Source-first digest for checked paper rank 22, rank_id p021.
- Routing status:
pandoc_failed - PDF extraction: not used
Motivation / Background
Modern tool-using agents are usually evaluated as if one task is active at a time and tool calls return immediately. AsyncTool argues that this misses a central real-world constraint: external function calls can take time, and a useful agent should make progress on other independent tasks while waiting for delayed results.
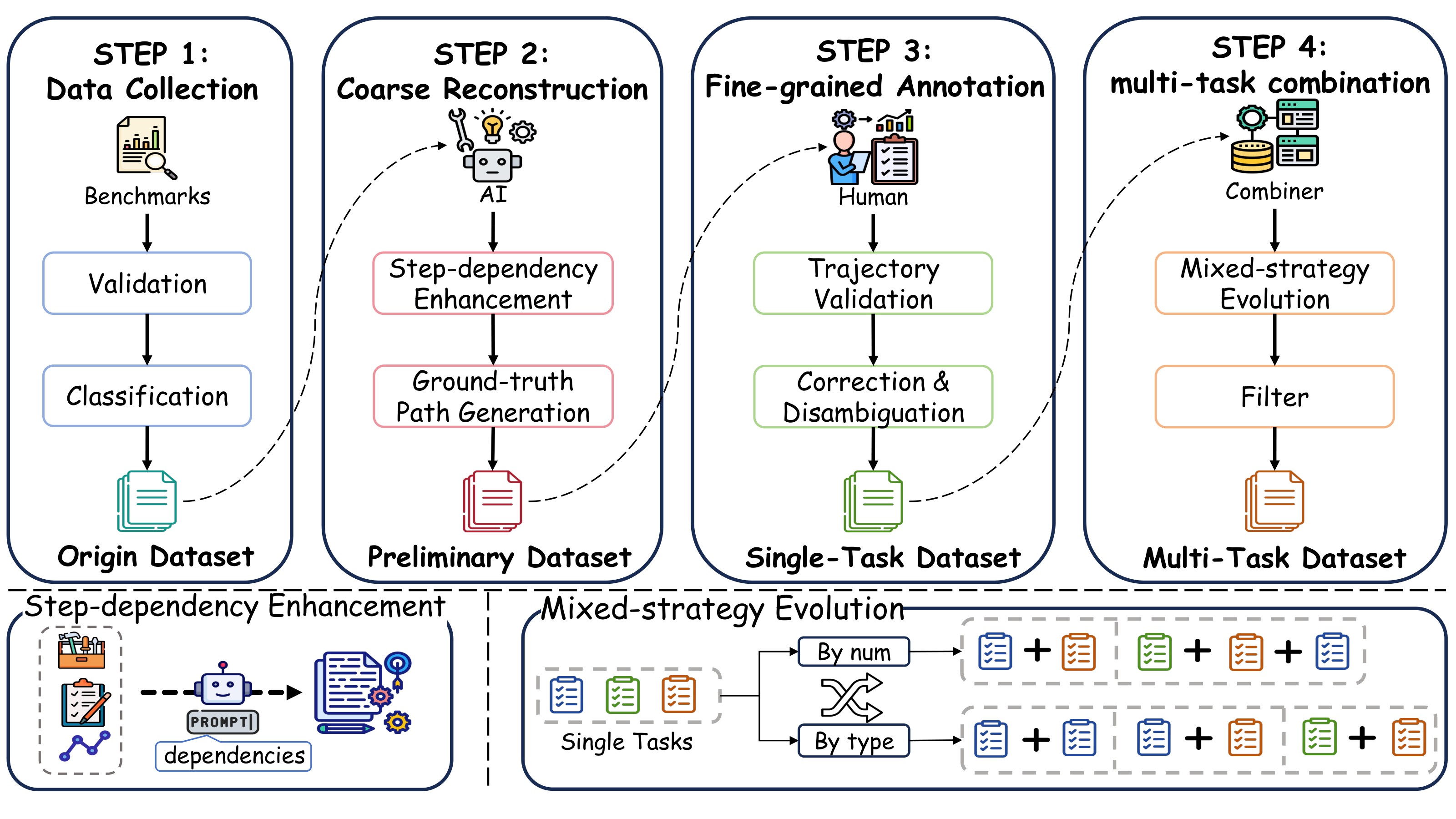
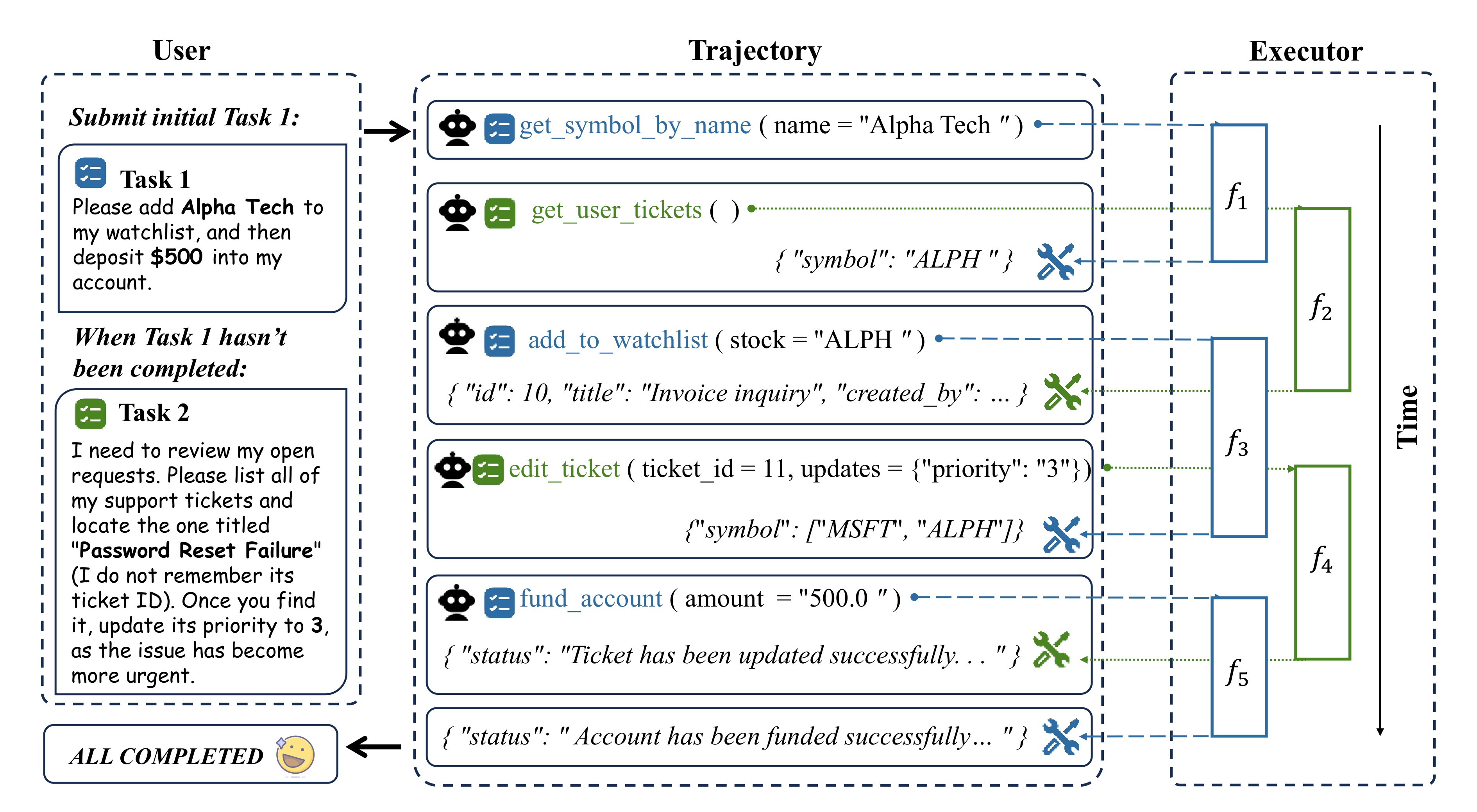
The benchmark reframes the agent as a concurrent scheduler. Each task has an ordered tool-call trajectory with intra-task dependencies, while different tasks can be interleaved. The agent must call the right tool with valid arguments, preserve task state across pending calls, resume a task only when its dependency has returned, and avoid confusing tools or state across tasks. Figure 1 shows how the benchmark is built, and Figure 2 illustrates the asynchronous executor interaction.