Source-first digest for checked paper rank 52, rank_id p037.
- Routing status:
success - PDF extraction: not used
Motivation / Background
Structured output is still awkward for LLMs. Free-form natural language lets the model reason fluently, but the final answer may be hard to parse. Hard grammar- or regex-constrained decoding gives syntactic guarantees, but if the constraint is applied from the beginning, the constraint can shape the reasoning trace itself and degrade performance.
The paper positions In-Writing between these extremes. The model first reasons normally, then a trigger token activates constrained decoding only for the answer field. The local reconstruction in Figure 1 captures the paper's core example: natural generation can conclude "Helga" while In-Writing emits a structured { "final_answer": "A" }, using the constraint as a parser/corrector after the reasoning is already written.

figures.json, so this digest uses a local SVG reconstruction from the source text. It is placed here because it is the simplest evidence for the paper's claim that In-Writing preserves reasoning while making the final answer parseable.Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | In-Writing cleanly decouples reasoning from output formatting by applying constrained decoding only after a trigger token. | 4 | overview, probabilistic formulation, state algorithm |
| C2 | Constrained decoding is more useful as a post-reasoning parser/corrector than as a full-generation regime. | 5 | Figure 1, main NL-to-Format results, overlap analysis |
| C3 | Using only <eos> as the trigger mitigates premature triggering, especially on reasoning-heavy tasks. |
4 | state algorithm, main results, limitations |
| C4 | In-Writing* improves accuracy over natural generation, vanilla constrained decoding, and NL-to-Format across many evaluated classification and reasoning settings. | 4 | benchmark design, main results, newer-model comparison, classification and reasoning table |
| C5 | In-Writing* gives reliable parseability with small output-token overhead. | 5 | parse and token evidence |
| C6 | In-Writing is a stronger practical alternative to CRANE-style grammar-constrained reasoning on GSM-Symbolic. | 4 | CRANE comparison, limitations |
Support scores are support-from-paper scores. They are not reproduction scores. I cap broad robustness claims below 5 where the source itself reports prompt-sensitivity and failure cases.
Core Technical Idea
In-Writing treats answer formatting as a late-stage constrained slot, not as a constraint on the entire reasoning process. Let \(q\) be the question, \(R\) a latent reasoning trace, \(A\) the answer, and \(F\) the formatting constraint. Normal chain-of-thought answer generation is written as:
Hard constrained decoding instead conditions both the reasoning and answer on the format:
The paper argues that this is the source of damage: hard constraints can filter reasoning traces before they finish. It formalizes this as:
In-Writing instead keeps reasoning independent of the final-answer format:
and only conditions the final answer extraction step:
This is the whole conceptual move: let \(R\) be natural language, then constrain the final \(A\) field.
Method Details
The implementation uses a finite-state machine (FSM) or grammar/regex constraint, but starts generation in a free-form state -1. Once a trigger token appears, the decoder switches into the constrained FSM state 0. The original state diagram in Figure 4 shows the mechanism on a simple "Yes."/"No." regex: the model first emits unconstrained text, then the allowed token transitions are governed by the schema.
