Source-first digest for checked paper rank 38, rank_id p022.
- Routing status:
success - PDF extraction: not used
Motivation / Background
The paper starts from a practical tension in agentic AI. Frontier LLMs are strong enough to run long-horizon tool workflows, but cloud API costs can grow quickly because agents repeatedly plan, act, observe, and recover. Smaller language models can run on phones or laptops and offer privacy, availability, and cost advantages, but they are weaker and have tighter context and KV-cache limits.
The paper studies whether hybrid systems can do more than route a request to either a small or large model. Its main setup gives different roles to the models: an on-device Executor performs the token-heavy ReAct loop, while a cloud Supervisor plans, verifies, replans, or advises only at scheduled intervals. The architecture map in Figure 1 is the entry point for the whole paper.

S, Executor E, environment \mathcal{E}, observations o^t, actions a^t, and supervisor interventions. The paper source also contains the pseudocode text; I summarize its operational differences in Table 1.Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | A cloud-supervised, device-executed MAS can improve over monolithic edge execution while using much less cloud spend than a monolithic cloud agent. | 4 | architecture overview, experimental setup, main trade-off curves, reverse assignment, KV efficiency |
| C2 | There is no single best hybrid MAS architecture: PEVR is better suited to stateful UI assistance, while EVA is better suited to deep-search QA. | 5 | main trade-off curves, domain mechanism analysis, verifier ablation, verifier table |
| C3 | More cloud supervision is not automatically better; too-frequent intervention can degrade performance, especially in deep search. | 5 | main trade-off curves, intervention distributions, false-positive rates |
| C4 | The architecture's restart and verification policy is a mechanism, not just a cost knob: PEVR replans are useful when plans remain actionable, while EVA advice avoids damaging restarts in search. | 4 | architecture comparison, domain mechanism analysis, summarization ablation |
| C5 | The best hybrid direction in their study is device Executor plus cloud Supervisor; reversing the roles is less accurate and more expensive than a cloud-only agent. | 4 | reverse assignment |
| C6 | Hybrid MASs are not equivalent to simple model routing: the best MAS solves some tasks that neither monolithic edge nor monolithic cloud solves. | 3 | task overlap |
| C7 | Context resets help make long-horizon agents more feasible on memory-constrained devices by reducing KV-cache growth while improving AppWorld task success. | 4 | KV-cache equation, KV efficiency table |
| C8 | The reported cost and edge-energy comparison is useful for relative design analysis, but the edge-energy side is an estimate rather than direct device measurement. | 3 | energy model, limitations |
Scores are support-from-paper scores, not independent reproduction scores. Claims about broad deployment are capped when evidence comes from a fixed model family, estimated energy rather than direct device measurement, or a limited set of benchmarks.
Core Technical Idea
The paper adapts two common multi-agent patterns to a cloud-device split. In both, the on-device Executor does the long ReAct trajectory and the cloud Supervisor only checks progress every T_v steps. A supervisor intervention always resets the Executor context, replacing a growing trajectory with a compact handoff.
| Architecture | Initial cloud action | Executor loop | Verification target | Intervention payload | Why it matters |
|---|---|---|---|---|---|
| PEVR: Plan-Execute-Verify-Replan | Supervisor writes an initial natural-language plan. | Executor follows the plan through ReAct tool use. | Supervisor checks alignment with the plan. | A revised plan for the remaining task. | Strong when a detailed plan stays valid and early mistakes are costly. |
| EVA: Execute-Verify-Advise | No initial plan; the Executor receives the user query directly. | Executor acts directly through ReAct tool use. | Supervisor checks progress relative to the query. | A summary of prior work plus advice. | Strong when repeated replanning can disrupt search and the Executor needs lighter correction. |
Table 1. PEVR versus EVA. This table is placed here because the paper's main result is not a new model architecture; it is the interaction between role assignment, verification target, and restart prompt.
The design desiderata are explicit: cover very different model capabilities, keep multi-turn execution on device where possible, expose cloud involvement through a tunable verification interval, and keep edge contexts bounded. That design makes the verification interval a single knob that changes cost, intervention frequency, and context-reset frequency at the same time.
