Source-first digest for checked paper rank 42, rank_id p029.
- Routing status:
success - PDF extraction: not used
Motivation / Background
Knowledge-intensive QA is an awkward target for RL. Math and code can often use deterministic reward functions, but factual QA responses can mix a correct answer with unsupported claims in the same reasoning trace. Outcome-level rewards see only the final answer, while sentence-level factuality rewards usually require NLI models, LLM judges, retrieval, or knowledge-verification services for every generated sentence.
CorVer targets that gap. It turns Wikipedia subject-object co-occurrence into a process reward: extract one factual triplet from each generated sentence, query an Infini-gram Wikipedia index for the subject and object content words, convert the count into a small sentence reward, and align that sentence reward back to the generated tokens. Figure 1 frames the paper's motivation: factual QA lacks the cheap verification loop that has made RL easier for math and code.
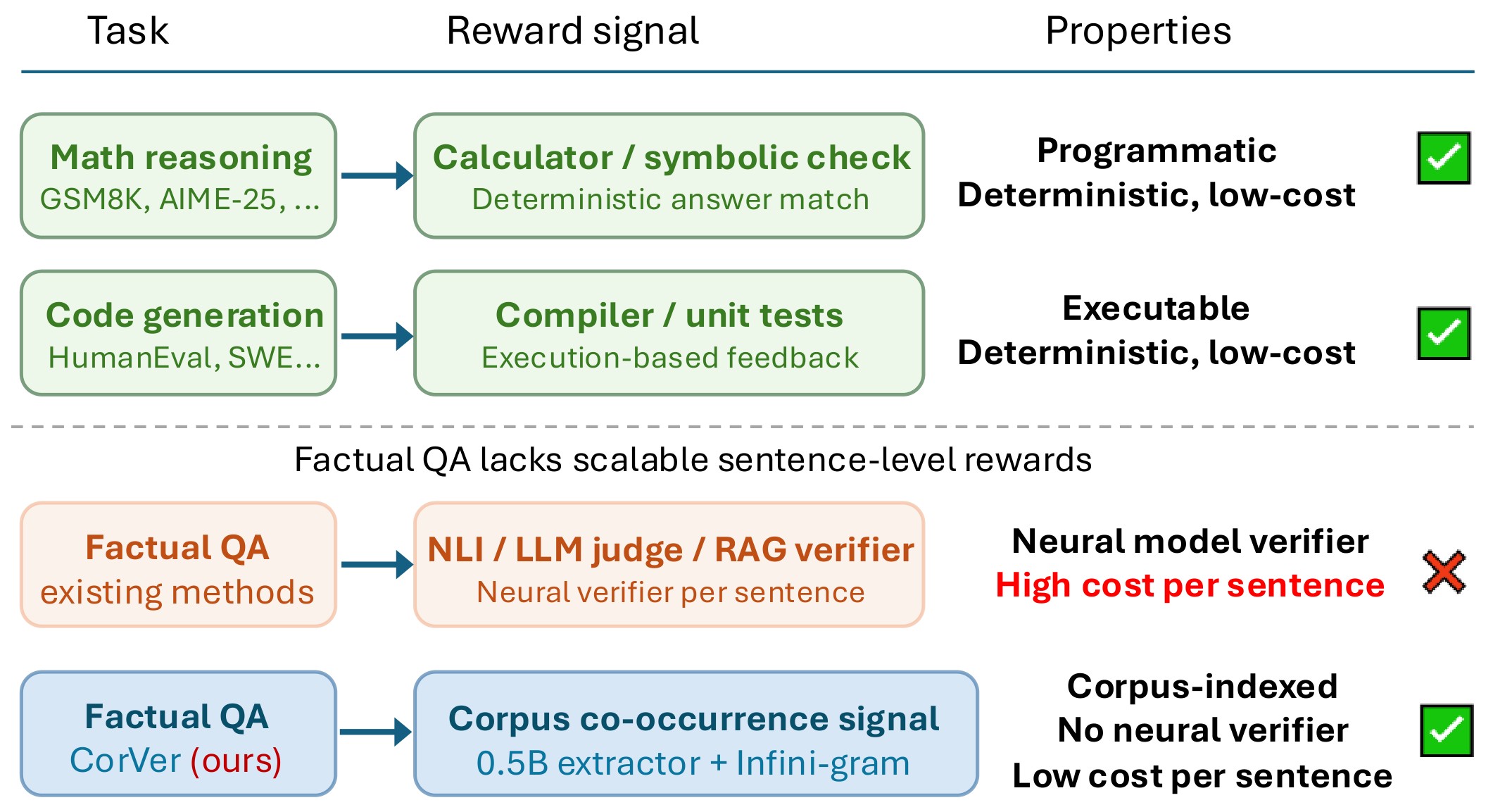
The key caveat is already visible in the motivation: CorVer is not a fact checker. A co-occurrence count can be a useful directional signal, but it cannot prove the predicate is correct. The rest of the paper argues that this weak but cheap signal is useful enough when it is calibrated, bounded, and combined with a response-level answer reward.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | A corpus-indexed co-occurrence signal can provide lightweight sentence-level process supervision for factual QA without putting neural verifiers in the reward loop. | 5 | problem setup, pipeline, reward map, cost |
| C2 | Co-occurrence count is a calibrated directional proxy for sentence factuality, especially at the zero-count and high-count extremes. | 4 | calibration figure, calibration table, case study, limitations |
| C3 | CorVer improves factual QA accuracy over the raw model across all 30 tested model-benchmark cells from 3B to 14B. | 5 | main results, cross-model scaling, full scaling summary |
| C4 | Under feasible training configurations, CorVer beats the four neural-verifier factuality-RL baselines in most cells while training faster. | 4 | main results, training-time comparison, cost table |
| C5 | The gain is not just from adding another scalar reward; per-token sentence alignment and the QuCo signal both matter. | 4 | ablation table, aggregation variants, penalty sweep |
| C6 | The method's gains track corpus coverage more than rare-entity rescue, which is both evidence for how the signal works and a limitation. | 4 | PopQA quartiles, limitations |
| C7 | On Qwen3-8B, part of the gain comes from reducing refusals rather than indiscriminate guessing, but that diagnostic is model-specific. | 3 | refusal decomposition, checkpoint curve |
Scores are support-from-paper scores, not independent reproduction scores. Claims with single-model diagnostics or asymmetric baseline configurations are capped below 5 even when the reported results are strong.
