Source-first digest for checked paper rank 55, rank_id p033.
- Routing status:
pandoc_failed - PDF extraction: not used
Motivation / Background
The paper asks a narrow but important scaling question: when a larger model succeeds on a task that a smaller model misses, is the smaller model merely undertrained, or is there a part of the data mixture that cannot be learned without increasing model capacity? The authors argue that standard power-law scaling already suggests a regime where extra data alone cannot recover the loss reached by a larger model, then use controlled task mixtures to study what that missing part of the distribution looks like.
Their answer is data-centric rather than purely expressivity-centric. Smaller models allocate limited representational directions to high-frequency or low-complexity tasks, so low-frequency or high-complexity tasks are not retained long enough to accumulate into generalizable structure. Larger models have enough width to explain common tasks, which weakens common-task gradients and reduces interference against rare-task updates. The conceptual distinction between "learnable via data scaling" and "learned via model scaling" is summarized in Figure 1.
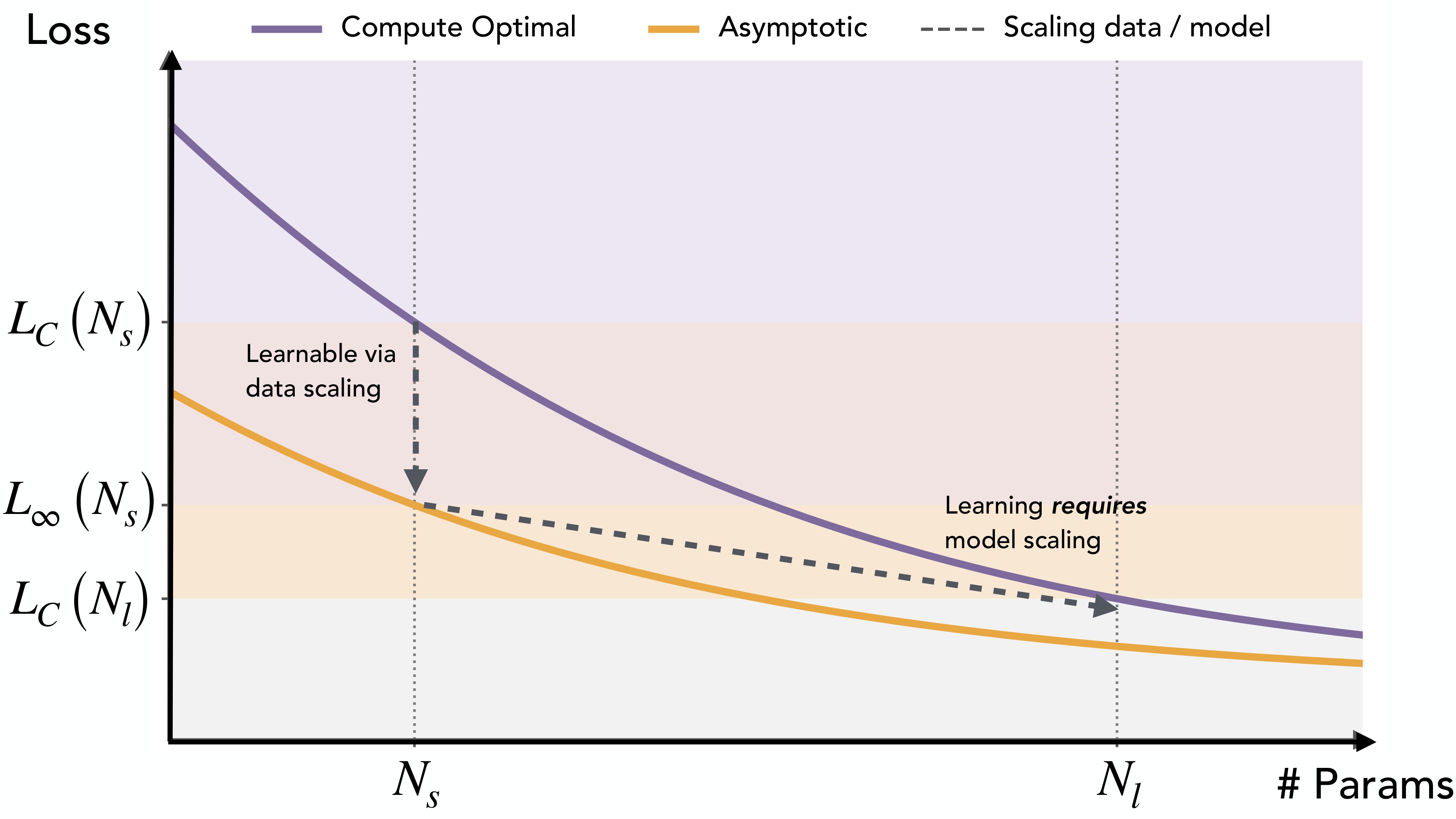
Claims And Evidence
The support ratings in Table 1 are support-from-paper scores, not independent reproduction scores.
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Power-law scaling motivates a regime where model scaling explains part of the data distribution that data scaling alone cannot recover for a smaller model. | 3 | conceptual scaling argument, limitations |
| C2 | In the synthetic mixture, a width-\(N\) model learns the top-\(N\) task features by utility \(u_{k,j} = \pi_k \lambda_{k,j}\), so rare or complex tasks require larger width. | 5 | utility theorem, phase diagram, long-horizon check |
| C3 | Larger width reduces interference from common tasks and lets rare-task updates persist between sparse observations. | 5 | gradient bound, residual control, rare-task retention |
| C4 | The same rare-task pattern appears in an OLMo-style pretraining pipeline with injected comparison and modular-addition tasks. | 4 | OLMo setup, OLMo phase diagrams, injection-gap evidence |
| C5 | Larger OLMo models embed more task-relevant features and show less gradient interference on localized task neurons. | 4 | representational evidence, gradient evidence |
| C6 | Practically, increasing target-task frequency or managing data-mixture interference may sometimes be a more efficient route than only increasing parameters. | 3 | task-vs-LM loss, compute comparison, discussion and limitations |
Core Technical Idea
The paper separates three explanations for why larger models do better:
- Expressivity: the small model cannot represent the solution.
- Sample efficiency: the small model could learn it, but needs more data or compute.
- Data-mixture learning dynamics: the small model has enough formal expressivity for the task, but gradient-based training on a mixture allocates scarce representational resources to higher-utility tasks.