Method Details
Benchmarks And Models
The experimental setup in Table 2 spans short retrieval, long information aggregation, and stateful UI execution. The cloud model is GPT-4o through Azure. Edge Executors are Qwen3 4B, 8B, 14B, and 32B served with vLLM; the 32B setting uses fp8 quantization of KV-cache and weights so it fits on one A100 for the experiments.
| Benchmark | Task character | Metric reported | Main-turn budget | Verification intervals |
|---|---|---|---|---|
| HotpotQA | Short-horizon multi-hop Wikipedia QA | ROUGE-1 F1 | 10 | 1, 2, 3, 5 steps |
| FanOutQA | Longer fan-out information aggregation | ROUGE-1 F1 | 20 | 1, 2, 3, 5, 10 steps |
| AppWorld | Stateful application/API task execution | Test pass ratio and task success | 40 | 1, 2, 4, 8, 16 steps |
Table 2. Experimental setup. This table is reconstructed from the paper text and anchors the later results: AppWorld rewards structured, stateful execution, while HotpotQA and FanOutQA are deep-search settings where restarts can disrupt reasoning.
Cost, Energy, And KV-Cache Accounting
The paper evaluates cloud cost by summing cloud inference costs over a multi-turn trajectory. For Azure GPT-4o, it uses per-token subscription prices from the source text: 2.5 USD per 1M prefill tokens, 1.25 USD per 1M cached tokens, and 10 USD per 1M generated tokens.
For edge energy, the paper uses a back-of-the-envelope operation model rather than direct device measurement. A single inference round is decomposed as:
For dense Transformers, it approximates operations per token as:
so the total operation count is:
Given hardware efficiency \eta in operations per joule, the estimated energy is:
The paper's example for a 4B model with 1000 prompt tokens, 200 generated tokens, and \eta = 1.5 \times 10^{12} Ops/J yields about 6.4 J. This supports relative comparison, but the paper itself notes the model omits DRAM access, CPU/runtime overhead, display and thermal costs, and sustained-efficiency loss.