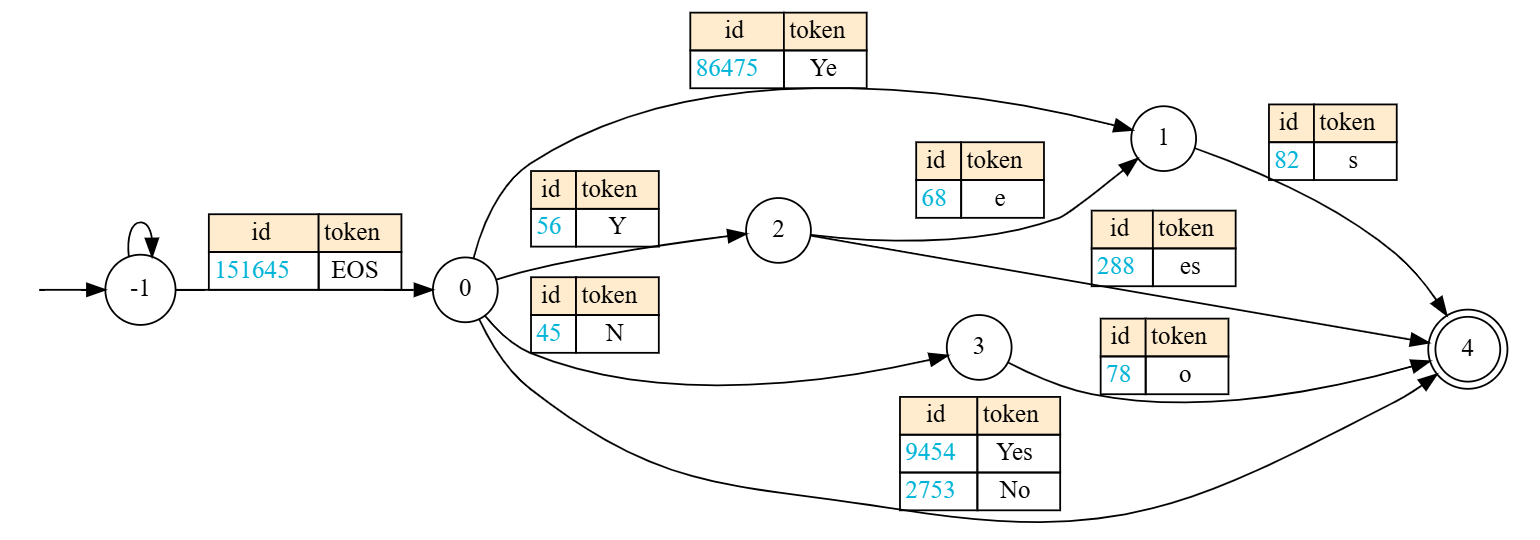
-1 to state 0.The source evaluates two trigger policies:
In-Writing-Base: trigger tokens are<eos>and{.In-Writing*: the only trigger token is<eos>.
The practical lesson is that { can trigger too early because JSON-like braces may appear before the model has completed reasoning. The paper reports that this premature triggering can degrade GSM8K by more than 30% relative to In-Writing*, while classification tasks are less sensitive.
The experiments use Pydantic to define JSON schemas. Vanilla constrained decoding is forced to produce JSON with think_step_by_step and final_answer; In-Writing allows free-form reasoning first and then constrains only the final JSON answer field. The implementation uses Litelines on top of Outlines, specifically allow_preamble and trigger_token_ids.
The evaluation covers reasoning tasks (GSM8K, GSM-Symbolic, Last Letter Concatenation, Shuffled Objects) and classification tasks (DDXPlus, MultiFin, Sports Understanding, NI Task 280). The models span Qwen, Llama, Gemma, DeepSeek, and SmolLM families from 1.5B to 32B parameters. Accuracy is exact-match after extraction, and parse rate measures whether the expected answer format can be parsed.
Experiments And Results
The key zero-shot reasoning table is Table 1: In-Writing* is best on all six LLaMA/Gemma task-model rows for GSM8K, Last Letter, and Shuffled Objects. The comparison is important because the reasoning traces for Baseline, NL-to-Format, and In-Writing* are held identical; differences come from extraction and formatting.
| Task | Model | Baseline (NL) | Constrained | NL-to-Format | In-Writing* |
|---|---|---|---|---|---|
| GSM8K | LLaMA3-8B | 66.2 +/- 9.5 | 48.9 +/- 6.7 | 74.7 +/- 0.6 | 77.9 +/- 1.3 |
| GSM8K | Gemma2-9B | 82.7 +/- 7.2 | 84.2 +/- 3.7 | 86.5 +/- 0.6 | 86.9 +/- 0.4 |
| Last Letter | LLaMA3-8B | 41.9 +/- 3.8 | 28.0 +/- 12.2 | 70.1 +/- 5.3 | 70.3 +/- 3.8 |
| Last Letter | Gemma2-9B | 9.3 +/- 8.1 | 39.0 +/- 6.8 | 56.8 +/- 9.8 | 58.4 +/- 4.8 |
| Shuffled Obj | LLaMA3-8B | 1.0 +/- 1.1 | 15.7 +/- 11.0 | 27.0 +/- 5.5 | 39.2 +/- 4.7 |
| Shuffled Obj | Gemma2-9B | 10.0 +/- 7.0 | 50.5 +/- 8.9 | 49.4 +/- 5.8 | 50.5 +/- 5.6 |
Table 1. Key zero-shot reasoning results. Values are mean accuracy plus/minus standard deviation over nine prompt variations. This table supports C2 and C4 because In-Writing* usually beats both a second-stage parser and hard constrained decoding in the same prompt setting.