The authors focus on the third explanation. Their synthetic setting is a mixture of linear regression tasks. Task \(k\) appears with frequency \(\pi_k\) and has covariance spectrum \(C_k = B_k \Lambda_k B_k^\top\), where larger or slower-decaying spectra represent more complex tasks. The student has a shared width-\(N\) encoder and task-specific linear decoders.
The central capacity theorem says the mixture loss reduces to an eigenspace problem:
The retained features are ranked by per-feature utility:
A width-\(N\) minimizer spans the top-\(N\) eigenspace of \(M\). If \(n_k(N)\) features from task \(k\) are retained, then the task's remaining loss is:
This gives a concrete answer to "what does width buy?" It buys lower-utility features: rare tasks have low \(\pi_k\), complex tasks spread mass over many \(\lambda_{k,j}\), and both are postponed until the representation has enough capacity.
The second technical step explains why a rare task can be observed and still forgotten. Let \(\mathcal{F}\) be the frequent-task set, \(M_{\mathcal{F}} = \sum_{k \in \mathcal{F}} \pi_k C_k\), and \(\delta_{\mathcal{F}}(U)=\mathrm{tr}((I-P_U)M_{\mathcal{F}})\) be the remaining frequent-task residual. The common-task gradient obeys:
Once a model has enough width to explain common tasks, their residual drops, their gradient pressure weakens, and rare-task directions can persist. For a rare rank-one task \(C_r=\lambda_r b_r b_r^\top\), the paper also gives a critical-width condition:
Below that width, the rare feature may be briefly learned after an injection batch but is eventually displaced by a common-task feature with higher utility.
Method Details
Synthetic Task Mixture
The synthetic experiments use \(K=32\) linear regression tasks in mutually orthogonal feature blocks. Task frequencies follow a power law \(k^{-\beta}\), and task spectra use power-law decay. The teacher for task \(k\) is:
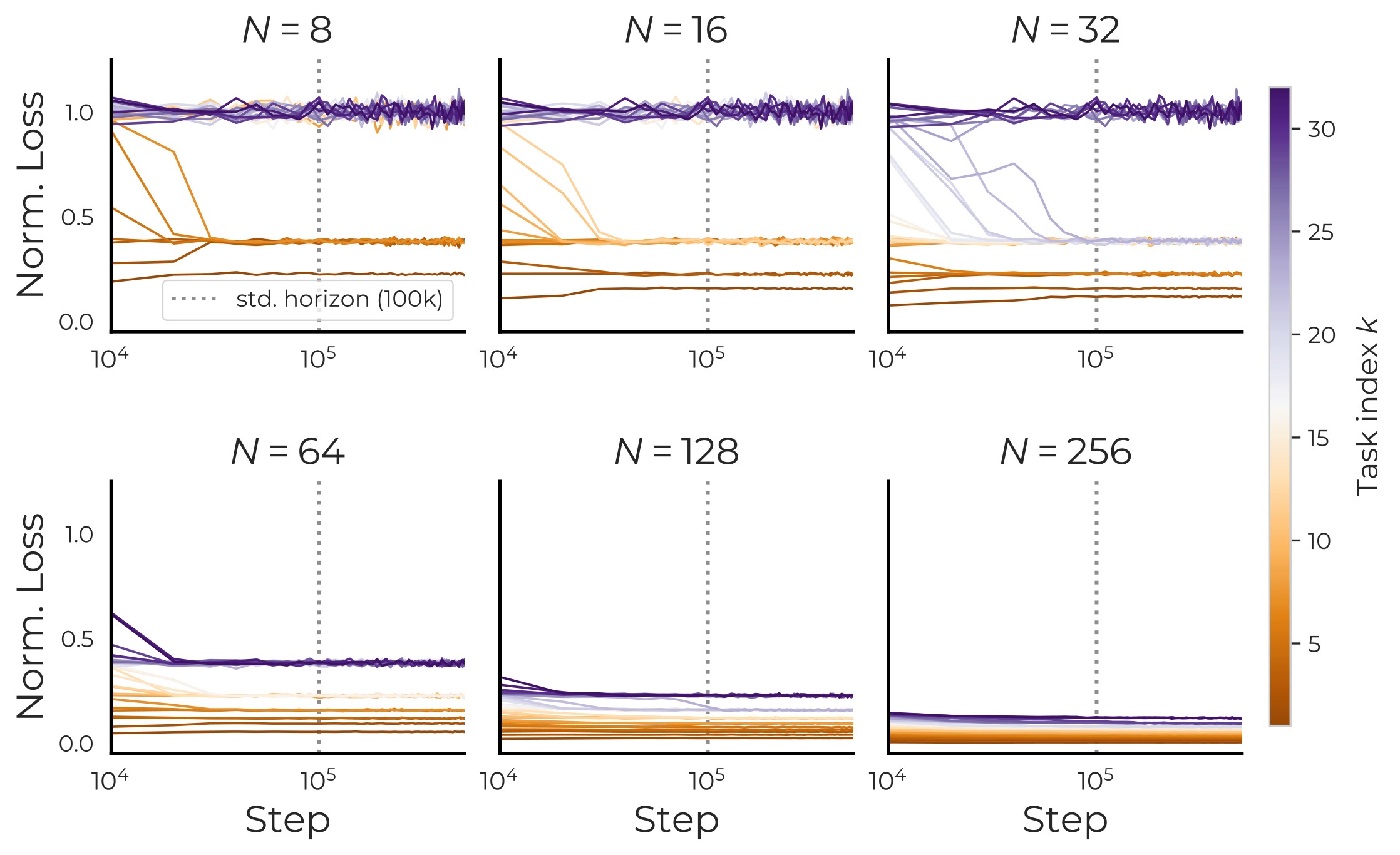
The student uses a shared encoder \(U\) and task-specific decoders \(D_k\), with prediction \(\hat{y}_k = D_k U^\top x\). Most phase-diagram runs train for 100K steps with Adam; the appendix extends selected runs to 1M steps to check that the apparent capacity bottleneck is not just slow convergence.
The main synthetic metrics are per-task loss, normalized per-task signal
and a random-baseline-corrected signal \(\tilde{s}_k(U)\). The retention experiments withhold a rare task for \(G\) steps, then inject a larger rare-task batch so the long-run task frequency remains matched across gaps.
