Source-first digest for checked paper rank p040.
- Routing status:
success - PDF extraction: not used
- Table recovery note: the benchmark and ablation tables were malformed in
paper.md; their numeric values were recovered fromlatex_flattened/main.flattened.tex.
Motivation / Background
Semantic correspondence asks for matches between semantically equivalent object parts across images. It is harder than low-level feature matching because viewpoint, articulation, intra-class shape, occlusion, and background all vary. The paper starts from a concrete failure mode: strong 2D foundation features such as DINOv2 and Stable Diffusion can still confuse left and right sides of symmetric objects or collapse repeated parts such as wheels, legs, and windows.
Prior 3D-aware correspondence pipelines partly address this by using pose annotations and coarse category-level spherical proxies. Geometry Matters argues that this is the wrong granularity: semantic correspondence needs per-instance geometry when the ambiguity is local, repeated, or asymmetric. The paper therefore uses single-image 3D foundation models as teachers: SAM3/SAM3D produce an object mask, mesh, and camera; a render-and-compare refinement improves the pose; PartField descriptors are rendered into the image plane; and geodesic distances on the reconstructed meshes filter candidate matches before training a small adapter.
The motivation is easiest to see in Figure 1: SD+DINO produces wrong repeated-part matches, a geodesic filter removes many mistakes but becomes sparse, and adding PartField features gives denser, more accurate pseudo-correspondences.



Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Single-image 3D foundation priors can replace manual pose annotations as a practical geometry source for weakly supervised semantic correspondence. | 4 | reconstruction, correspondence pipeline, main results |
| C2 | Rendered PartField descriptors complement DINO and Stable Diffusion features by resolving symmetric and repeated structures that 2D features confuse. | 4 | teaser, PartField PCA, PartField similarity, category pattern |
| C3 | Bicyclic geodesic filtering produces cleaner pseudo-labels than spherical, triplane, or direct PartField-similarity filters, and the cleaner labels improve final PCK. | 5 | weight search, filter validation, ablation |
| C4 | 3D-SC is strongest among weakly supervised methods without human annotations on the main reported benchmarks, especially SPair-71k and SPair-Geo-Aware. | 5 | main results |
| C5 | Gains are concentrated in rigid, symmetric, man-made categories; within-part localization and deformable animals remain weaker. | 4 | category pattern, limitations |
| C6 | The reduced-supervision claim is real but bounded: the method still depends on dataset category labels or detector-quality masks, SAM3D pose/shape quality, and PartField's part-level granularity. | 4 | implementation details, limitations |
Scores are support-from-paper scores, not independent reproduction scores. I cap the broad reduced-supervision and geometry-transfer claims below 5 because the evidence is strong on standard benchmarks but still depends on the quality and assumptions of the upstream 3D foundation models.
Core Technical Idea
The paper treats 3D foundation models as a source of pseudo-supervision for a 2D correspondence adapter. The pipeline is:
1. Reconstruct and canonicalize a mesh for each object instance. 2. Render PartField descriptors from that mesh into image coordinates. 3. Fuse rendered PartField with DINO and Stable Diffusion descriptors to propose candidate matches. 4. Lift each candidate match back to the two meshes and reject it if the 3D surface locations are geodesically inconsistent. 5. Train a lightweight adapter on top of frozen DINO+SD features using the retained pseudo-labels.
The key design choice is not simply adding a 3D feature. The paper uses 3D twice: PartField improves feature quality during candidate generation, and mesh geodesics filter candidate labels before supervision. Figure 3 is the main method diagram and shows how the image-space and mesh-space checks interact.
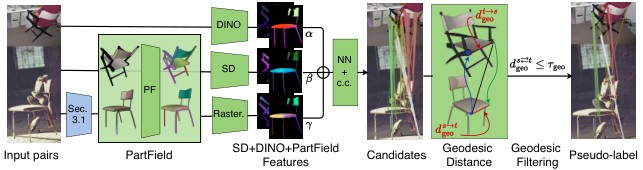
Method Details
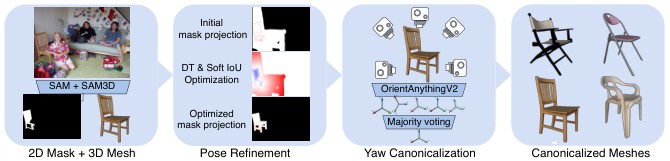
Canonicalized 3D Object Reconstruction
Figure 2 shows the upstream geometry stage. The method obtains an instance mask with SAM3, reconstructs an object-centric mesh and camera with SAM3D, then refines scale and translation by matching the rendered silhouette to the observed mask. The refinement uses a distance-transform phase first, because soft IoU has poor gradients when the rendered and observed masks do not overlap.