For memory, the paper tracks maximum context length over each trajectory and estimates KV-cache size as:
where L is layer count, H_{\mathrm{KV}} is the number of key-value heads, d_h is the per-head dimension, b_{\mathrm{act}} is bytes per cached activation, and C is context length. This equation is important because PEVR and EVA do not merely shift compute between models; they periodically shorten the active Executor context.
Experiments And Results
Main Trade-Off Curves
The central empirical result is in Figure 2: across AppWorld, FanOutQA, and HotpotQA, multi-agent configurations create new accuracy-cost operating points between monolithic edge and monolithic cloud systems.
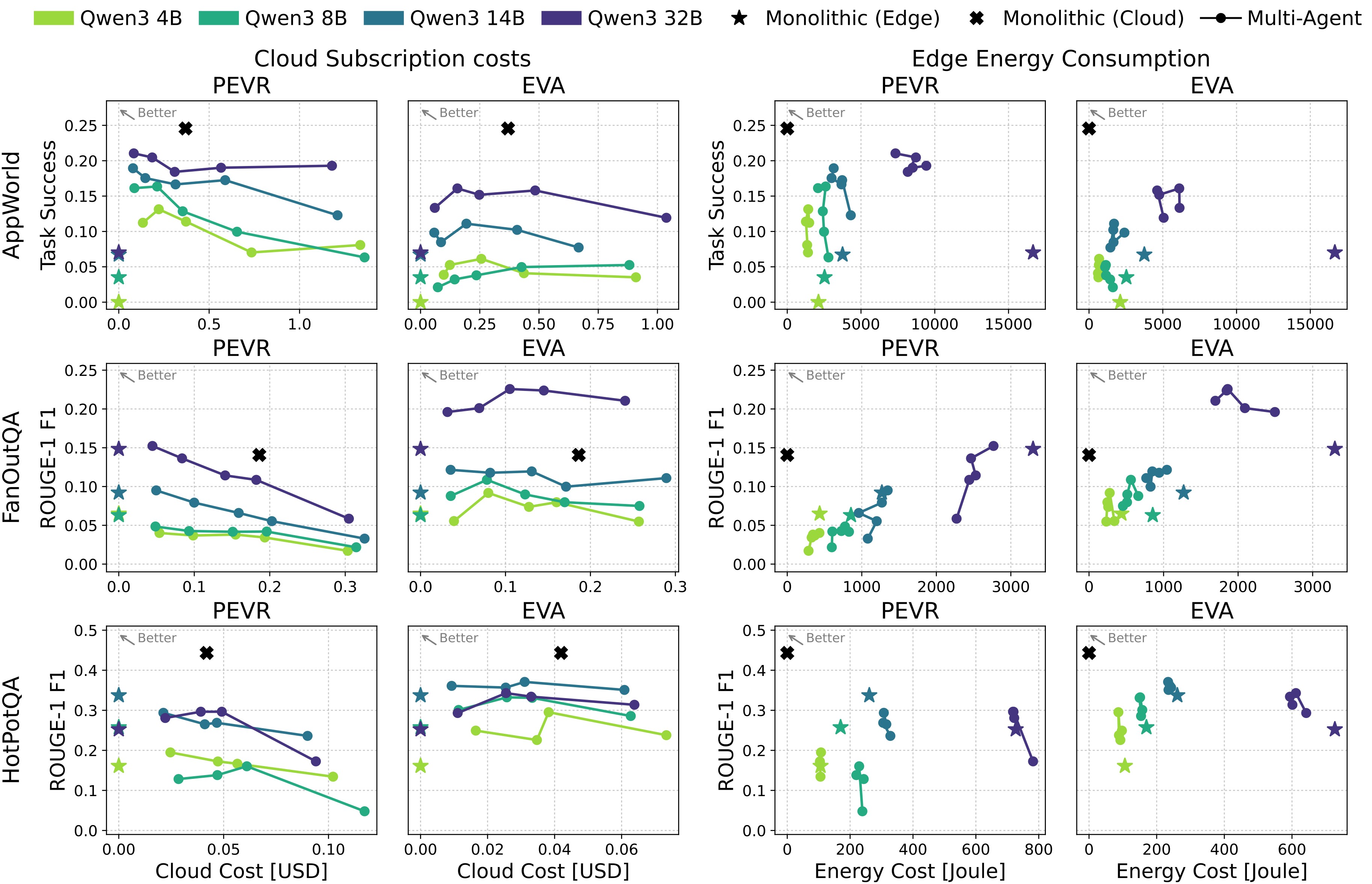
The key observations are:
- Hybrid MASs can outperform monolithic edge models while spending less than a monolithic cloud agent.
- PEVR is strongest on AppWorld, where initial plans and concrete replans help stateful tool execution.
- EVA is stronger on HotpotQA and FanOutQA, where repeated restarts and plan checking tend to interrupt search.
- Increasing cloud involvement is non-monotonic: tighter verification intervals can improve or hurt depending on the domain and architecture.
- Larger Qwen3 Executors generally do better, but architecture and verification interval still determine the final trade-off.
Why PEVR And EVA Split By Domain
Figure 3 makes the mechanism visible. On AppWorld, PEVR and EVA have comparable intervention-count distributions, but PEVR achieves better pass ratios at fixed intervention counts. The paper attributes this to the actionable initial plans and replans in a stateful environment where early mistakes are costly. On FanOutQA, restarts correlate with worse performance, and PEVR intervenes more repeatedly; EVA's more conservative, advice-based behavior is less disruptive.
