Source-first digest for checked paper rank 29, rank_id p058.
- Routing status:
success - PDF extraction: not used
- Table recovery:
latex_flattened/main.flattened.texwas consulted only to recover the missing numeric bodies oftab:main_resultandtab:replacement.
Motivation / Background
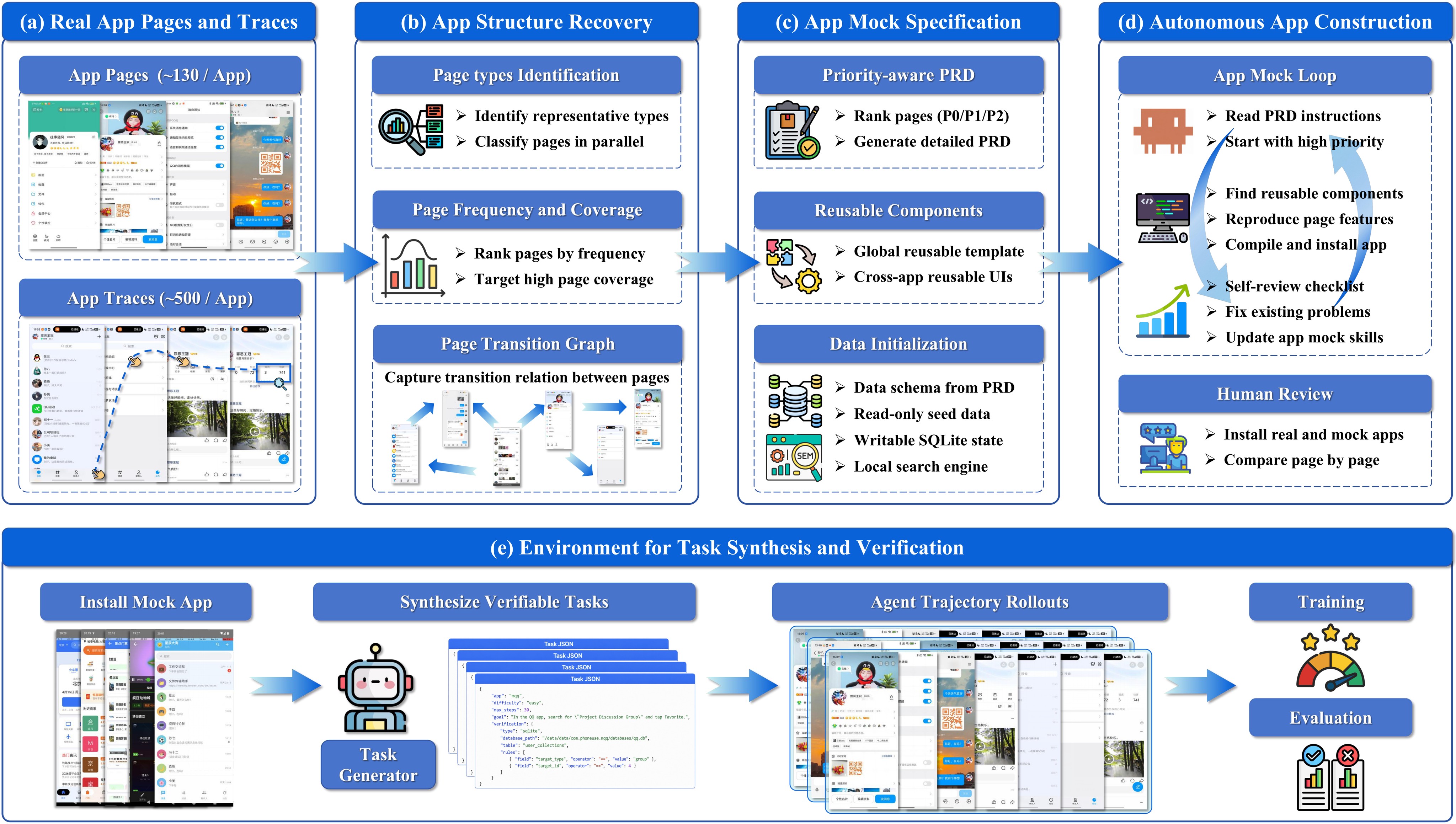
Phone-use agents operate through screenshots, touch actions, mobile navigation, and app state rather than through stable APIs. The paper argues that this makes environment supply a bottleneck: real mobile apps are dynamic, difficult to reset, and expensive to turn into reproducible evaluation and training setups. Existing systems such as AndroidWorld, MobileWorld, and A3 make mobile-agent evaluation more reliable, but they do not solve the upstream problem of repeatedly constructing new controllable phone-use environments.