The distance fields are:
The DT loss combines an outside attraction term with an inside coverage term:
After overlap is established, the method switches to soft IoU:
For yaw canonicalization, the paper renders each mesh at eight known yaw angles, asks OrientAnything V2 for apparent orientation, chooses a correction from \(\{0^\circ,90^\circ,180^\circ,270^\circ\}\), and aggregates by majority vote:
The supplement reports that 79 of 1,319 refined meshes required a non-zero yaw correction, or 5.99 percent. The most affected classes were bus, boat, train, and cow.
PartField Features And Feature Fusion
PartField predicts a continuous per-vertex descriptor field on a 3D shape. The method rasterizes these descriptors into the image using the SAM3D camera and refined pose. Vertices outside the frustum or foreground mask are discarded; pixels without projected descriptors are filled by nearest-neighbor propagation.
The PCA visualizations in Figure 5 support the paper's claim that PartField features are spatially coherent within semantic parts while remaining comparable across instances.

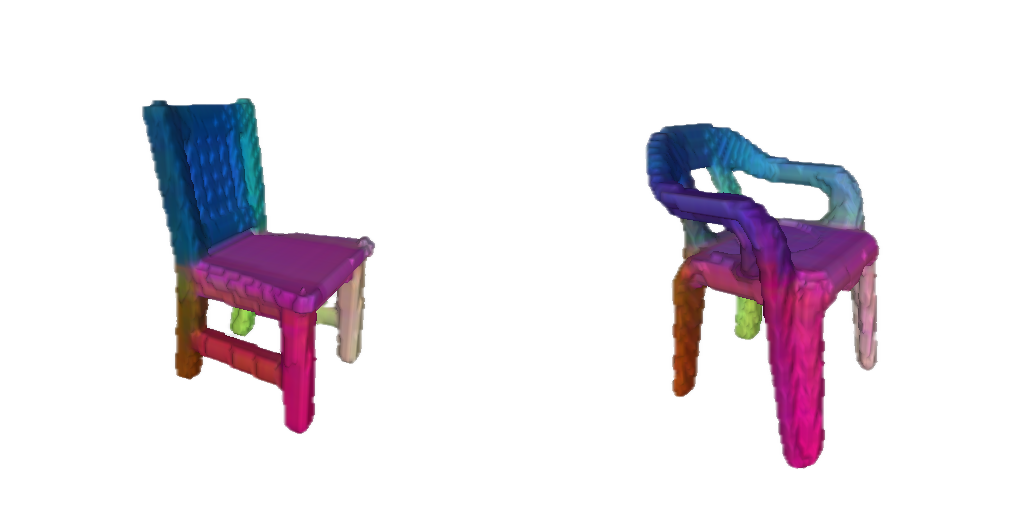
Figure 6 is more diagnostic: a queried car wheel or chair leg activates the corresponding repeated part instead of all visually similar parts. This is the mechanism the paper uses to explain gains on rigid symmetric categories.
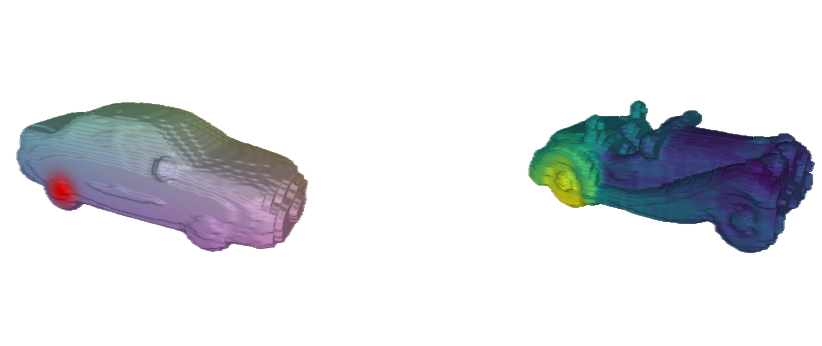
The fused image descriptor concatenates independently normalized SD, DINO, and PartField features with square-root weights:
The default weights are \(\alpha=1/2\), \(\beta=1/3\), and \(\gamma=1/6\). The square-root form makes the dot product in fused space equivalent to a weighted average of cosine similarities from the three normalized feature spaces.