The broader newer-model comparison in Figure 2 extends this pattern to Qwen3/Qwen3.5 and SmolLM on GSM8K, Last Letter, and Shuffled Objects. The figure also shows nuance: hard constrained decoding can be strong for some rows, but In-Writing* is best or tied in most displayed settings, and the large error bars on some baseline/constrained bars show why the paper emphasizes robustness rather than only peak accuracy.
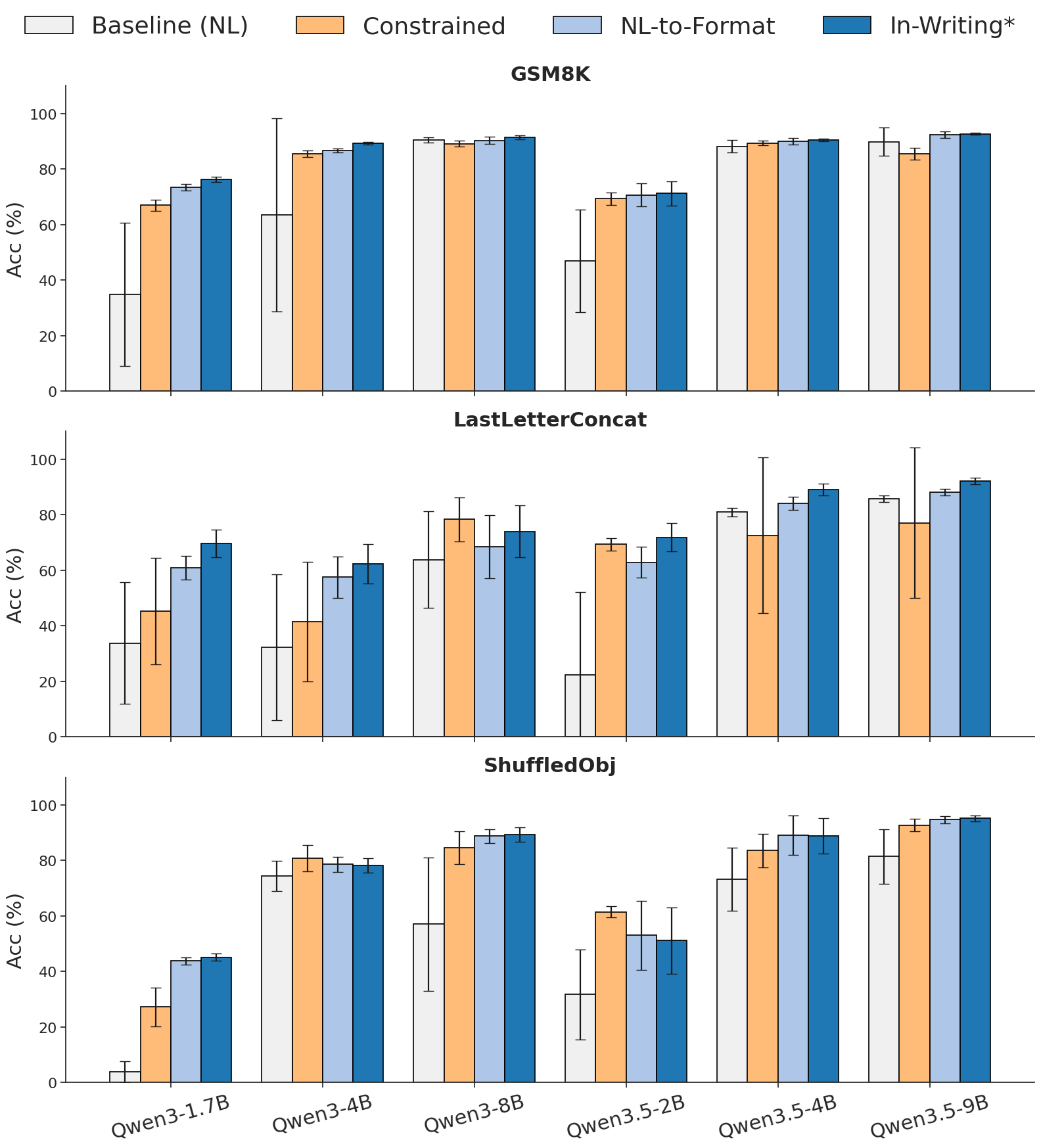
Table 2 condenses the parse-rate and token-efficiency evidence. In-Writing* reaches 100% parse rate across every Qwen3/Qwen3.5 reasoning row in the source parse table. It adds about 5-20 output tokens over the natural-language baseline, but avoids the extra model call and parser prompt required by NL-to-Format.