Core Technical Idea
CorVer has three reward channels:
- A response-level string-match judge reward for whether the answer is correct.
- A response-level format reward for the required
think/answertemplate. - A sentence-level co-occurrence reward, aligned back to the tokens in that sentence.
Figure 2 is the compact view: generated text is split into sentences, a 0.5B QuCo extractor pulls a subject-object relation triplet, the subject and object content words are counted in a Wikipedia Infini-gram index, and the resulting sentence reward is combined with GRPO.
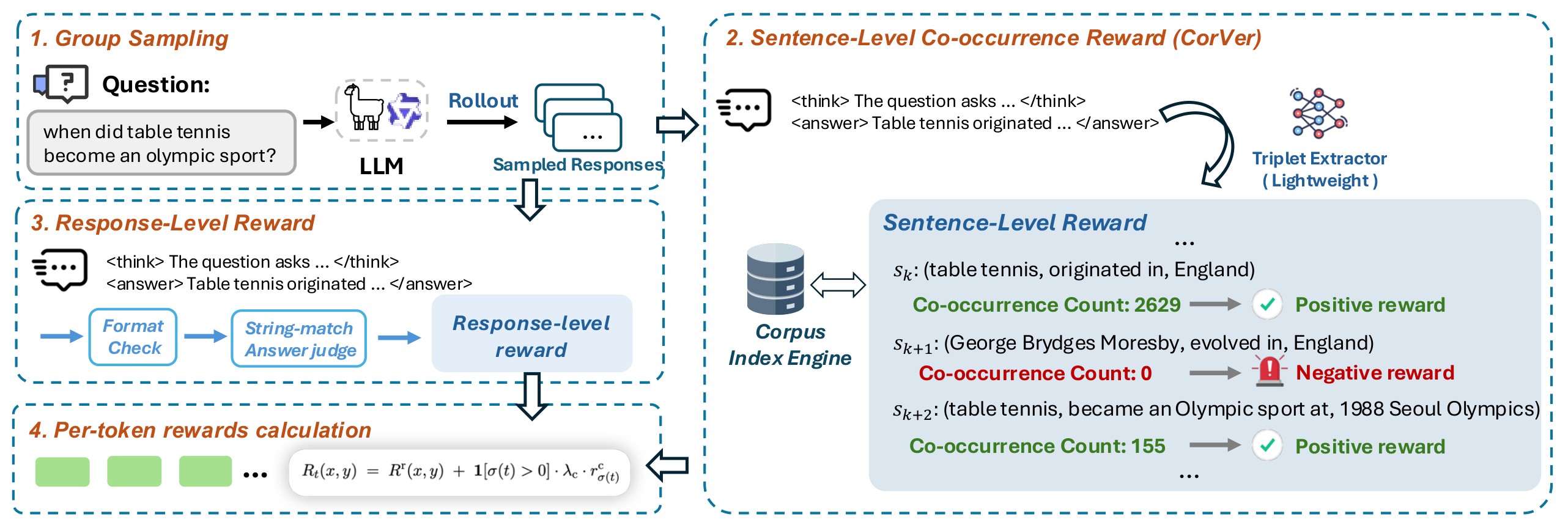
For a factual sentence \(s_i\), CorVer extracts a first valid triplet, discards the relation for the main query, reduces the head and tail to content words, and counts bounded-window co-occurrences:
The count becomes a bounded auxiliary reward:
| Co-occurrence condition | Sentence reward | Interpretation |
|---|---|---|
| No valid triplet | 0.0 | Do not shape the sentence. |
| \(c_i = 0\) | -0.3 | Strong negative signal for an unsupported subject-object pair. |
| \(0 < c_i < 5\) | -0.1 | Weak negative signal. |
| \(5 \leq c_i < 20\) | 0.0 | Neutral middle bucket. |
| \(c_i \geq 20\) | +0.1 | Weak positive signal for a well-covered pair. |
Table 1. Four-tier co-occurrence reward map. The concrete bins come from the appendix implementation section and the human calibration audit. Table 1 is important because it shows how deliberately small the co-occurrence term is.
The per-token return adds the sentence reward only to tokens that align to that sentence:
That is the main design decision. A response can get a positive final-answer reward while unsupported sentences receive a local negative shaping term, and two sentences in one completion can receive different local advantages.
Method Details
The paper uses a local English Wikipedia 20231101 Infini-gram index with about 6.4M articles and 5.5B tokens. Counts are bounded to a 1,000-token inter-clause window, so \(c_i\) measures passage-like position-level co-occurrence, not document-level co-occurrence. The extractor is QuCo-extractor-0.5B, a Qwen2.5-0.5B-Instruct triplet model. For each sentence, the implementation keeps only the first valid head-relation-tail triplet whose head and tail are non-empty and non-pronominal.
