-effect setting, NFE=8, best CLIP, best DreamSim, best VSA, best EditReward, and lowest BCR in this table.
| Setting | Method | CLIP | DreamSim | DINO | VSA | EditReward | BCR | NFE |
|---|---|---|---|---|---|---|---|---|
| Single Effect | Base | 0.726 | 0.434 | 0.611 | 4.075 | 1.007 | 0.141 | 40 x 2 |
| Single Effect | Base+Lightning | 0.717 | 0.441 | 0.612 | 3.901 | 0.986 | 0.168 | 8 |
| 50 Effects in 1 | FM + Lightning | 0.703 | 0.468 | 0.611 | 4.150 | 0.929 | 0.217 | 8 |
| 50 Effects in 1 | Ours | 0.727 | 0.425 | 0.600 | 4.380 | 1.052 | 0.087 | 8 |
Table 1. Quantitative comparison on EffectBench. Higher is better for CLIP, DINO, VSA, and EditReward; lower is better for DreamSim, BCR, and NFE. The paper notes that DINO can over-reward failed stylizations, which is why VSA is used as a stricter subject-consistency metric.
Deployment Cost
Table 2 supports the deployment-cost claim. For 10-50 effects, CollectionLoRA uses one 2.2 GB adapter and has no routing or LoRA-switch loading. For 100-150 effects, the authors describe a fallback that groups effects into multiple CollectionLoRAs and still reduces storage and switch count.
| Metric | Method | 10 LoRAs | 20 LoRAs | 50 LoRAs | 100 LoRAs | 150 LoRAs |
|---|---|---|---|---|---|---|
| Routing latency | Baseline | 6.88 s/q | 6.95 s/q | 7.09 s/q | 7.22 s/q | 9.18 s/q |
| Routing latency | Ours | 0 s/q | 0 s/q | 0 s/q | 7.22 s/q | 9.18 s/q |
| LoRA loading latency x switch count | Baseline | 1.2 s x 200 | 1.2 s x 200 | 1.2 s x 200 | 1.2 s x 200 | 1.2 s x 200 |
| LoRA loading latency x switch count | Ours | 0 s | 0 s | 0 s | 1.2 s x 108 | 1.2 s x 136 |
| Routing accuracy | Baseline | 99% | 94% | 87% | 85% | 76% |
| Routing accuracy | Ours | 100% | 100% | 100% | 90% | 82% |
| Storage overhead | Baseline | 2.2 GB x 10 | 2.2 GB x 20 | 2.2 GB x 50 | 2.2 GB x 100 | 2.2 GB x 150 |
| Storage overhead | Ours | 2.2 GB | 2.2 GB | 2.2 GB | 2.2 GB x 2 | 2.2 GB x 3 |
Table 2. Deployment costs across numbers of LoRAs. The table is simulated over 200 queries on one GPU against a VLM-routed baseline.
The qualitative comparison in Figure 6 is the paper's visual support for the failure taxonomy behind the quantitative metrics.

Figure 7 is the only direct evidence used here for the zero-shot composition claim.

Ablation Evidence
Table 3 is the clearest component-level evidence. AOP sharply reduces BCR versus PDSR alone, TS improves CLIP and DreamSim, TA-FM increases VSA and lowers BCR, and PDSR restores EditReward in the full configuration.
| Exp. | PDSR | AOP | TS | TA-FM | CLIP | DreamSim | DINO | VSA | EditReward | BCR |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | yes | no | no | no | 0.725 | 0.434 | 0.514 | 2.756 | 0.989 | 0.378 |
| 2 | yes | yes | no | no | 0.732 | 0.427 | 0.525 | 3.720 | 1.008 | 0.207 |
| 3 | yes | yes | yes | no | 0.736 | 0.420 | 0.541 | 4.018 | 0.979 | 0.199 |
| 4 | no | yes | yes | yes | 0.727 | 0.426 | 0.590 | 4.248 | 0.976 | 0.108 |
| 5 | yes | yes | yes | yes | 0.727 | 0.425 | 0.600 | 4.380 | 1.052 | 0.087 |
Table 3. Ablation under the 50-in-1 concurrent setting. The full method has the best DINO, VSA, EditReward, and BCR; TS-only-without-TA-FM has the best CLIP and DreamSim but worse consistency/failure metrics than the full model.