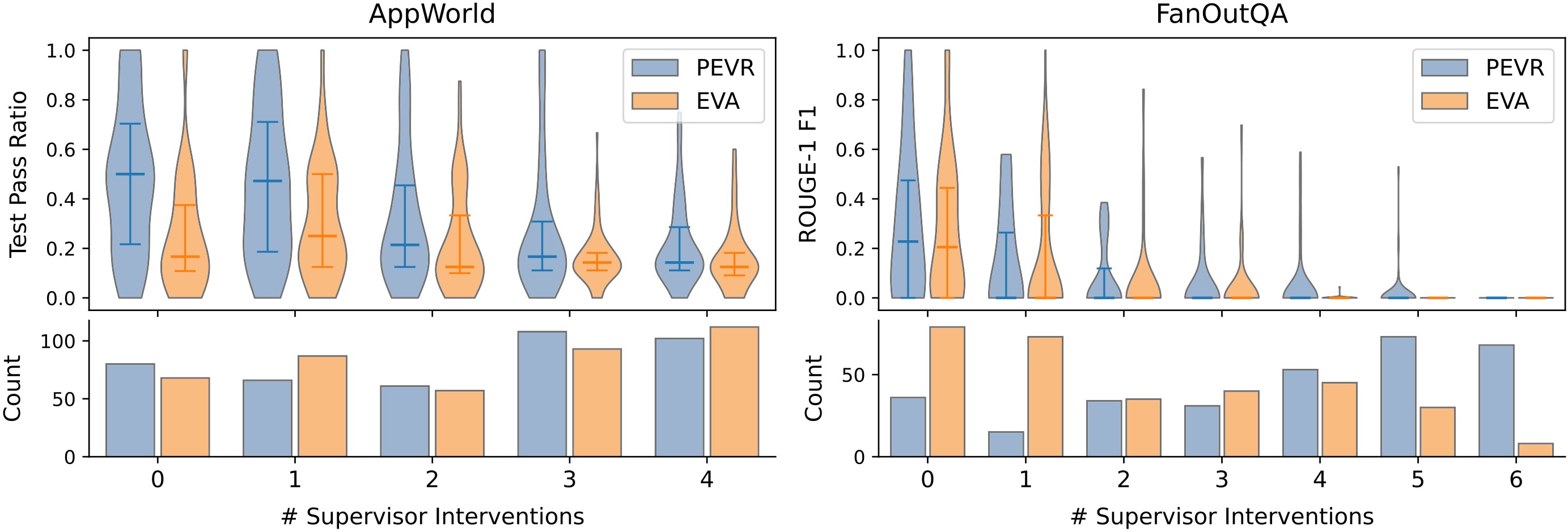
| Benchmark | Verifier | False negative | False positive |
|---|---|---|---|
| AppWorld | Plan-based (PEVR) | 5.3% | 6.2% |
| AppWorld | Query-based (EVA) | 6.0% | 1.9% |
| FanOutQA | Plan-based (PEVR) | 8.4% | 7.7% |
| FanOutQA | Query-based (EVA) | 14.8% | 6.1% |
Table 3. Verifier ablation. The paper labels FanOutQA tasks as successful if ROUGE-1 F1 is greater than 0.5. The table supports C3 and C4: PEVR has fewer false negatives but more false positives, and false positives matter when an unnecessary intervention triggers a harmful restart.
Role Assignment: Why Cloud Supervisor Plus Device Executor Wins
Table 4 compares the intended hybrid direction against the symmetric alternative. The intended direction keeps the token-heavy Executor on device and uses GPT-4o as intermittent Supervisor. The reverse direction puts GPT-4o in the Executor role and uses Qwen as Supervisor. In these experiments, the reverse direction is both less accurate and more expensive than cloud-only execution.