The reward scale is intentionally conservative. The response judge maps GOOD, BAD, and NA to \(+2.0, -1.0, -1.0\), the format reward is \(\pm 1.0\), and \(\lambda_{\mathrm{f}}=\lambda_{\mathrm{j}}=\lambda_{\mathrm{c}}=1.0\). The source text notes that the maximum co-occurrence contribution for a typical completion is about \(0.3\), an order of magnitude smaller than the judge reward swing of \(3.0\). This is why CorVer is best read as a local shaping signal, not a replacement correctness label.
Training uses LoRA with rank 128 and alpha 256, \(G=16\) generations per prompt, prompt batch 24, max completion length 1024, and 100 GRPO steps for the canonical runs. The method trains directly from the raw instruction-tuned model rather than from an SFT cold start. The paper reports that small 3B/4B models needed mastered anchor questions mixed into the self-filtered learning-zone pool, while models at least 8B did not.
The evaluation setup is summarized in Table 2. Training prompts come only from NQ-Open train and WebQuestions, so TriviaQA, PopQA, SimpleQA, and TruthfulQA are out-of-distribution for the RL prompt source.
| Item | Paper setting |
|---|---|
| Benchmarks | TriviaQA, NQ-Open, PopQA, SimpleQA, TruthfulQA |
| Evaluation sizes | 17,944; 3,610; 14,267; 4,326; 817 questions |
| Main models | Llama-3.2-3B, Qwen3-4B, Llama-3.1-8B, Qwen3-8B |
| Scaling models | Adds OLMo-2-13B and Qwen3-14B |
| Baselines | Raw, FoRAG, RLFH, FSPO, KnowRL |
| Metric | Factual QA accuracy with substring plus alias matching and lenient regex parsing |
| Diagnostics | NA/refusal rate, format success, answer length |
Table 2. Experimental setup. Table 2 is included to make the scope of the reported claims explicit.
Calibration And Reward Robustness
The main validation question is whether \(c_i\) is directionally meaningful. Figure 5 and Table 3 report the human audit: correctness rises monotonically from 24.0% for \(c_i=0\) to 81.0% for \(c_i \geq 20\).
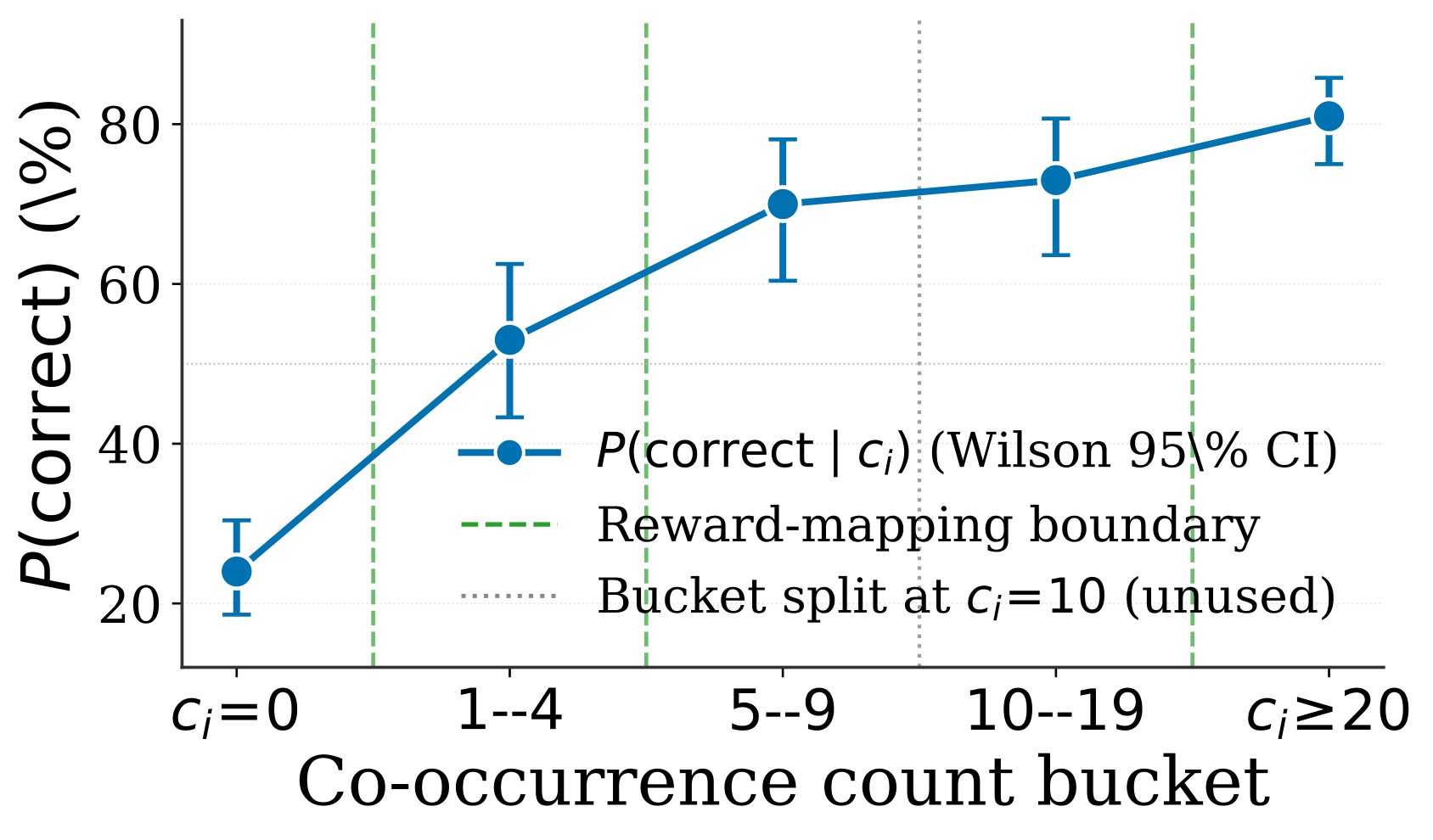
| Bucket | n | Correct | P(correct) | 95% CI |
|---|---|---|---|---|
| \(c_i = 0\) | 200 | 48 | 24.0% | [18.6, 30.4] |
| \(1 \leq c_i \leq 4\) | 100 | 53 | 53.0% | [43.3, 62.5] |
| \(5 \leq c_i \leq 9\) | 100 | 70 | 70.0% | [60.4, 78.1] |
| \(10 \leq c_i \leq 19\) | 100 | 73 | 73.0% | [63.6, 80.7] |
| \(c_i \geq 20\) | 200 | 162 | 81.0% | [75.0, 85.8] |
Table 3. Five-bucket calibration audit. The two thresholds used by the reward map sit at visible precision transitions: \(c_i=5\) and \(c_i=20\).
