Source-first digest for checked paper rank 56, rank_id p047.
- Routing status:
success - PDF extraction: not used
Motivation / Background
The paper asks whether softmax attention can be improved by treating each attention layer as a test-time regression solver. Linear attention and SSM-style mechanisms are efficient because they maintain recurrent state, but they fit query-agnostic global linear models and can lose accuracy on local or nonstationary mappings. Softmax attention is query-specific, but in this framing it is a local constant estimator, so it can suffer boundary bias and does not use local slope information.
Local Linear Attention (LLA) is the proposed middle ground: for each query, fit a local linear model to nearby key-value pairs and output the fitted intercept at the query. The paper positions this as an "optimal interpolation" between linear attention and softmax attention. Figure 1 and Table 1 summarize the regression view that motivates the method.
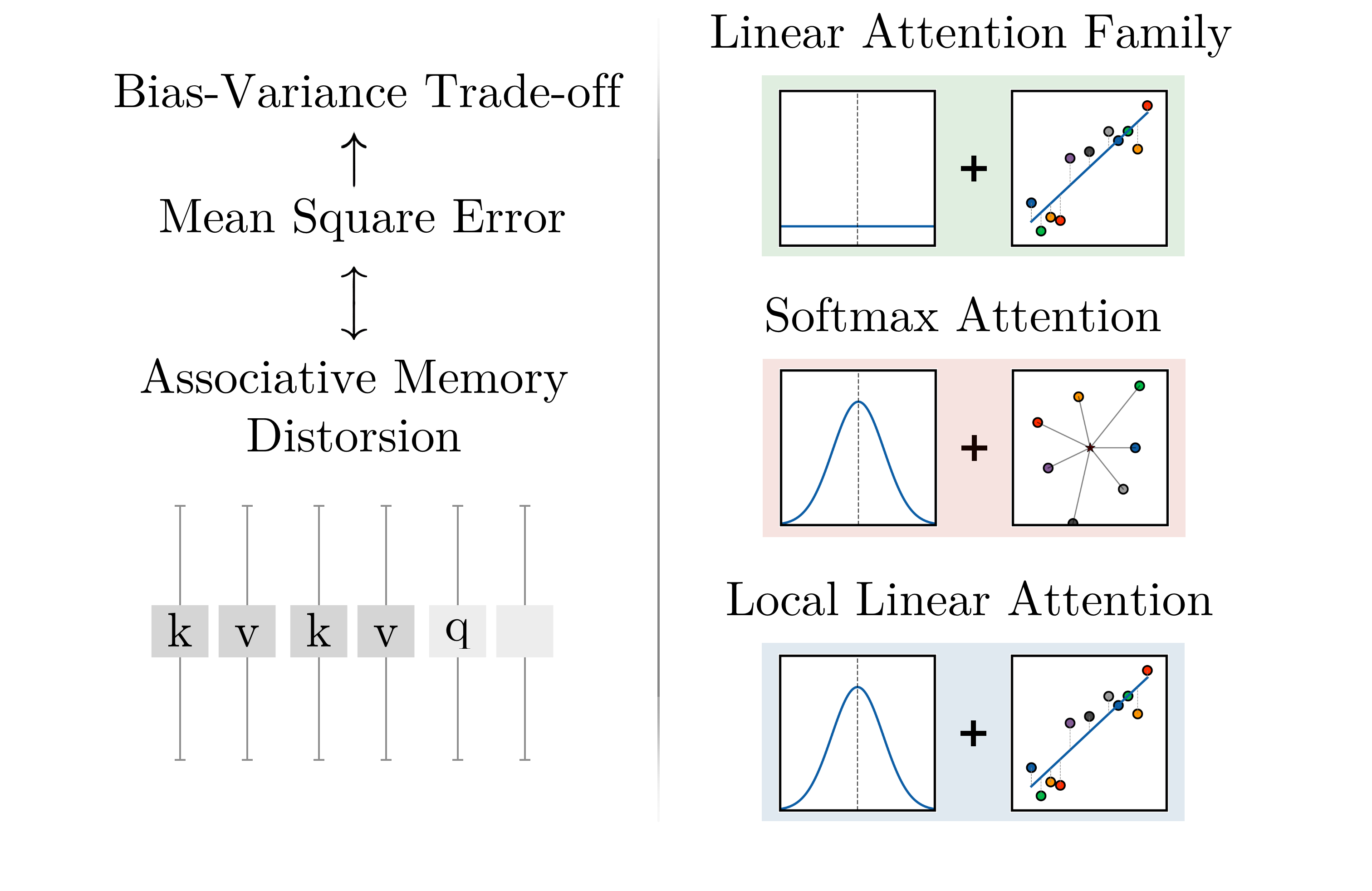
| Mechanism family | Regression view | Main strength | Main weakness in this paper's framing |
|---|---|---|---|
| Linear attention / SSMs | Global linear or recurrent fast-weight regression | Efficient recurrent state and long-context scaling | Query-agnostic fit can have irreducible approximation error when the mapping is not globally linear |
| Softmax attention | Local constant Nadaraya-Watson kernel regression | Query-specific locality and strong retrieval behavior | Boundary bias and no use of local first-order structure |
| Local Linear Attention | Query-specific local linear regression | Uses both locality and local slope information | More expensive than softmax because it solves query-specific linear systems |
Table 1. Digest comparison of the attention families. This table is derived from the paper's test-time regression interpretation and is included to clarify what the authors mean by interpolation.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Attention variants can be analyzed as test-time regression estimators, with linear attention as global linear regression and softmax as local constant kernel regression. | 4 | regression view, LLA formulation |
| C2 | LLA has a theoretical bias-variance advantage over both global linear and local constant estimators under the paper's assumptions. | 4 | theory propositions, regression strategies figure |
| C3 | The LLA formula interpolates softmax and linear attention by locally averaging residuals after a linear prediction. | 4 | LLA formulation, interpolation equation |
| C4 | FlashLLA makes the method practical enough to benchmark by avoiding pairwise difference materialization and matrix materialization. | 4 | implementation details, memory profile |
| C5 | LLA outperforms strong baselines on the paper's nonstationary test-time regression and in-context regression tasks. | 5 | test-time regression, in-context regression, full regression grid |
| C6 | LLA improves associative recall in controlled token tasks, but it does not solve state tracking beyond softmax attention. | 4 | associative recall, recall curves, state tracking |
| C7 | LLA is not yet validated as a drop-in LLM attention replacement; computation, I/O, kernel stability, and low-precision matrix inversion remain open. | 5 | limitations, memory profile |
Support scores are support-from-paper scores, not independent reproduction scores. Claims based on formal derivations are capped at 4 when the assumptions are narrower than deployed transformer settings; the experimental wins are strongest on the controlled synthetic and moderate-scale tasks the paper actually runs.