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | AsyncTool fills a real benchmark gap by jointly testing function calls, multi-task execution, multi-step trajectories, cross-scenario composition, and an asynchronous executor. | 4 | motivation, benchmark comparison, data construction |
| C2 | The dataset is deliberately constructed from validated single-task trajectories and then composed into diverse two-task and three-task asynchronous settings. | 4 | data pipeline, task inventory, task-type split, composition table |
| C3 | The evaluation protocol captures correctness at step, sub-task, and task levels, not only final answer success. | 5 | metric definitions, trajectory equations, main results |
| C4 | Current agents struggle under asynchronous delayed feedback; even strong models achieve modest end-to-end overall scores. | 5 | main results, latency ablation, task-count ablation |
| C5 | Good asynchronous performance requires the right kind of switching: frequent switching alone is insufficient without state maintenance and dependency tracking. | 4 | scheduling trade-off, error modes, score figure, score visualization |
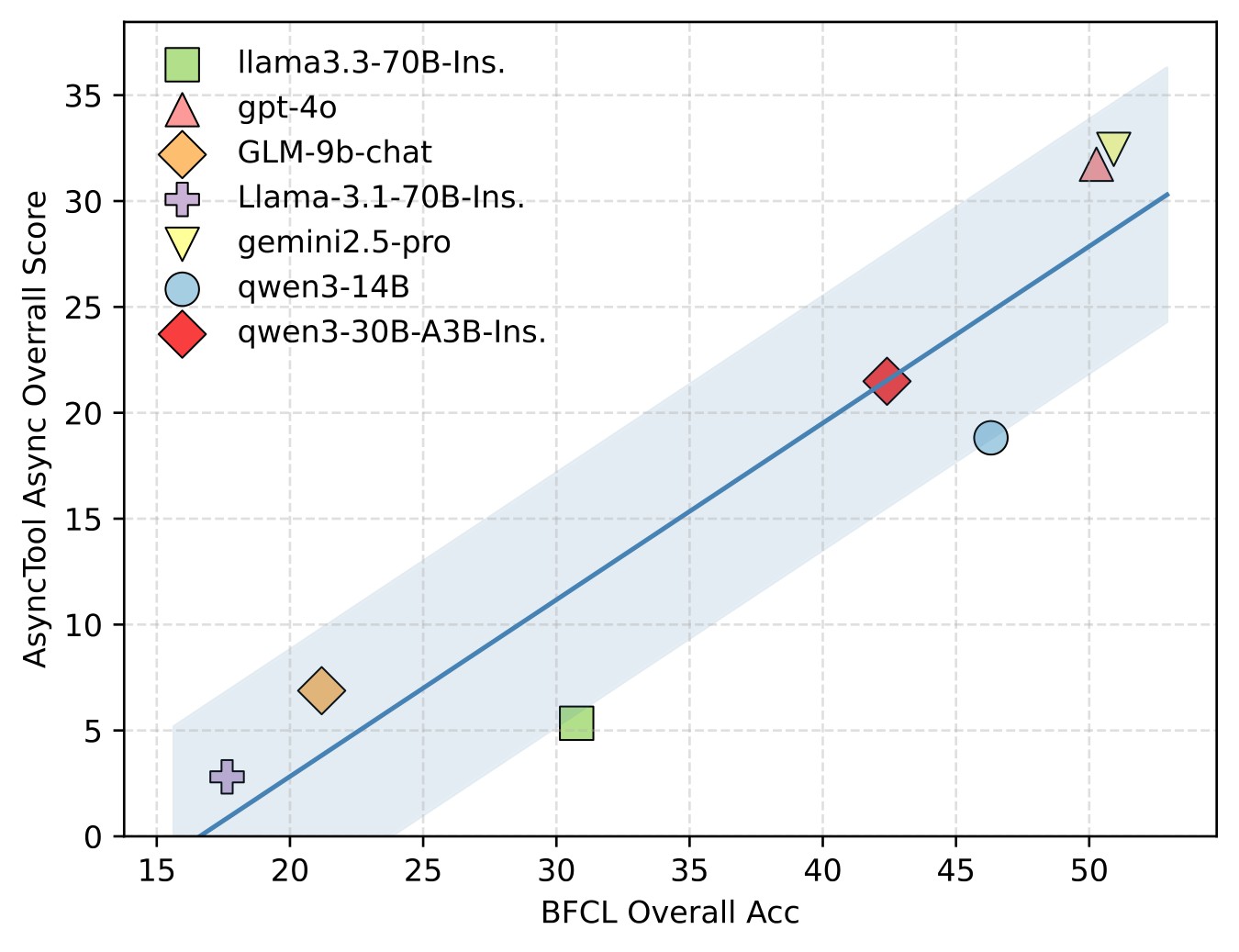
| C6 | Existing function-calling strength, as measured by BFCL, does not fully predict AsyncTool performance. | 3 | BFCL comparison, BFCL score plot |
| C7 | Few-shot trajectory examples help some smaller open models but do not solve the benchmark. | 4 | few-shot table |
Scores are support-from-paper scores, not independent reproduction scores. Dataset novelty is capped below 5 because it is substantiated by feature comparison and construction details rather than an external benchmark audit; core metric and result claims receive higher support because the paper gives explicit definitions and quantitative tables.