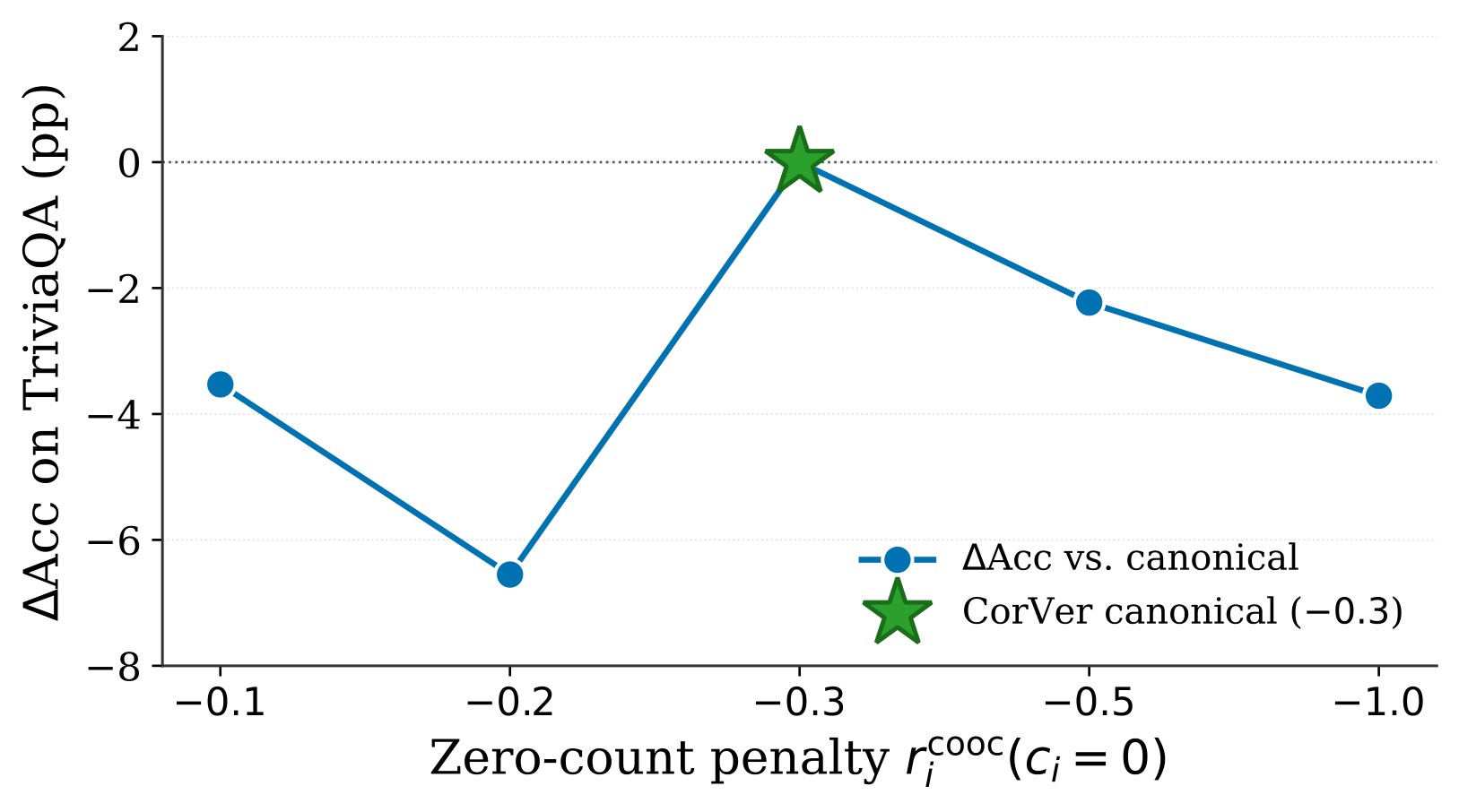
Figure 6 checks whether the zero-count penalty is fragile. The full recipe is retrained with zero-count penalties from -0.1 to -1.0 on Llama-3.2-3B-Instruct; both weaker and stronger penalties underperform the canonical -0.3 setting.
The qualitative case study in Table 9 shows the same idea at the sentence level: zero co-occurrence can catch plausible but wrong entities that a GPT-4o-mini offline judge labels correct.
