Source-first digest for checked paper rank 43, rank_id p009.
- PDF extraction: not used
Motivation / Background
LLMs need to absorb new facts, preferences, and task-specific records after pretraining. Non-parametric memory methods such as in-context learning and retrieval-augmented generation can expose source text at inference time, but they remain limited by context length, attention dilution, and retrieval/runtime overhead. Parametric memory instead writes information into model weights or modular adapters, giving the model retrieval-free access to the stored content.
This paper studies the strictest version of that problem: exact parametric memory. The goal is not to answer semantically equivalent questions, but to reconstruct a target sequence verbatim from a key after the content has been stored only in parameter updates. The authors use LoRA as a controllable probe because the LoRA rank is a clean parameter-budget knob. The motivating setup is summarized in Figure 1.
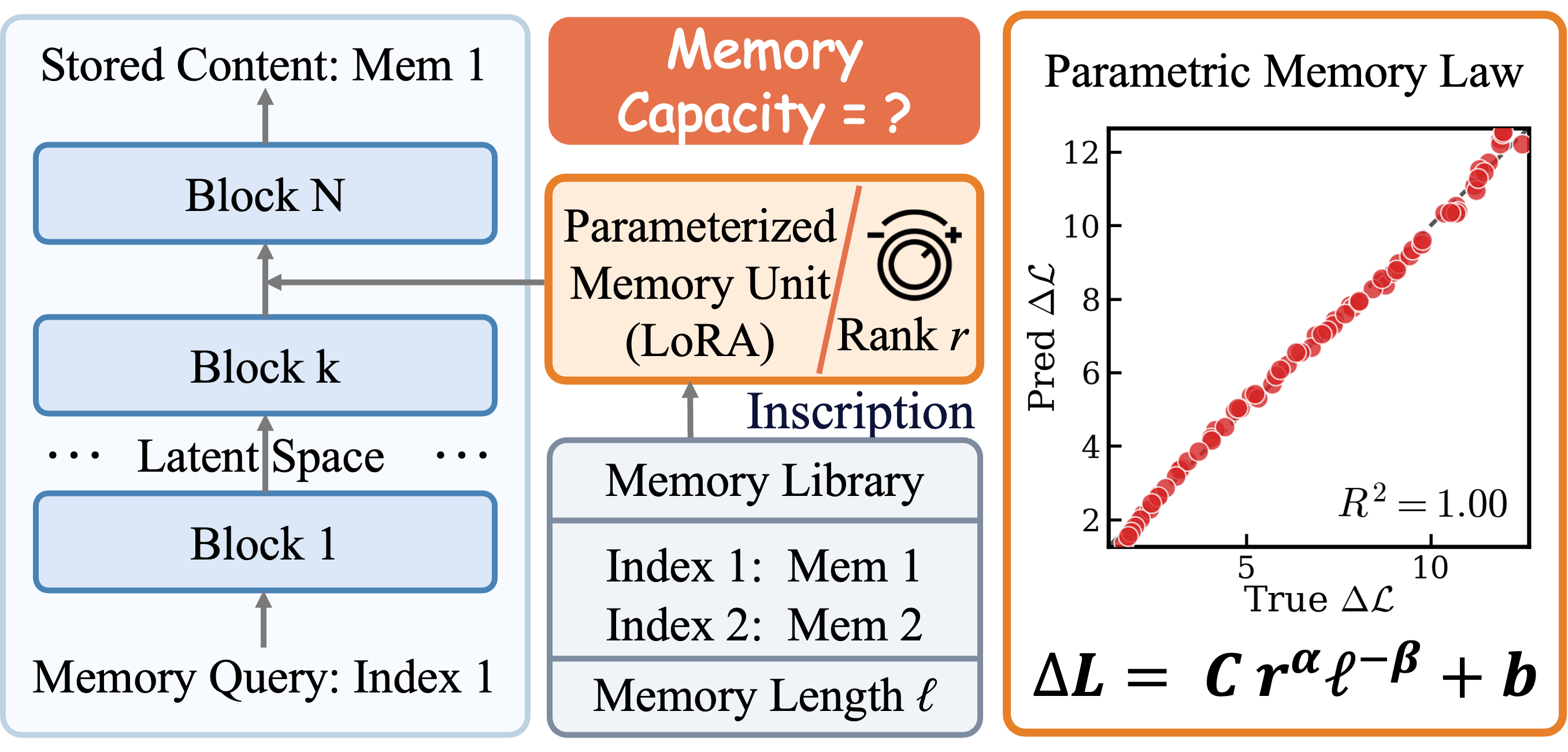
r LoRA module in the model latent space, treats it as a memory inscription, and asks how memory capacity changes with LoRA rank and target length. This is the first-viewport conceptual evidence for the paper's capacity-law framing.The key research question is: what governs the capacity boundary and token-level dynamics of exact parametric memory? The paper's answer has three pieces: a macroscopic power law for loss reduction, a token-level phase transition around target-token probability p = 0.5, and a training method, MemFT, that spends more gradient budget on tokens that have not crossed that threshold.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | LoRA can be used as a controlled latent-space probe for exact parametric memory because the frozen base model plus trainable low-rank adapter isolates parameter writing from retrieval or in-context access. | 4 | motivation, task setup, LoRA memory unit, exact-memory cases |
| C2 | Loss reduction from LoRA follows a robust parametric memory law, scaling positively with rank and negatively with sequence length. | 5 | law formulation, scaling figures, fit table |
| C3 | Average cross-entropy loss can be badly misaligned with exact recall; token positions below p = 0.5 act as stubborn bottlenecks that can trigger autoregressive collapse under greedy decoding. |
4 | phase transition, stubborn-token figure, probability grids |
| C4 | MemFT improves exact-memory fidelity and parameter efficiency by redirecting optimization toward sub-threshold tokens. | 5 | MemFT objective, main results, landscape figures |
| C5 | MemFT may improve rule generalization rather than merely overfitting memorized strings. | 3 | linear-rule table |
| C6 | The conclusions are bounded: the experiments are limited to 8B-scale models, greedy decoding, and a partial check of broader capability trade-offs. | 5 | limitations |
Scores are support-from-paper scores, not independent reproduction scores. The strongest evidence is for the empirical scaling fits and MemFT improvements on the paper's own benchmarks. Generalization and broader deployment claims are capped because the supporting experiments are narrower.