OLMo Pretraining Pipeline
The OLMo experiments inject controlled synthetic tasks into Dolma v1.7 pretraining. The two injected tasks are comparison, \(T_{\mathrm{CMP}}\), and modular addition, \(T_{\mathrm{ADD}}\). Each is represented as three tokens, TOK1 TOK2 LABEL, with 10K instances split evenly between train and test. Frequencies range from \(7.8\times 10^{-3}\) to \(2.4\times 10^{-8}\), roughly from 1K instances per batch to 1 instance every 10 batches.
Table 2 shows the parameter sweep used for the OLMo validation.
| Model | Parameters | Layers | Hidden dim | MLP dim | Attention heads |
|---|---|---|---|---|---|
| 4M | 6,963,200 | 8 | 64 | 512 | 8 |
| 20M | 28,753,920 | 16 | 192 | 1,536 | 8 |
| 300M | 371,458,048 | 16 | 1,024 | 8,192 | 16 |
| 1B | 1,279,787,008 | 16 | 2,048 | 16,384 | 16 |
| 4B | 4,707,057,664 | 16 | 4,096 | 32,768 | 32 |
For representation analysis, the comparison task is localized to a global token-order feature using distributed alignment search. The modular-addition task is analyzed through Fourier modes in the residual stream. For gradient analysis, the authors localize task-relevant MLP neurons, use a task reference direction \(g_r\) from all 10K task instances, and decompose the batch gradient into task-token and non-task-token parts:
Experiments And Results
Synthetic Capacity Results
Figure 2 is the main synthetic result for the utility-ranking theorem. It compares empirical retained task features and losses against the analytic top-utility prediction.
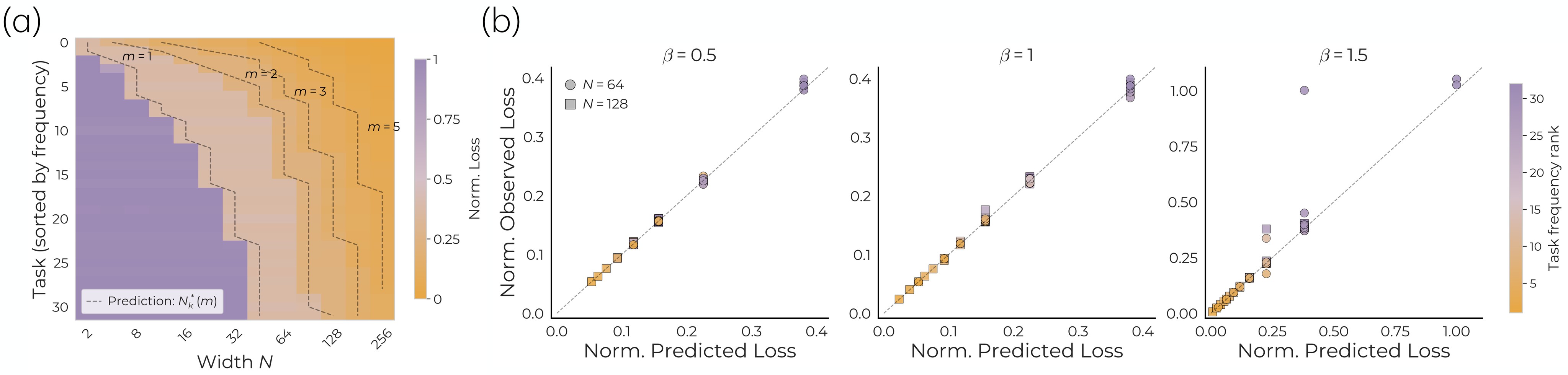
The important point is not just that larger models have lower average loss. The phase diagram says which tasks become learnable: the learned region follows the theoretical utility staircase, so width is buying specific low-utility task directions. This directly supports C2.
The long-horizon check in Figure 10 addresses the possible objection that small models simply need more optimization time.
Synthetic Interference And Retention
Figure 3 tests the residual-control claim: rare-task signal appears only after enough common-task residual has been explained.
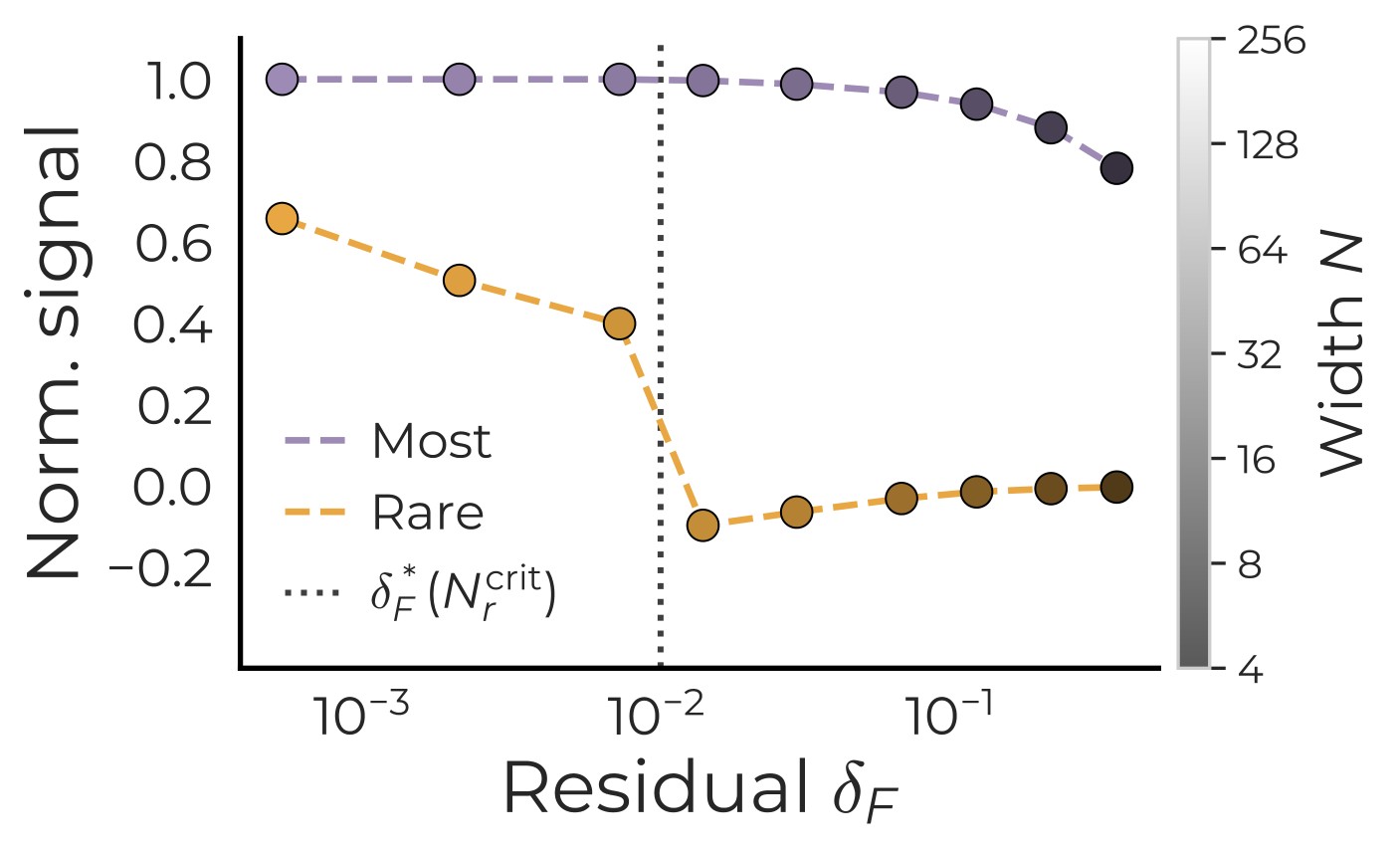
Figure 4 isolates rare-task retention by matching long-run frequency while changing the gap \(G\) between rare-task observations.