| Evidence item | Reported result | Why it matters |
|---|---|---|
| Parse rate | In-Writing* is 100% on the reported Qwen3/Qwen3.5 GSM8K, Last Letter, and Shuffled Objects rows. | Supports the claim that late constrained decoding gives syntactic validity. |
| NL baseline parse rate | Varies substantially, e.g. as low as 22% on Shuffled Objects for Qwen3-1.7B and 36% on Last Letter for Qwen3.5-2B. | Natural generation can be correct but hard to extract reliably. |
| Token overhead | In-Writing* adds about 5-20 output tokens compared with Baseline (NL). | The formatting cost is small compared with using a second LLM parser. |
| Vanilla constrained decoding | Can be inconsistent and sometimes changes the reasoning trace because JSON syntax is introduced at the start. | Supports the paper's "think before constraining" framing. |
Table 2. Parse and token-efficiency evidence. This table summarizes the source parse and token tables rather than reproducing every row, because the digest only needs the evidence needed to judge C5.
The overlap analysis in Figure 3 and Table 3 is the strongest evidence that In-Writing is doing more than merely formatting. Since NL-to-Format and In-Writing* receive the same first-stage reasoning, asymmetric wins show the effect of the final extraction step.
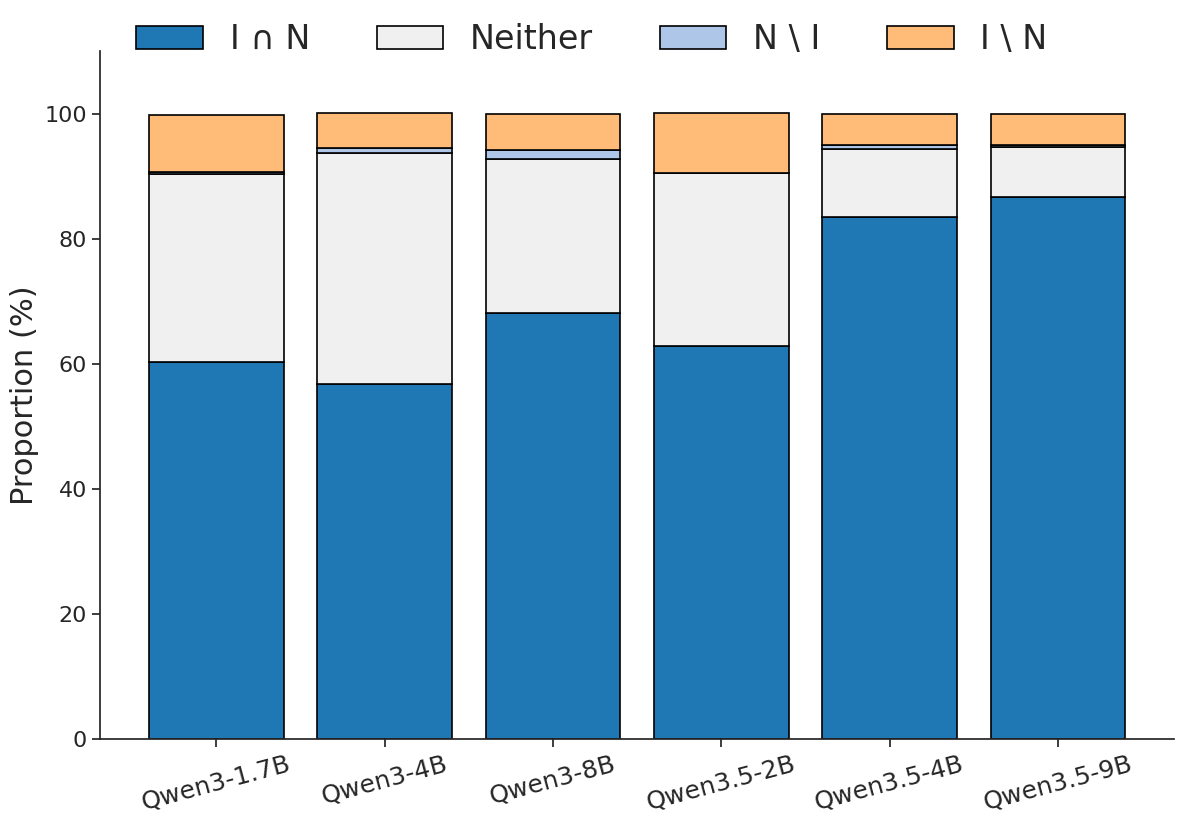
| Task / model | \(I \cap N\) | Neither | \(N \setminus I\) | \(I \setminus N\) | Reading |
|---|---|---|---|---|---|
| Last Letter / SmolLM3-3B | 53.5 | 34.0 | 0.7 | 11.8 | Largest reported In-Writing-only gain. |
| Last Letter / Qwen3.5-2B | 62.9 | 27.6 | 0.0 | 9.6 | In-Writing recovers many parser failures. |
| GSM8K / Qwen3-1.7B | 73.4 | 23.5 | 0.2 | 2.8 | Smaller but consistent asymmetric gain. |
| Shuffled Obj / Qwen3.5-2B | 48.4 | 45.5 | 3.9 | 2.1 | A counterexample where NL-to-Format has more asymmetric wins. |
Table 3. Selected overlap rows. These rows preserve both the main positive pattern and an explicit residual limitation.
The CRANE comparison tests a stricter hybrid-constrained setting on GSM-Symbolic. Table 4 shows that In-Writing* beats CRANE on seven of eight listed models, with the largest gap at Qwen2.5-Coder-14B: 77 versus 45. The one exception is DeepSeek-R1-Llama-8B, where CRANE is 31 and In-Writing* is 30.
| Model | Baseline | Constrained | CoT | CRANE | In-Writing* |