Core Technical Idea
The paper starts from a dataset at each position \(i\): historical key-value pairs \(\mathcal D_i=\{(k_j,v_j)\}_{j=1}^i\). A query \(q_i\) is treated as the test point where the attention layer should predict a value. Global linear attention estimates a weight matrix once from history, while softmax attention locally averages values around the query.
The theory section gives two separations. If the true mapping is not global linear, the global-linear estimator has non-vanishing integrated error while the local-constant estimator can converge:
Then, when boundary gradients are large enough, local linear regression improves over local constant regression:
Those rates are not an LLM benchmark. They are the mathematical reason the authors expect local linear fitting to help when attention is used for associative memory and nonstationary regression.
For query \(q_i\), LLA fits a local linear model \(f(x)=b+W(x-q_i)\) with query-dependent kernel weights:
Define \(z_{ij}=k_j-q_i\), and the query-specific statistics
With \(\rho_i=\Sigma_i^{-1}\mu_i\), the LLA output is still a weighted sum of values:
The important operational difference from MesaNet is that \(\Sigma_i\) is built from key vectors centered around the specific query \(q_i\). LLA therefore keeps a KV cache of size \(\Theta(nd)\) like softmax attention, not a constant-size recurrent state like the linear-attention family.
The interpolation claim is clearest in the residual decomposition:
Read literally, LLA locally averages residuals from a linear model and adds back the linear prediction at the query. Setting or approximating \(\hat W_i\) in different ways yields a design template between softmax-style local averaging and recurrent linear mechanisms.
Method Details
Naive LLA has two practical bottlenecks. First, materializing every centered pair \(z_{ij}=k_j-q_i\) costs \(\Theta(n^2d)\) memory. The paper avoids this by rewriting centered statistics in terms of uncentered weighted sums and the query:
The same trick gives a relative matrix multiplication primitive:
Second, directly inverting \(\Sigma_i\) for every token costs \(\Theta(nd^2)\) memory. The paper instead uses conjugate gradients, because the needed operation is a matrix-vector product with \(\Sigma_i\), not an explicit matrix inverse. In the forward pass, the algorithm solves \(R=\Sigma^{-1}\mu\) and then forms
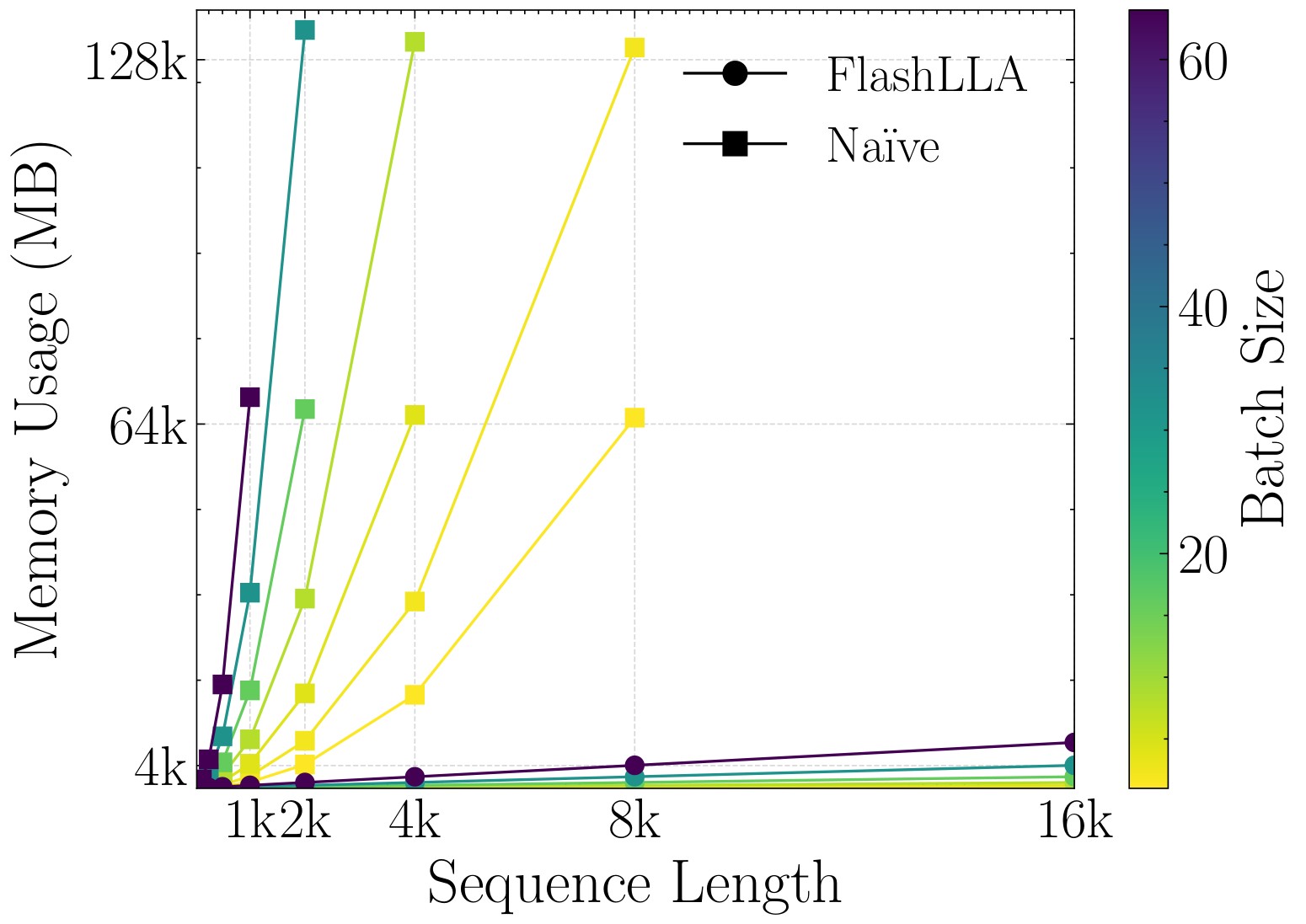
