Source-first digest for checked paper rank 11, rank_id p026.
- Routing status:
success - PDF extraction: not used
Motivation / Background
The paper starts from a gap between deep search and deep research. Deep search usually aims at short, checkable answers, while deep research asks an agent to synthesize scattered evidence into a long report. That second setting is harder to verify because there is no deterministic ground truth, and it is harder to present well because useful reports need text interleaved with charts, diagrams, screenshots, and other visual evidence.
The authors argue that existing deep-research systems fail in two coupled ways: mistakes from early search and planning stages can propagate into final reports, and images are often inserted as post-hoc decoration instead of being tied to claims, citations, and section intent. Figure 1 makes this framing concrete: images can reduce cognitive load and support claims, but the same visual channel can harm credibility through invalid references, uninformative images, or poor placement.

Claims And Evidence
The digest's evidence map is Table A. Scores are support-from-paper scores, not independent reproduction scores.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Ptah turns multimodal deep research into a staged, inspectable workflow rather than a single monolithic generation pass. | 4 | motivation, harness overview, planning/research/writing details |
| C2 | Visual evidence is treated as structured working state through visual requirements, webpage image extraction, VLM selection, and Visual Working Memory. | 4 | harness overview, visual working memory, example reports |
| C3 | A verifier agent improves stability and factual grounding by checking stage outputs, citations, protocol compliance, and cross-modal consistency. | 4 | method stages, FACT results, verifier ablation, verifier latency |
| C4 | PtahEval fills a measurement gap by adding image-level and rendered-page presentation scores to existing deep-research benchmarks. | 5 | PtahEval protocol, PtahEval scores |
| C5 | Ptah improves multimodal report quality and credibility over the evaluated baselines. | 4 | content results, PtahEval scores, FACT results, human evaluation |
| C6 | Test-time scaling contributes to content quality, image quality, and rendered HTML quality. | 4 | TTS method, TTS ablation |
| C7 | The multi-agent decomposition is not only a quality device; parallel section-level research reduces wall-clock research latency. | 4 | stage latency, parallel latency |
| C8 | The system remains bounded by current open-source model reliability and by manually defined stage boundaries. | 5 | limitations |
Core Technical Idea
Ptah is a harness around agents, tools, intermediate state, and verification. The paper does not propose a new foundation model. Its contribution is an execution pattern for long-form multimodal report generation: make the report plan visual-aware, let researchers collect claim-grounded text and source-aligned image candidates, then let a writer compose an interleaved report through declarative image operations.