Core Technical Idea
AsyncTool is not a new agent architecture. It is an evaluation environment for agents that must juggle multiple delayed tool-use tasks. The important object is a sub-task tuple:
where \(I_i\) is the task identifier, \(Q_i\) is the task query, \(T_i\) is the available API list, and \(E_i\) is the hidden environment state. The model response must explicitly include \(I_i\), so the executor can tell which pending sub-task the agent is trying to advance.
For each sub-task, the source trajectory is an ordered sequence of tool calls:
where each action \(a_j\) is a pair of tool name and arguments. The appendix defines predicted and ground-truth trajectories as:
The asynchronous twist is that after an agent issues a tool call, the environment may report that the result is not yet available. The agent can wait, continue the same task incorrectly, or switch to another available task. AsyncTool scores whether it eventually produces the correct tool trajectories and environment states while managing those delays.
Method Details
Benchmark Construction
The construction pipeline starts from NESTFUL and BFCLv3, because those benchmarks already provide tool APIs, executors, task descriptions, and execution paths. The authors extract 12 tools and 358 tasks into an original single-task dataset, reconstruct task descriptions and strictly ordered trajectories with Gemini 2.5 Pro, and then manually correct errors in arguments, dependency order, initial task interpretation, and task-trajectory alignment.
The human validation instructions require annotators to inspect task goals, validate ordered function calls, check tool names and argument formats, verify dependency relations, execute or inspect trajectory results, correct unambiguous errors, rewrite ambiguous descriptions, and remove unreliable instances. This matters because an asynchronous benchmark is only meaningful if the single-task dependency chains are deterministic and executable before they are composed.
Table 1 summarizes the 12 single-task categories used before composition. It is referenced here because it shows that the benchmark is not limited to one tool domain.
| Category | Abbrev. | Tasks | Avg. trajectory length |
|---|---|---|---|
| Data Management | DM | 59 | 2.14 |
| Filesystem | FS | 53 | 3.58 |
| Data generation | DG | 29 | 2.14 |
| MessageAPI | MA | 23 | 3.48 |
| Number operations | NO | 24 | 2.12 |
| SocialConnect | SC | 18 | 4.11 |
| String Manipulation | SM | 34 | 2.09 |
| TicketPurchase | TP | 21 | 2.81 |
| TradingBot | TB | 15 | 3.27 |
| TravelPlanning | TP* | 20 | 3.10 |
| DataFormat | DF | 44 | 2.09 |
| Machine Operation | MO | 18 | 3.00 |
Table 2 gives the final 712 multitasking instances. The benchmark uses both similar-task and cross-task mixtures, with two-task and three-task settings.
| Composition | Number of tasks | Samples | Share |
|---|---|---|---|
| SIMILAR | 2 | 120 | 16.85% |
| CROSS | 2 | 132 | 18.54% |
| SIMILAR | 3 | 240 | 33.71% |
| CROSS | 3 | 220 | 30.90% |
What AsyncTool Adds
Table 3 is the paper's compact argument for novelty. It claims that prior benchmarks cover some pieces of the problem, but not the full combination of async executor, function calling, multi-tasking, multi-step execution, and cross-scenario composition.
| Benchmark | Async executor | Function call | Multi-task | Multi-step | Cross-scenario |
|---|---|---|---|---|---|
| tau-bench | No | Yes | No | No | No |
| BFCL v3 | No | Yes | No | Yes | No |
| NESTFUL | No | Yes | No | Yes | No |
| TimeArena | Yes | No | Yes | Yes | No |
| C3-Bench | No | Yes | Yes | Yes | No |
| Robotouille | Yes | No | No | Yes | No |
| AsyncTool | Yes | Yes | Yes | Yes | Yes |
Metrics
AsyncTool scores agents at three levels:
- Step level: F1 for function-name correctness and parameter correctness.