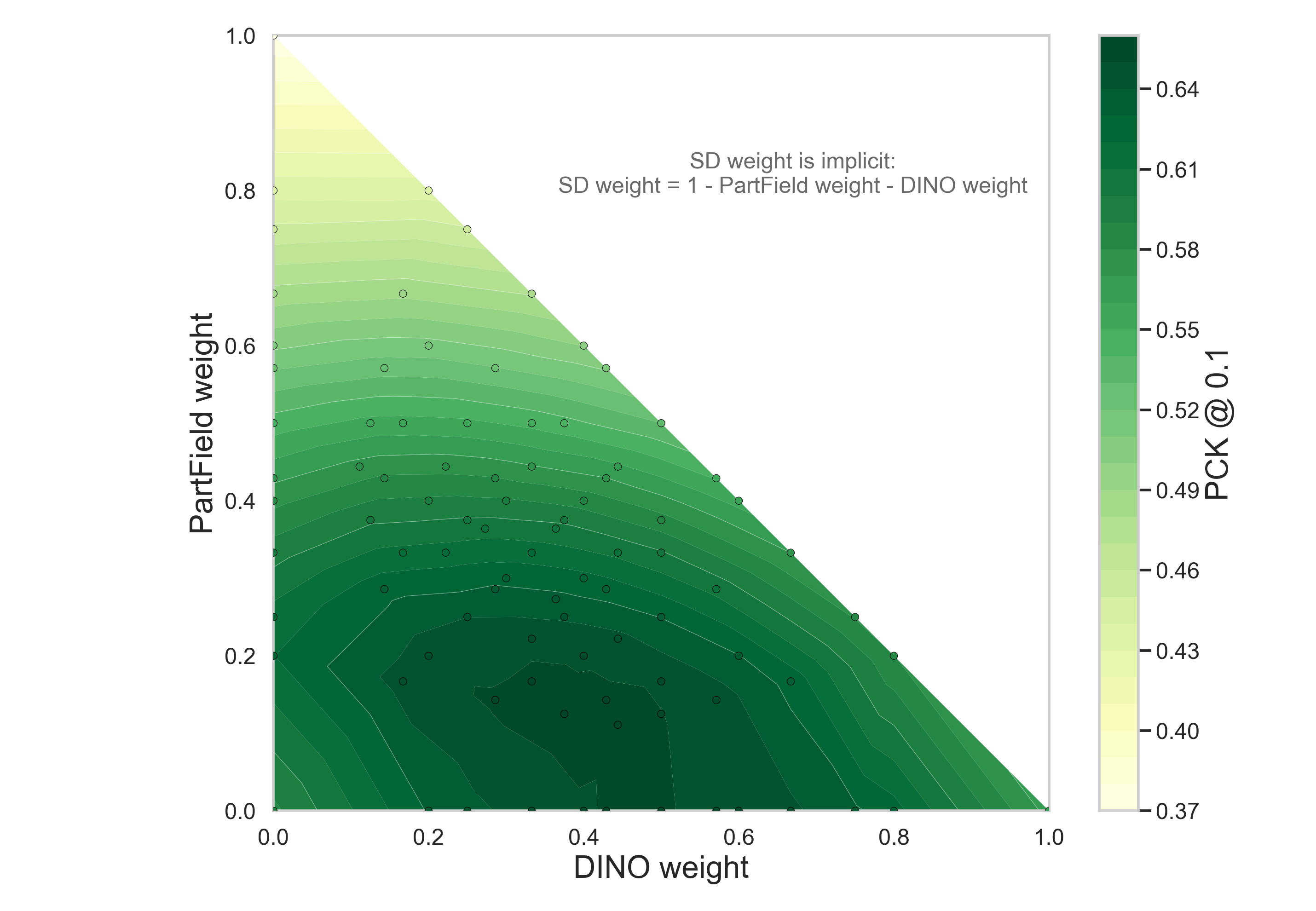
The paper's weight search in Figure 7 shows that multiple mixtures work, but the chosen one keeps PartField present without letting the coarser 3D part descriptor dominate within-part localization.