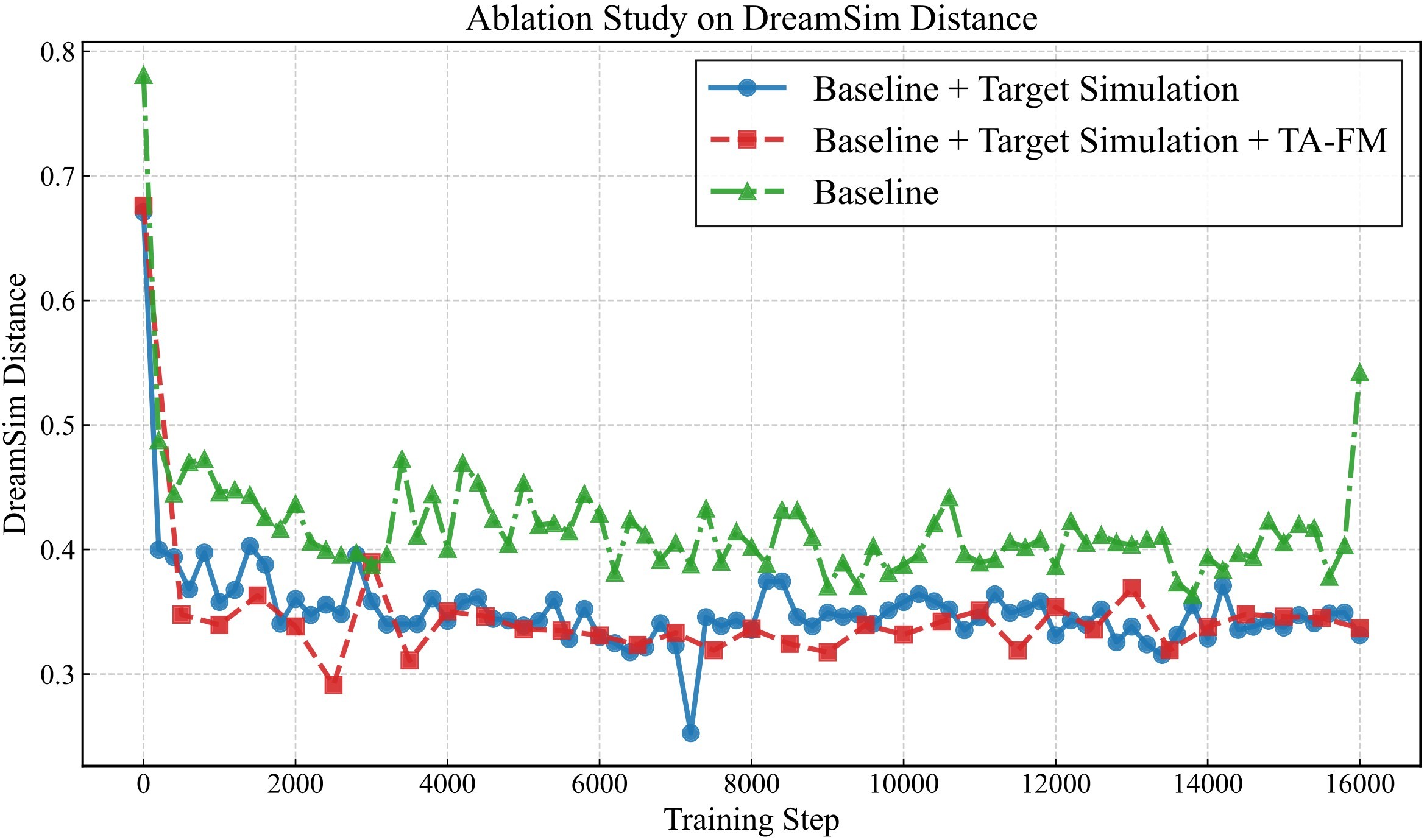
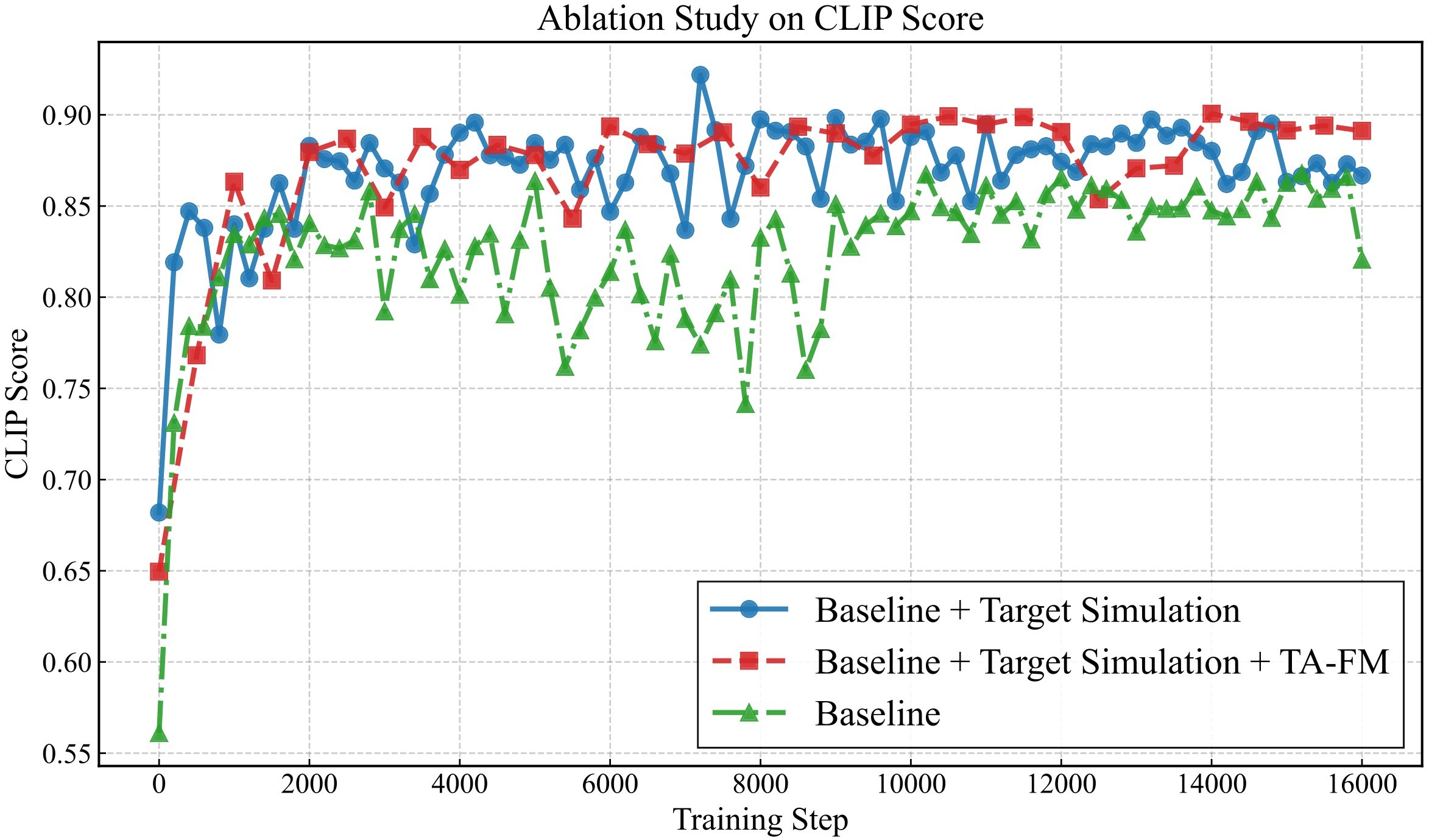
Figure 8 shows the same component story visually, while Figure 9 shows the reported DreamSim and CLIP training dynamics.

Scaling Beyond 50 Effects
Table 4 is useful but narrower than the main table because it reports CLIP only. CollectionLoRA beats the naive all-in-1 FM baseline at every scale, beats Base+Lightning at every scale, and beats Base up to 50 effects. At 100 and 180 effects, Base has higher CLIP, while CollectionLoRA still keeps competitive CLIP with much lower storage overhead.
| Method | 10 LoRAs | 20 LoRAs | 50 LoRAs | 100 LoRAs | 180 LoRAs |
|---|---|---|---|---|---|
| Base | 0.735 | 0.724 | 0.726 | 0.723 | 0.724 |
| Base+Lightning | 0.716 | 0.712 | 0.717 | 0.717 | 0.722 |
| All in 1 (FM) + Lightning | 0.725 | 0.722 | 0.703 | 0.694 | 0.689 |
| All in 1 (Ours) | 0.741 | 0.723 | 0.727 | 0.716 | 0.709 |
Table 4. CLIP score across numbers of LoRAs. The authors present the 100-180 effect drop as expected under extreme concept compression, not as catastrophic failure.