- Sub-task level: trajectory completion, environment matching, and their combined sub-task accuracy.
- Task level: trajectory completion and environment consistency count only when all sub-task metrics within the task are satisfied.
This creates a sharp distinction between local tool-call fluency and full asynchronous success. A model can have high step-level scores while still failing overall because it mixes task states, violates dependencies, or produces an inconsistent final environment.
Experiments And Results
Main Results
Table 4 distills the main result table. The full source table reports eight metrics; this digest keeps the most diagnostic columns: step-level function and parameter F1, sub-task accuracy, task-level environment matching, and overall score.
| Model | Group | Func. | Param. | Sub-task Acc. | Task Env. | Overall |
|---|---|---|---|---|---|---|
| Qwen-Max | closed | 86.22 | 73.62 | 52.44 | 50.14 | 25.56 |
| Kimi-K2 | closed | 96.14 | 80.46 | 56.79 | 51.69 | 24.44 |
| Gemini 2.5 Pro | closed | 89.08 | 78.27 | 62.05 | 54.35 | 32.44 |
| GPT-5 | closed | 92.21 | 80.11 | 60.67 | 58.43 | 31.32 |
| GPT-4o | closed | 93.92 | 82.26 | 61.41 | 60.53 | 31.74 |
| GPT-4.1 | closed | 96.22 | 84.08 | 67.14 | 64.89 | 38.06 |
| LLaMA-3.1-8B-Instruct | open <20B | 78.29 | 43.69 | 12.47 | 14.61 | 1.26 |
| Qwen2.5-7B-Instruct | open <20B | 82.40 | 65.01 | 26.38 | 25.84 | 6.04 |
| Qwen2.5-14B-Instruct | open <20B | 81.32 | 70.22 | 46.28 | 38.20 | 18.82 |
| Qwen3-8B | open <20B | 63.05 | 53.61 | 29.30 | 28.65 | 10.67 |
| Qwen3-14B | open <20B | 85.02 | 72.67 | 47.19 | 44.66 | 18.82 |
| LLaMA-3.1-70B-Instruct | open >20B | 89.60 | 47.10 | 17.83 | 16.43 | 2.81 |
| LLaMA-3.3-70B-Instruct | open >20B | 73.00 | 40.32 | 20.54 | 18.26 | 5.34 |
| GLM-4-32B | open >20B | 60.59 | 51.41 | 33.97 | 29.78 | 15.17 |
| Qwen3-32B | open >20B | 79.95 | 70.37 | 46.71 | 41.43 | 19.10 |
| Qwen2.5-32B-Instruct | open >20B | 94.24 | 81.73 | 56.48 | 49.72 | 24.86 |
| Qwen3-30B-A3B-Instruct | open >20B | 94.29 | 80.03 | 53.03 | 47.47 | 21.49 |
| DeepSeek-V3.1-Terminus | open >20B | 86.10 | 75.32 | 56.21 | 49.30 | 28.93 |
GPT-4.1 is the best reported model, but its overall score is only 38.06. That is the most important result: even when function and parameter F1 are high, end-to-end asynchronous task completion remains difficult.