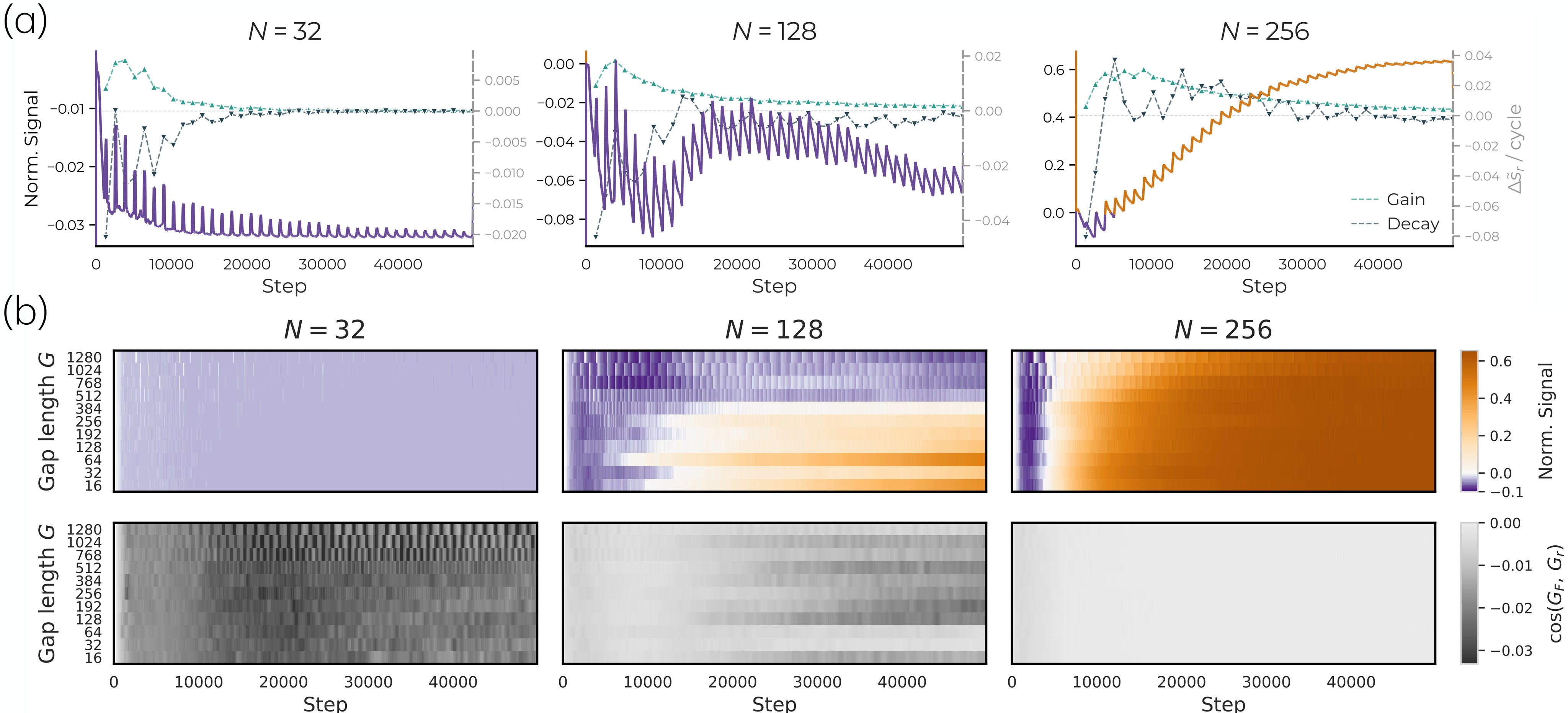
Together, Figure 3 and Figure 4 give the paper's strongest mechanism evidence. The rare task is not impossible for the architecture in isolation; it loses the competition inside the mixed training stream until width reduces common-task pressure.
OLMo Behavioral Evidence
The OLMo validation asks whether the controlled synthetic pattern survives in a language-model pretraining pipeline. Figure 5 shows that larger OLMo models learn lower-frequency injected comparison and modular-addition tasks that smaller models do not.