Core Technical Idea
The task is exact key-value memorization. For a dataset
the model receives key q and must reproduce target answer a verbatim. The frozen base model is f_{\theta_0} and only an added parameter increment \Delta\theta is trained:
The paper treats \Delta\theta as the only storage medium because target answers are not present at inference time. All sequence-length, loss, and accuracy accounting is answer-only: key tokens condition the model but do not count toward reported memory length.
LoRA implements the parameter increment. For a frozen linear layer,
The rank r controls trainable capacity. By sweeping r and target length \ell, the paper observes a capacity-length trade-off and then asks where the smooth loss trend breaks at token level.
| Scenario | Why exact recall matters |
|---|---|
| Credentials, endpoints, license keys, watermark strings | One wrong character changes operational meaning or invalidates the secret/key. |
| Legal or medical code text | Small wording or code errors can change compliance meaning or downstream use. |
| LaTeX/source snippets | Punctuation, braces, and symbols are part of the answer, not optional formatting. |
Table. Exact-memory scenarios. This distilled version of the paper's scenario table explains why the authors focus on verbatim recall instead of gist-level QA. It supports C1 and frames the practical value of exact parametric memory.
Method Details
Parametric Memory Law
The paper defines loss reduction as
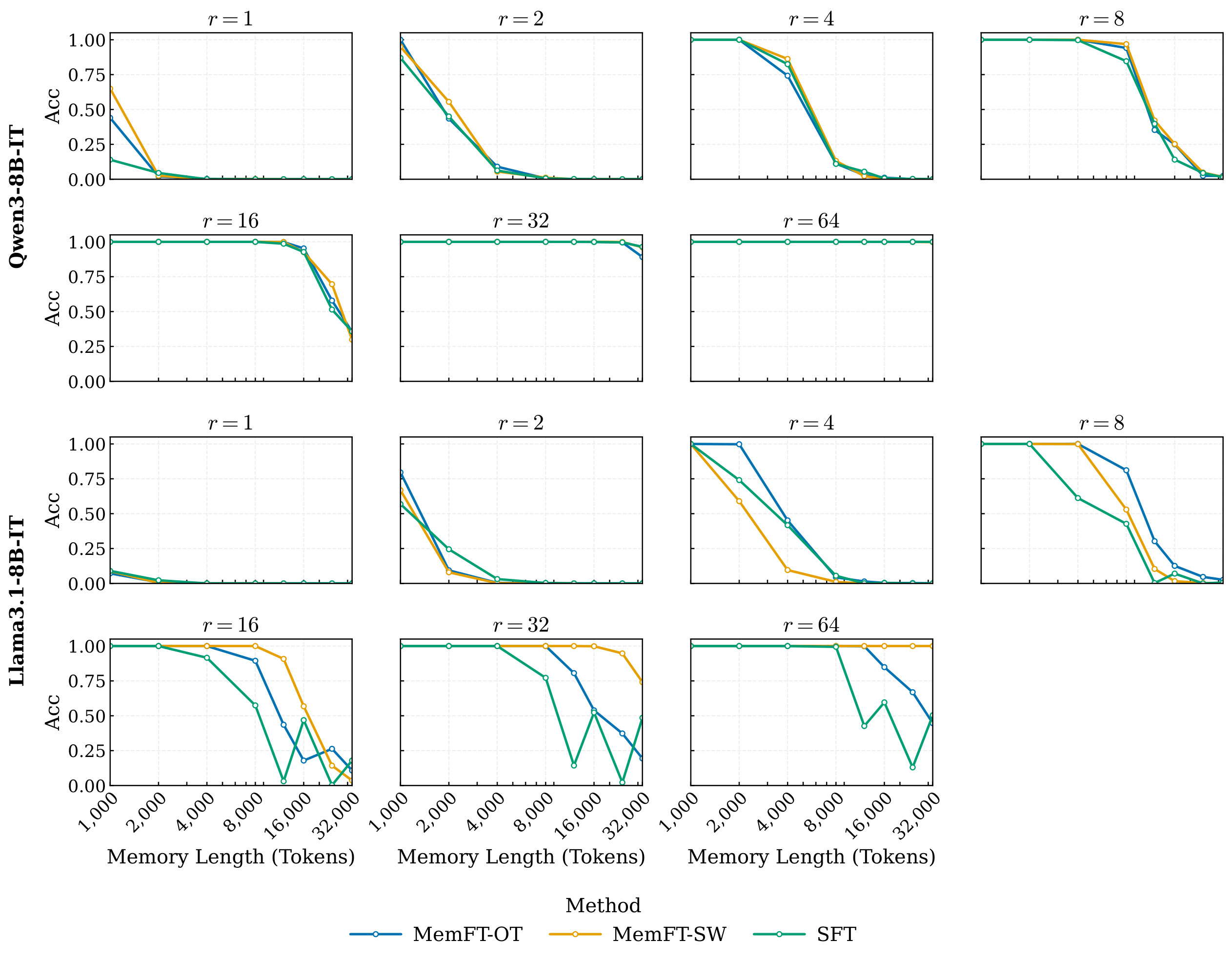
Across Qwen3-8B-IT and Llama3.1-8B-IT, the authors sweep LoRA rank r, target length \ell, random-token mixtures in a long-context stress test, and PhoneBook key-value lengths. They report that in the non-saturated regime, loss reduction is approximately log-linear with rank and length. The proposed empirical law is:
Here \alpha is the capacity exponent and \beta is the length penalty exponent. The law says that more LoRA rank increases memory gain, while longer targets reduce it by a power-law penalty. Figure 2 shows the source-side scaling panels used for this claim.