The task formulation represents a report as ordered blocks:
where each block is either text \(t_i\) or a visual element \(v_i\). During execution, the harness maintains a state \(s_t = (q, \mathcal{M}_t, \tau_{<t})\), where \(\mathcal{M}_t\) contains plans, evidence, citations, numerical data, and visual candidates. That state is the key object: the system does not just produce prose; it accumulates inspectable intermediate artifacts before final rendering.
The full Planning-Research-Writing lifecycle is summarized in Figure 2.
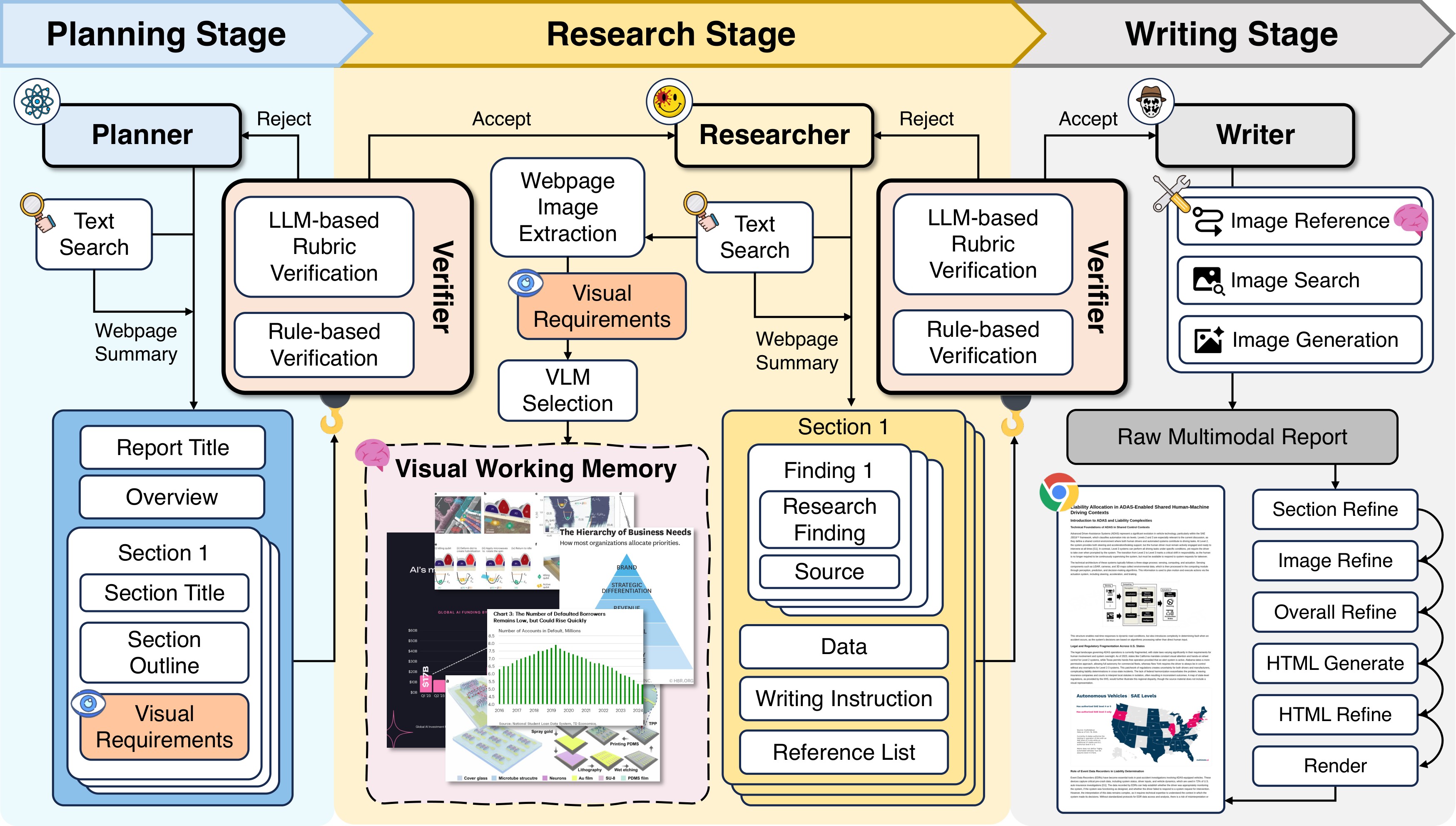
The verifier is placed between lifecycle stages rather than only after final generation. This matters because the paper's problem is error accumulation: bad plans, unsupported research packages, invalid references, or misaligned images become harder to fix once they are already woven into a final report.
Method Details
Planning Stage
The planner uses text search to explore the user's query and emits a structured plan. The plan contains an overview, section-level research goals, expected evidence types, and explicit visual specifications. Those visual specifications say what kind of image should support a section, where it should appear, and what communicative role it should serve.
The verifier checks the plan in two ways. Rule-based checks validate interaction protocol, tool-use constraints, and JSON format. LLM-based rubric checks assess query coverage, section coherence, and whether visual requirements actually match the intended argument. Failed plans are revised before research starts.
Research Stage
For each planned section, a researcher performs an independent investigation. The output is a structured research package containing key findings, evidence, numerical data, tables, references, and writing instructions. This decomposition is meant to support broad coverage without losing traceability.
In parallel, researchers extract candidate images from visited webpages. Low-resolution, duplicated, irrelevant, or non-informative images are filtered out, and a VLM selector keeps images that satisfy the planner's visual requirements. Retained images are stored in Visual Working Memory with source URL, surrounding context, section association, and intended role. This is the paper's main design answer to post-hoc image insertion.
Writing Stage
The writer receives the global plan, verified research packages, and Visual Working Memory. It generates text and image directives jointly, then the harness arbitrates among three image operations:
- Image Reference: reuse a source-aligned image from Visual Working Memory.
- Image Search: retrieve an additional web image when Visual Working Memory is insufficient.
- Image Generation: synthesize a visual element, including data-driven charts through code execution or thematic illustrations through an image generator.
