Source-first digest for checked paper rank 32, rank_id p024.
- Routing status:
success - PDF extraction: not used
- Table recovery: malformed numeric tables in
paper.mdwere checked againstlatex_flattened/main.flattened.tex
Motivation / Background
Terminal agents need to solve long-horizon command-line tasks where progress depends on partial observations, changing filesystem or system state, tool feedback, and persistent goal tracking. LiteCoder-Terminal argues that this setting is not well covered by repository patch-generation tasks such as SWE-bench: terminal work requires interactive adaptation to raw text feedback and latent environment changes, not only editing code against a static issue.
The training bottleneck is data. Existing terminal-agent resources often rely on mined repositories, GitHub issues, Stack Overflow-style material, or opaque closed training recipes. LiteCoder-Terminal proposes a zero-dependency alternative: synthesize executable terminal tasks, their environments, reference solutions, and verifiers directly from domain specifications. The first stage of that source-free pipeline is shown in Figure 1.
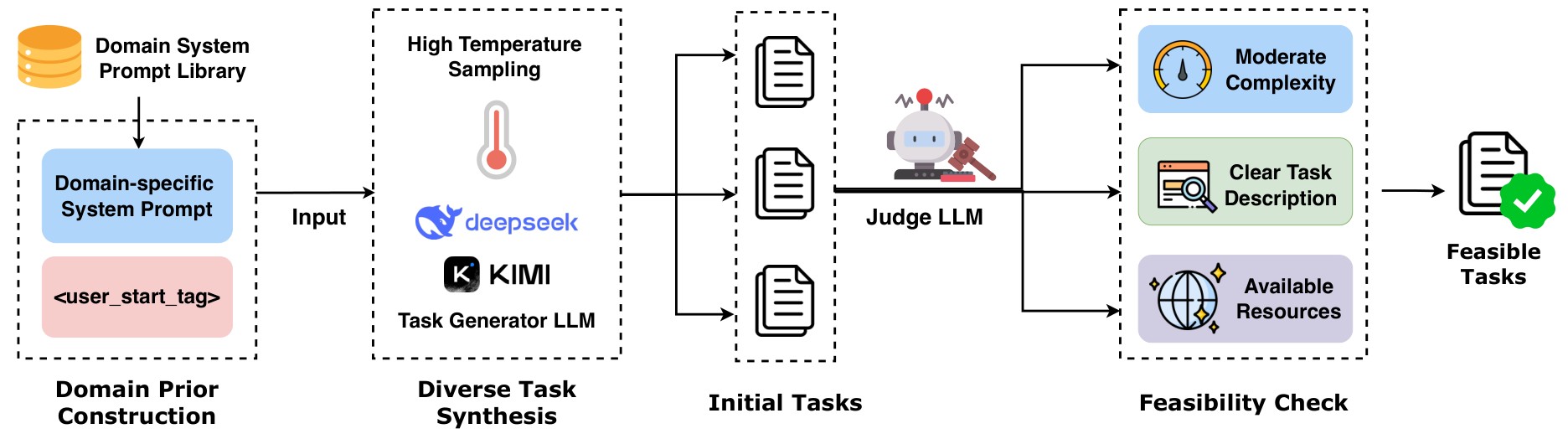
LiteCoder-Terminal-Gen. Starting from a target terminal domain, the system constructs a domain-specific prompt prefix that elicits a raw task description from the LLM, then applies a feasibility check that retains only tasks satisfying criteria such as moderate complexity, a clear task description, and available resources. I place it here because it is the clearest evidence for the paper's claim that tasks can be generated from domain specifications rather than scraped examples.The resulting resources are LiteCoder-Terminal-SFT, with 11,255 expert trajectories across 10 domains, and LiteCoder-Terminal-RL, with 602 executable and verifiable environments for preference optimization. The paper then fine-tunes Qwen-family models and evaluates them on Terminal Bench 1.0, Terminal Bench 2.0, Terminal Bench Pro, and SWE-bench.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | A zero-dependency generator can synthesize executable, verifier-backed terminal environments from high-level domain specifications. | 4 | domain-to-task, environment synthesis, environment-synthesis figure, Harbor task format |
| C2 | The generated data resource is broad enough to exercise realistic long-horizon terminal behavior. | 4 | dataset statistics, command coverage, trajectory filtering, decontamination |
| C3 | Supervised fine-tuning on LiteCoder-Terminal-SFT improves Qwen-family terminal agents across Terminal Bench variants. |
5 | main benchmark table, training setup |
| C4 | The synthetic environment approach is data-efficient compared with larger mined terminal-agent corpora. | 4 | main benchmark table, baseline comparison |