|---|---|---|---|---|---|
| Qwen2.5-1.5B | 21 | 22 | 26 | 31 | 37 |
| Qwen2.5-Coder-7B | 36 | 35 | 37 | 39 | 69 |
| Qwen2.5-Math-7B | 27 | 29 | 29 | 38 | 47 |
| Qwen2.5-Coder-14B | 42 | 42 | 42 | 45 | 77 |
| Llama3.1-8B | 21 | 26 | 30 | 33 | 59 |
| DeepSeek-R1-Qwen-7B | 18 | 20 | 24 | 29 | 47 |
| DeepSeek-R1-Llama-8B | 12 | 13 | 21 | 31 | 30 |
| DeepSeek-R1-Qwen-14B | 29 | 30 | 32 | 38 | 65 |
Table 4. GSM-Symbolic comparison with CRANE. The paper's interpretation is that CRANE constrains reasoning inside delimiter-controlled fields, while In-Writing constrains only the final extraction step.
The limitations matter. The paper does not optimize prompts for In-Writing, and it reports that increasing few-shot examples can improve Baseline performance while degrading NL-to-Format and In-Writing because the models adhere more strongly to an "answer is:" prefix. The source also includes concrete cases where constrained decoding maps the reasoning to an incorrect final_answer. This means the framework improves parseability and often accuracy, but it is not a semantic verifier.
Practical Takeaways
For structured reasoning systems, the most reusable idea is simple: let the model finish its reasoning in natural language, then constrain only the final schema slot. That preserves the model's normal reasoning distribution while still producing a machine-parseable answer.
The trigger token is not a minor implementation detail. The paper's <eos>-only In-Writing* is more stable than allowing { as a trigger, because brace-triggering can interrupt reasoning before the answer is ready.
The strongest evidence is parseability plus asymmetric overlap: In-Writing* achieves 100% parse rate in the reported Qwen reasoning parse table and recovers many NL-to-Format failures. The weakest point is semantic correctness of the final extraction: constraints can still force a syntactically valid but wrong final_answer, and the paper does not supply a full statistical analysis of those semantic failures.
For use in agent pipelines, I would treat In-Writing as an output-interface improvement, not a replacement for verification. It is attractive when strict JSON/XML/YAML fields are needed from a single model call, but high-stakes workflows should still validate the extracted answer against the reasoning or external evidence.