Pseudo-Label Filtering And Adapter Training
Candidate matches are proposed by nearest-neighbor search in fused feature space, then filtered by relaxed cyclic consistency:
The important second filter is geometric. For a source-target candidate, the method lifts both pixels onto their meshes. It then uses PartField nearest-neighbor search to predict a cross-mesh counterpart and compares that predicted surface point with the target surface point induced by the image-space match. The forward geodesic error is:
The final bicyclic geodesic error averages forward and backward errors and normalizes by mesh bounding-box diagonals:
Retained pseudo-labels are:
The adapter is a four-layer, 5M-parameter model trained on top of frozen DINOv2 and Stable Diffusion features. It uses sparse contrastive supervision on pseudo-correspondences plus dense regression through a window soft-argmax:
Implementation settings matter for interpreting the results. The paper uses \(\lambda=4\), \(\tau_{cc}=0.05\), and \(\tau_{\text{geo}}=0.05\). SD and DINO features are extracted from high-resolution images, PartField descriptors are rasterized at \(60^2\), and training runs for 200k iterations with 50 pseudo-labels sampled per pair per iteration.
Experiments And Results
Table 1 is the central quantitative evidence. The compact version below keeps the PCK@0.1 columns needed to judge the main claims; values come from the recovered LaTeX table.
| Method | Supervision type | SPair-71k | SPair-Geo-Aware | AP-10K intra | AP-10K cross-species | AP-10K cross-family | SPairU |
|---|---|---|---|---|---|---|---|
| DINOv2+NN | Unsupervised | 53.9 | 42.0 | 60.9 | 57.3 | 47.4 | 54.9 |
| DIFT | Unsupervised | 52.9 | 42.5 | 50.3 | 46.0 | 35.0 | 47.4 |
| Spherical Map | Weak, human pose annotations | 64.4 | -- | 65.4 | 63.1 | 51.0 | 61.0 |
| DIY-SC | Weak, human annotations | 71.6 | 67.5 | 70.6 | 69.8 | 57.8 | 67.9 |
| SD+DINOv2 | Weak, no human annotations | 59.9 | 49.3 | 62.9 | 59.3 | 48.3 | 59.4 |
| DIY-SC+OriAny | Weak, no human annotations | 69.6 | 65.8 | 69.3 | 66.8 | 54.0 | 66.3 |
| 3D-SC (ours) | Weak, no human annotations | 73.0 | 70.8 | 69.6 | 68.5 | 56.9 | 67.3 |
Table 1. Evaluation on standard benchmarks. 3D-SC is strongest among the no-human-annotation weakly supervised methods on all listed columns and beats the human-annotation DIY-SC baseline on SPair-71k and SPair-Geo-Aware. The AP-10K gains are smaller but still positive against DIY-SC+OriAny.
Main Benchmark Interpretation
On SPair-71k, 3D-SC reaches 73.0 PCK@0.1, improving over DIY-SC+OriAny by 3.4 points. On the geometry-targeted SPair-Geo-Aware subset, it reaches 70.8, improving over DIY-SC+OriAny by 5.0 points and over SD+DINOv2 by 21.5 points. This is the cleanest support for the paper's core hypothesis: if the benchmark emphasizes symmetric and repeated parts, instance-specific 3D geometry helps.
On AP-10K, the method reports 69.6/68.5/56.9 on intra-species, cross-species, and cross-family splits. That beats the no-human-annotation baseline, but the gap is modest compared with the SPair-Geo-Aware gain. The paper's explanation is plausible: PartField's part-level cues are less reliable for deformable animals and unusual poses.
Pseudo-Annotation Quality
Figure 4 visually supports the pseudo-label quality claim: 3D-SC annotations are denser and more geometrically consistent than DIY-SC in the paper's examples.

Figure 8 extends the same evidence with more categories. I include it because the qualitative claim is not just one cherry-picked pair; the supplement uses the same visual comparison across additional objects.


Filter And Ablation Evidence
Table 2 isolates the filter. With SD+DINO+PartField candidates, geodesic filtering has the lowest false positive rate, 1.78 percent, while keeping 1,634 candidates per pair.
| Feature set | Filter | FPR | Candidates per pair |
|---|---|---|---|
| SD+DINO | Spherical mapper | 10.95 | 1856 |
| SD+DINO | Triplane | 13.15 | 1948 |
| SD+DINO | PF feature similarity | 2.81 | 1608 |
| SD+DINO | Geodesic | 1.82 | 1543 |
| SD+DINO+PartField | Spherical mapper | 10.75 | 2001 |
| SD+DINO+PartField | Triplane | 13.07 | 2090 |
| SD+DINO+PartField | PF feature similarity | 2.47 | 1694 |
| SD+DINO+PartField | Geodesic | 1.78 | 1634 |
Table 2. Filtering evaluation on the validation set. FPR is the false positive rate among unfiltered wrong predictions. The geodesic filter is best under both feature sets.