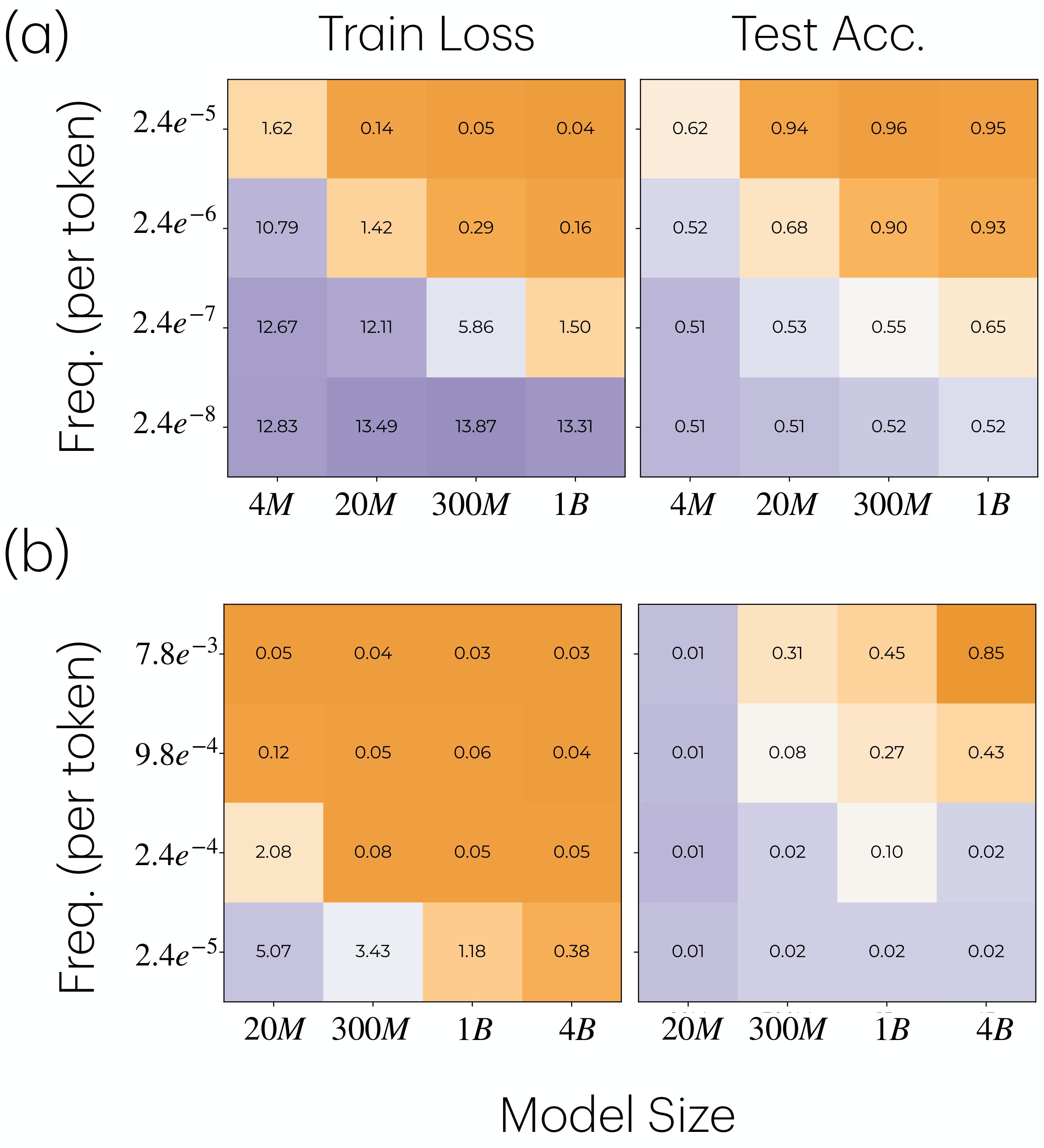
Figure 6 adds two behavioral checks: tasks are learned in frequency order, and larger gaps between matched-frequency injections hurt learning.
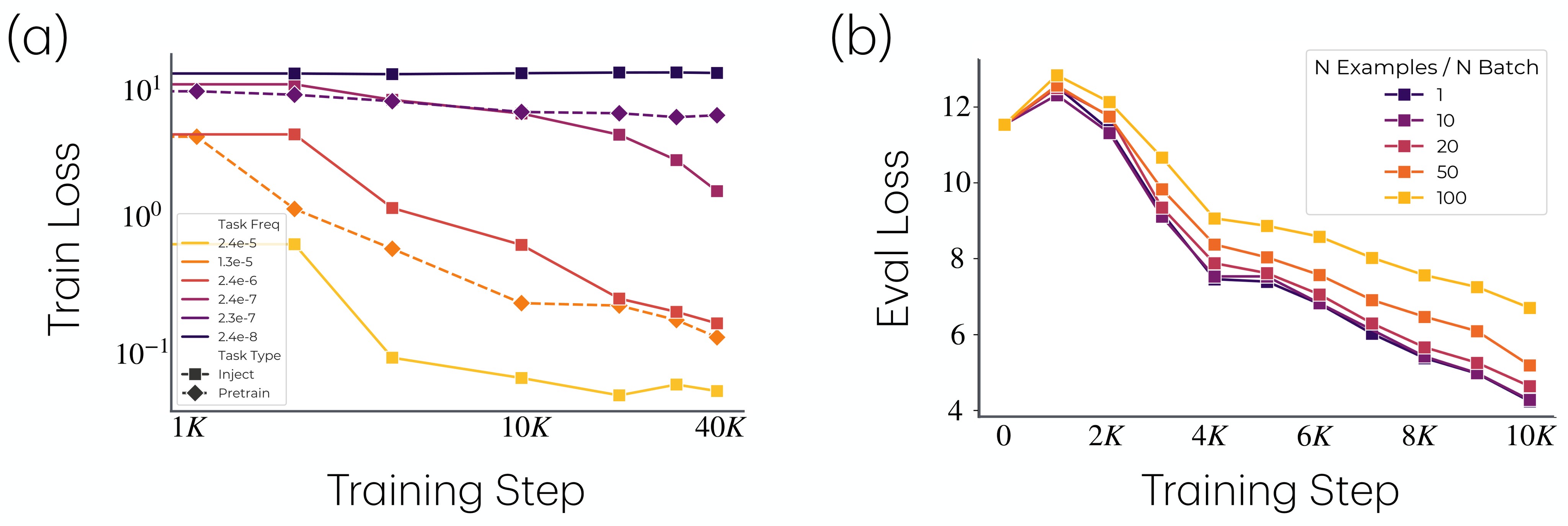
The limitation is that these are deliberately injected tasks, not a direct census of naturally occurring tasks in web data. That makes frequency measurable and the mechanism testable, but it also narrows the ecological scope of C4.
OLMo Representation Evidence
Figure 7 asks whether the larger models actually encode the task-relevant structures.