| Executor | Supervisor | AppWorld task success | AppWorld cost USD | FanOutQA ROUGE-1 F1 | FanOutQA cost USD |
|---|---|---|---|---|---|
| GPT-4o | none | 0.25 | 0.37 | 0.14 | 0.19 |
| Qwen 32B | GPT-4o | 0.21 | 0.09 | 0.23 | 0.11 |
| Qwen 14B | GPT-4o | 0.19 | 0.08 | 0.12 | 0.04 |
| Qwen 8B | GPT-4o | 0.16 | 0.08 | 0.09 | 0.04 |
| Qwen 4B | GPT-4o | 0.11 | 0.13 | 0.06 | 0.04 |
| GPT-4o | Qwen 32B | 0.25 | 0.67 | 0.14 | 0.17 |
| GPT-4o | Qwen 14B | 0.19 | 0.79 | 0.10 | 0.17 |
| GPT-4o | Qwen 8B | 0.21 | 0.58 | 0.13 | 0.17 |
| GPT-4o | Qwen 4B | 0.22 | 0.61 | 0.13 | 0.17 |
| Qwen 32B | none | 0.07 | 0.00 | 0.15 | 0.00 |
Table 4. Reverse role assignment. This table was recovered from latex_flattened/main.flattened.tex because paper.md leaves the converted table body empty. It is strong evidence for C5: if the expensive model performs the whole execution trajectory and the cheap model only supervises, the system loses the cost advantage and does not recover better accuracy.
Hybrid MASs Are Not Just Model Routing
The overlap analysis in Figure 4 compares the best monolithic cloud agent, the best monolithic edge agent, and the best MAS configuration. The result is not that one system dominates. Each solves some tasks the others miss, and the MAS solves nontrivial unique subsets: 20 AppWorld tasks, 49 FanOutQA tasks, and 26 HotpotQA tasks are shown in the MAS-only regions.
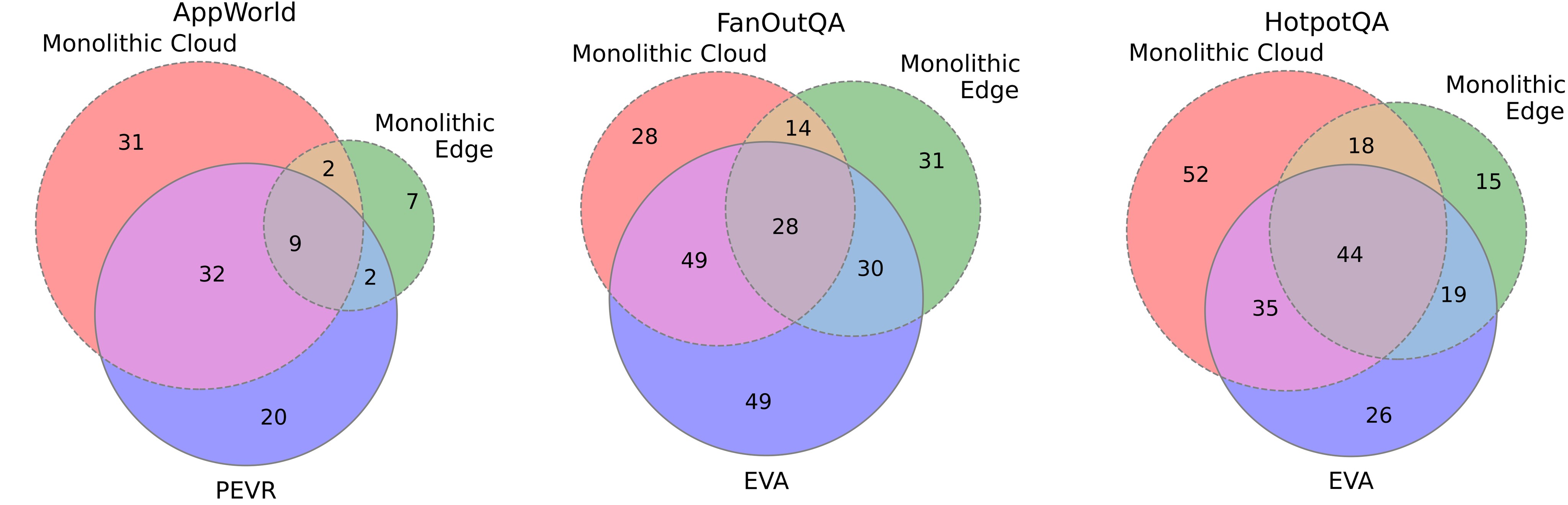
Context Efficiency And KV-Cache Growth
The KV-cache results in Table 5 are the strongest memory-side evidence. On AppWorld, PEVR has higher task success and lower maximum KV-cache footprint than monolithic execution as the turn budget grows. The effect is largest for Qwen3 32B at 80 turns: PEVR reports 0.19 task success and 7.90 GB KV-cache, versus monolithic 0.09 task success and 13.12 GB.