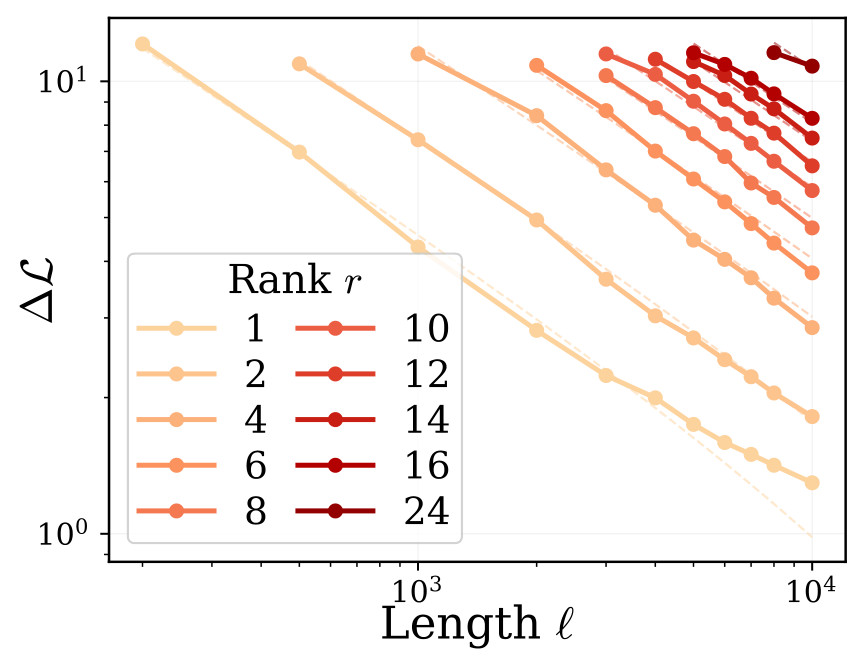
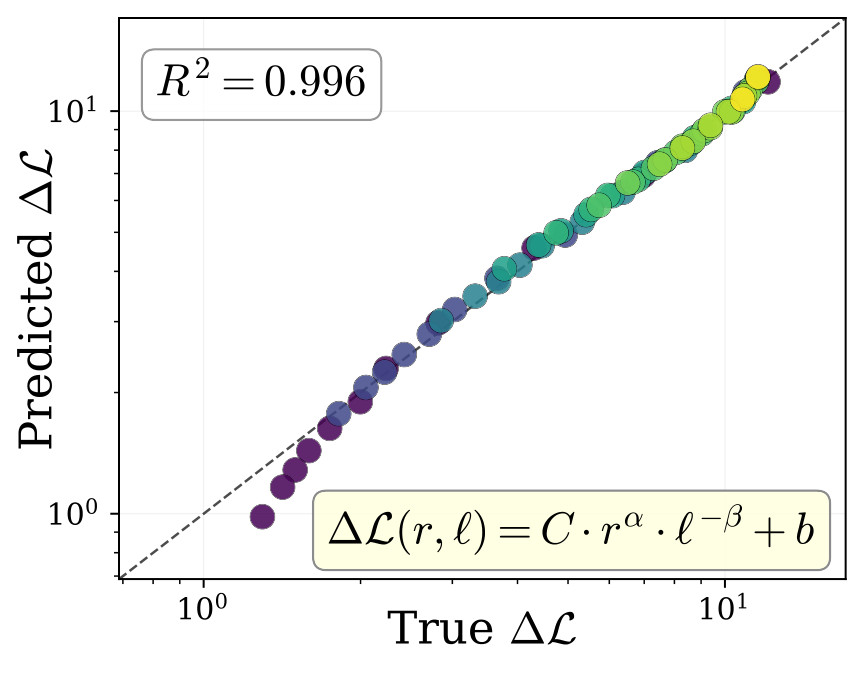
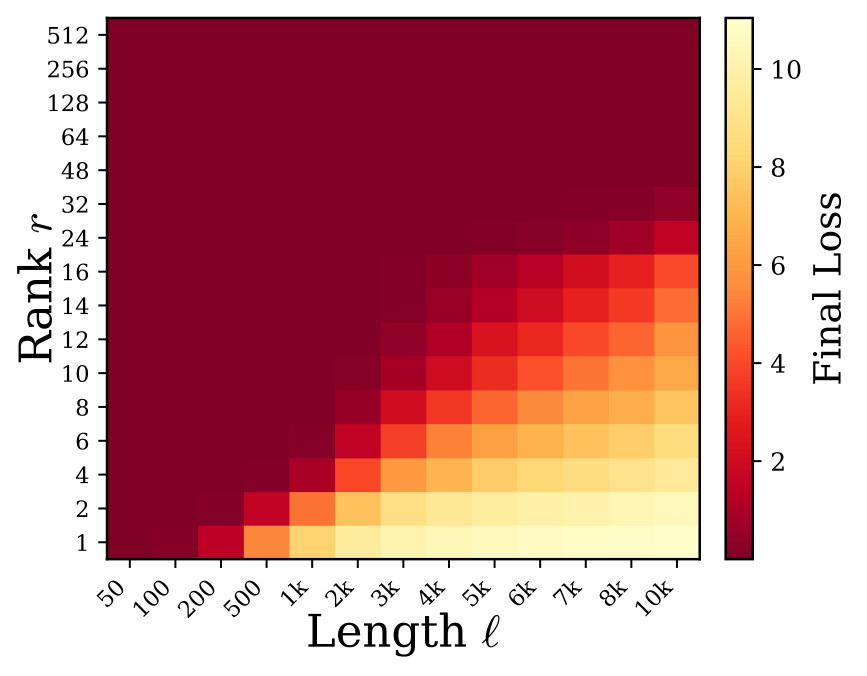
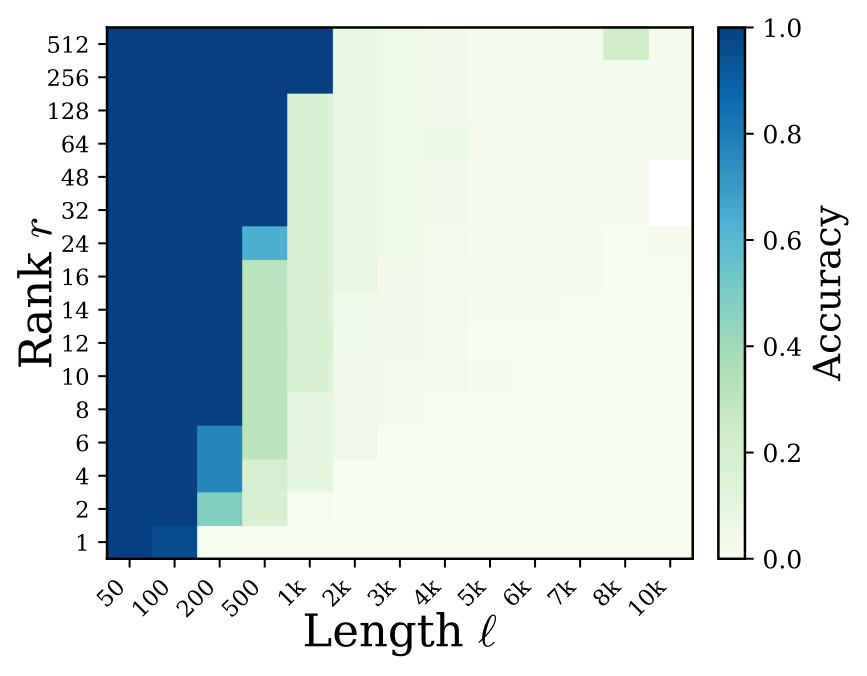
\Delta\mathcal{L} against rank and length, a predicted-vs-true fit panel, and paired heatmaps showing that low final loss can still coexist with poor token accuracy. I split the original multi-panel PDF into local JPEG panels for browser readability.Loss-Accuracy Misalignment And Phase Transition
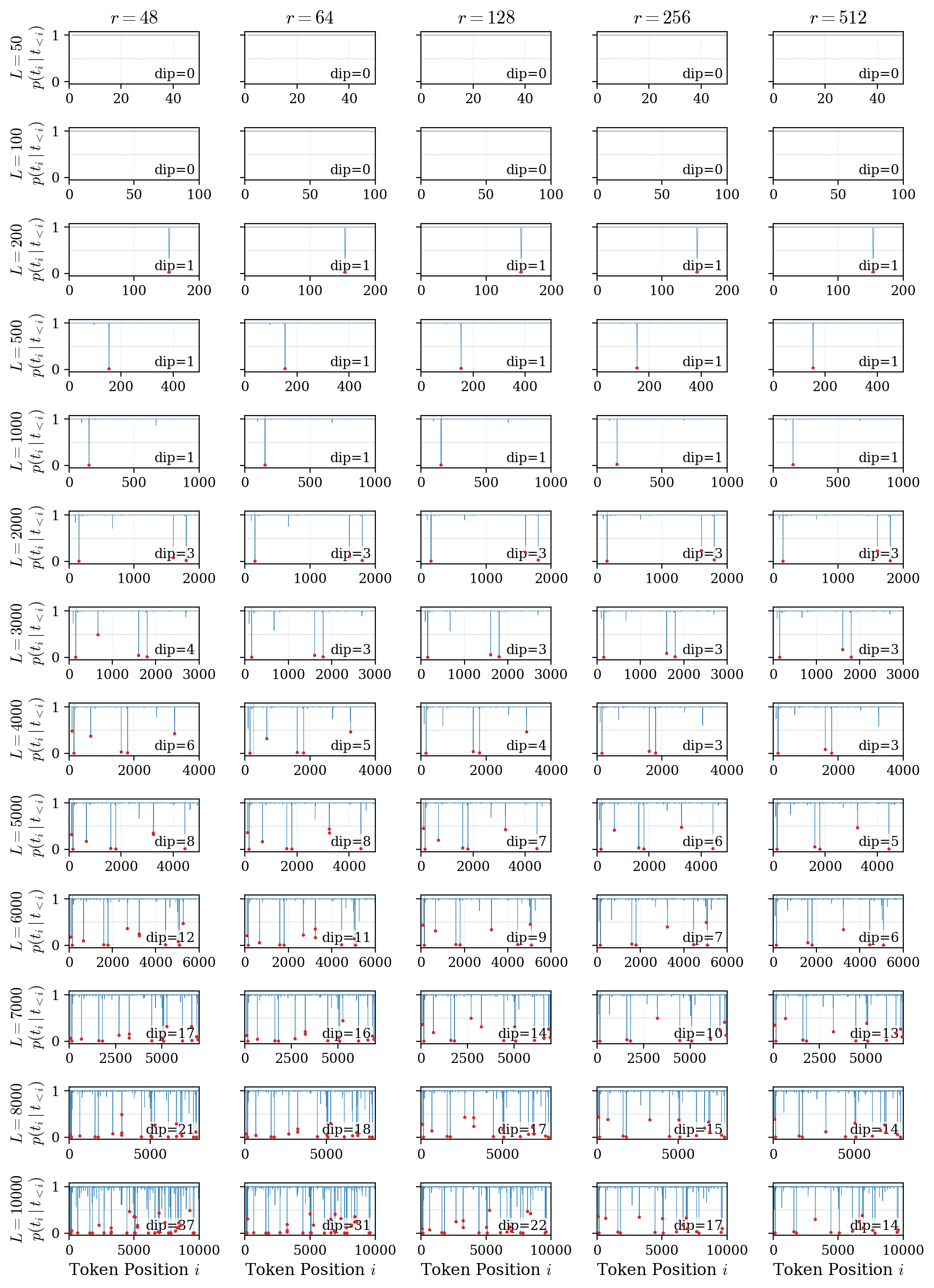
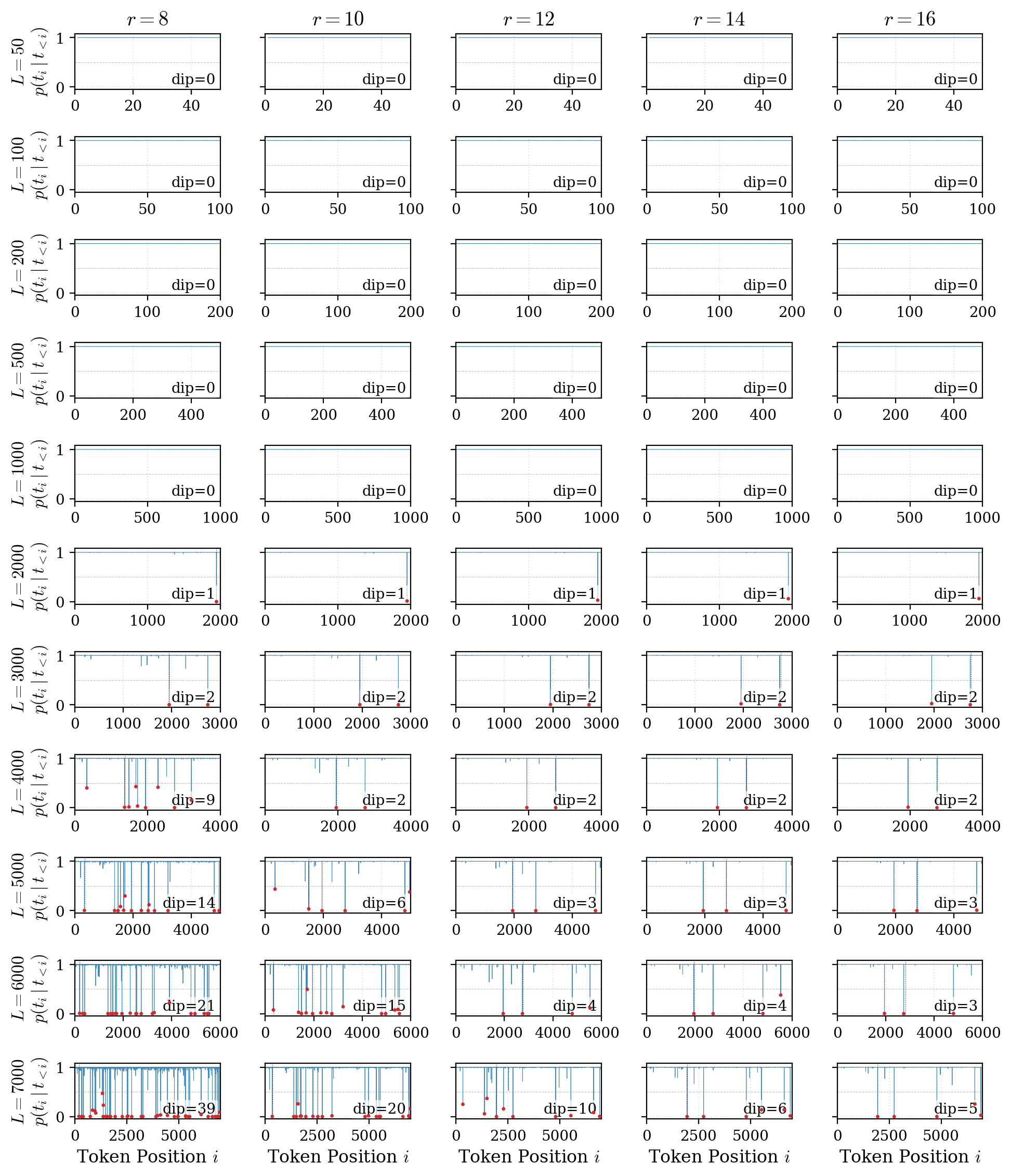
The paper argues that average loss is too smooth for exact recall. A model can drive most token probabilities very high while leaving a few target positions below the threshold required for greedy decoding. Those local bottlenecks are called stubborn tokens.