Experiments And Results
Main Accuracy Results
Table 4 compresses the main table into model-level averages and the two exceptions noted in the source. CorVer improves every Raw cell in the four-model main comparison; compared with the four prior factuality-RL baselines, it wins 18 of 20 model-benchmark cells under the paper's feasible baseline configurations.
| Model | Raw avg | Best non-CorVer avg | CorVer avg | CorVer vs Raw avg | Notes |
|---|---|---|---|---|---|
| Llama-3.2-3B | 22.52 | 25.55 | 27.89 | +5.37 | CorVer best on all five benchmarks. |
| Llama-3.1-8B | 30.64 | 31.21 | 35.27 | +4.63 | Largest main-table average improvement. |
| Qwen3-4B | 20.85 | 22.12 | 22.69 | +1.84 | CorVer narrowly ahead of FSPO average. |
| Qwen3-8B | 24.37 | 24.65 | 26.11 | +1.74 | FSPO beats CorVer on PopQA by 0.26 pp; RLFH beats CorVer on SimpleQA by 0.58 pp. |
Table 4. Main result summary. The average deltas in Table 4 are computed from the source table. The paper's own wording emphasizes that CorVer improves every Raw cell and beats prior baselines in 18 of 20 cells, with the two baseline wins both on Qwen3-8B and within a point.
Scaling Across Six Models
Figure 3 and Table 5 address generality. The scaling heatmap reports positive CorVer-minus-Raw gains in all 30 cells across six instruction-tuned models and five benchmarks.
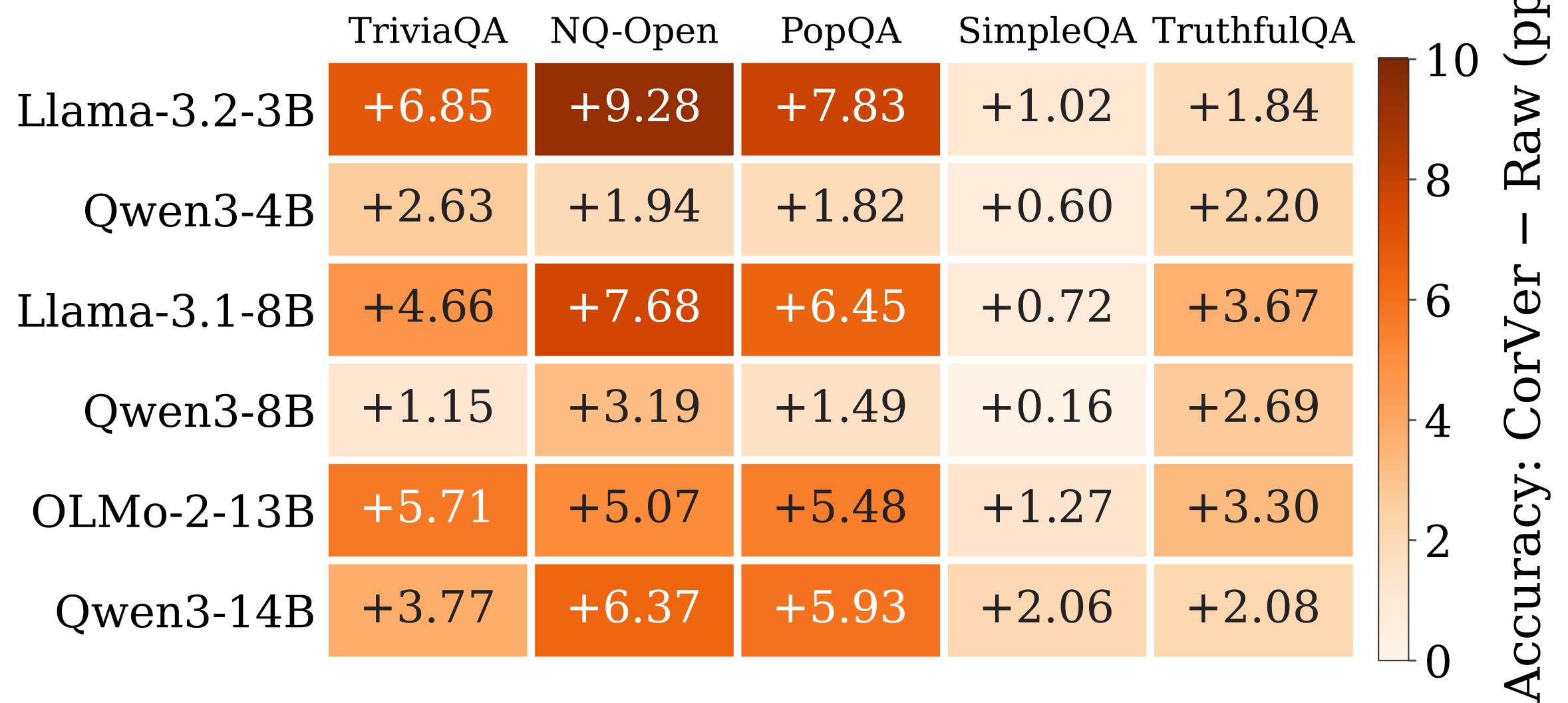
| Scale | Model | TriviaQA Raw -> CorVer | NQ-Open Raw -> CorVer | PopQA Raw -> CorVer | SimpleQA Raw -> CorVer | TruthfulQA Raw -> CorVer |
|---|---|---|---|---|---|---|
| 3B | Llama-3.2-3B-Instruct | 55.39 -> 62.24 | 34.13 -> 43.41 | 15.92 -> 23.75 | 1.55 -> 2.57 | 5.63 -> 7.47 |
| 4B | Qwen3-4B | 51.14 -> 53.77 | 24.65 -> 26.59 | 17.51 -> 19.33 | 2.52 -> 3.12 | 8.45 -> 10.65 |
| 8B | Llama-3.1-8B-Instruct | 71.86 -> 76.52 | 40.66 -> 48.34 | 28.85 -> 35.30 | 5.20 -> 5.92 | 6.61 -> 10.28 |
| 8B | Qwen3-8B | 62.84 -> 63.99 | 29.61 -> 32.80 | 20.34 -> 21.83 | 2.57 -> 2.73 | 6.49 -> 9.18 |
| 13B | OLMo-2-13B-Instruct | 67.48 -> 73.19 | 32.80 -> 37.87 | 25.56 -> 31.04 | 2.17 -> 3.44 | 6.00 -> 9.30 |
| 14B | Qwen3-14B | 67.51 -> 71.28 | 31.39 -> 37.76 | 19.44 -> 25.37 | 1.85 -> 3.91 | 7.71 -> 9.79 |
Table 5. Full scaling summary. Table 5 preserves the Raw and CorVer values behind the 30 positive cells.