Figure 2 shows why this matters: the naive implementation runs out of memory as sequence length grows, while the blockwise Triton kernel keeps the working set much smaller. Table 2 then separates the implementation into the algebraic centering rewrite, implicit CG solve, and FlashLLA block loop.
| Component | Problem addressed | Digest note |
|---|---|---|
| Algebraic centering | Avoids explicit \(z_{ij}\) tensors | Reduces the pairwise-difference memory bottleneck from \(\Theta(n^2d)\) materialization to vector/key/query operations |
| Conjugate gradients | Avoids explicit per-token \(\Sigma_i^{-1}\) | Uses repeated matrix-vector products and keeps \(\Sigma_i\) implicit |
| FlashLLA block loop | Controls HBM/SRAM traffic | Uses three key/value passes per query block: accumulate statistics, solve CG, then apply corrected weights to values |
Table 2. Implementation pieces. This digest table summarizes the algorithmic role of the two memory-efficient primitives and the blockwise kernel.
The cost caveat is essential: CG and extra passes make the constant factors higher than FlashAttention, and the paper says low-precision kernels are numerically sensitive because of the matrix inversion.
Experiments And Results
The experiment scope is summarized in Table 3. The paper evaluates controlled mechanisms and small trained models, not full LLM replacement training.
| Setting | What is tested | Baselines named in the paper | Main result |
|---|---|---|---|
| Test-time regression | Single-layer adaptation to nonstationary piecewise-linear maps without training projections | Softmax, vanilla LA, MesaNet, random predictor | LLA has the lowest position-wise MSE after shifts and improves within segments |
| In-context regression | Two-layer trained models on nonstationary regression prompts | Softmax, Mamba, GLA, Hyena, Gated DeltaNet | LLA wins across the reported segment-size configurations |
| Associative recall | MQAR-style key-value recall with discrete tokens | Softmax and efficient sequence baselines | LLA reaches the highest recall accuracy across sequence lengths and key-value counts |
| State tracking | Permutation swap tracking | Same model family context | LLA is roughly on par with softmax, showing a clear limitation |
Table 3. Experimental scope. This table is distilled from the paper text and helps interpret the support scores: the empirical evidence is strong for the reported controlled tasks, but still short of full-scale LLM validation.