| Max turns | Architecture | Qwen3 8B task success | Qwen3 8B KV GB | Qwen3 32B task success | Qwen3 32B KV GB |
|---|---|---|---|---|---|
| 20 | Monolithic | 0.00 | 3.52 | 0.05 | 6.59 |
| 20 | PEVR | 0.07 | 3.34 | 0.18 | 6.53 |
| 40 | Monolithic | 0.02 | 4.82 | 0.07 | 11.34 |
| 40 | PEVR | 0.09 | 3.65 | 0.16 | 6.98 |
| 80 | Monolithic | 0.00 | 5.17 | 0.09 | 13.12 |
| 80 | PEVR | 0.11 | 3.82 | 0.19 | 7.90 |
Table 5. Context efficiency on AppWorld. This table was recovered from latex_flattened/main.flattened.tex because the numeric body was missing from paper.md. It directly supports C7 by tying context resets to lower KV-cache growth and higher task success.
Summarization Is Not The Whole EVA Story
Figure 5 tests whether EVA's advantage on FanOutQA comes mainly from summarizing prior work after a restart. Removing summarization does not substantially change EVA, while PEVR still degrades as cloud cost/interventions rise. The paper concludes that the PEVR/EVA gap is more likely caused by verifier criteria and restart prompt type than by summarization alone.
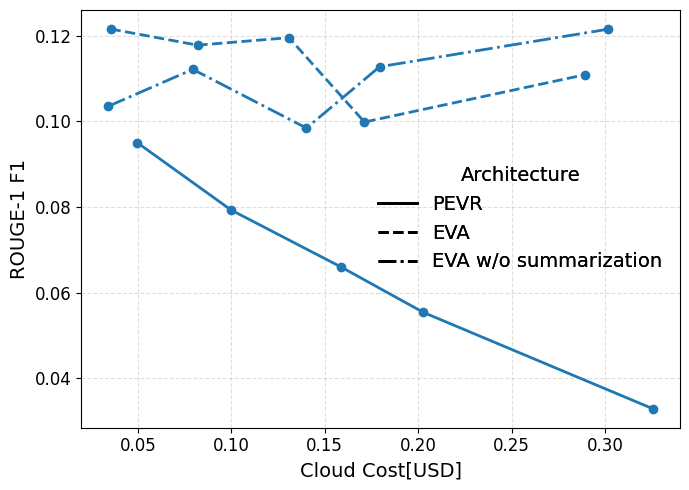
Limitations
The paper is careful about several limits. It evaluates three domains, but does not include robotics or coding agents. It fixes the cloud model to GPT-4o and the edge family to Qwen3 variants. The cost and compute burden led the authors to prioritize breadth over multi-seed repetitions. The edge energy model is explicitly a comparative estimate, not direct measurement on physical mobile or laptop hardware.
Practical Takeaways
- Hybrid agent systems should assign roles, not just route requests. The paper's best pattern keeps long execution on device and uses the cloud for sparse supervision.
- The verification interval is a performance knob, not simply a cost knob. More cloud calls can inject better feedback, but they can also cause harmful restarts.
- The right supervision style depends on task shape. PEVR-style explicit plans help stateful UI workflows; EVA-style advice is safer for search-like tasks where maintaining a long reasoning thread matters.
- Context reset is a concrete systems benefit. Even when accuracy gains are modest, bounded Executor context can reduce KV-cache growth enough to matter for edge deployment.
- The energy numbers should be treated as order-of-magnitude design evidence. Direct device measurements would be needed before making hardware or battery-life claims.
- A promising follow-up is a dynamic controller that chooses PEVR, EVA, monolithic edge, or monolithic cloud per task, because the Venn analysis shows no fixed configuration owns all successful cases.