After the first report draft, Ptah applies verifier-guided test-time scaling. The six lifecycle refinement hooks are Section Refine, Image Refine, Overall Refine, HTML Generate, HTML Refine, and Render. The important detail is that refinement is not only prose polishing: image placement, image editing/deletion, global layout, and browser-rendered readability are also refined.
PtahEval
Figure 3 shows how PtahEval extends existing deep-research benchmarks with multimodal evaluation.
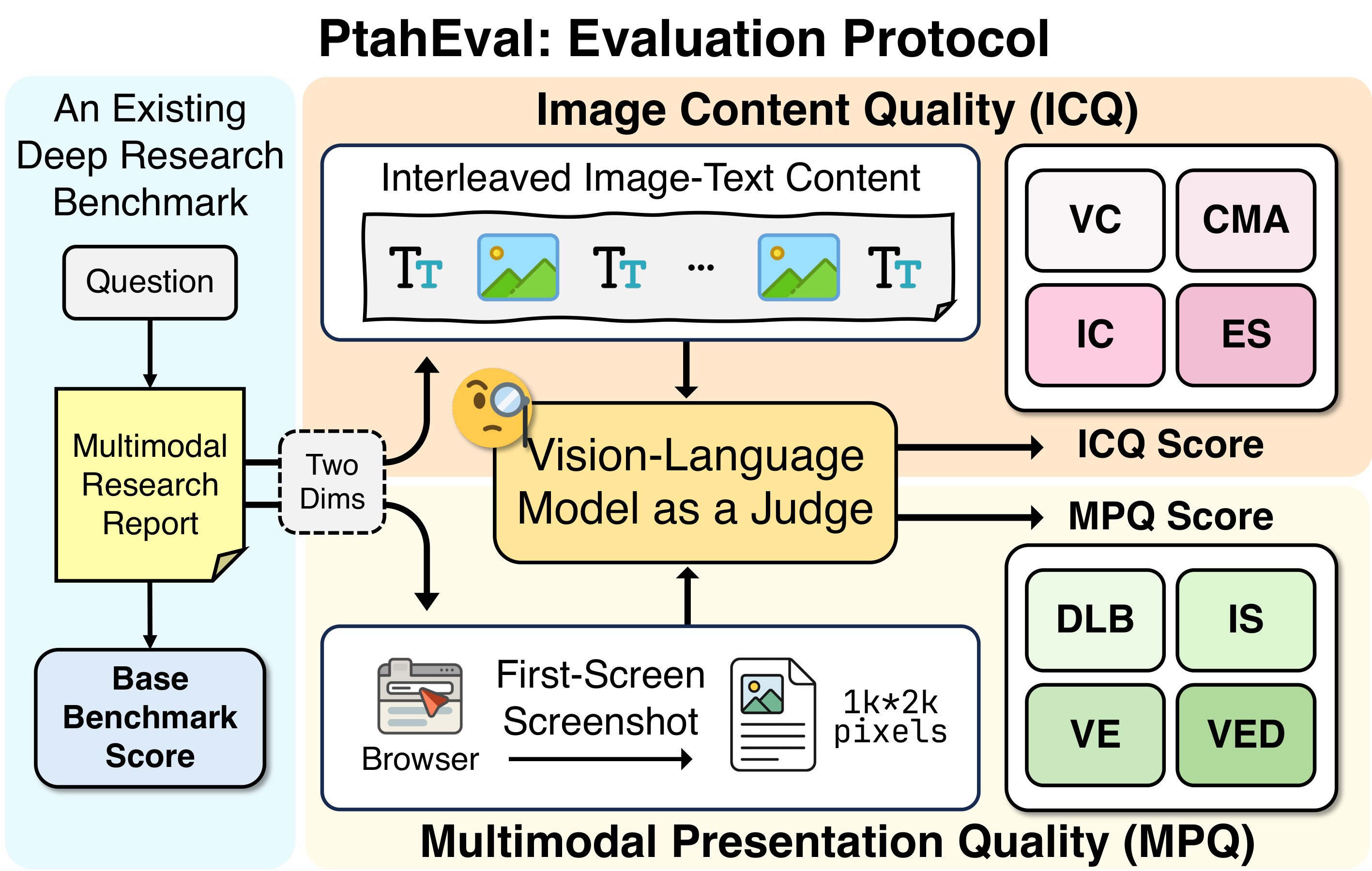
PtahEval keeps the base benchmark score, then adds two VLM-judged dimensions:
- Image Content Quality (ICQ): Visual Clarity, Cross-Modal Alignment, Information Complementarity, and Evidentiary Support.