Table 3 shows how the components accumulate. Pseudo-labeling, cyclic consistency, geodesic filtering, PartField, DINOv3, and capped sampling all contribute to the final 73.0 SPair-71k PCK@0.1.
| Pseudo labels | PartField | Cyclic consistency | Geodesic filter | Sampling cap | DINO | SPair-71k PCK@0.1 |
|---|---|---|---|---|---|---|
| no | no | no | no | yes | v2 | 64.9 |
| yes | no | no | no | yes | v2 | 67.0 |
| yes | no | yes | no | yes | v2 | 67.6 |
| yes | no | yes | yes | yes | v2 | 71.6 |
| yes | no | yes | yes | yes | v3 | 72.4 |
| yes | yes | no | no | yes | v2 | 66.9 |
| yes | yes | yes | no | yes | v2 | 68.8 |
| yes | yes | yes | yes | yes | v2 | 72.1 |
| yes | yes | yes | yes | no | v3 | 72.4 |
| yes | yes | yes | yes | yes | v3 | 73.0 |
| DIY-SC baseline | -- | -- | -- | -- | v3 | 72.1 |
| DIY-SC+OriAny baseline | -- | -- | -- | -- | v3 | 70.4 |
Table 3. Ablations on SPair-71k. The largest single jump in the visible sequence is adding geodesic filtering after pseudo-labels and cyclic consistency. The final row also shows a 0.6 point gain from the sampling cap relative to the same v3 configuration without it.
Category Pattern
The per-category table in the supplement is too wide for the digest, but Table 4 captures the main pattern the authors emphasize: the largest gains over DIY-SC+OriAny appear on rigid, symmetric, man-made categories. Regressions appear on deformable or less PartField-friendly categories.
| Category pattern | Reported delta or behavior | Interpretation |
|---|---|---|
| Bus | +10.8 over DIY-SC+OriAny | Strong symmetry and repeated structures; 3D geometry is highly useful. |
| TV/monitor | +9.8 | Rigid object with viewpoint-sensitive part identity. |
| Bottle | +8.8 | Geometry helps distinguish visually similar object regions. |
| Car | +6.9 | Front/rear and left/right ambiguity is a central failure case. |
| Train | +6.2 | Repeated rigid components benefit from geometric filtering. |
| Motorcycle | +5.1 | Rigid structure and repeated wheels match the PartField prior. |
| Chair | +4.0 | Repeated legs and front/back ambiguity benefit from 3D cues. |
| Sheep, cat, cow | -2.7, -1.5, -1.7 | Deformable animals are weaker for the current PartField/SAM3D setup. |
Table 4. Per-category result pattern. The strongest gains align with the method's stated target: symmetric or repeated rigid structure. This also exposes the current boundary of the approach.
Practical Takeaways
The reusable idea is to use 3D foundation models as a source of geometry-aware pseudo-labels for a 2D task, not necessarily to make the final model 3D-heavy. The final adapter still runs on frozen 2D features; 3D is used offline to produce better supervision.
The strongest evidence is the combination of SPair-Geo-Aware results, geodesic-filter FPR, and ablations. Those three pieces line up: geometry helps most where the benchmark demands geometric disambiguation, the geodesic filter removes false matches directly, and the ablation shows that filtering improves downstream PCK.
The weak spots are also clear. The pipeline inherits failures from SAM3D pose and shape estimates. PartField descriptors are coarse part-level descriptors, so they help less when the task requires precise within-part localization. Deformable animals are not as clean a fit as rigid man-made objects. The method also assumes object category information or detector-quality masks are available, even if it removes the manual pose labels required by prior approaches.
For future paper digestion, the biggest lesson is that the source Markdown can render figures well but still mangle LaTeX tables. Here, the main benchmark and ablation tables needed recovery from latex_flattened/main.flattened.tex; without that recovery, the digest would miss the strongest quantitative evidence.