Test-Time Regression
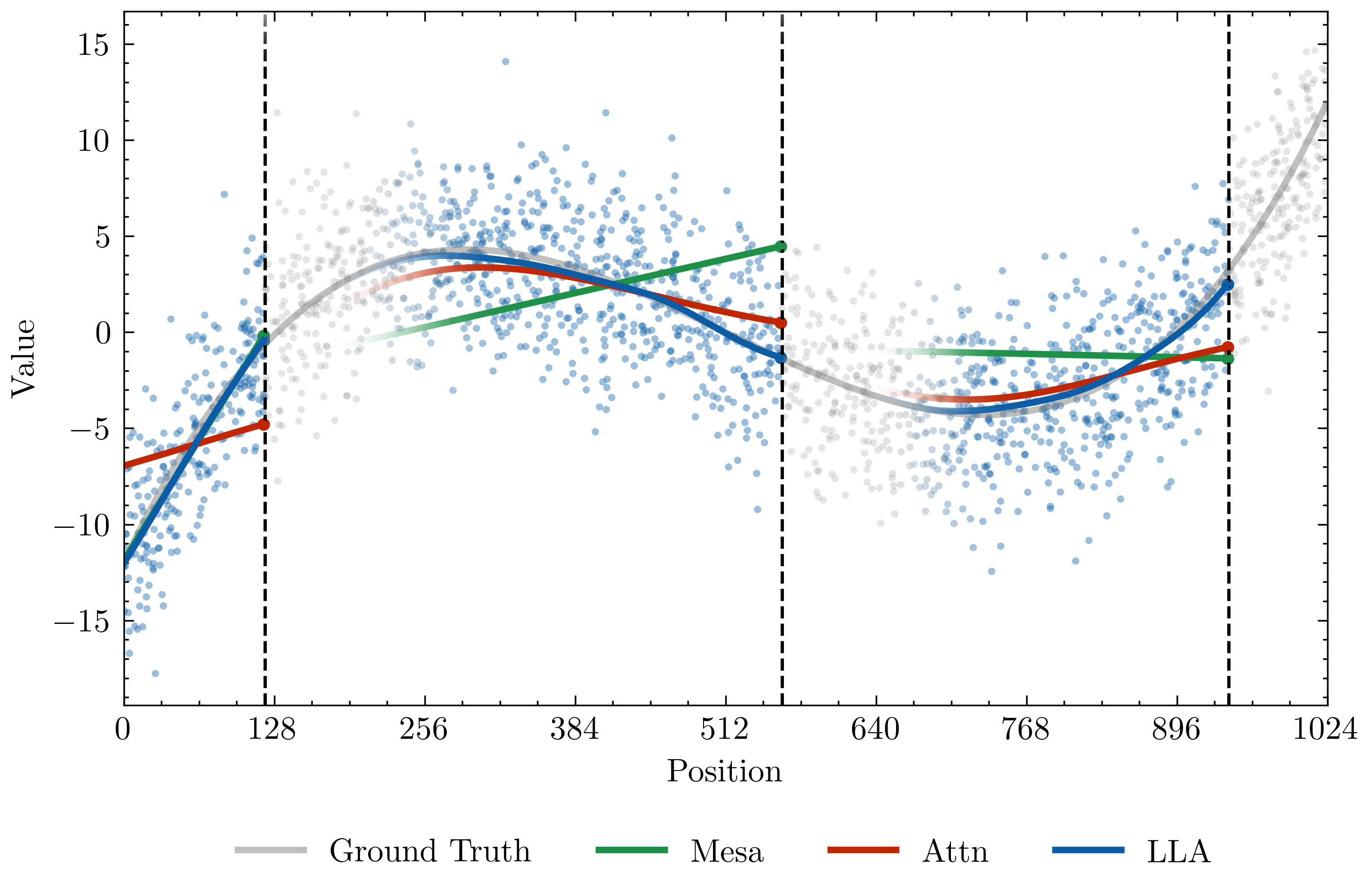
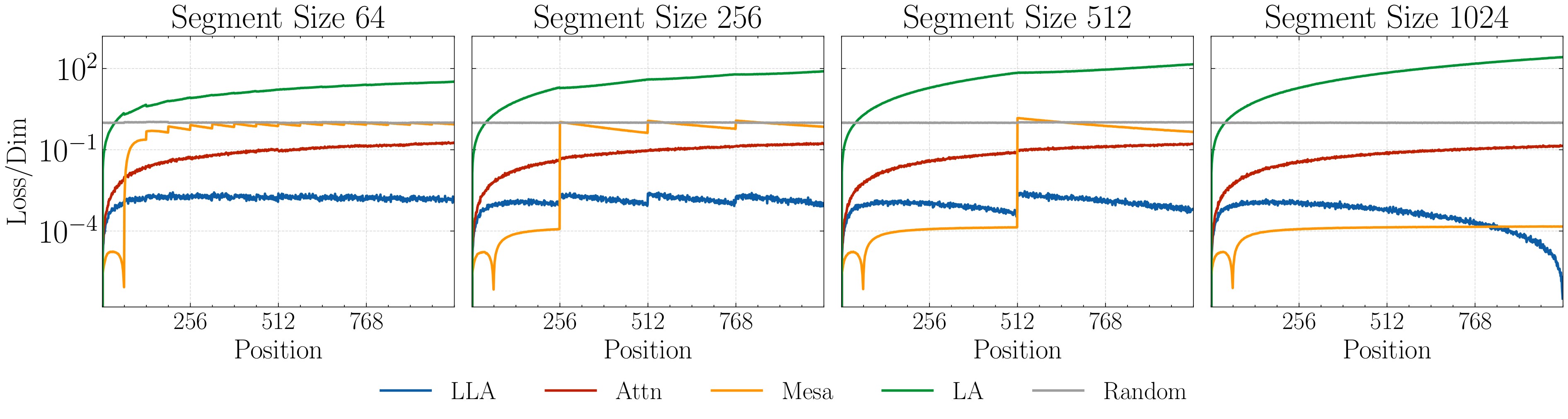
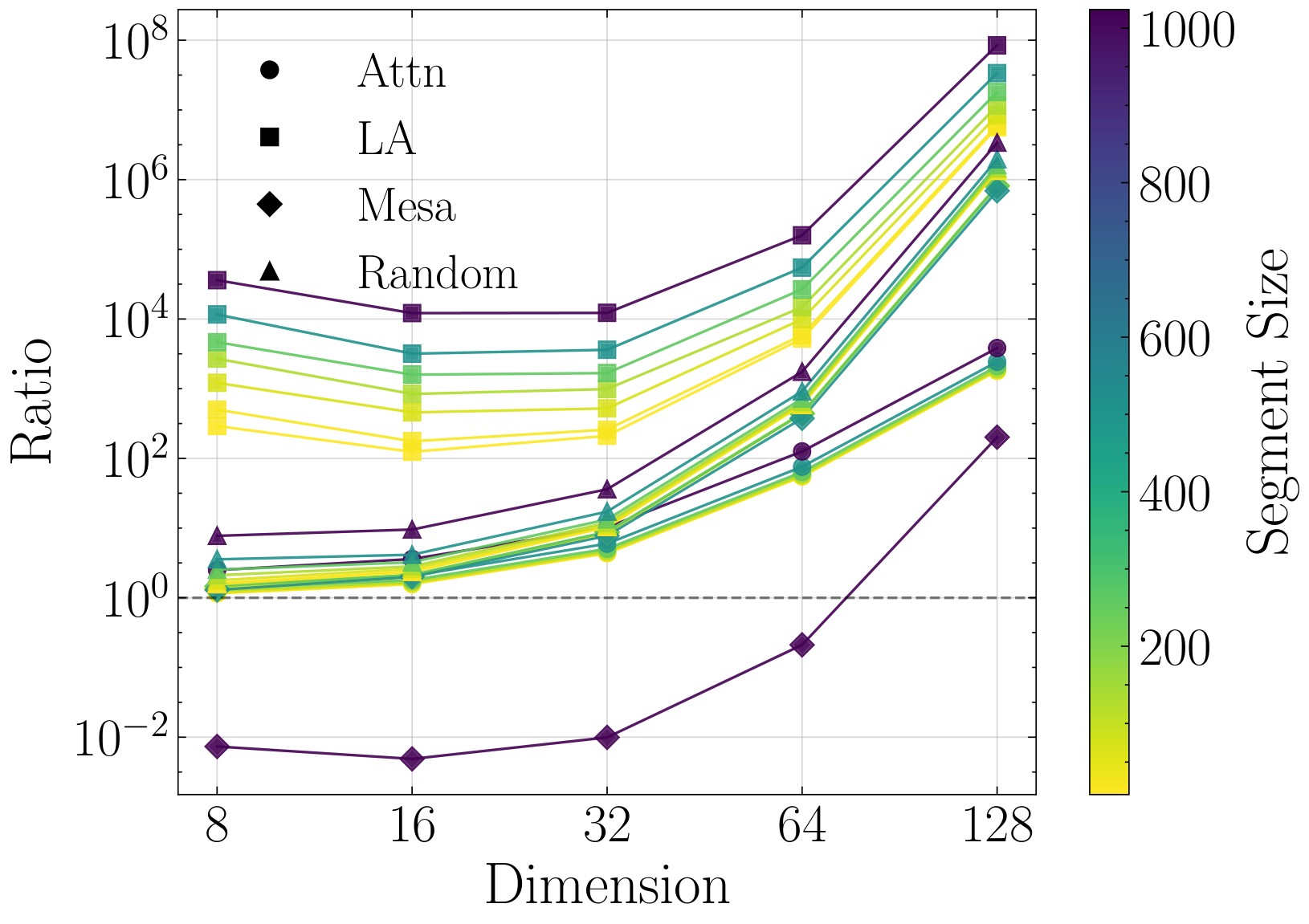
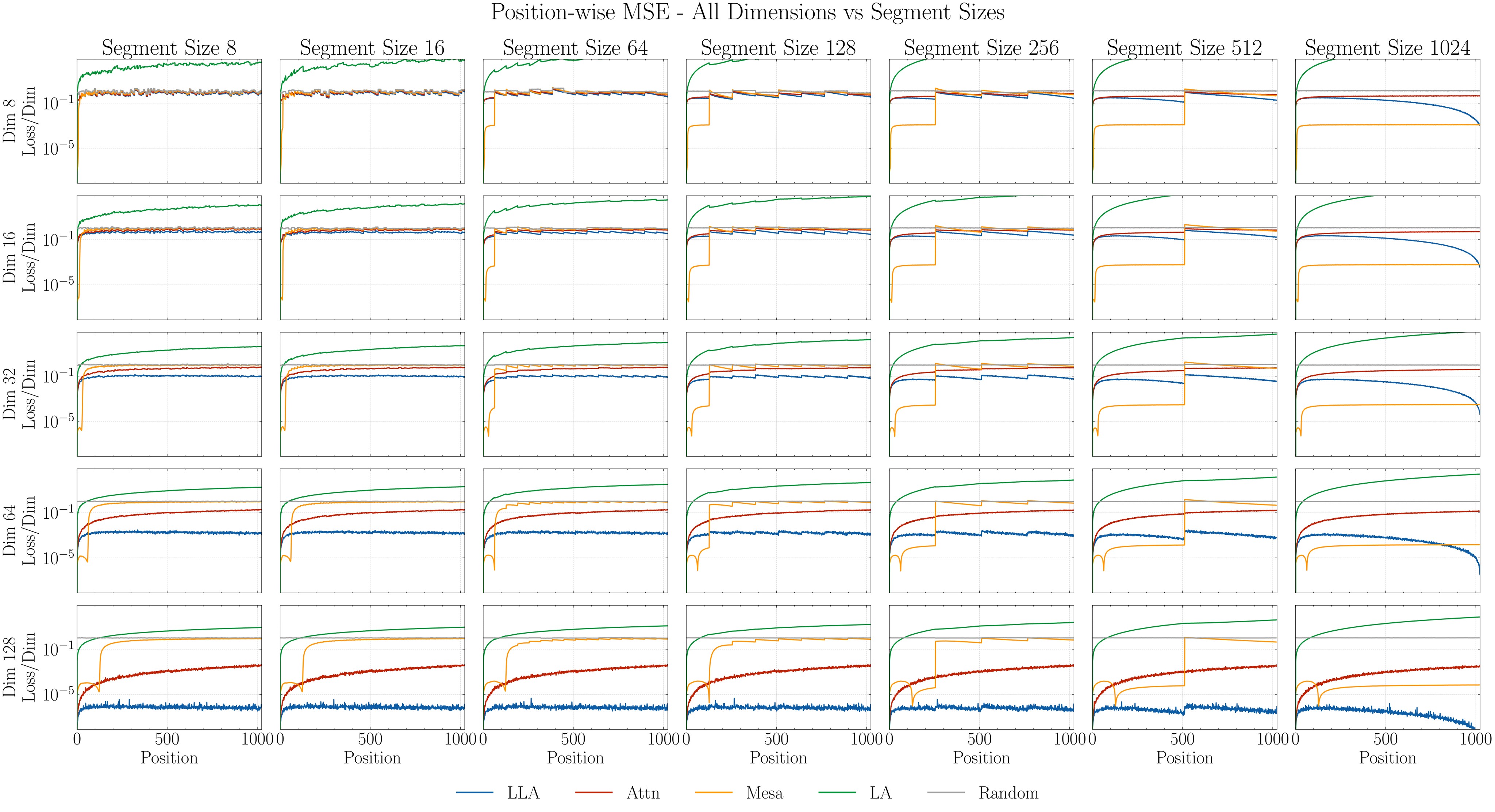
The first experiment creates length-\(L=1024\) sequences partitioned into segments. Each segment has a distinct cone-supported key distribution and a distinct linear map \(v_i=A_ck_i+\epsilon_i\), so