PhoneWorld addresses that upstream bottleneck. It converts real GUI trajectories and representative screenshots into runnable mock Android apps, executable tasks, rule-based verifiers, and verifier-confirmed training rollouts. The key shift is that trajectories are not treated only as demonstrations; they are used to decide which screens matter, how navigation flows between screens, what state changes must persist, and which user goals can be checked automatically. Figure 1 shows the full source-to-environment pipeline, and Table 1 summarizes the scale of the current suite.
| Component | Summary |
|---|---|
| Apps | 34 mock Android apps across 16 domains |
| Reusable modules | 18 shared modules reused across app families |
| Benchmark | 120 audited tasks: 102 single-app + 18 cross-app |
| Verification | Answer-based checks and SQLite-based state checks |
| Task pool | 7,936 generated tasks used for large-scale rollout generation |
| Training rollouts | 3,354 successful episodes / 36,193 interaction steps |
Table 1. Summary of the PhoneWorld suite. This table grounds the scale claims: PhoneWorld is not only an app-construction recipe, but a concrete 34-app suite with held-out evaluation tasks and successful rollout data.
Claims And Evidence
| Claim id | Main claim | Support | Evidence anchors |
|---|---|---|---|
| C1 | Real trajectories plus screenshots can be converted into controllable, resettable phone-use environments with tasks, verifiers, and rollouts. | 4 | pipeline, worked example, worked-example figure, prompt verifier, suite |
| C2 | The current PhoneWorld instantiation has enough breadth to test environment scaling: 34 apps, 16 domains, 18 reusable modules, and held-out audited tasks. | 5 | suite, evaluation benchmarks, evaluation setup |
| C3 | Under a matched total training budget, replacing 10K auxiliary AndroidWorld steps with broad PhoneWorld supervision improves all four reported benchmarks. | 5 | partial replacement |
| C4 | PhoneWorld supervision is strong but complementary to AndroidWorld supervision rather than a wholesale replacement. | 4 | full replacement, add-only control, add-only table |
| C5 | Under a fixed 10K PhoneWorld budget, broader app coverage is the strongest reported scaling signal. | 4 | scaling figure |
| C6 | The construction process is scalable but not fully automatic; human audit and selective abstraction remain part of the system. | 3 | construction loop, limitations |
Scores are support-from-paper scores, not independent reproduction scores. I cap the broad scaling and construction-process claims below 5 where the paper gives strong experimental evidence but does not fully expose artifacts, app-level QA statistics, or public benchmark access.
Core Technical Idea
PhoneWorld is an environment factory for phone-use agents. For each target app, it takes two source signals:
- representative screenshots, which define visual layout and visible content;
- real exploratory-use trajectories, which define page importance, navigation flow, state-changing actions, and recurrent user goals.