| C5 | The 602 generated RL environments and verifiers provide a usable reward signal for trajectory-level preference optimization. | 4 | DMPO objective, DMPO results |
| C6 | Capability does not depend on a single task domain; games and security are the most sensitive removals, but all leave-one-domain drops are modest. | 4 | domain ablation |
| C7 | Terminal SFT improves test-time scaling and transfers some behavior to repository-level SWE-bench tasks. | 3 | test-time scaling, SWE-bench transfer, limitations |
Scores are support-from-paper scores, not independent reproduction scores. Claims about generated environment validity are capped below 5 unless they are backed by external benchmark results, because the digest did not independently inspect the released tasks or rerun verifiers.
Core Technical Idea
LiteCoder-Terminal-Gen turns a high-level terminal domain into executable agent training data through a staged synthesis pipeline:
1. Sample domain-conditioned task descriptions with a Magpie-like LLM prompting strategy. 2. Filter tasks for feasibility, clarity, moderate complexity, and available resources. 3. Convert feasible descriptions into self-contained terminal environments. 4. Generate a reference solution and verifier so each task has an executable success signal. 5. Collect expert trajectories and train language agents with SFT, then optionally improve them with verifier-grounded preference optimization.
The key design choice is to synthesize the whole task bundle from scratch. The paper is not only generating natural-language instructions; it also materializes files, Docker setup, reference solutions, tests, reward logging, and task metadata.
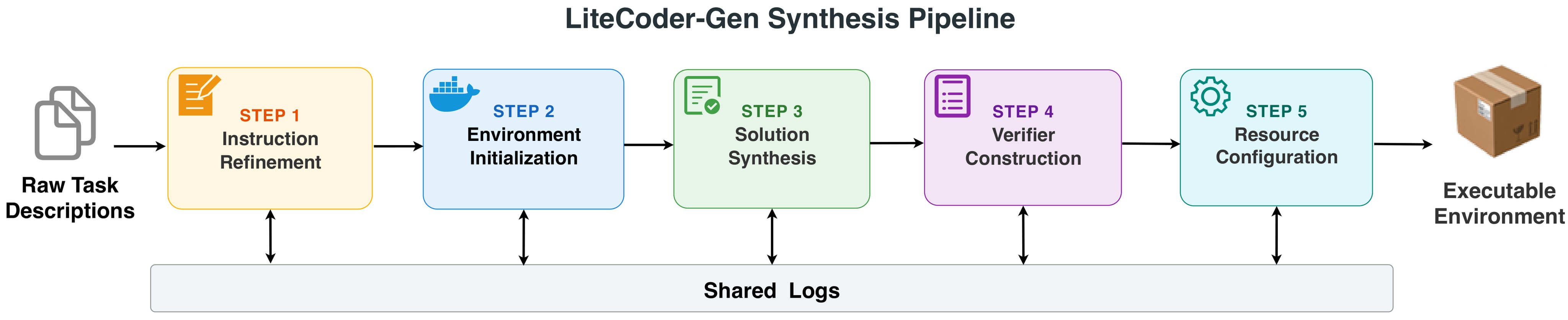
LiteCoder-Terminal-Gen. Each raw task description is expanded into a full executable environment through a five-stage sequential pipeline - instruction refinement, environment materialization, solution synthesis, verifier crafting, and config derivation - with every stage reading from a shared log directory to prevent inter-stage drift. This figure supports the claim that generated tasks are grounded in earlier artifacts rather than free-floating prompts.Method Details
Domain-To-Task Generation
The paper defines 10 terminal domains: AI&ML, build tools, data science, networking, security, system administration, version control, coding, scientific computing, and games. For each domain, it uses a domain-specific prompt prefix and asks the model to complete a missing user turn. The feasibility filter rejects generated tasks that are too vague, too hard, dependent on unavailable resources, or not practical inside a CPU-only, single-machine Docker environment. The prompt template in the appendix asks for a task title, domain focus, objective, scenario, and a 6-10 item todo checklist.