the mapping changes along the sequence. The model is not trained; each attention mechanism is evaluated as a test-time estimator. Figure 3 is the main result, and Figure 4 shows that the advantage grows with data dimension in the reported sweep.
In-Context Regression
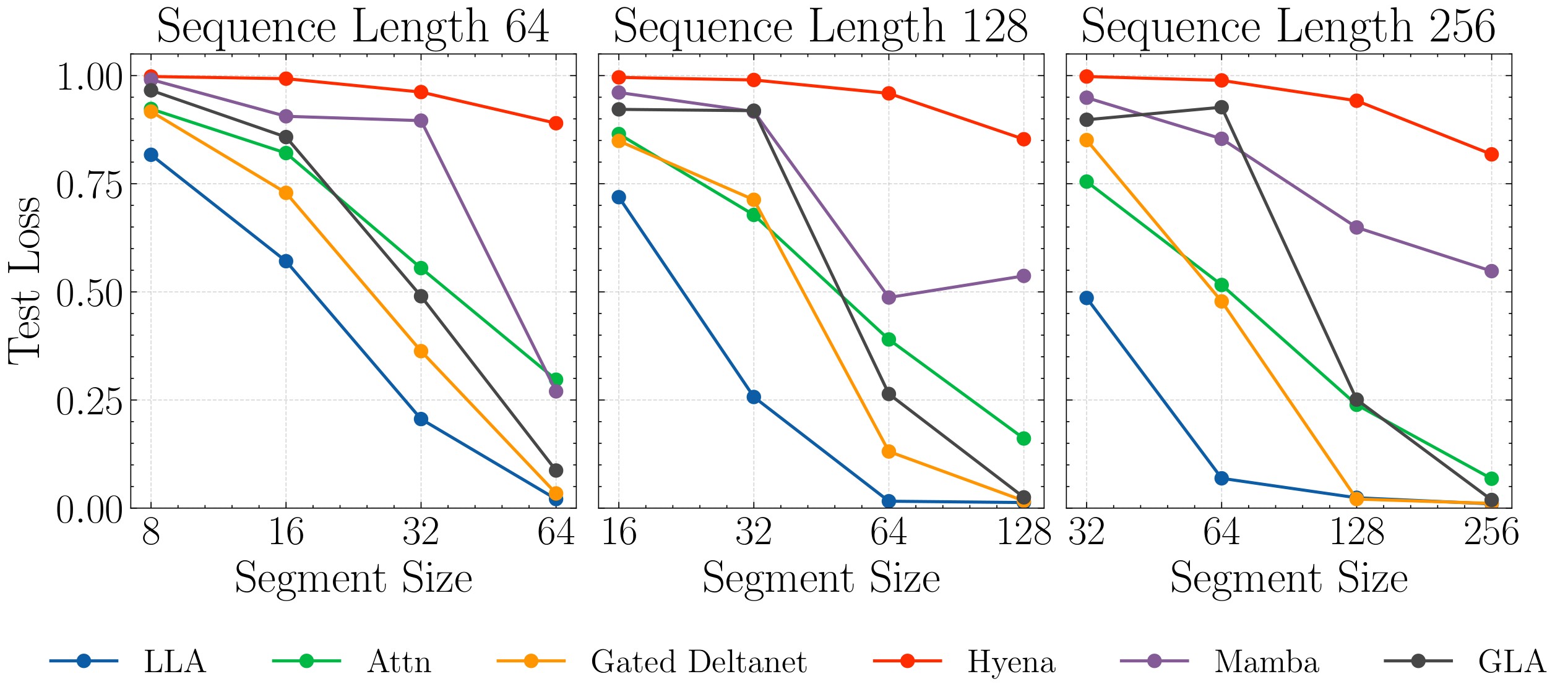
The in-context regression task trains two-layer models without MLPs. Inputs concatenate \(L\) shuffled input-target pairs and \(L'\) query tokens; the loss is MSE on the query targets. The paper fixes \(d_x=d_y=32\), \(L'=16\), sweeps segment size, and compares against softmax, Mamba, GLA, Hyena, and Gated DeltaNet. Figure 6 reports that LLA consistently has lower test error, especially when segment sizes are smaller and nonstationarity is stronger.