- Multimodal Presentation Quality (MPQ): Density-Legibility Balance, Informational Saliency, Visual Encoding Diversity, and Visual Ergonomics.
For MPQ, the generated report is rendered as a web page and a \(1000 \times 2000\) pixel first-screen screenshot is judged. This choice is practical: the authors evaluate what a reader sees, not just a text file with image tags.
Implementation And Tools
The experiments use Qwen3-32B as Planner, Researcher, and Verifier, with Qwen3-VL-32B-Instruct as Writer. Qwen3-32B is also used for LLM-based verification, while Qwen3-VL-32B-Instruct performs image selection in the research stage. The benchmark evaluator uses Qwen3-VL-235B-A22B-Instruct.
The tool stack includes text search, image search, image generation, image editing, and code execution. In the reported setup, text/image search use Serper, webpage parsing uses Jina Reader, and image generation/editing/evaluation components are accessed through SiliconFlow APIs. The paper says these APIs are replaceable interfaces rather than fixed parts of the core design.
Experiments And Results
The main benchmark setup uses DeepResearch Bench and DeepConsult. Baselines include direct Qwen3-32B and QwQ-32B report generation, text-only search agents ReAct, Search-o1, and WebThinker, plus LLM-I as a multimodal-generation baseline.
Table 1 collects the main content-quality values that are visible in the extracted Markdown. Some cells in the source table were blank after conversion, so this digest only reports the numeric cells available in paper.md.
| Method | DeepResearch Bench visible values | DeepConsult visible values |
|---|---|---|
| WebThinker | Comprehensiveness 44.63; Insight/Depth 43.26; Instruction-Following 46.86; Readability 46.61; Overall 45.00 | Instruction-Following 2.94; Comprehensiveness 17.64; Completeness 2.94; Average 7.35 |
| Ptah | Comprehensiveness 42.97; Insight/Depth 44.32; Readability 47.95; Overall 45.16 | Instruction-Following 13.73; Comprehensiveness 18.63; Completeness 17.64; Writing Quality 14.71; Average 16.18 |
Table 1. Main content-quality results. The strongest numeric claim here is on DeepConsult, where Ptah reaches an average of 16.18 versus WebThinker's 7.35. On DeepResearch Bench, Ptah's overall score is only slightly above WebThinker, but the paper emphasizes stronger Insight/Depth and Readability.
Table 2 gives the PtahEval values visible in the paper's extracted Markdown.
| Method | VC | CMA | IC | ES | ICQ Avg. | DLB | IS | VED | VE | MPQ Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| LLM-I | 2.10 | 2.28 | 1.96 | 1.52 | 1.97 | - | - | 3.25 | - | - |
| Ptah | 4.42 | 4.79 | 4.35 | 4.01 | 4.39 | 3.72 | 3.78 | 3.61 | 3.74 | 3.71 |
Table 2. PtahEval results on DeepResearch Bench. Ptah has high scores on all ICQ dimensions and complete MPQ results, supporting the claim that visual evidence is clearer, better aligned, and presented with better rendered-page ergonomics than the multimodal baseline.
The paper's credibility claim is easiest to inspect in Table 3.
| Method | Citation Accuracy | Effective Citations | Avg. Search Calls |
|---|---|---|---|
| ReAct | 37.28 | 0.23 | 4.17 |
| Search-o1 | 40.91 | 0.31 | 2.78 |
| WebThinker | 60.74 | 2.32 | 5.91 |
| Ptah w/o Verifier | 30.29 | 4.75 | 5.13 |
| Ptah | 87.53 | 9.64 | 12.82 |
Table 3. FACT evaluation on DeepResearch Bench. Ptah reaches 87.53 citation accuracy and 9.64 effective citations per task, substantially above WebThinker's 60.74 and 2.32. The w/o Verifier row also shows that removing the verifier harms citation accuracy sharply.
Figure 4 is the paper's human-evaluation evidence for PtahEval and rendered multimodal quality.