Executable Environment Synthesis
LiteCoder-Terminal-Gen then expands each raw task through five agents:
- Instruction refinement: rewrite the task into a testable
instruction.md, binding inputs and outputs to concrete/apppaths and deterministic formats. - Environment initialization: create an
environment/directory with a Dockerfile and input artifacts, extending a fixed Ubuntu 24.04 base image. - Solution synthesis: write a complete
solution/solve.shthat satisfies the instruction and acts as a solvability check. - Verifier generation: write
tests/test.shandtests/test_outputs.py, with the shell entrypoint writing a binary reward to/logs/verifier/reward.txt. - Resource configuration: write
task.tomlwith verifier, agent, and build timeouts plus CPU, memory, and storage quotas.
The generated task uses the Harbor format: instruction, environment setup, reference solution, tests, and configuration. Each generation stage reads the shared agent_logs/ from previous stages, and each stage ends with lightweight existence checks for its expected artifacts. This is important because the verifier is generated after the reference solution, so the paper explicitly asks the verifier agent to use a four-phase adversarial iteration: draft, attack with lazy solutions, refine against legitimate alternative solutions, and finalize.
Trajectory Collection, Filtering, And Decontamination
For SFT, the authors collect trajectories with Harbor using MiniMax M2 and M2.1 teacher models across Terminus, Claude Code, and OpenHands scaffolds. A retained trajectory includes the agent's reasoning, shell commands, and environment observations, which is the supervision signal for long-horizon thought-action-observation loops.
The filtering judge removes trajectories that show:
- Adaptability failures: command loops or tiny syntax tweaks without a real strategy change.
- Groundedness failures: ignoring tool errors, claiming success without verification, or drifting away from observed state.
- Persistence failures: giving up immediately after a missing command or environmental obstacle.
- Explicit refusal: refusing the task.
The final SFT set is decontaminated with strict 13-gram overlap filtering against Terminal Bench evaluation queries. This does not prove semantic non-overlap, but it is concrete evidence that the paper attempted benchmark leakage control.
Training And DMPO
The experiments fine-tune Qwen3-4B-Instruct, Qwen3-30B-A3B-Instruct, and Qwen2.5-Coder-32B-Instruct into LiteCoder-Terminal models. The appendix reports AutoAlign training with DeepSpeed ZeRO-3 on 8 GPUs per node, AdamW at learning rate \(5 \times 10^{-6}\), cosine scheduling, 0.04 warmup ratio, 0.1 weight decay, 3 epochs, BF16 precision, gradient checkpointing, and a 65,536-token maximum sequence length.
For LiteCoder-Terminal-RL, the paper uses Direct Multi-turn Preference Optimization rather than treating a whole trajectory as a one-step DPO sample:
Here \(s_t\) and \(a_t\) are state and action sequences at turn \(t\). The normalized discount factor is:
The authors start from LiteCoder-Terminal-4b-sft, sample two independent rollouts per one of the 602 RL environments, compute each rollout's verifier pass ratio, and keep environments where the two rollouts differ. The higher-scoring rollout becomes the preferred trajectory and a lower-scoring trajectory from the same environment becomes the rejected trajectory.