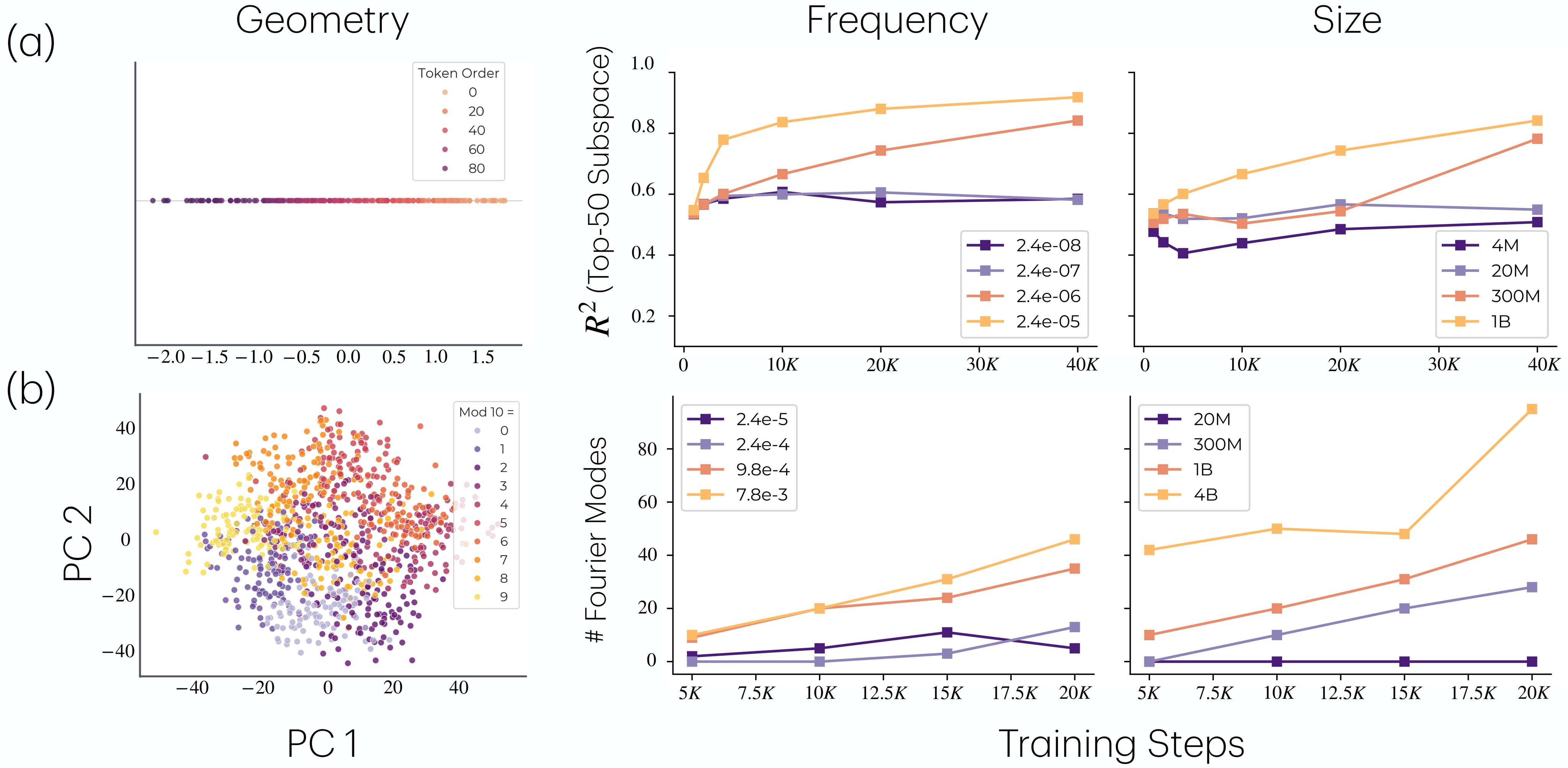
This matters because the behavioral loss curves could otherwise be read as memorization alone. The representation analysis supports the paper's claim that retained rare-task observations can consolidate into abstract task features.
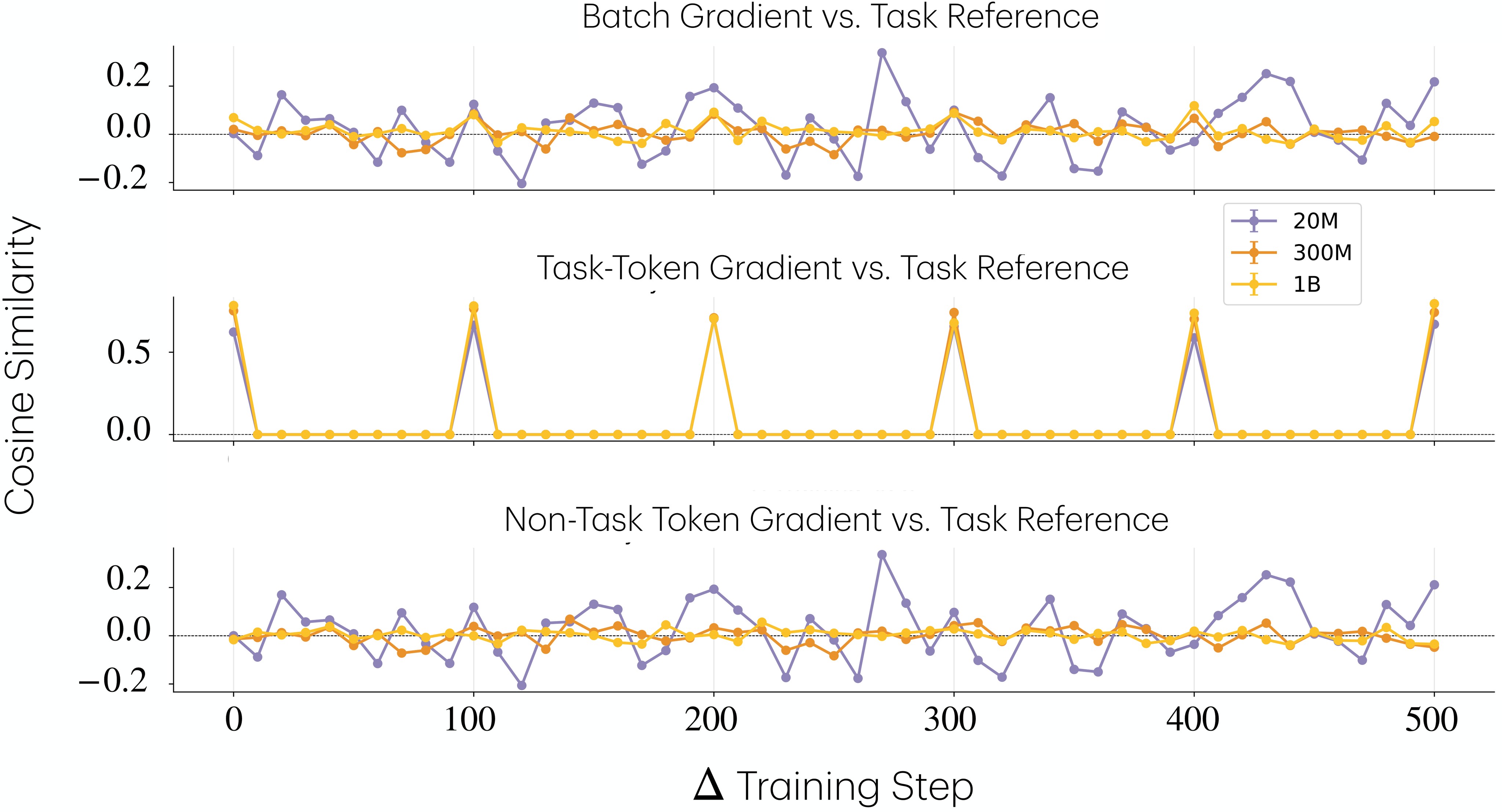
OLMo Gradient Evidence
The gradient analysis uses localized first-layer MLP neurons and the comparison task. Figure 8 shows that larger models retain more task information after periodic injections.