Associative Recall
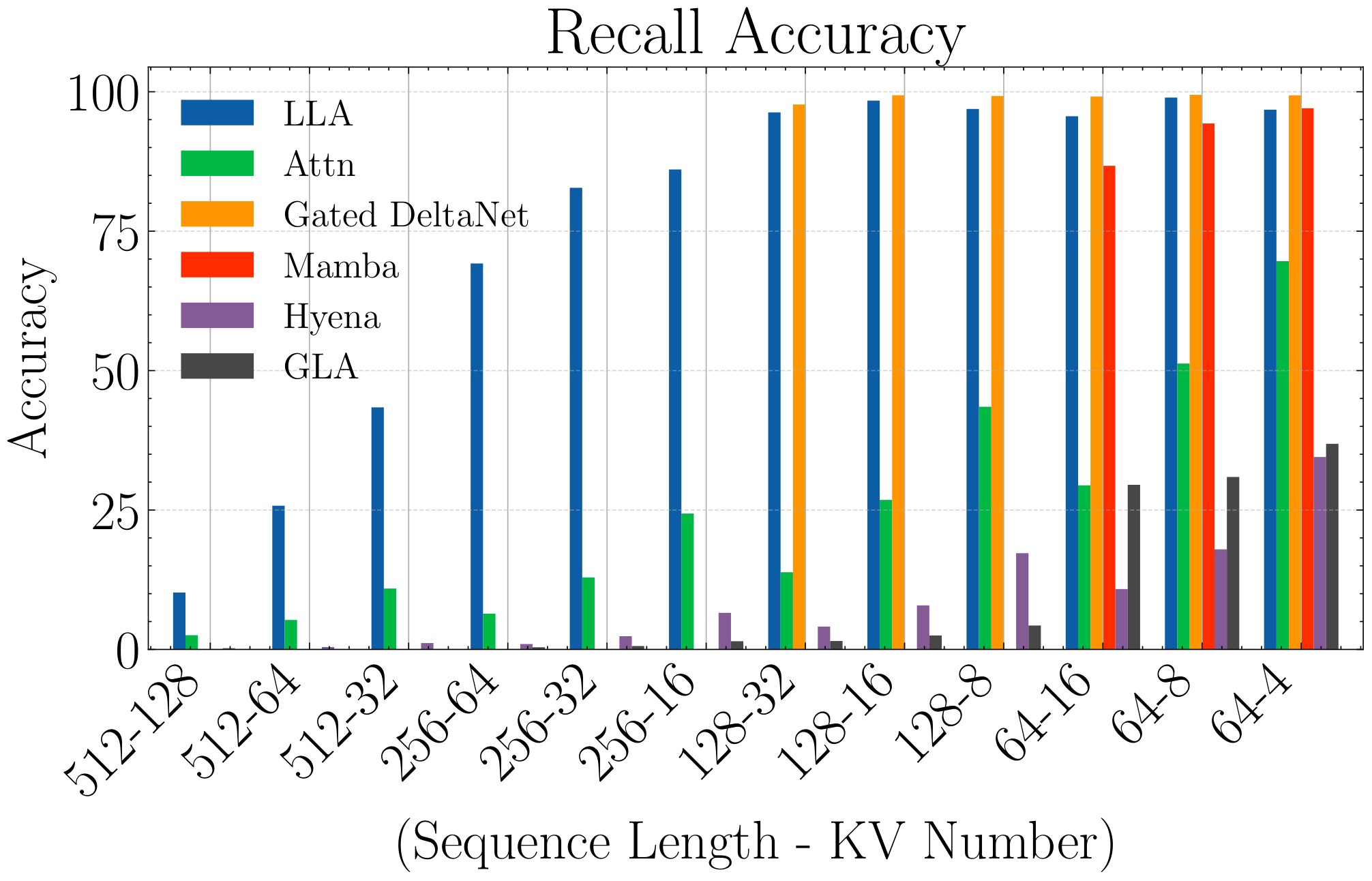
For MQAR-style recall, the model sees key-value pairs and then query keys whose answers are values from the context. The paper disables short convolution in all baselines because a short convolution can solve simple next-token recall. It uses vocabulary size \(|\mathcal A_k\cup\mathcal A_v|=8192\), sequence lengths \(L\in\{64,128,256,512\}\), and varying numbers of key-value pairs. Figure 7 is the main recall plot; Figure 8 expands the training curves from the appendix.