Experiments And Results
Dataset Statistics And Command Coverage
LiteCoder-Terminal-SFT contains 11,255 expert trajectories across 10 task categories, with an average of 27.4 turns per trajectory. The source reports a roughly balanced category distribution, with system administration at 11.6%, networking at 11.6%, build tools at 12.0%, and scientific computing as the smallest group at 7.3%. Scaffold composition is Terminus-2 at 86.6%, OpenHands at 7.1%, and Claude Code at 6.3%. Figure 3 shows both the domain distribution and the most frequent commands.
The command coverage analysis tokenizes the first command of each keystroke entry, intersects the vocabulary with the tldr-pages Linux command index, and reports more than 720 real Linux commands. The paper highlights common tools such as cat, ls, grep, git, pip, cargo, make, gcc, curl, and openssl, plus rarer tools such as mongod, kubeadm, grafana-cli, bison, nasm, and lvcreate.
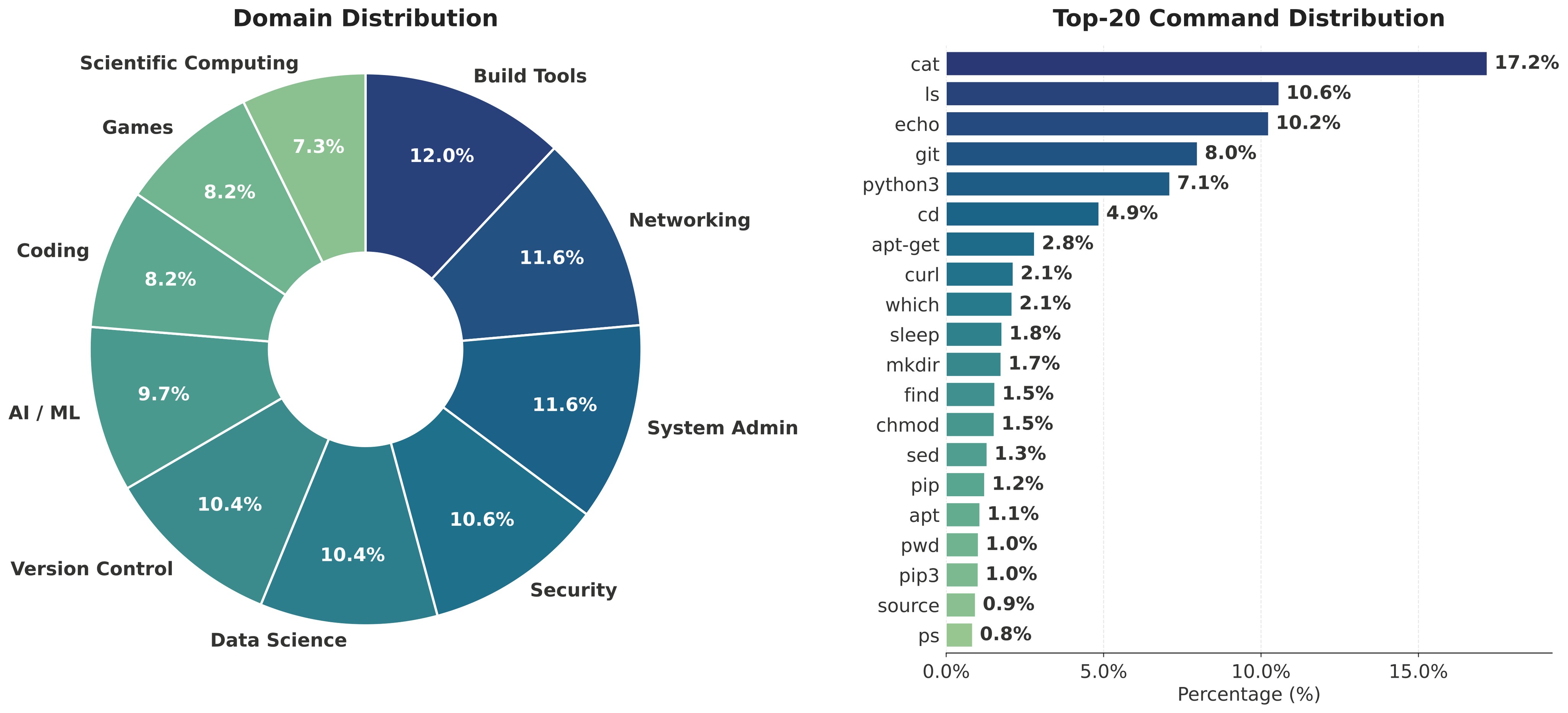
LiteCoder-Terminal-SFT dataset. This figure is included because the dataset-diversity claim depends on both domain balance and actual command usage, not just the number of generated tasks.Terminal Bench Results
Table 1 is the paper's main quantitative evidence for SFT. It reports pass@1 on Terminal Bench 1.0, Terminal Bench 2.0, and Terminal Bench Pro, and pass@4 on Terminal Bench 1.0 and 2.0. The values below were recovered from latex_flattened/main.flattened.tex because the converted Markdown table was malformed.