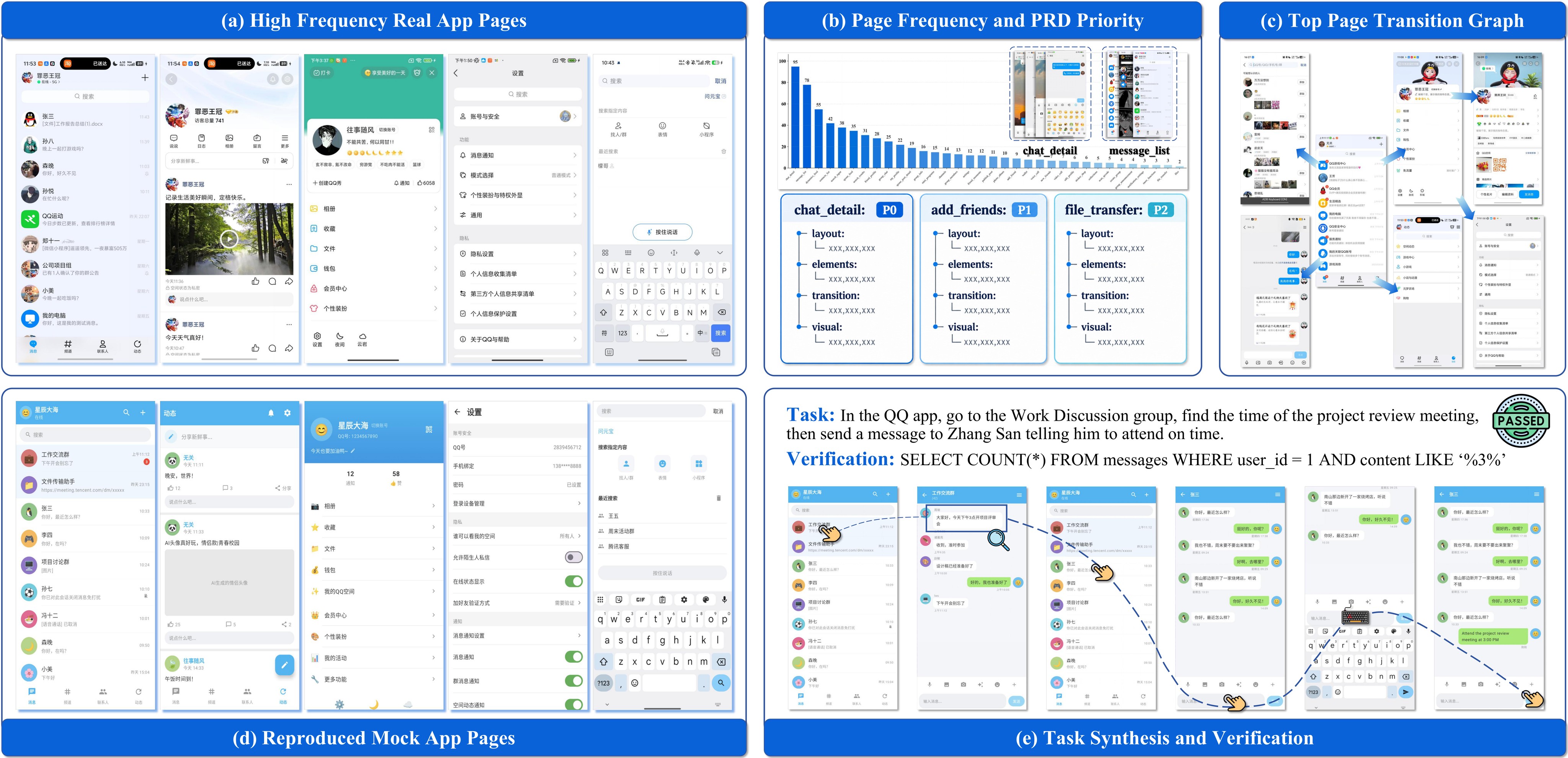
The pipeline recovers a page taxonomy, classifies screenshots into that taxonomy, estimates page visitation frequency, and builds a weighted page-transition graph. High-frequency pages become P0 build targets; moderate pages become P1; long-tail pages become P2 unless they are required by tasks. This matters because the system does not aim to clone every app feature. It preserves the screens, transitions, visible content, and mutable actions that matter for mobile agents.
The build specification layer converts recovered structure into per-page PRDs, reusable UI components, and a data architecture. The data layer separates read-only app content from mutable state in a resettable SQLite database. Read-only content lets agents browse and search realistic data offline; mutable tables record state changes such as favorites, cart edits, comments, messages, or profile updates. The same database is later used by verifiers.
The construction loop is deliberately pragmatic: a coding agent writes Kotlin/Jetpack Compose code, compiles the APK, runs a self-review checklist, and fixes issues such as schema mismatches, dead buttons, and missing routes. Across apps, recurring UI and logic patterns are promoted into reusable modules. The paper reports 18 modules, including search, feeds, comments, cart/checkout, address management, messaging, settings, and media player patterns.
Method Details
Structure Recovery And Build Specification
PhoneWorld first asks a coding/vision-language process to identify recurring page types from screenshots. A lightweight vision-language model then classifies the screenshot corpus in parallel. The classified trajectories yield a page-frequency distribution and a page-transition graph. Those two artifacts guide what the mock app must preserve: high-use screens, common navigation paths, and stateful interactions that tasks will later require.
For each prioritized page, a vision-language model writes a structured PRD covering layout, interactive elements, transitions, and visual attributes. A coding agent then implements the app with shared modules and a local data backend. The paper's central engineering choice is to make the environment resettable and inspectable: mutable app state lives in SQLite, read-only content is initialized deterministically, and local BM25 search gives reproducible retrieval behavior.
Task Synthesis And Verification
PhoneWorld generates tasks from the artifacts already produced during app construction: app content, database schema, and UI specification. This grounding is meant to ensure that generated goals refer to visible entities, ask for feasible operations, and have deterministic verification rules. The paper uses two verifier types: answer-based checks for information-seeking tasks, and SQLite-based checks for state-changing tasks. Figure 3 shows the source prompt-template example as a local SVG rendering because the LaTeX figure is a text box rather than an external graphic.