For greedy decoding, the target token is guaranteed to be selected if it holds more than half of the probability mass:
The equivalent critical cross-entropy value is:
The paper uses this as the deterministic phase boundary. Above the boundary, the target token may lose to another candidate; below it, no other single token can exceed it. This is a sufficient condition, not a claim about stochastic decoding or a necessary condition in every vocabulary distribution.
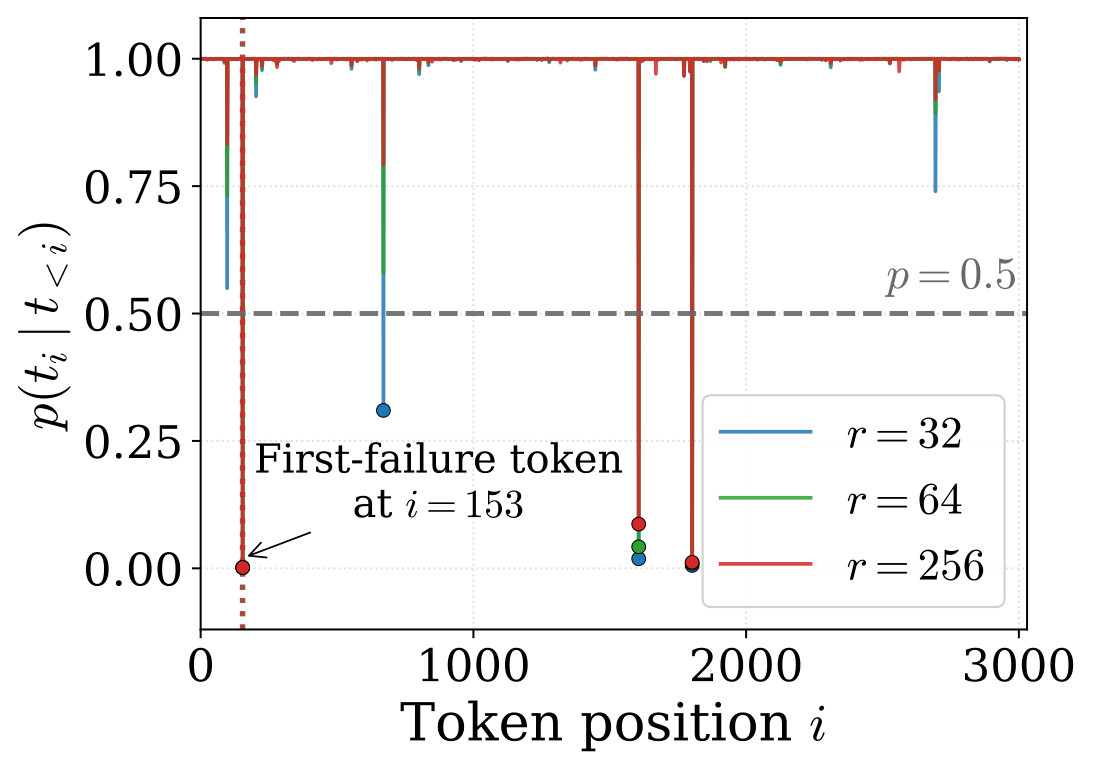
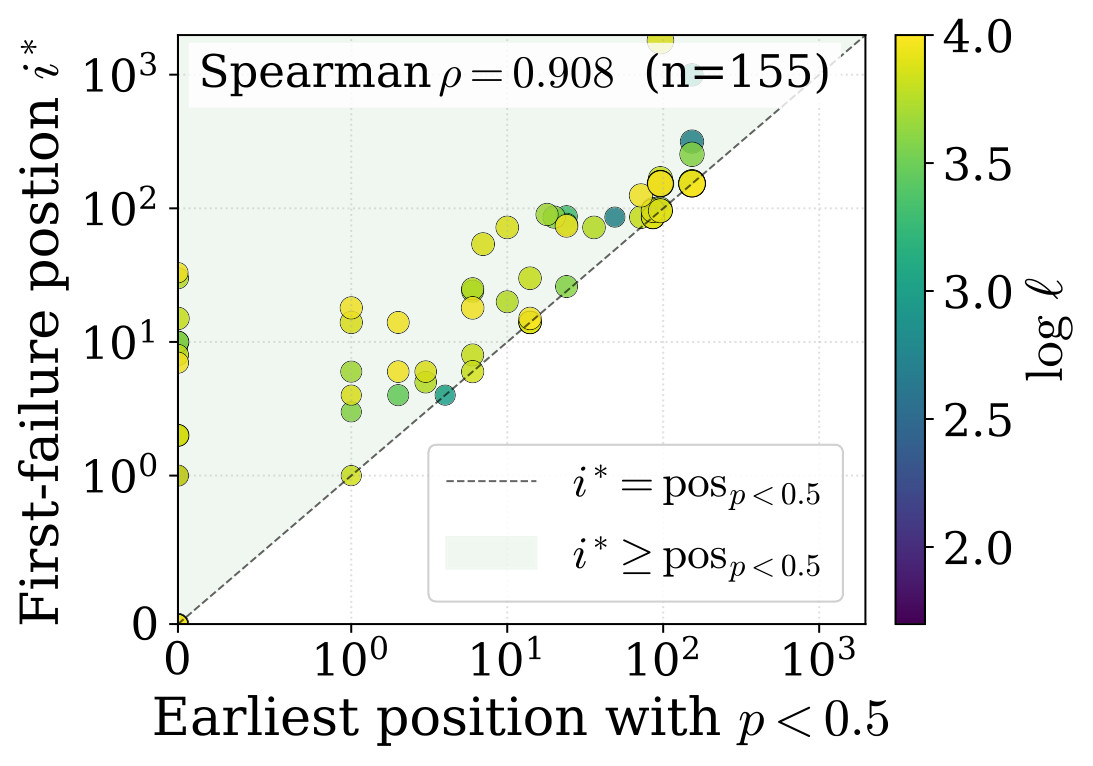
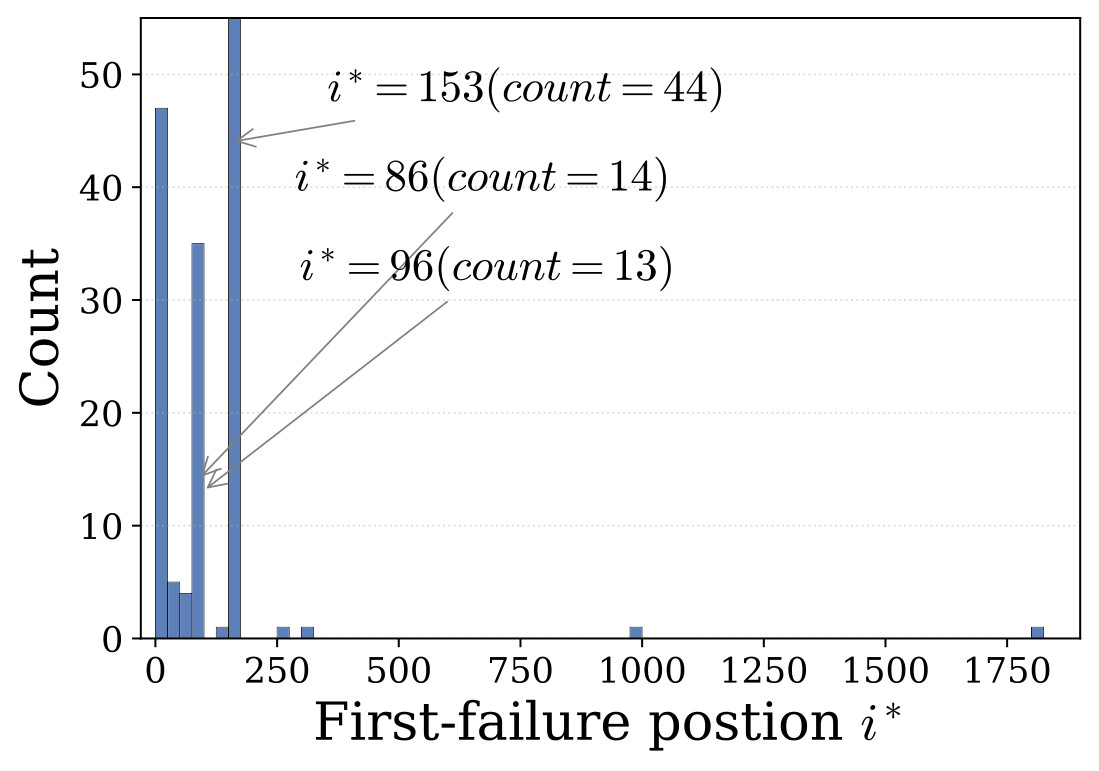
0.5, a tight relationship between earliest stubborn position and first free-run decoding failure, and localization of failure positions. The reported Spearman correlation between earliest stubborn position and first failure is rho = 0.908 with n = 155.MemFT Objective