| Model | Scaffold | Pass@1 TB-1 | Pass@1 TB-2 | Pass@1 TB-Pro | Pass@1 Avg. | Pass@4 TB-1 | Pass@4 TB-2 | Pass@4 Avg. |
|---|---|---|---|---|---|---|---|---|
| Qwen3-4B-Instruct | Terminus-2 | 6.25 +/- 1.77 | 1.12 +/- 1.12 | 3.50 | 3.62 | 15.00 | 3.37 | 9.19 |
| Qwen3-30B-A3B-Instruct | Terminus-2 | 16.56 +/- 3.29 | 5.34 +/- 1.69 | 20.50 | 14.13 | 28.75 | 11.24 | 20.00 |
| Qwen2.5-Coder-32B-Instruct | Terminus-2 | 12.19 +/- 3.08 | 4.49 +/- 1.72 | 13.50 | 10.06 | 20.00 | 8.99 | 14.50 |
| OpenThinker-Agent-v1 | Terminus-2 | 11.25 +/- 1.77 | 4.49 +/- 3.18 | 19.50 | 11.75 | 25.00 | 10.10 | 17.55 |
| Qwen3-30B-A3B-Nex-N1 | OpenHands | 18.44 +/- 3.13 | 12.36 +/- 2.05 | 21.00 | 17.27 | 32.50 | 23.60 | 28.05 |
| Qwen3-32B-Nex-N1 | OpenHands | 24.69 +/- 1.56 | 18.54 +/- 1.95 | 30.50 | 24.58 | 35.00 | 26.97 | 30.99 |
| TerminalTraj-32B | Terminus-2 | 33.44 +/- 3.44 | 23.88 +/- 2.95 | 30.50 | 29.27 | 45.00 | 37.08 | 41.04 |
| Nemotron-Terminal-32B | Terminus-2 | 27.81 +/- 3.29 | 21.35 +/- 2.75 | 37.00 | 28.72 | 46.25 | 35.96 | 41.11 |
| LiteCoder-Terminal-4b-sft | Terminus-2 | 14.69 +/- 1.20 | 4.78 +/- 1.83 | 21.50 | 13.66 | 28.75 | 10.11 | 19.43 |
| LiteCoder-Terminal-30b-a3b-sft | Terminus-2 | 24.38 +/- 1.61 | 12.36 +/- 2.75 | 31.50 | 22.75 | 40.00 | 23.60 | 31.80 |
| LiteCoder-Terminal-32b-sft | Terminus-2 | 29.06 +/- 4.18 | 18.54 +/- 3.40 | 34.00 | 27.20 | 45.00 | 30.34 | 37.67 |
Table 1. Terminal task benchmark results. Original caption: Terminal task benchmark results at pass@1 and pass@4 (%). TB-1 / 2 / Pro stands for Terminal Bench-1.0 / 2.0 / Pro.