Cost And Feasibility
At the canonical rollout density, the reward loop issues about:
sentence-level reward calls per training run. Figure 4 and Table 6 show why the paper cares so much about per-call cost.
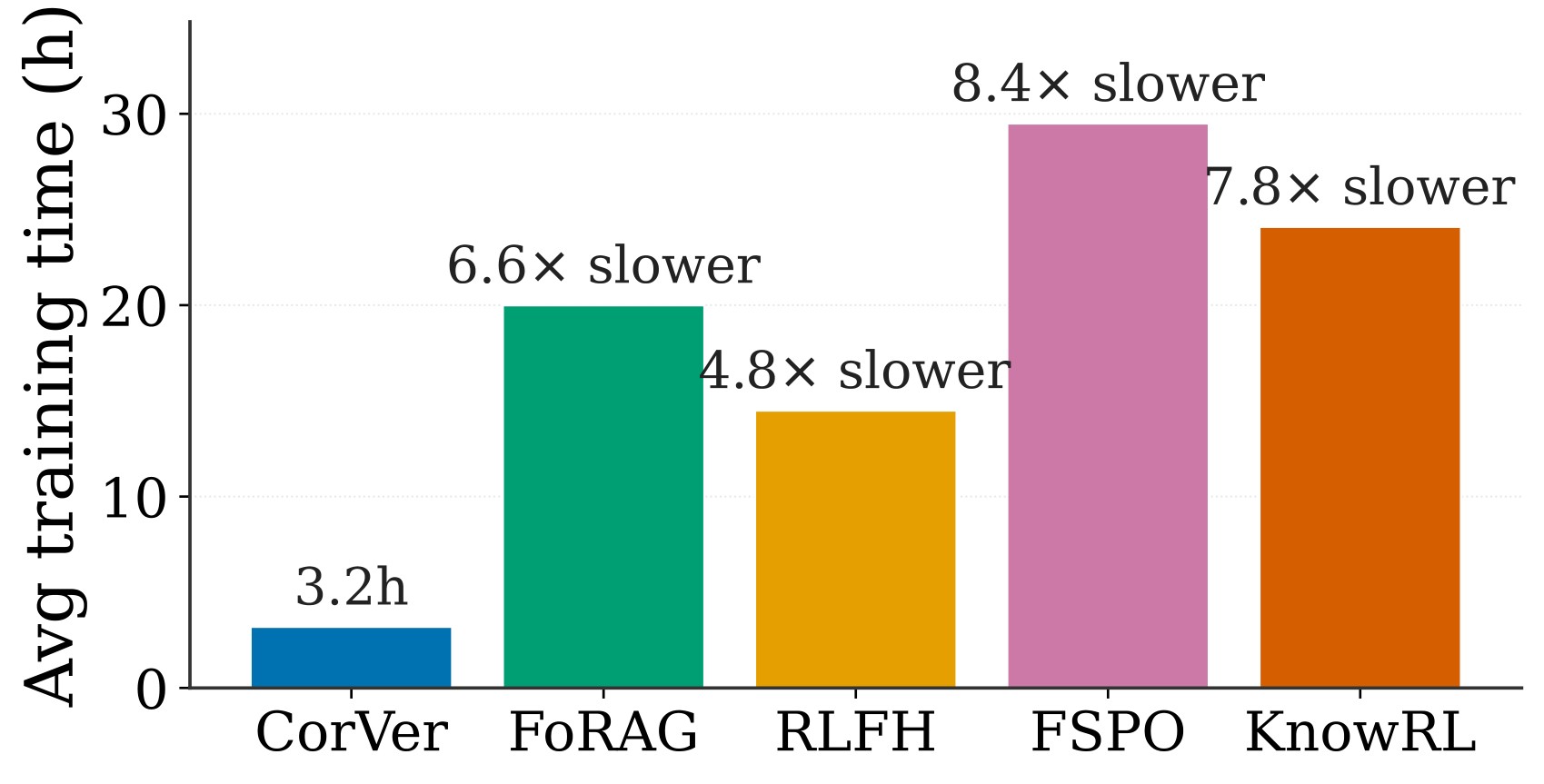
| Method | Llama-3.2-3B | Qwen3-4B | Llama-3.1-8B | Qwen3-8B | Avg slowdown |
|---|---|---|---|---|---|
| CorVer | 2.0 h | 4.3 h | 2.5 h | 4.1 h | 1x |
| FoRAG | 21.0 h | 26.9 h | 11.8 h | 20.1 h | 6.6x |
| RLFH | 15.5 h | 23.1 h | 9.4 h | 10.1 h | 4.8x |
| FSPO | 11.7 h | 27.6 h | 12.8 h | 65.8 h | 8.4x |
| KnowRL | 21.1 h | 21.9 h | 17.1 h | 36.4 h | 7.8x |
Table 6. Training wall-clock comparison. Table 6 is not an equal-budget comparison; it reflects the paper's argument that neural-verifier baselines cannot be run at the same rollout configuration without prohibitive cost.