MemFT changes the training objective from uniform token averaging to threshold-guided weighting. The general form is:
MemFT-OT uses a hard threshold:
MemFT-SW adds sliding mechanisms. The intra-sample spatial window anchors on the first greedy decoding error and weights a local neighborhood around it. The inter-batch temporal curriculum begins with simpler/shorter batches and expands exposure over training. The intent is to stop spending equal gradient budget on already-ordered tokens and instead push the stubborn positions over the deterministic threshold.
Experiments And Results
The experimental evidence has two layers: the capacity-law fit and the MemFT comparison. The main benchmarks are a long-context memorization stress test and PhoneBook. The long-context stress test uses LongBench-derived sequences with random-token replacements from 0% to 100%; the method evaluation emphasizes the fully random condition as the maximal difficulty regime. PhoneBook removes the context field and evaluates exact key-to-phone-number recall with answer-only length buckets.
| Model | Metric | r0 | r20 | r40 | r60 | r80 | r100 | Combined | PhoneBook |
|---|---|---|---|---|---|---|---|---|---|
| Llama3.1-8B-IT | R^2 |
0.992 | 0.994 | 0.996 | 0.995 | 0.996 | 0.996 | 0.987 | 0.981 |
| Llama3.1-8B-IT | MAPE (%) | 1.430 | 2.493 | 2.528 | 2.755 | 2.710 | 2.563 | 7.057 | 1.606 |
| Qwen3-8B-IT | R^2 |
0.996 | 0.993 | 0.996 | 0.996 | 0.995 | 0.996 | 0.983 | 0.990 |
| Qwen3-8B-IT | MAPE (%) | 0.752 | 2.553 | 2.331 | 2.862 | 3.944 | 3.472 | 8.320 | 0.476 |
Table. Parametric-law fit validation. The law reaches R^2 > 0.98 in all listed settings, including combined long-context mixtures and PhoneBook. This is the strongest evidence for C2.