The paper's strongest result is the matched-backbone comparison: the 4B, 30B-A3B, and 32B fine-tuned models improve over their base models on all pass@1 benchmarks. The 32B model moves from 12.19% to 29.06% on TB-1, 4.49% to 18.54% on TB-2, and 13.50% to 34.00% on TB-Pro. The 4B and 30B-A3B variants also show clear pass@4 gains, indicating that the learned policy gives sampling a more useful search space.
The data-efficiency claim is plausible but not airtight. The paper notes that LiteCoder-Terminal-SFT has 11.2K trajectories versus 50.7K for TerminalTraj and 490.5K for Nemotron-Terminal, and that the 32B model is competitive in average pass@1. But Table 1 also shows TerminalTraj and Nemotron leading on average pass@4 and Nemotron leading on TB-Pro pass@1. The paper additionally notes a timeout-reproduction caveat for Nemotron, so this digest scores the data-efficiency claim as mostly supported, not fully settled.
DMPO Results
Table 2 evaluates whether the generated RL environments and verifiers provide useful preference signals for Qwen3-4B-Instruct.
| Method | TB-1 | TB-2 | TB-Pro | Avg. |
|---|---|---|---|---|
| SFT Baseline | 14.69 | 4.78 | 21.50 | 13.66 |
| + DMPO | 14.38 | 6.10 | 23.00 | 14.49 |
Table 2. DMPO effect. Original caption: Effect of DMPO on pass@1 (%) for Qwen3-4B-Instruct.
DMPO improves the average from 13.66 to 14.49 and improves the harder TB-2 and TB-Pro settings, but TB-1 drops slightly from 14.69 to 14.38. The result supports the verifier-grounded RL claim, but only for the 4B setting and with modest absolute gains.
Domain Ablation
Table 3 tests whether the dataset is carried by one dominant domain. The paper reports leave-one-domain-out SFT on a balanced subset. The Markdown table lost the impact values, so this digest recovers the full table from main.flattened.tex.
| Removed domain | TB-1 | TB-2 | TB-Pro | Avg. | Impact on Avg. |
|---|---|---|---|---|---|
| Full Data (Baseline) | 14.69 | 4.78 | 21.50 | 13.66 | - |
| w/o games | 11.88 | 5.60 | 16.00 | 11.16 | down 2.50 |
| w/o security | 11.25 | 4.78 | 18.50 | 11.51 | down 2.15 |
| w/o version control | 12.81 | 3.93 | 19.50 | 12.08 | down 1.58 |
| w/o coding | 13.44 | 5.30 | 17.50 | 12.08 | down 1.58 |
| w/o data science | 13.13 | 6.18 | 17.50 | 12.27 | down 1.39 |
| w/o ai_ml | 10.94 | 5.62 | 20.50 | 12.35 | down 1.31 |
| w/o system admin | 14.06 | 7.86 | 16.00 | 12.64 | down 1.02 |
| w/o networking | 13.75 | 5.90 | 19.50 | 13.05 | down 0.61 |
| w/o build tools | 16.88 | 4.50 | 18.50 | 13.29 | down 0.37 |
| w/o scientific comp. | 14.38 | 4.78 | 21.00 | 13.39 | down 0.27 |
Table 3. Domain ablation. Original caption: Domain ablation results. We report the performance after removing each domain from the training mixture. Domains are sorted by their impact on the average score, highlighting their relative importance to the model's overall capability.
The ablation supports a distributed-skill interpretation: every removal degrades average performance, but no single domain destroys the model. The sharpest drops come from removing games and security, which the authors interpret as demanding edge-case reasoning and complex dependency management.
Test-Time Scaling And SWE-Bench Transfer
The paper argues that SFT changes not just pass@1 but the ability to exploit extra samples. Figure 4 shows pass@k for 4B and 30B-A3B models on Terminal Bench 1.0 and 2.0. The text highlights that the 30B-A3B LiteCoder-Terminal model scales from 24.4% at \(k=1\) to 40.0% at \(k=4\) on TB-1, a 15.6-point gain.