What Drives The Gain
Table 7 holds the base model fixed at Llama-3.1-8B-Instruct and removes components. The full configuration beats every ablation on every benchmark. The most important comparison is A3 versus full: A3 keeps the same QuCo scalar magnitude but removes per-token sentence alignment, and it recovers only part of the gain.
| Variant | TriviaQA | NQ-Open | PopQA | SimpleQA | TruthfulQA |
|---|---|---|---|---|---|
| Raw | 71.86 | 40.66 | 28.85 | 5.20 | 6.61 |
| CorVer full | 76.52 | 48.34 | 35.30 | 5.92 | 10.28 |
| A1: no QuCo | 71.3 | 45.9 | 34.6 | 5.4 | 6.8 |
| A2: no judge | 76.1 | 42.6 | 31.7 | 4.8 | 7.1 |
| A3: no per-token alignment | 72.9 | 46.3 | 34.9 | 5.8 | 6.6 |
| A4: no self-filter | 75.0 | 46.0 | 33.5 | 5.1 | 8.0 |
Table 7. Component ablation. Table 7 supports the claim that CorVer needs both the response-level judge and the token-aligned sentence reward, especially outside TriviaQA.
Table 8 compares alternative triplet aggregation rules. The canonical "first valid triplet" rule is not the most exhaustive factual checker, but it is the best training signal in the reported experiment: Min catches more within-sentence issues but collapses length and accuracy, while RelCheck adds relation tokens and cost but underperforms.
| Variant | Correct (%) | NA (%) | Mean length | Time |
|---|---|---|---|---|
| First, canonical | 62.24 | 5.04 | 150 | 1.0x |
| Min | 57.27 | 0.33 | 40 | 1.2x |
| RelCheck | 61.37 | 6.58 | 150 | 1.7x |
Table 8. Triplet aggregation variants. Table 8 explains a practical choice: a weaker, first-triplet proxy can train better than a harsher multi-triplet rule because the policy can exploit the latter by shortening outputs.
The paper's qualitative Figure 7 has no external graphics asset, so I reconstruct its content as Table 9. Each row is a single sentence where the co-occurrence reward assigns \(r_i^{\mathrm{c}}=-0.3\) and the offline GPT-4o-mini judge incorrectly says the sentence is correct.
| Case | Prompt / gold answer | Generated error | Extracted pair | Co-occurrence result | Offline LLM judge |
|---|---|---|---|---|---|
| A | Ronkonkoma, NY zip code / 11779 | "11777" | Ronkonkoma NY - 11777 | \(c_i=0\), reward -0.30 | Correct |
| B | Kevin James's wife in Grown Ups / Maria Bello | Jennifer Coolidge appears in Grown Ups | Jennifer Coolidge - Grown Ups | \(c_i=0\), reward -0.30 | Correct |
| C | Ella Fitzgerald's parent / William Fitzgerald | Temperance Mary Tempie Height Fitzgerald | Ella Fitzgerald - Height | \(c_i=0\), reward -0.30 | Correct |
Table 9. Reconstructed case-study figure. The source caption says these are three single-sentence examples from the zero-frequency bucket; all were independently verified as factually incorrect by a human annotator.
Coverage, Refusals, And Checkpoints
Table 10 is the paper's most important limitation analysis. If CorVer mainly rescued rare entities, gains should be largest in Q1. Instead, gains are larger for better-covered PopQA entities, especially Q3 and Q4.
| Model | PopQA quartile | Raw | CorVer | Delta |
|---|---|---|---|---|
| Llama-3.1-8B | Q1 rare | 18.94 | 24.41 | +5.47 |
| Llama-3.1-8B | Q2 | 16.51 | 21.64 | +5.13 |
| Llama-3.1-8B | Q3 | 24.50 | 32.89 | +8.39 |
| Llama-3.1-8B | Q4 popular | 57.06 | 64.55 | +7.50 |
| OLMo-2-13B | Q1 rare | 15.63 | 19.31 | +3.68 |
| OLMo-2-13B | Q2 | 13.27 | 17.61 | +4.33 |
| OLMo-2-13B | Q3 | 23.74 | 29.25 | +5.51 |
| OLMo-2-13B | Q4 popular | 50.60 | 59.63 | +9.03 |
Table 10. PopQA popularity-quartile gains. Table 10 shows that the reward works best where the corpus has enough coverage to distinguish correct from incorrect co-occurrences.
For Qwen3-8B, Table 11 shows a large reduction in refusal rates. The paper checks the subset of questions that Raw refused but CorVer attempted and reports nontrivial correctness on that subset, which supports the interpretation that the model is recovering some factual recall rather than just guessing everywhere.
| Dataset | Raw NA% | CorVer NA% | Correct on Raw-refused subset |
|---|---|---|---|
| TriviaQA | 8.32 | 4.37 | 24.9 |
| NQ-Open | 13.27 | 4.13 | 17.5 |
| PopQA | 18.30 | 2.58 | 7.0 |
| SimpleQA | 27.99 | 2.96 | 1.3 |
| TruthfulQA | 16.65 | 3.30 | 8.1 |
Table 11. Qwen3-8B refusal decomposition. This diagnostic is useful but narrow: the source text says the Llama family shows the opposite NA-rate shift, so this is not a universal mechanism.