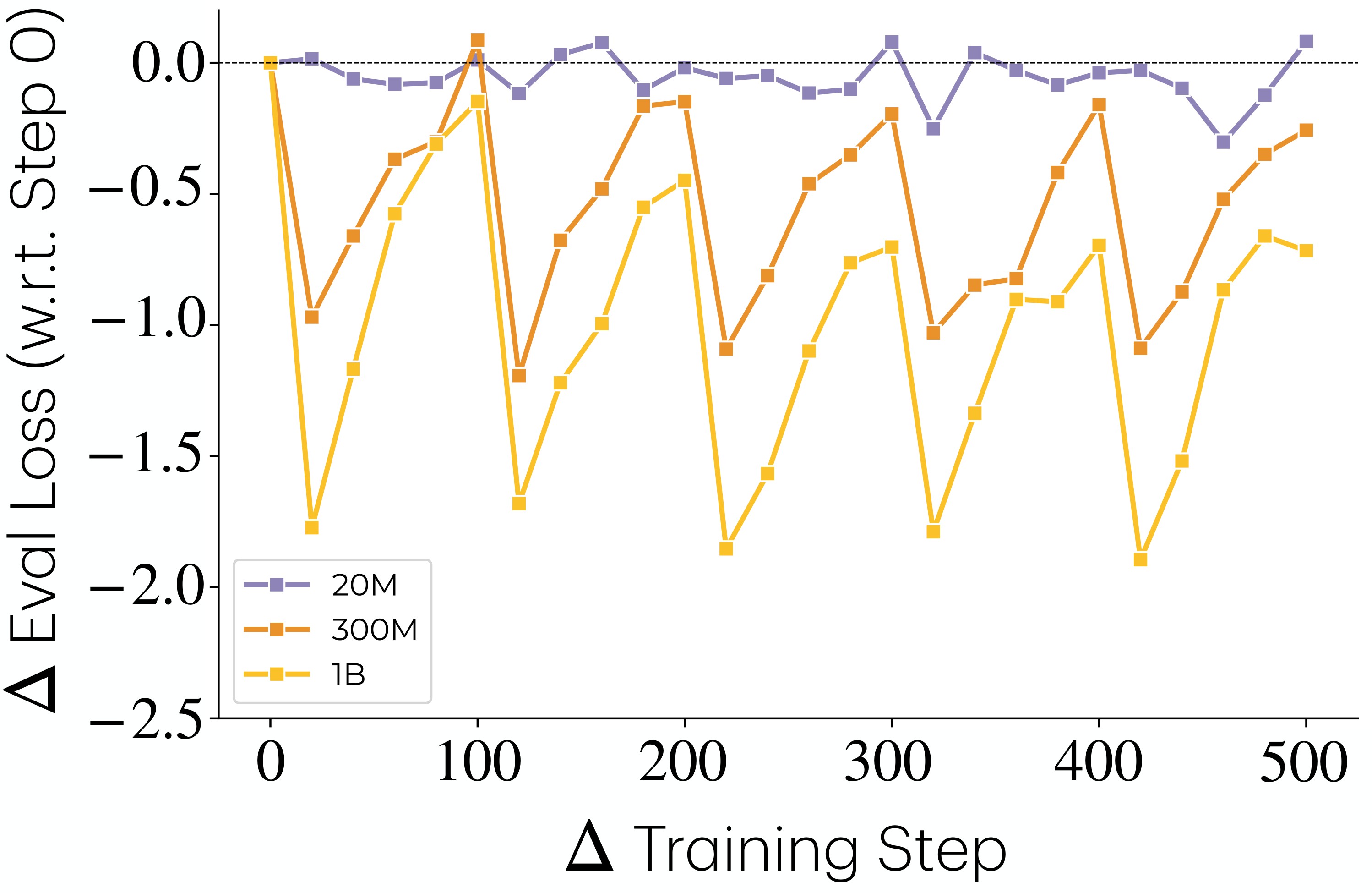
Figure 9 directly decomposes gradient alignment with the task reference direction \(g_r\).
Data Scaling, Language Modeling Loss, And Compute
Figure 11 compares injected-task loss against general language-modeling loss.