| Model | Method | r1 | r2 | r3 | r4 | r5 | r6 | r7 | r8 | r9 | p1 | p2 | p3 | p4 | p5 | p6 | p7 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama3.1-8B-IT | SFT | 27.4 | 28.5 | 43.6 | 45.9 | 54.9 | 69.5 | 78.2 | 86.3 | 94.7 | 0.50 | 3.85 | 18.7 | 28.0 | 37.8 | 47.0 | 59.3 |
| Llama3.1-8B-IT | MemFT-OT | 27.3 | 36.4 | 45.6 | 54.7 | 63.6 | 70.5 | 85.4 | 94.7 | 100.0 | 1.00 | 11.2 | 31.4 | 53.9 | 61.0 | 73.9 | 87.0 |
| Llama3.1-8B-IT | MemFT-SW | 32.5 | 37.5 | 46.0 | 52.3 | 56.0 | 63.4 | 69.1 | 76.6 | 81.1 | 1.84 | 15.0 | 34.0 | 45.7 | 70.7 | 96.1 | 100.0 |
| Qwen3-8B-IT | SFT | 17.9 | 24.2 | 27.8 | 31.7 | 33.1 | 39.8 | 40.2 | 40.0 | 47.7 | 2.32 | 17.4 | 37.5 | 55.5 | 84.8 | 99.5 | 100.0 |
| Qwen3-8B-IT | MemFT-OT | 19.2 | 23.6 | 29.8 | 38.5 | 47.5 | 56.1 | 91.1 | 100.0 | 100.0 | 5.78 | 19.1 | 36.2 | 57.4 | 86.1 | 98.6 | 100.0 |
| Qwen3-8B-IT | MemFT-SW | 24.7 | 29.3 | 32.0 | 39.4 | 52.5 | 74.6 | 93.5 | 94.4 | 94.4 | 8.45 | 19.7 | 37.8 | 58.8 | 86.5 | 99.5 | 100.0 |
Table. Main MemFT results. Long-context columns report token-level accuracy percentages; PhoneBook columns report exact-match accuracy percentages. For Llama, long-context ranks r1..r9 map to {1,2,4,6,8,10,12,14,16}; for Qwen, they map to {1,2,4,8,16,32,64,128,256}. PhoneBook p1..p7 maps to {1,2,4,8,16,32,64}. This table directly supports C4: both MemFT variants usually beat SFT, but OT and SW trade off by regime.
The main nuance is method-dependent. MemFT-SW is strongest at low ranks and on PhoneBook, reaching 100.0% PhoneBook EM at p7 for Llama and at p7 for Qwen while staying high at p6. MemFT-OT is sharper in high-rank long-context settings: it reaches 100.0% at Llama r9 and Qwen r8/r9.
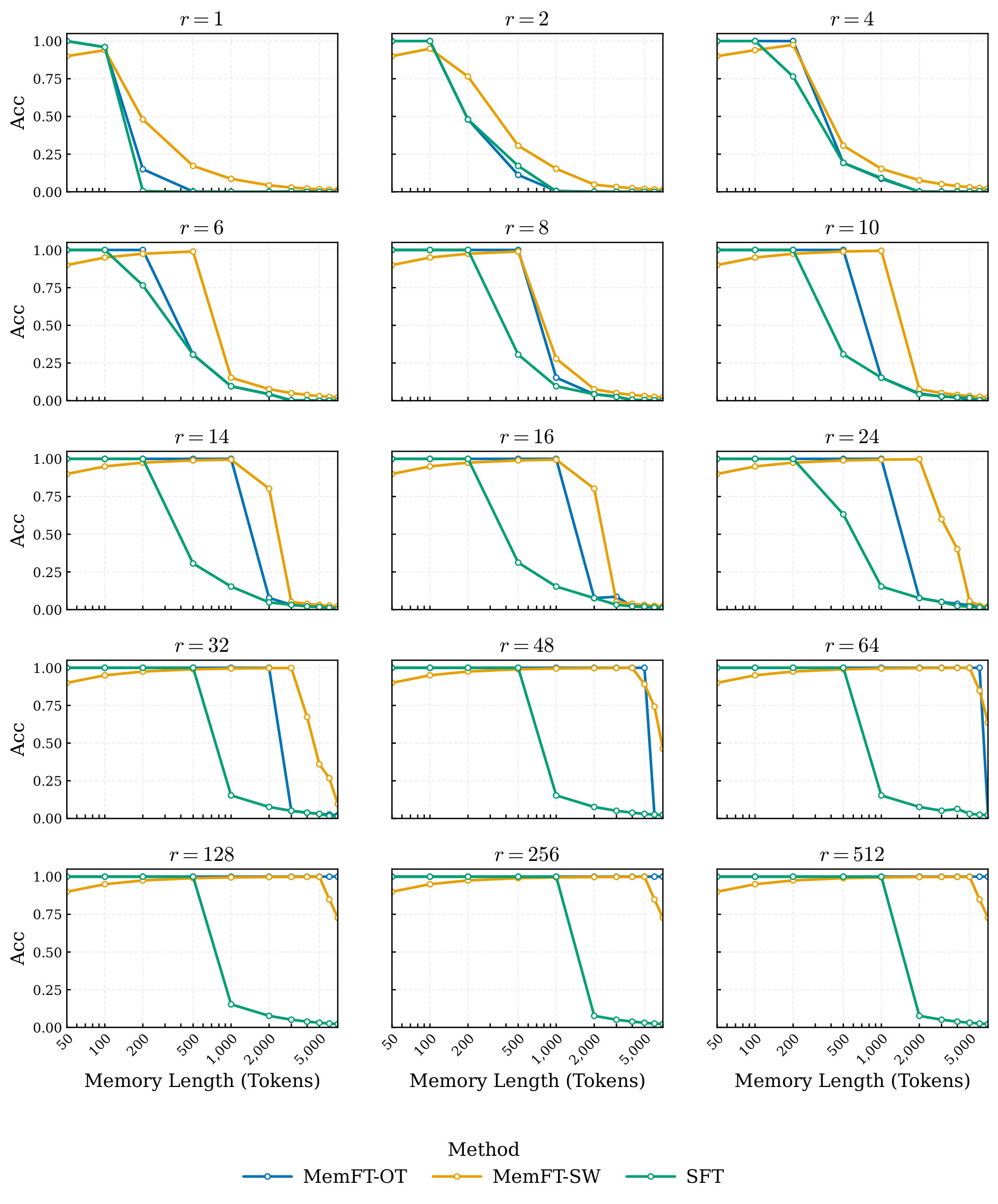
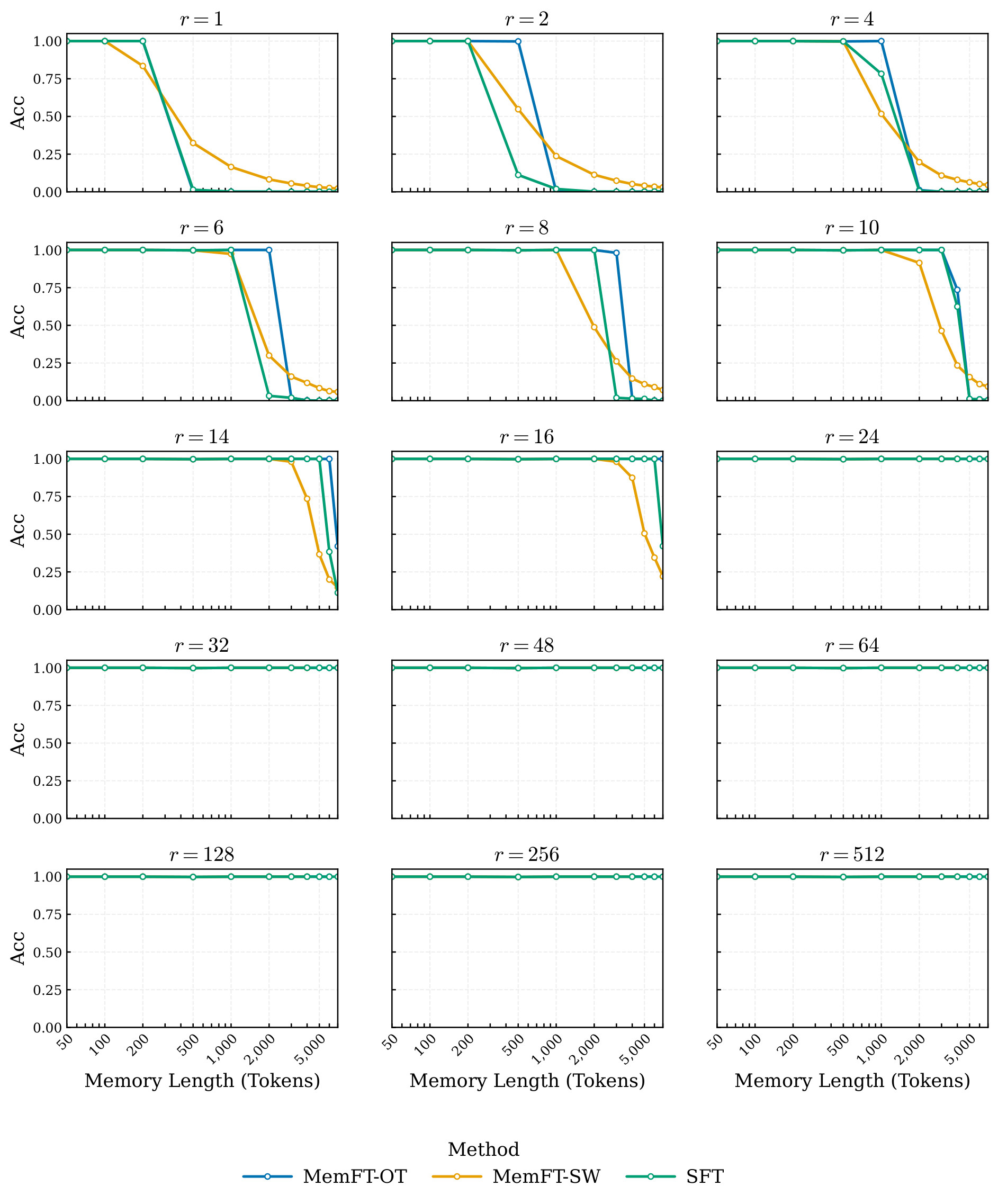
| Rank | Method | Memory (%) | Generalization (%) |
|---|---|---|---|
| 1 | SFT | 83.0 | 19.0 |