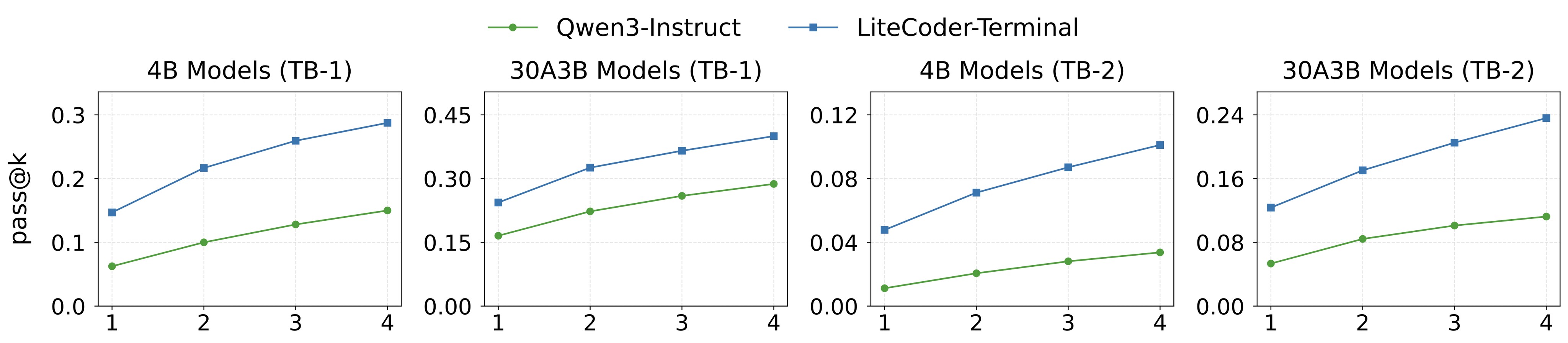
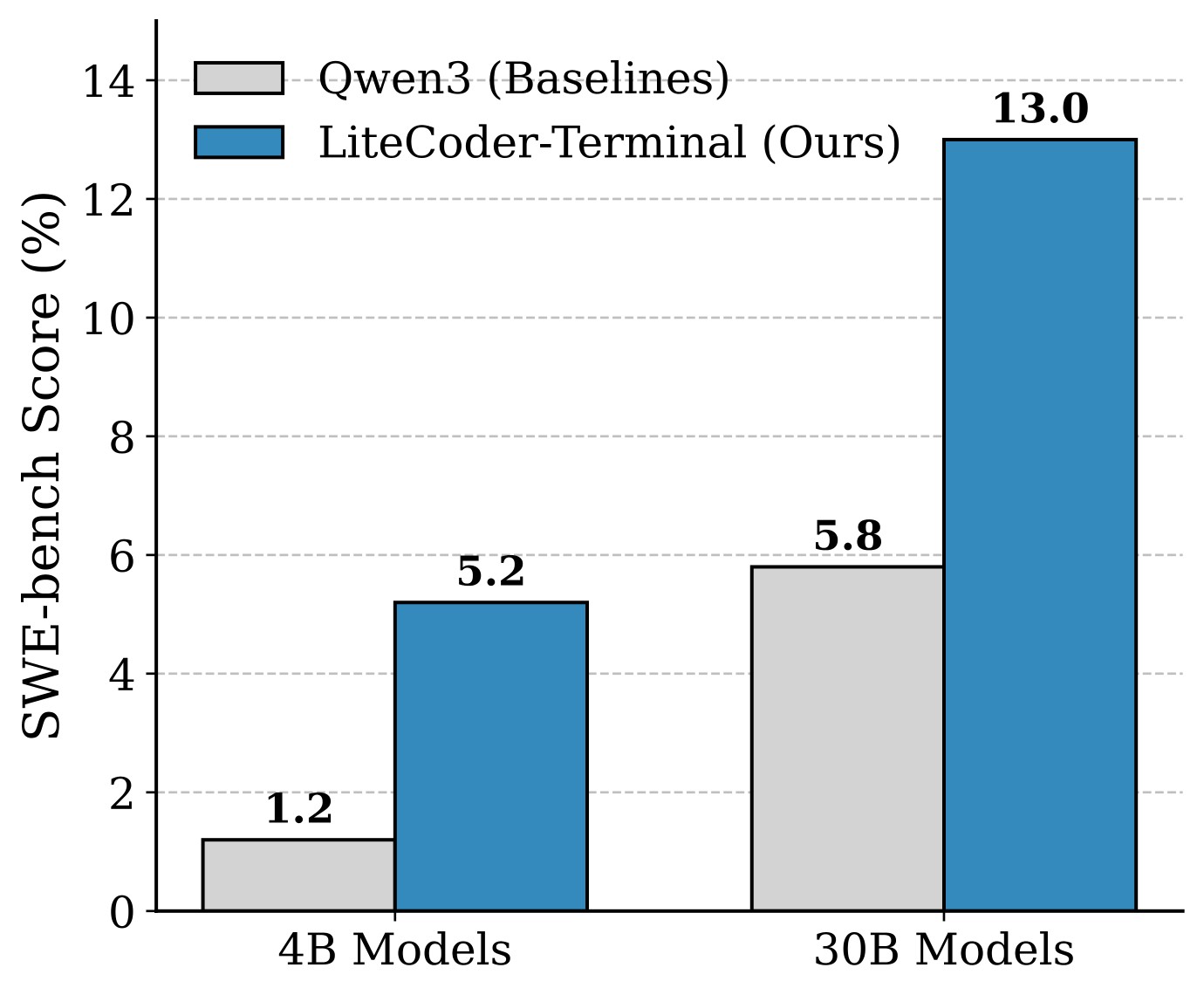
Qwen3-Instruct; blue: LiteCoder-Terminal fine-tuned on SFT trajectories. This supports the idea that synthetic terminal trajectories improve exploration under multiple attempts, not only first-shot accuracy.The paper also evaluates SWE-bench transfer, shown in Figure 5. The reported resolution rate rises from 1.2% to 5.2% for the 4B model and from 5.8% to 13.0% for the 30B-A3B model. This is useful evidence that terminal interaction data can transfer to repository-level tasks inside the same agent scaffold, but the paper states that the pipeline was not explicitly optimized for SWE-bench.
Limitations
The paper names two limitations. First, task instructions are generated with LLM completion, so the task distribution inherits generator-model biases. Second, all environments use Ubuntu-based Docker images and mostly exercise GNU/Linux utilities. That means the claimed terminal-agent capability may overfit Linux command conventions unless future data expands to other distributions and operating systems.
Practical Takeaways
- The most reusable idea is the full task-bundle synthesis pipeline: generate the instruction, environment, reference solution, verifier, and resource config together, with each stage reading prior logs.
- The verifier design is the critical part. The paper's four-phase verifier prompt is an explicit attempt to avoid tests that only accept the reference solution or accidentally reward lazy outputs.
- The quantitative SFT evidence is strong for matched Qwen backbones. The cleanest takeaway is that 11.2K synthesized trajectories can substantially improve Terminal Bench pass@1 and pass@4.
- The comparison against larger mined datasets is encouraging but not decisive. Some larger baselines remain stronger on average pass@4 and TB-Pro, and scaffold/timeout choices matter.
- DMPO is promising but small in scope here: it helps TB-2 and TB-Pro for the 4B model, while TB-1 slightly drops.
- The biggest follow-up questions are whether the generated tasks are semantically diverse beyond surface command coverage, whether verifiers accept multiple valid solutions in practice, and how well the approach transfers outside Ubuntu/GNU/Linux terminal assumptions.