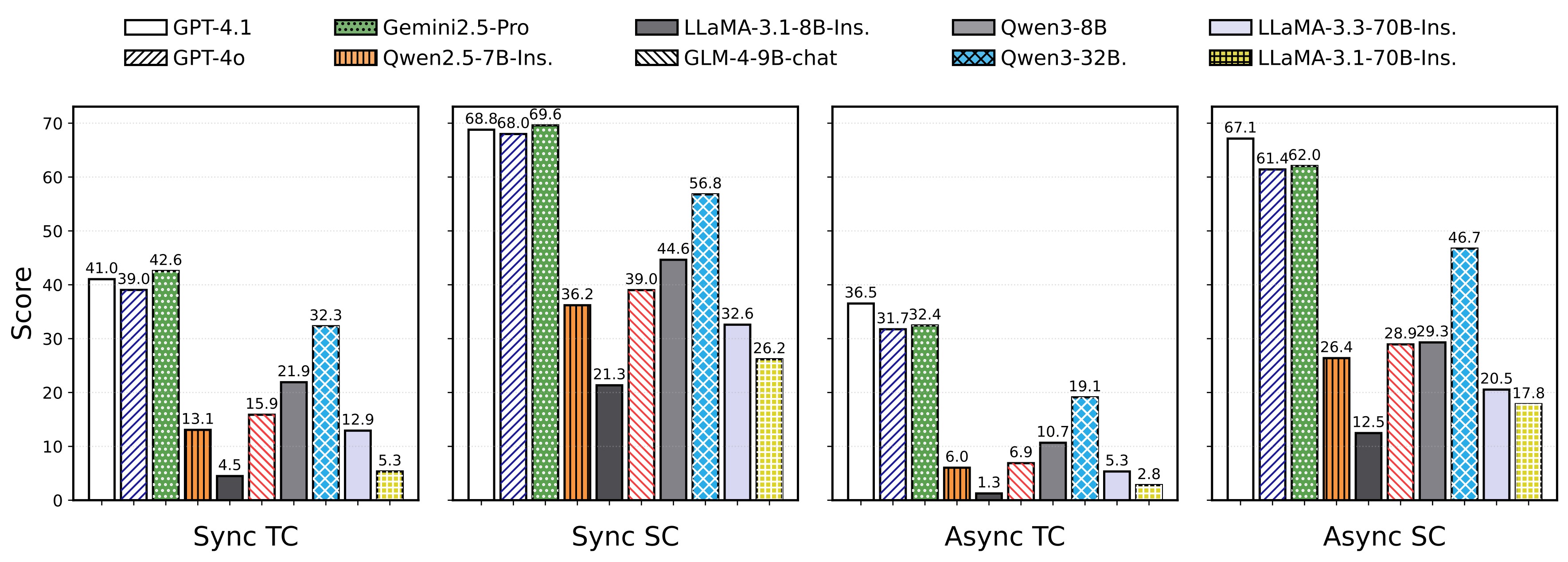
Scheduling And Efficiency
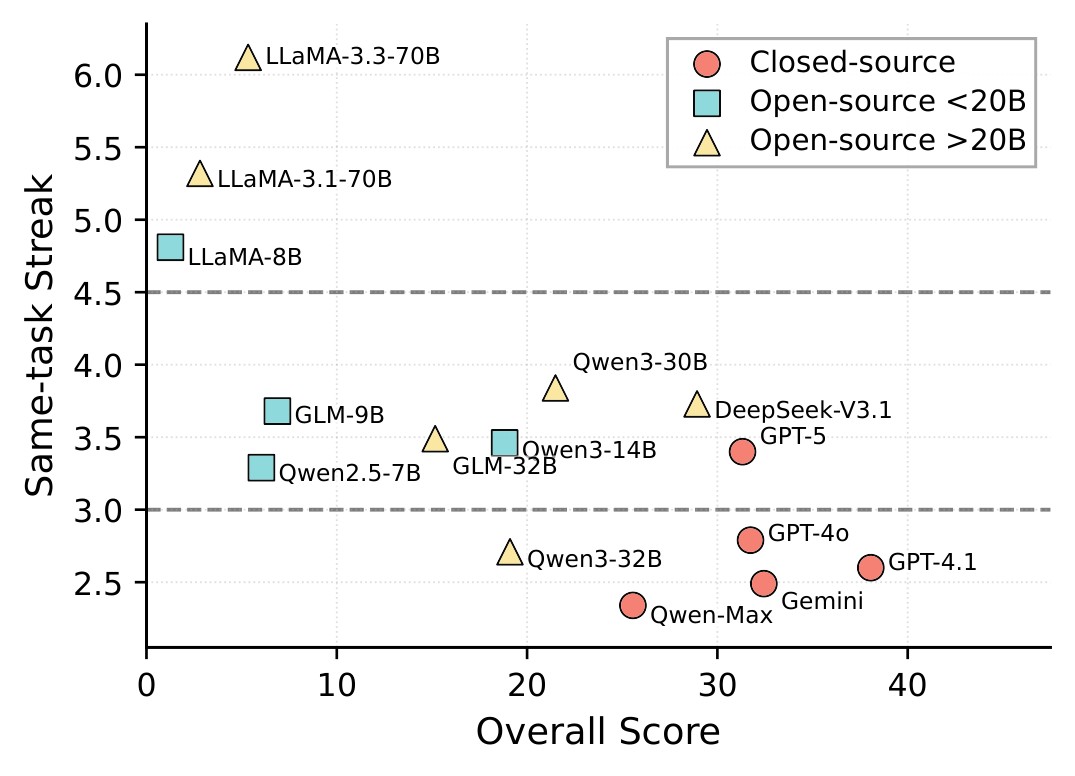
The paper introduces Same-task Streak as an efficiency-oriented behavior metric: the longest consecutive sequence of turns spent on the same task, averaged over samples. Lower values indicate stronger interleaving. Figure 4 shows why this cannot be optimized blindly.