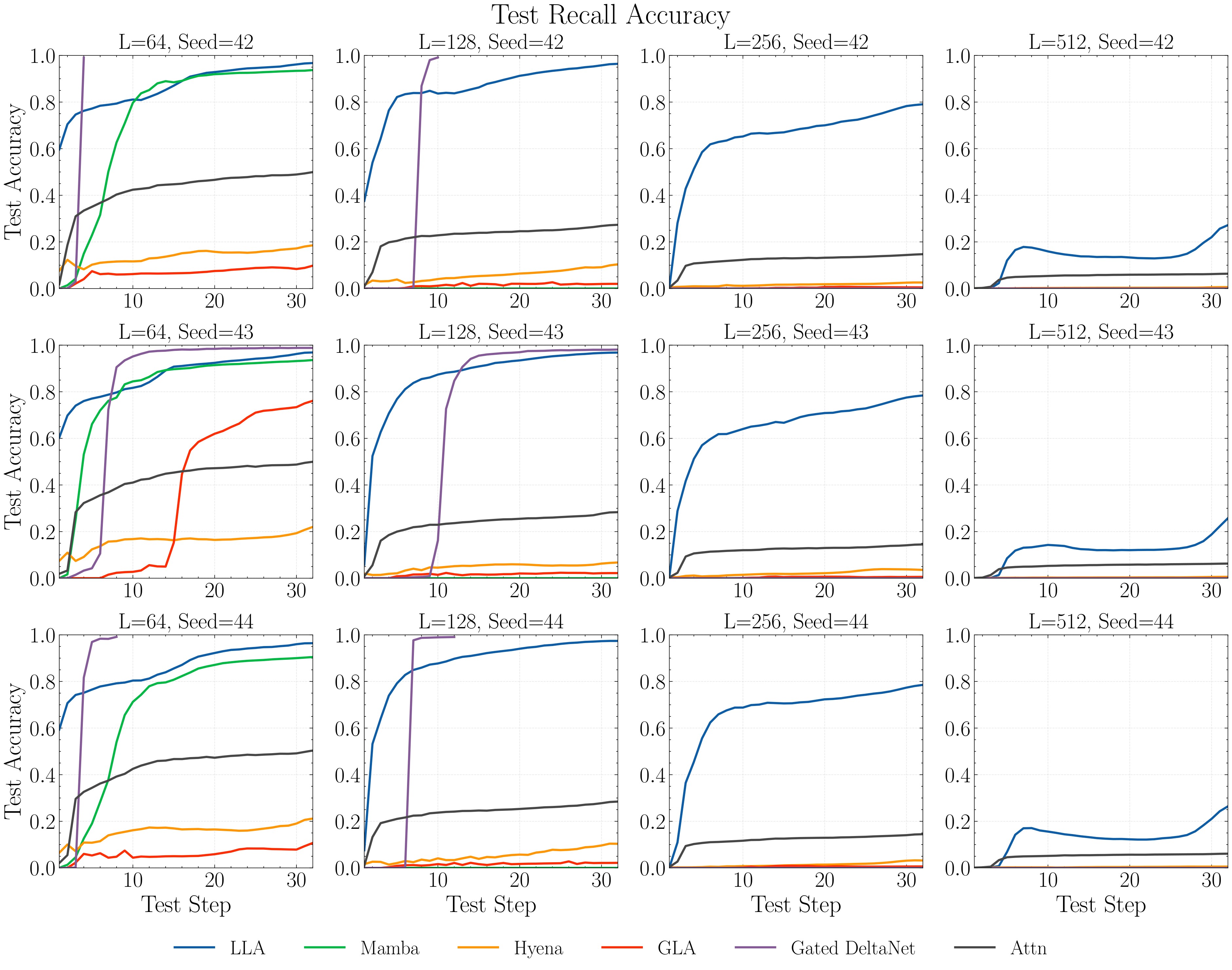
State Tracking Limitation
The state-tracking task gives an initial item-position assignment, a sequence of swaps, and query positions. The target is the final item at each queried position. Figure 9 is important because it is a negative result: LLA matches softmax attention but does not break the constant-depth limitation of this architecture family.
Limitations
The authors are explicit that LLA has not yet been established as a full LLM attention replacement. They evaluate synthetic and moderate-scale tasks, and say training LLMs with the PyTorch implementation is infeasible because of high compute and memory cost. The custom kernel reduces memory, but the method still has higher constant-factor I/O than FlashAttention, requires careful CG iteration control, and has numerical sensitivity around low-precision matrix inversion.
Practical Takeaways
- The reusable idea is the regression lens: softmax is local constant estimation, linear attention is global/recurrent linear estimation, and LLA is local linear estimation at each query.
- LLA is most convincing when the mapping is locally linear but nonstationary. That is exactly the setup where global linear recurrence is too rigid and softmax-style averaging wastes slope information.
- The implementation contribution matters. Without algebraic centering, implicit CG solves, and blockwise computation, the method is mostly a theoretical estimator.
- The evidence is strong for controlled regression and recall tasks, but not for production-scale language modeling. Treat the paper as a principled attention-design proposal, not as proof that LLA should replace softmax in large LLMs today.
- The most interesting follow-up direction is the interpolation equation: approximate \(\hat W_i\) with cheaper recurrent or sparse mechanisms, then preserve enough local correction to keep the bias-variance benefit.