Incremental Extension
Table 5 supports the claim that new effects can be added with lightweight fine-tuning from the 50-effect model. The reported fine-tuning is 100 generator steps, and CLIP remains in the 0.725-0.728 range.
| Method | 50 LoRAs | 51 LoRAs | 52 LoRAs | 53 LoRAs | 54 LoRAs |
|---|---|---|---|---|---|
| Base+Lightning | 0.717 | 0.720 | 0.721 | 0.724 | 0.724 |
| Ours | 0.727 | 0.726 | 0.728 | 0.727 | 0.725 |
Table 5. CLIP score for incremental effect addition. This is evidence for extension without retraining from scratch, but it is still only a short 50-to-54 effect test.
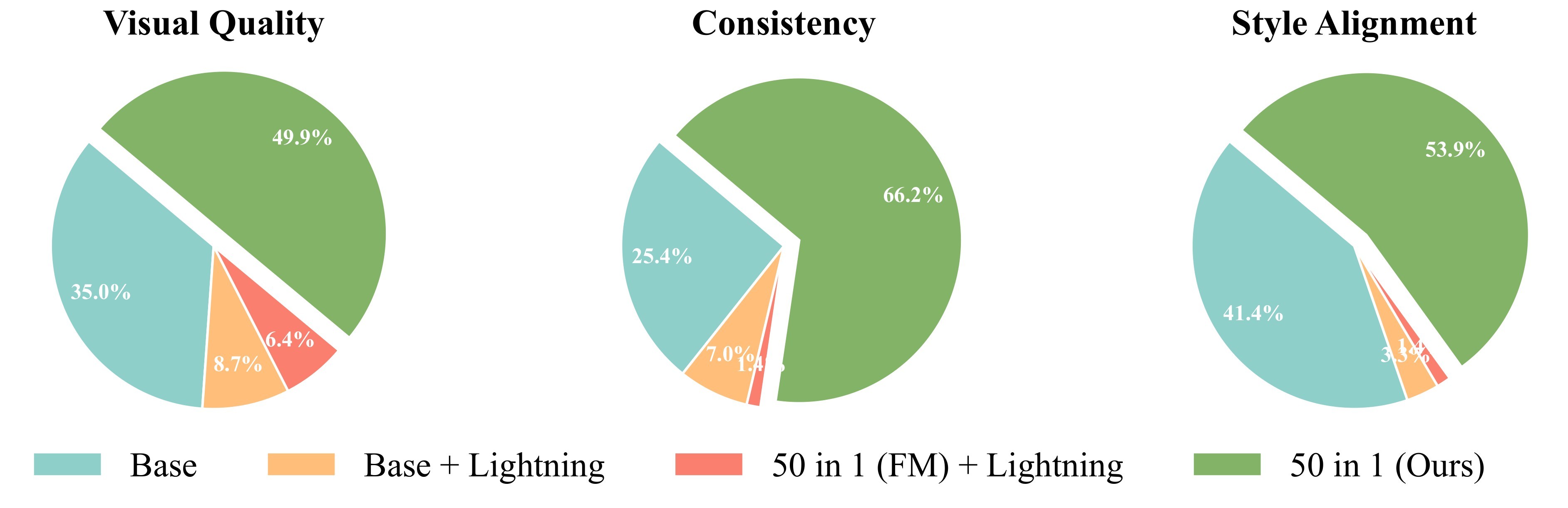
The subjective preference evidence is summarized in Figure 10.
Practical Takeaways
- The most reusable idea is not just "merge LoRAs"; it is the training recipe that keeps effect acquisition and base-model preservation separate through PDSR.
- AOP is a concrete prompt-space isolation trick: use original prompts for teachers, VLM-refined prompts plus unique trigger words for the student.
- C2F-DO addresses the cold-start mismatch that makes multi-teacher DMD unstable. TA-FM anchors structure; target simulation restores high-frequency detail; backward simulation regularizes the global distribution.
- The quantitative case is strongest for the 50-effect, NFE=8 setting on EffectBench. The approach clearly improves BCR and VSA over the baselines in the paper's metrics.
- The scaling claim is promising but less complete than the main result because the 10-180 effect table reports only CLIP.
- The zero-shot composition result is practically interesting but should be treated as a qualitative observation until a composition benchmark is reported.
- The evidence is all source-side and paper-reported; no implementation or reproduction details beyond those in the paper are assumed here.