Task Type, Task Count, And Latency
The remaining ablations separate category difficulty from scaling difficulty. Figure 6 shows the task-type heatmap before the task-count and latency tables, making clear that asynchronous difficulty is uneven across tool domains.
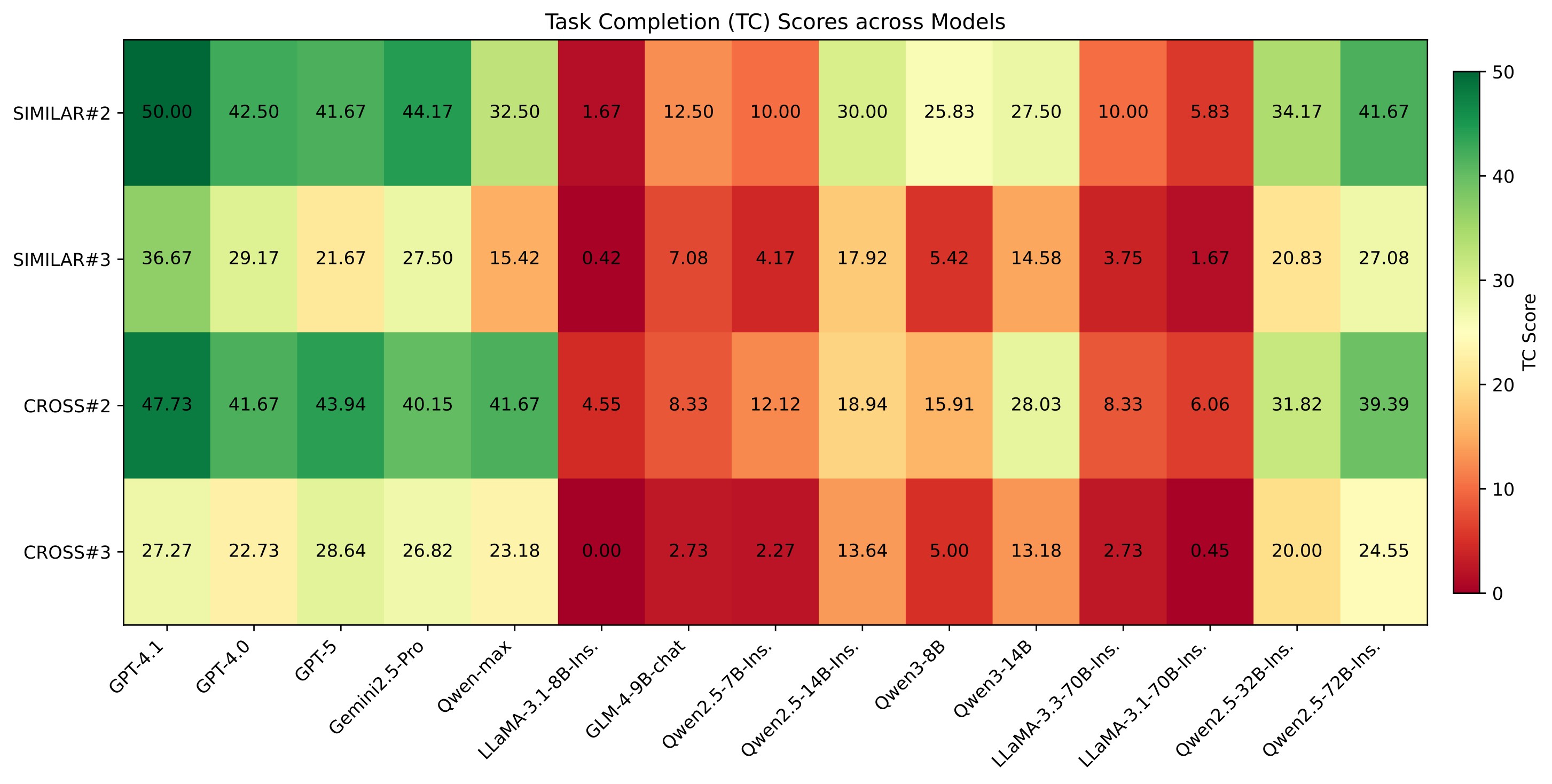
Table 5 uses the appendix task-count experiment to isolate one difficulty factor. Moving from two to three tasks reduces overall scores by about one-third to more than one-half for the four reported open models; moving from three to four tasks causes another large drop.