user_collections in the app's SQLite database. This illustrates why the environment construction step and verifier construction step must share the same content and schema.Training And Evaluation Setup
The training experiments use the same Qwen3.5-9B backbone, LlamaFactory training for two epochs, normalized coordinates, and the original phone screenshot resolution \(1080 \times 2400\). The matched-budget runs keep a shared AndroidWorld base corpus of 36,193 steps fixed and vary the other 36,193 steps, so the total budget is \(36{,}193 + 36{,}193 = 72{,}386\) steps.
| Benchmark | Environment | Metric | Role in the paper |
|---|---|---|---|
| HYMobileBench | Offline | Step SR | Real-device mobile performance proxy |
| AndroidControl | Offline | Step SR | Android control transfer |
| AndroidWorld | Online real app | Task SR | Out-of-domain real-app transfer |
| PhoneWorld | Online mock apps | Task SR | In-domain PhoneWorld evaluation |
Table 2. Evaluation benchmarks used in this paper. The table matters because the central result is not merely in-domain PhoneWorld improvement; the partial-replacement setting also improves the real-app AndroidWorld benchmark and two offline control benchmarks.
Experiments And Results
Matched-Budget Partial Replacement
The main matched-budget experiment asks whether a small amount of broad PhoneWorld data improves a strong AndroidWorld-based baseline. Baseline uses 36,193 shared AndroidWorld base steps plus 36,193 auxiliary AndroidWorld steps. The 10K PhoneWorld replacement keeps the same 72,386-step total, retains 26,193 auxiliary AndroidWorld steps, and replaces 10,000 auxiliary steps with verifier-confirmed PhoneWorld rollouts from all 34 apps. Table 3 is the key evidence.
| Benchmark | Baseline | 10K PhoneWorld replacement | Absolute change |
|---|---|---|---|
| HYMobileBench | 15.5 | 33.2 | +17.7 |
| AndroidControl | 53.7 | 59.7 | +6.0 |
| AndroidWorld | 56.9 | 71.6 | +14.7 |
| PhoneWorld | 12.5 | 65.0 | +52.5 |
Table 3. Matched-budget partial replacement. Replacing only 10K auxiliary AndroidWorld steps with broad PhoneWorld supervision improves all four reported benchmarks. The strongest gain is in-domain PhoneWorld, but AndroidWorld and the offline benchmarks also improve, which supports the claim that PhoneWorld is not just overfitting its own mock apps.
Full Replacement Control
Table 4 tests the endpoint where the full auxiliary AndroidWorld corpus is replaced by 36,193 PhoneWorld steps. This is useful because it separates "PhoneWorld data is useful" from "PhoneWorld data can replace every AndroidWorld signal."
| Benchmark | Baseline | Full PhoneWorld replacement | Absolute change |
|---|---|---|---|
| HYMobileBench | 15.5 | 33.2 | +17.7 |
| AndroidControl | 53.7 | 59.3 | +5.6 |
| AndroidWorld | 56.9 | 46.6 | -10.3 |
| PhoneWorld | 12.5 | 73.3 | +60.8 |
Table 4. Matched-budget full-replacement control. Full replacement strongly improves PhoneWorld and keeps gains on the two offline benchmarks, but it hurts AndroidWorld by 10.3 points. The paper interprets this as complementarity: AndroidWorld still contributes a distinct real-app transfer signal.
Scaling Amount And App Coverage
The second scaling study adds PhoneWorld supervision on top of the shared AndroidWorld base, using 0, 10K, 20K, or 36,193 PhoneWorld steps. PhoneWorld task success rises from 14.2 to 64.2, 70.0, and 73.3. The first 10K steps give the largest jump, and later additions still help but with smaller returns.
The third scaling study fixes the PhoneWorld budget at 10K steps and varies how many apps those steps cover. Figure 4 summarizes both curves. The app-coverage result is the stronger practical point: with the same 10K PhoneWorld budget, expanding coverage from 5 to 34 apps raises PhoneWorld from 46.7 to 65.0, HYMobileBench from 14.9 to 33.2, and AndroidWorld from 61.2 to 71.6, while AndroidControl stays roughly stable.