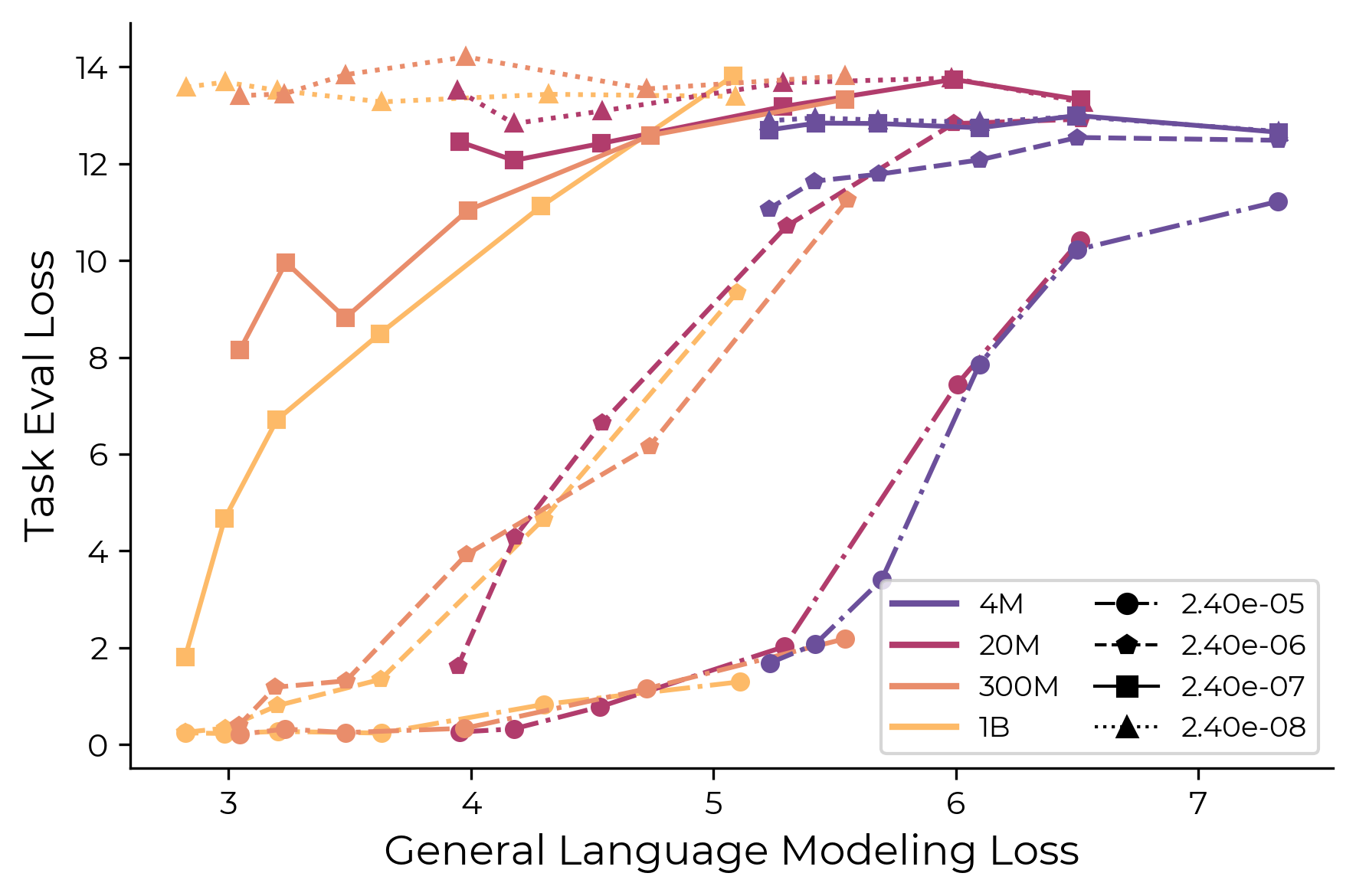
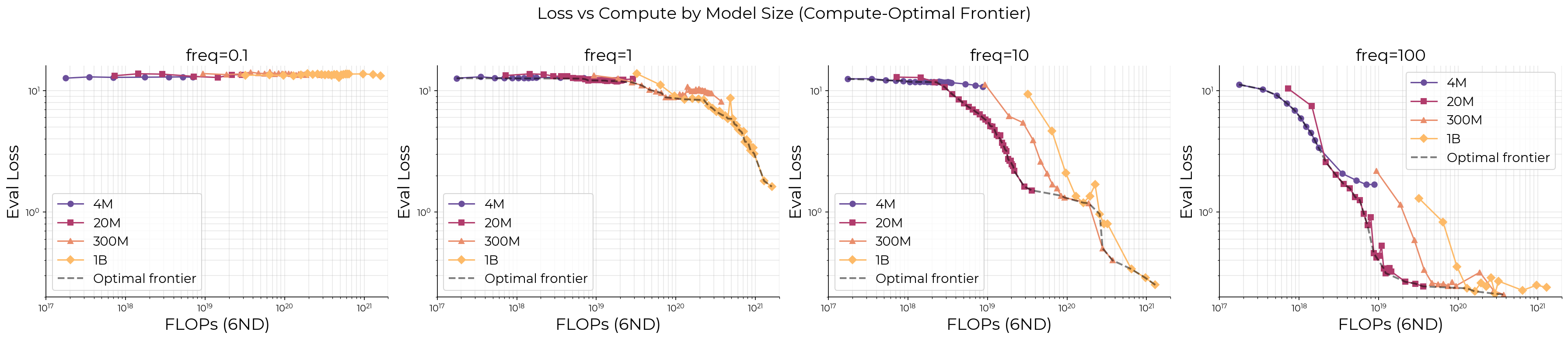
Figure 12 compares the comparison task against estimated compute.
Practical Takeaways
- The most reusable idea is the utility lens: in mixed training, a feature's effective priority is not just "is this task present?" but roughly "how often is it present times how much signal does this feature explain?"
- The paper gives a concrete mechanism for why rare tasks can fail in smaller models even when the model could express the task in isolation: frequent-task gradients erase rare-task updates before they accumulate.
- Memorization is framed as a useful intermediate for rare-task generalization. The model must retain traces of sparse observations long enough for them to consolidate into abstract features.
- Data-mixture design matters. If a target capability is rare, increasing its frequency or reducing gradient interference may be more efficient than increasing model size blindly.
- The strongest evidence is controlled: synthetic orthogonal regression tasks plus injected OLMo tasks. This makes the mechanism readable, but it does not prove that every emergent capability in frontier-scale pretraining follows this mechanism.
The limitations section explicitly says this is not a complete account of scaling. Expressivity and sample efficiency still matter, and the OLMo validation does not cover larger-scale or over-trained language models. The injected tasks are chosen to match frequencies of tasks learned in OLMo pretraining, so extreme frequency regimes and naturally occurring task families remain open follow-up questions.