| Model | #2 overall | #3 overall | Drop #2 to #3 | #4 overall | Drop #3 to #4 |
|---|---|---|---|---|---|
| Qwen2.5-7B-Instruct | 17.06 | 10.87 | 36.28% | 6.33 | 41.77% |
| GLM-4-9B-chat | 21.43 | 12.83 | 40.13% | 8.17 | 36.32% |
| Qwen2.5-72B-Instruct | 50.79 | 33.70 | 33.65% | 22.00 | 34.72% |
| LLaMA3.3-70B-Instruct | 20.63 | 8.70 | 57.83% | 3.67 | 57.81% |
Table 6 summarizes the reported latency ablations for selected closed-source models. Scores are not monotonic across every model and delay regime, but the broader result supports the claim that response timing changes behavior and difficulty.
| Model | Main overall | Fixed delay 2 | Random delay 0-1 | Random delay 1-2 |
|---|---|---|---|---|
| Qwen-Max | 25.56 | 30.76 | 34.41 | 30.20 |
| Gemini 2.5 Pro | 32.44 | 25.70 | 35.25 | 29.35 |
| GPT-4o | 31.74 | 26.54 | 35.53 | 28.79 |
| GPT-4.1 | 38.06 | 26.40 | 34.55 | 29.49 |
The source text's main qualitative conclusion is stronger than the raw ablation table alone: when tool responses are delayed, lower-performing models often continue dependent calls prematurely or hallucinate parameters based on assumed results. Higher-performing models are better at moving to independent tasks and resuming when dependencies are actually available.
Few-shot And Error Modes
Table 7 reports few-shot prompting with one successful trajectory as a reference. It helps several smaller open models, especially LLaMA-3.1-8B and Qwen2.5-14B, but the resulting overall scores remain low in absolute terms.
| Model | Base overall | Few-shot overall | Change |
|---|---|---|---|
| Qwen2.5-7B-Instruct | 6.04 | 8.29 | +2.25 |
| LLaMA-3.1-8B-Instruct | 1.26 | 6.74 | +5.48 |
| Qwen3-8B | 10.67 | 11.24 | +0.57 |
| Qwen2.5-14B-Instruct | 18.32 | 21.91 | +3.59 |
| Qwen2.5-72B-Instruct | 31.04 | 34.55 | +3.51 |
The paper's error analysis identifies three high-level asynchronous failures:
- Premature continuation: the model executes a later dependent call before the previous tool result has returned.
- Task neglect: the model over-focuses on the most recently presented task and fails to complete earlier tasks, especially in tri-task settings.
- Tool confusion: the model switches across tasks but uses a tool from the wrong scenario, causing cascading failures.
These failure modes explain why high function-call fluency does not guarantee high overall score. The hard part is maintaining separate task state and dependency information through delayed, interleaved interactions.
Practical Takeaways
- The reusable idea is the evaluation framing: tool-use agents should be tested as schedulers under delayed feedback, not only as single-threaded function callers.
- The benchmark is useful for agent harness design because its failures map to concrete engineering needs: per-task state tracking, dependency guards, pending-call management, and explicit scheduling policies.
- The main result is sobering: GPT-4.1 leads with 38.06 overall, while many open models have respectable step-level scores but very low task-level success.
- Same-task Streak is a useful diagnostic but not a standalone objective. Frequent switching can be harmful if the agent does not preserve state and dependency order.
- The evidence for benchmark construction is credible from source-side details, but an external audit of dataset determinism and leakage would be needed before treating AsyncTool as fully settled.
- The paper is benchmark-focused; it diagnoses coordination failures but does not provide a new agent architecture that fixes them.