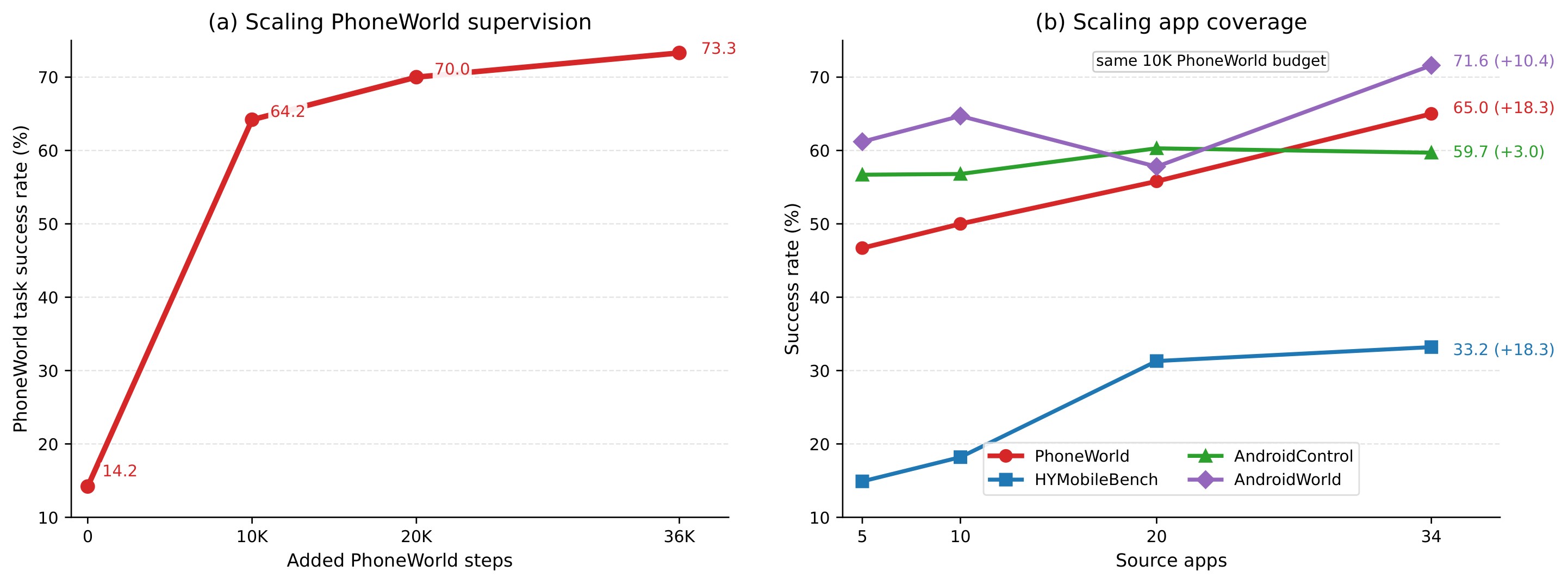
| Added PhoneWorld steps | AndroidWorld | PhoneWorld |
|---|---|---|
| 0K | 46.6 | 14.2 |
| 10K | 45.7 | 64.2 |
| 20K | 45.2 | 70.0 |
| 36K | 46.6 | 73.3 |
Table 5. Supplementary add-only analysis. Adding PhoneWorld supervision to the shared AndroidWorld base substantially improves PhoneWorld while leaving AndroidWorld roughly unchanged. This supports the paper's interpretation that the AndroidWorld drop in full replacement comes from removing auxiliary AndroidWorld data, not from adding PhoneWorld data itself.
Practical Takeaways
- The most reusable idea is the environment-construction loop, not any single benchmark number: use real traces to identify the functional app skeleton, build resettable state, and generate verifier-grounded tasks from the same schema.
- PhoneWorld's strongest result is the 10K partial replacement setting. It improves all four reported benchmarks under the same training budget, so the gain cannot be explained by simply adding more steps.
- Environment breadth appears more valuable than narrow data volume under a fixed PhoneWorld budget. The 5-to-34 app comparison is the cleanest evidence for scaling coverage.
- Full replacement is a warning against treating controllable mock apps as a substitute for real-app data. PhoneWorld contributes broad consumer-behavior supervision; AndroidWorld contributes a different real-app transfer signal.
- SQLite-backed mutable state is the important verifier design pattern. It makes tasks resettable, permits deterministic success checks, and creates a direct path from evaluation to successful-rollout harvesting.
The limitations are material. PhoneWorld apps are selective abstractions rather than full replicas, the benchmark is intentionally compact and manually audited, HYMobileBench is internal, and the PhoneWorld APKs/tasks are not publicly released at submission time. The system is AI-driven, but the paper does not claim full automation; human audit remains part of the construction process.