| 1 | MemFT | 95.0 | 34.0 |
| 2 | SFT | 100.0 | 38.0 |
| 2 | MemFT | 97.0 | 47.0 |
| 4 | SFT | 99.0 | 46.0 |
| 4 | MemFT | 100.0 | 53.0 |
| 8 | SFT | 100.0 | 39.0 |
| 8 | MemFT | 99.0 | 49.0 |
| 16 | SFT | 100.0 | 41.0 |
| 16 | MemFT | 100.0 | 54.0 |
Table. Linear rule learning generalization. The paper adds an auxiliary benchmark for f(x,y)=3x+5y+7 on Qwen3-8B-IT. MemFT improves unseen-pair accuracy by 7 to 15 percentage points in the reported ranks. I score this claim lower because this is a small synthetic check, not broad generalization evidence.
Limitations
The paper's limitations are explicit. The analysis is restricted to 8B-scale models. The p=0.5 phase transition is tied to greedy decoding and remains unverified for stochastic decoding such as nucleus sampling. The authors also say the trade-off with broader capabilities such as open-ended reasoning is only preliminarily assessed.
Practical Takeaways
The useful engineering idea is not just "use higher LoRA rank." The paper says memory gain follows a capacity-length scaling law, but exact recall is ultimately bottlenecked by local token positions. If a target token remains below p=0.5, greedy decoding can fail at that point and corrupt the rest of the sequence.
MemFT is the actionable method: stop treating all answer tokens equally once many have crossed the deterministic threshold, and spend optimization on tokens that are still sub-threshold or near the first failure anchor. The evidence is strong for exact-memory toy/stress settings and PhoneBook-style key-value recall.
The biggest caveat is scope. This is an 8B-model, synthetic/exact-memory study under greedy decoding. It provides a clean theory and practical training heuristic for exact recall, but it does not yet establish that the law transfers unchanged to larger models, stochastic decoding, or open-ended reasoning tasks.