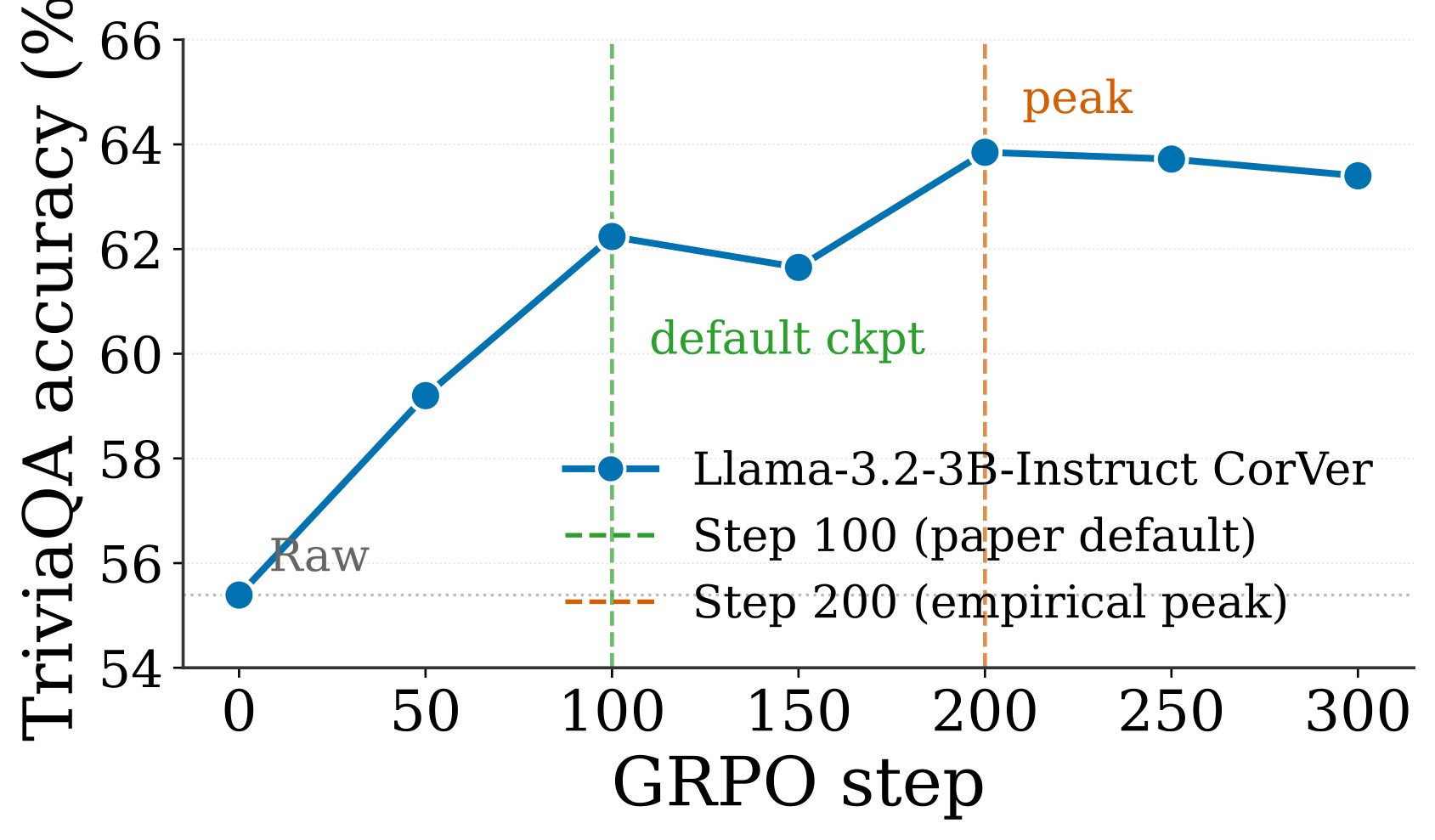
Figure 8 supports the uniform step-100 checkpoint choice. On a longer Llama-3.2-3B CorVer run, the largest jump comes in the first 100 steps; step 200 is higher but costs twice as much, and later checkpoints drift slightly down.
Practical Takeaways
- The reusable idea is not "co-occurrence equals truth"; it is "a cheap, bounded, calibrated corpus statistic can be useful as a dense auxiliary reward when paired with an ordinary answer reward."
- The strongest empirical support is breadth: all 30 Raw-vs-CorVer cells improve across six models and five benchmarks.
- The strongest engineering support is cost: at roughly 120k sentence-level reward calls per run, avoiding neural verifier calls changes what configurations are feasible.
- The most important limitation is predicate blindness. A subject and object can co-occur in Wikipedia while the generated relation is wrong.
- Corpus coverage is a real constraint. The PopQA analysis shows larger gains on better-covered entities, so this is not a magic fix for the rarest facts.
- The "first triplet" rule is pragmatic. It misses some multi-fact sentence errors, but harsher aggregation changed model behavior in worse ways.
- The paper validates CorVer only under GRPO. PPO, REINFORCE, DPO-style preference construction, larger web indexes, and combinations with retrieval or NLI rewards are future-work claims, not demonstrated results.
Limitations And Residual Risk
The reward is a corpus-grounded proxy, not a claim-level verifier. It ignores predicate semantics in the main query, keeps only one triplet per sentence, depends on English Wikipedia coverage, and uses a lenient substring-plus-alias evaluator for absolute accuracies. The relative comparisons use the same grader, so the tables are still meaningful for within-paper comparisons, but absolute correctness should be read cautiously.
I did not use raw PDF extraction. I did not consult latex_flattened/main.flattened.tex because the numeric tables needed for this digest were recoverable from paper.md; the HTML-rowspan tables were awkward, but not malformed enough to require fallback recovery.