The paper also reports a user-centric human evaluation on 20 DeepResearch Bench reports. Table 4 summarizes the win-or-tie rates over WebThinker.
| Evaluator | Readability | Usability | Information Acquisition | Overall |
|---|---|---|---|---|
| Expert E1 | 85% | 90% | 95% | 95% |
| Expert E2 | 85% | 80% | 95% | 90% |
| General U1 | 90% | 95% | 100% | 100% |
| General U2 | 95% | 90% | 95% | 95% |
| Average | 88.75% | 88.75% | 96.25% | 95.00% |
Table 4. User-centric human evaluation. This supports the usability claim, but the sample is still small and centered on report preference rather than independent factual reproduction.
Table 5 isolates the role of test-time scaling.
| Method | DRB | ICQ | MPQ | Avg. Images / Failures |
|---|---|---|---|---|
| LLM-I | 36.36 | 1.97 | 3.00 | 0.74 / 0.14 |
| Ptah w/o TTS | 42.13 | 2.77 | 3.49 | 5.06 / 0.38 |
| Ptah | 45.16 | 4.39 | 3.71 | 3.76 / 0.12 |
Table 5. Test-time scaling ablation. Removing TTS drops DRB by 3.03 points, ICQ from 4.39 to 2.77, and MPQ from 3.71 to 3.49. The full system also has fewer image failures than the no-TTS variant.
The cost side is reported in Table 6. The full pipeline takes 1015 seconds on average, with research as the dominant stage.
| Stage | Avg. Time (s) |
|---|---|
| Planning Stage | 192 |
| Research Stage | 459 |
| Writing Stage | 121 |
| TTS | 243 |
| Total | 1015 |
Table 6. Stage-wise latency. Research is the largest component because it performs open-ended evidence collection, webpage inspection, and image-pool construction.
Table 7 shows the efficiency benefit of parallel researchers.
| Research Execution | Avg. Time (s) | Relative Change |
|---|---|---|
| Parallel | 459 | 1.00x |
| Sequential | 1328 | 2.89x slower |
Table 7. Parallel research latency. Parallel section-level research reduces research-stage wall-clock time by 65.4% relative to sequential execution.
Table 8 gives the verifier-strength trade-off.
| Setting | Time (s) |
|---|---|
| Current Verifier - Planning | 192 |
| Current Verifier - Research | 459 |
| DeepSeek-R1 Verifier - Planning | 853 |
| DeepSeek-R1 Verifier - Research | 1408 |
Table 8. Verifier latency. A stronger verifier can trigger more expensive verification and additional revision rounds, so the paper frames verifier choice as a quality-efficiency trade-off.
Figure 5 shows first-screen examples of Ptah reports.
Table 9 is an additional same-framework ablation on removing images from Ptah outputs.
| Method | DRB Overall | MPQ Avg. |
|---|---|---|
| WebThinker | 45.00 | 3.11 |
| Ptah w/ images | 45.16 | 3.71 |
| Ptah w/o images | 45.10 | 3.29 |
Table 9. Visual-elements ablation. Removing images barely changes the text-oriented DRB score but lowers MPQ from 3.71 to 3.29, supporting the claim that visuals mainly improve multimodal presentation rather than only text quality.
Practical Takeaways
- The most reusable idea is the harness contract: keep plans, research packages, citations, numerical data, and visual candidates as explicit state, then verify them before final writing.
- Visual Working Memory is the paper's clearest design pattern. It changes image handling from "find a picture later" into a source-aligned, section-aware evidence store.
- PtahEval is useful because it evaluates both image content and rendered-page ergonomics. The first-screen screenshot protocol is especially relevant for human-facing reports.
- The strongest experimental evidence is for credibility and visual/report quality: FACT, PtahEval, TTS ablation, and human preferences all point in the same direction.
- The text-quality gain on DeepResearch Bench is modest. Ptah's larger numeric gain appears on DeepConsult and in multimodal/citation metrics.
- The system is expensive: the reported full pipeline averages 1015 seconds, and stronger verifiers can multiply planning/research latency.
- The authors' own limitation matters. Ptah uses manually defined stage boundaries because current open-source models are not reliable enough for a stable single-pass long-horizon multimodal research agent.
The limitations section explicitly says stable autonomous long-horizon multimodal search and generation remains challenging with current open-source models. The modular stage design is therefore a reliability choice, not proof that the decomposition is the only possible architecture.